凤凰架构
凤凰架构
微服务九个特征
文中列举了微服务的九个核心的业务与技术特征,下面将其一一列出并解读。
- 围绕业务能力构建(Organized around Business Capability)。这里再次强调了康威定律的重要性,有怎样结构、规模、能力的团队,就会产生出对应结构、规模、能力的产品。这个结论不是某个团队、某个公司遇到的巧合,而是必然的演化结果。如果本应该归属同一个产品内的功能被划分在不同团队中,必然会产生大量的跨团队沟通协作,跨越团队边界无论在管理、沟通、工作安排上都有更高昂的成本,高效的团队自然会针对其进行改进,当团队、产品磨合调节稳定之后,团队与产品就会拥有一致的结构。
- 分散治理(Decentralized Governance)。这是要表达“谁家孩子谁来管”的意思,服务对应的开发团队有直接对服务运行质量负责的责任,也应该有着不受外界干预地掌控服务各个方面的权力,譬如选择与其他服务异构的技术来实现自己的服务。这一点在真正实践时多少存有宽松的处理余地,大多数公司都不会在某一个服务使用 Java,另一个用 Python,下一个用 Golang,而是通常会有统一的主流语言,乃至统一的技术栈或专有的技术平台。微服务不提倡也并不反对这种“统一”,只要负责提供和维护基础技术栈的团队,有被各方依赖的觉悟,要有“经常被凌晨 3 点的闹钟吵醒”的心理准备就好。微服务更加强调的是确实有必要技术异构时,应能够有选择“不统一”的权利,譬如不应该强迫 Node.js 去开发报表页面,要做人工智能训练模型时,应该可以选择 Python,等等。
- 通过服务来实现独立自治的组件(Componentization via Services)。之所以强调通过“服务”(Service)而不是“类库”(Library)来构建组件,是因为类库在编译期静态链接到程序中,通过本地调用来提供功能,而服务是进程外组件,通过远程调用来提供功能。前面的文章里我们已经分析过,尽管远程服务有更高昂的调用成本,但这是为组件带来隔离与自治能力的必要代价。
- 产品化思维(Products not Projects)。避免把软件研发视作要去完成某种功能,而是视作一种持续改进、提升的过程。譬如,不应该把运维只看作运维团队的事,把开发只看作开发团队的事,团队应该为软件产品的整个生命周期负责,开发者不仅应该知道软件如何开发,还应该知道它如何运作,用户如何反馈,乃至售后支持工作是怎样进行的。注意,这里服务的用户不一定是最终用户,也可能是消费这个服务的另外一个服务。以前在单体架构下,程序的规模决定了无法让全部人员都关注完整的产品,组织中会有开发、运维、支持等细致的分工的成员,各人只关注于自己的一块工作,但在微服务下,要求开发团队中每个人都具有产品化思维,关心整个产品的全部方面是具有可行性的。
- 数据去中心化(Decentralized Data Management)。微服务明确地提倡数据应该按领域分散管理、更新、维护、存储,在单体服务中,一个系统的各个功能模块通常会使用同一个数据库,诚然中心化的存储天生就更容易避免一致性问题,但是,同一个数据实体在不同服务的视角里,它的抽象形态往往也是不同的。譬如,Bookstore 应用中的书本,在销售领域中关注的是价格,在仓储领域中关注的库存数量,在商品展示领域中关注的是书籍的介绍信息,如果作为中心化的存储,所有领域都必须修改和映射到同一个实体之中,这便使得不同的服务很可能会互相产生影响而丧失掉独立性。尽管在分布式中要处理好一致性的问题也相当困难,很多时候都没法使用传统的事务处理来保证,但是两害相权取其轻,有一些必要的代价仍是值得付出的。
- 强终端弱管道(Smart Endpoint and Dumb Pipe)。弱管道(Dumb Pipe)几乎算是直接指名道姓地反对 SOAP 和 ESB 的那一堆复杂的通信机制。ESB 可以处理消息的编码加工、业务规则转换等;BPM 可以集中编排企业业务服务;SOAP 有几十个 WS-*协议族在处理事务、一致性、认证授权等一系列工作,这些构筑在通信管道上的功能也许对某个系统中的某一部分服务是有必要的,但对于另外更多的服务则是强加进来的负担。如果服务需要上面的额外通信能力,就应该在服务自己的 Endpoint 上解决,而不是在通信管道上一揽子处理。微服务提倡类似于经典 UNIX 过滤器那样简单直接的通信方式,RESTful 风格的通信在微服务中会是更加合适的选择。
- 容错性设计(Design for Failure)。不再虚幻地追求服务永远稳定,而是接受服务总会出错的现实,要求在微服务的设计中,有自动的机制对其依赖的服务能够进行快速故障检测,在持续出错的时候进行隔离,在服务恢复的时候重新联通。所以“断路器”这类设施,对实际生产环境的微服务来说并不是可选的外围组件,而是一个必须的支撑点,如果没有容错性的设计,系统很容易就会被因为一两个服务的崩溃所带来的雪崩效应淹没。可靠系统完全可能由会出错的服务组成,这是微服务最大的价值所在,也是这部开源文档标题“凤凰架构”的含义。
- 演进式设计(Evolutionary Design)。容错性设计承认服务会出错,演进式设计则是承认服务会被报废淘汰。一个设计良好的服务,应该是能够报废的,而不是期望得到长存永生。假如系统中出现不可更改、无可替代的服务,这并不能说明这个服务是多么的优秀、多么的重要,反而是一种系统设计上脆弱的表现,微服务所追求的独立、自治,也是反对这种脆弱性的表现。
- 基础设施自动化(Infrastructure Automation)。基础设施自动化,如 CI/CD 的长足发展,显著减少了构建、发布、运维工作的复杂性。由于微服务下运维的对象比起单体架构要有数量级的增长,使用微服务的团队更加依赖于基础设施的自动化,人工是很难支撑成百上千乃至成千上万级别的服务的。
《Microservices》一文中对微服务特征的描写已经相当具体了,文中除了定义微服务是什么,还专门申明了微服务不是什么——微服务不是 SOA 的变体或衍生品,应该明确地与 SOA 划清了界线,不再贴上任何 SOA 的标签。如此,微服务的概念才算是一种真正丰满、独立的架构风格,为它在未来的几年时间里如明星一般闪耀崛起于技术舞台铺下了理论基础。
从上至下 从客户端到服务端
0、反向代理 nginx (应用层负载均衡)
1、服务发现 Nacos
1.1 RPC 远程调用 (负载均衡)
2、api网关 spring Gateway (过滤)
- 流量控制 -
- 限流 sentinel
- 可靠性 - 容错
- 容错设计模式 - 断路器 - 熔断降级、壁仓、
- 容错策略
- 可观测性
- 链路追踪
- 追踪
- 跨度
- 日志 – 在
- 输入
- 加工 ELK
- 聚合
- 存储
- metric - 度量
- 链路追踪
3、验证授权 – 可靠网络
-
4、
———第一章《演进中的架构》———
1.1原始分布式式时代
1.2单体系统时代
1.3SOA时代
1.4微服务时代
微服务的九个核心的业务与技术特征,下面将其一一列出并解读。
- 围绕业务能力构建(Organized around Business Capability)。这里再次强调了康威定律的重要性,有怎样结构、规模、能力的团队,就会产生出对应结构、规模、能力的产品。这个结论不是某个团队、某个公司遇到的巧合,而是必然的演化结果。如果本应该归属同一个产品内的功能被划分在不同团队中,必然会产生大量的跨团队沟通协作,跨越团队边界无论在管理、沟通、工作安排上都有更高昂的成本,高效的团队自然会针对其进行改进,当团队、产品磨合调节稳定之后,团队与产品就会拥有一致的结构。
- 分散治理(Decentralized Governance)。这是要表达“谁家孩子谁来管”的意思,服务对应的开发团队有直接对服务运行质量负责的责任,也应该有着不受外界干预地掌控服务各个方面的权力,譬如选择与其他服务异构的技术来实现自己的服务。这一点在真正实践时多少存有宽松的处理余地,大多数公司都不会在某一个服务使用 Java,另一个用 Python,下一个用 Golang,而是通常会有统一的主流语言,乃至统一的技术栈或专有的技术平台。微服务不提倡也并不反对这种“统一”,只要负责提供和维护基础技术栈的团队,有被各方依赖的觉悟,要有“经常被凌晨 3 点的闹钟吵醒”的心理准备就好。微服务更加强调的是确实有必要技术异构时,应能够有选择“不统一”的权利,譬如不应该强迫 Node.js 去开发报表页面,要做人工智能训练模型时,应该可以选择 Python,等等。
- 通过服务来实现独立自治的组件(Componentization via Services)。之所以强调通过“服务”(Service)而不是“类库”(Library)来构建组件,是因为类库在编译期静态链接到程序中,通过本地调用来提供功能,而服务是进程外组件,通过远程调用来提供功能。前面的文章里我们已经分析过,尽管远程服务有更高昂的调用成本,但这是为组件带来隔离与自治能力的必要代价。
- 产品化思维(Products not Projects)。避免把软件研发视作要去完成某种功能,而是视作一种持续改进、提升的过程。譬如,不应该把运维只看作运维团队的事,把开发只看作开发团队的事,团队应该为软件产品的整个生命周期负责,开发者不仅应该知道软件如何开发,还应该知道它如何运作,用户如何反馈,乃至售后支持工作是怎样进行的。注意,这里服务的用户不一定是最终用户,也可能是消费这个服务的另外一个服务。以前在单体架构下,程序的规模决定了无法让全部人员都关注完整的产品,组织中会有开发、运维、支持等细致的分工的成员,各人只关注于自己的一块工作,但在微服务下,要求开发团队中每个人都具有产品化思维,关心整个产品的全部方面是具有可行性的。
- 数据去中心化(Decentralized Data Management)。微服务明确地提倡数据应该按领域分散管理、更新、维护、存储,在单体服务中,一个系统的各个功能模块通常会使用同一个数据库,诚然中心化的存储天生就更容易避免一致性问题,但是,同一个数据实体在不同服务的视角里,它的抽象形态往往也是不同的。譬如,Bookstore 应用中的书本,在销售领域中关注的是价格,在仓储领域中关注的库存数量,在商品展示领域中关注的是书籍的介绍信息,如果作为中心化的存储,所有领域都必须修改和映射到同一个实体之中,这便使得不同的服务很可能会互相产生影响而丧失掉独立性。尽管在分布式中要处理好一致性的问题也相当困难,很多时候都没法使用传统的事务处理来保证,但是两害相权取其轻,有一些必要的代价仍是值得付出的。
- 强终端弱管道(Smart Endpoint and Dumb Pipe)。弱管道(Dumb Pipe)几乎算是直接指名道姓地反对 SOAP 和 ESB 的那一堆复杂的通信机制。ESB 可以处理消息的编码加工、业务规则转换等;BPM 可以集中编排企业业务服务;SOAP 有几十个 WS-*协议族在处理事务、一致性、认证授权等一系列工作,这些构筑在通信管道上的功能也许对某个系统中的某一部分服务是有必要的,但对于另外更多的服务则是强加进来的负担。如果服务需要上面的额外通信能力,就应该在服务自己的 Endpoint 上解决,而不是在通信管道上一揽子处理。微服务提倡类似于经典 UNIX 过滤器那样简单直接的通信方式,RESTful 风格的通信在微服务中会是更加合适的选择。
- 容错性设计(Design for Failure)。不再虚幻地追求服务永远稳定,而是接受服务总会出错的现实,要求在微服务的设计中,有自动的机制对其依赖的服务能够进行快速故障检测,在持续出错的时候进行隔离,在服务恢复的时候重新联通。所以“断路器”这类设施,对实际生产环境的微服务来说并不是可选的外围组件,而是一个必须的支撑点,如果没有容错性的设计,系统很容易就会被因为一两个服务的崩溃所带来的雪崩效应淹没。可靠系统完全可能由会出错的服务组成,这是微服务最大的价值所在,也是这部开源文档标题“凤凰架构”的含义。
- 演进式设计(Evolutionary Design)。容错性设计承认服务会出错,演进式设计则是承认服务会被报废淘汰。一个设计良好的服务,应该是能够报废的,而不是期望得到长存永生。假如系统中出现不可更改、无可替代的服务,这并不能说明这个服务是多么的优秀、多么的重要,反而是一种系统设计上脆弱的表现,微服务所追求的独立、自治,也是反对这种脆弱性的表现。
- 基础设施自动化(Infrastructure Automation)。基础设施自动化,如 CI/CD 的长足发展,显著减少了构建、发布、运维工作的复杂性。由于微服务下运维的对象比起单体架构要有数量级的增长,使用微服务的团队更加依赖于基础设施的自动化,人工是很难支撑成百上千乃至成千上万级别的服务的。
1.5后微服务时代
———第二章《架构师视角》———
2.1访问远程服务
2.1.2 远程服务调用
进程间通信
这件事情在计算机科学中被称为“进程间通信 (opens new window)”(Inter-Process Communication,IPC)。可以考虑的办法有以下几种。
管道(Pipe)或者具名管道(Named Pipe):管道类似于两个进程间的桥梁,可通过管道在进程间传递少量的字符流或字节流。普通管道只用于有亲缘关系进程(由一个进程启动的另外一个进程)间的通信,具名管道摆脱了普通管道没有名字的限制,除具有管道所有的功能外,它还允许无亲缘关系进程间的通信。管道典型的应用就是命令行中的
|操作符,譬如:1
ps -ef | grep javaps与grep都有独立的进程,以上命令就通过管道操作符|将ps命令的标准输出连接到grep命令的标准输入上。信号(Signal):信号用于通知目标进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程自身。信号的典型应用是
kill命令,譬如:1
kill -9 pid以上就是由 Shell 进程向指定 PID 的进程发送 SIGKILL 信号。
信号量(Semaphore):信号量用于两个进程之间同步协作手段,它相当于操作系统提供的一个特殊变量,程序可以在上面进行
wait()和notify()操作。消息队列(Message Queue):以上三种方式只适合传递传递少量信息,POSIX 标准中定义了消息队列用于进程间数据量较多的通信。进程可以向队列添加消息,被赋予读权限的进程则可以从队列消费消息。消息队列克服了信号承载信息量少,管道只能用于无格式字节流以及缓冲区大小受限等缺点,但实时性相对受限。
共享内存(Shared Memory):允许多个进程访问同一块公共的内存空间,这是效率最高的进程间通信形式。原本每个进程的内存地址空间都是相互隔离的,但操作系统提供了让进程主动创建、映射、分离、控制某一块内存的程序接口。当一块内存被多进程共享时,各个进程往往会与其它通信机制,譬如信号量结合使用,来达到进程间同步及互斥的协调操作。
套接字接口(Socket):消息队列和共享内存只适合单机多进程间的通信,套接字接口是更为普适的进程间通信机制,可用于不同机器之间的进程通信。套接字(Socket)起初是由 UNIX 系统的 BSD 分支开发出来的,现在已经移植到所有主流的操作系统上。出于效率考虑,当仅限于本机进程间通信时,套接字接口是被优化过的,不会经过网络协议栈,不需要打包拆包、计算校验和、维护序号和应答等操作,只是简单地将应用层数据从一个进程拷贝到另一个进程,这种进程间通信方式有个专名的名称:UNIX Domain Socket,又叫做 IPC Socket。
基于套接字接口的通信方式(IPC Socket),它不仅适用于本地相同机器的不同进程间通信,由于 Socket 是网络栈的统一接口,它也理所当然地能支持基于网络的跨机器的进程间通信。
通信的成本
通过网络进行分布式运算的八宗罪 (opens new window)(8 Fallacies of Distributed Computing):
- The network is reliable —— 网络是可靠的。
- Latency is zero —— 延迟是不存在的。
- Bandwidth is infinite —— 带宽是无限的。
- The network is secure —— 网络是安全的。
- Topology doesn’t change —— 拓扑结构是一成不变的。
- There is one administrator —— 总会有一个管理员。
- Transport cost is zero —— 不必考虑传输成本。
- The network is homogeneous —— 网络是同质化的。
RPC 中的三个基本问题
变着花样使用各种手段来解决以下三个基本问题:
如何表示数据
:这里数据包括了传递给方法的参数,以及方法执行后的返回值。无论是将参数传递给另外一个进程,还是从另外一个进程中取回执行结果,都涉及到它们应该如何表示。进程内的方法调用,使用程序语言预置的和程序员自定义的数据类型,就很容易解决数据表示问题,远程方法调用则完全可能面临交互双方各自使用不同程序语言的情况;即使只支持一种程序语言的 RPC 协议,在不同硬件指令集、不同操作系统下,同样的数据类型也完全可能有不一样表现细节,譬如数据宽度、字节序的差异等等。有效的做法是将交互双方所涉及的数据转换为某种事先约定好的中立数据流格式来进行传输,将数据流转换回不同语言中对应的数据类型来进行使用,这个过程说起来拗口,但相信大家一定很熟悉,就是序列化与反序列化。每种 RPC 协议都应该要有对应的序列化协议,譬如:
- ONC RPC 的External Data Representation (opens new window)(XDR)
- CORBA 的Common Data Representation (opens new window)(CDR)
- Java RMI 的Java Object Serialization Stream Protocol(opens new window)
- gRPC 的Protocol Buffers(opens new window)
- Web Service 的XML Serialization(opens new window)
- 众多轻量级 RPC 支持的JSON Serialization(opens new window)
- ……
如何传递数据
:准确地说,是指如何通过网络,在两个服务的 Endpoint 之间相互操作、交换数据。这里“交换数据”通常指的是应用层协议,实际传输一般是基于标准的 TCP、UDP 等标准的传输层协议来完成的。
两个服务交互不是只扔个序列化数据流来表示参数和结果就行的,许多在此之外信息,譬如异常、超时、安全、认证、授权、事务,等等,都可能产生双方需要交换信息的需求。在计算机科学中,专门有一个名称“Wire Protocol (opens new window)”来用于表示这种两个 Endpoint 之间交换这类数据的行为,常见的 Wire Protocol 有:
- Java RMI 的Java Remote Message Protocol (opens new window)(JRMP,也支持RMI-IIOP (opens new window))
- CORBA 的Internet Inter ORB Protocol (opens new window)(IIOP,是 GIOP 协议在 IP 协议上的实现版本)
- DDS 的Real Time Publish Subscribe Protocol (opens new window)(RTPS)
- Web Service 的Simple Object Access Protocol (opens new window)(SOAP)
- 如果要求足够简单,双方都是 HTTP Endpoint,直接使用 HTTP 协议也是可以的(如 JSON-RPC)
- ……
如何确定方法
:这在本地方法调用中并不是太大的问题,编译器或者解释器会根据语言规范,将调用的方法签名转换为进程空间中子过程入口位置的指针。不过一旦要考虑不同语言,事情又立刻麻烦起来,每门语言的方法签名都可能有所差别,所以“如何表示同一个方法”,“如何找到对应的方法”还是得弄个跨语言的统一的标准才行。这个标准做起来可以非常简单,譬如直接给程序的每个方法都规定一个唯一的、在任何机器上都绝不重复的编号,调用时压根不管它什么方法签名是如何定义的,直接传这个编号就能找到对应的方法。这种听起既粗鲁又寒碜的办法,还真的就是 DCE/RPC 当初准备的解决方案。虽然最终 DCE 还是弄出了一套语言无关的接口描述语言 (opens new window)(Interface Description Language,IDL),成为此后许多 RPC 参考或依赖的基础(如 CORBA 的 OMG IDL),但那个唯一的绝不重复的编码方案
UUID (opens new window)
(Universally Unique Identifier)却也被保留且广为流传开来,今天已广泛应用于程序开发的方方面面。类似地,用于表示方法的协议还有:
- Android 的Android Interface Definition Language (opens new window)(AIDL)
- CORBA 的OMG Interface Definition Language (opens new window)(OMG IDL)
- Web Service 的Web Service Description Language (opens new window)(WSDL)
- JSON-RPC 的JSON Web Service Protocol (opens new window)(JSON-WSP)
2.1.2 REST 设计风格
理解REST
REST 所说的“表征状态转移”
从“超文本”或者“超媒体”的含义来理解什么是“表征”以及 REST 中其他关键概念,这里使用一个具体事例将其描述如下。
- 资源(Resource):譬如你现在正在阅读一篇名为《REST 设计风格》的文章,这篇文章的内容本身(你可以将其理解为其蕴含的信息、数据)我们称之为“资源”。无论你是购买的书籍、是在浏览器看的网页、是打印出来看的文稿、是在电脑屏幕上阅读抑或是手机上浏览,尽管呈现的样子各不相同,但其中的信息是不变的,你所阅读的仍是同一份“资源”。
- 表征(Representation):当你通过电脑浏览器阅读此文章时,浏览器向服务端发出请求“我需要这个资源的 HTML 格式”,服务端向浏览器返回的这个 HTML 就被称之为“表征”,你可能通过其他方式拿到本文的 PDF、Markdown、RSS 等其他形式的版本,它们也同样是一个资源的多种表征。可见“表征”这个概念是指信息与用户交互时的表示形式,这与我们软件分层架构中常说的“表示层”(Presentation Layer)的语义其实是一致的。
- 状态(State):当你读完了这篇文章,想看后面是什么内容时,你向服务器发出请求“给我下一篇文章”。但是“下一篇”是个相对概念,必须依赖“当前你正在阅读的文章是哪一篇”才能正确回应,这类在特定语境中才能产生的上下文信息即被称为“状态”。我们所说的有状态(Stateful)抑或是无状态(Stateless),都是只相对于服务端来说的,服务器要完成“取下一篇”的请求,要么自己记住用户的状态:这个用户现在阅读的是哪一篇文章,这称为有状态;要么客户端来记住状态,在请求的时候明确告诉服务器:我正在阅读某某文章,现在要读它的下一篇,这称为无状态。
- 转移(Transfer):无论状态是由服务端还是客户端来提供的,“取下一篇文章”这个行为逻辑必然只能由服务端来提供,因为只有服务端拥有该资源及其表征形式。服务器通过某种方式,把“用户当前阅读的文章”转变成“下一篇文章”,这就被称为“表征状态转移”。
RESTful 的系统
资源 与 服务:REST 提出以资源为主体进行服务设计的风格
Fielding 认为,一套理想的、完全满足 REST 风格的系统应该满足以下六大原则。
- 服务端与客户端分离(Client-Server)
将用户界面所关注的逻辑和数据存储所关注的逻辑分离开来,有助于提高用户界面的跨平台的可移植性,这一点正越来越受到广大开发者所认可,以前完全基于服务端控制和渲染(如 JSF 这类)框架实际用户已甚少,而在服务端进行界面控制(Controller),通过服务端或者客户端的模版渲染引擎来进行界面渲染的框架(如 Struts、SpringMVC 这类)也受到了颇大的冲击。这一点主要推动力量与 REST 可能关系并不大,前端技术(从 ES 规范,到语言实现,到前端框架等)的近年来的高速发展,使得前端表达能力大幅度加强才是真正的幕后推手。由于前端的日渐强势,现在还流行起由前端代码反过来驱动服务端进行渲染的 SSR(Server-Side Rendering)技术,在 Serverless、SEO 等场景中已经占领了一块领地。 - 无状态(Stateless)
无状态是 REST 的一条核心原则,部分开发者在做服务接口规划时,觉得 REST 风格的服务怎么设计都感觉别扭,很有可能的一种原因是在服务端持有着比较重的状态。REST 希望服务器不要去负责维护状态,每一次从客户端发送的请求中,应包括所有的必要的上下文信息,会话信息也由客户端负责保存维护,服务端依据客户端传递的状态来执行业务处理逻辑,驱动整个应用的状态变迁。客户端承担状态维护职责以后,会产生一些新的问题,譬如身份认证、授权等可信问题,它们都应有针对性的解决方案(这部分内容可参见“安全架构”的内容)。
但必须承认的现状是,目前大多数的系统都达不到这个要求,往往越复杂、越大型的系统越是如此。服务端无状态可以在分布式计算中获得非常高价值的好处,但大型系统的上下文状态数量完全可能膨胀到让客户端在每次请求时提供变得不切实际的程度,在服务端的内存、会话、数据库或者缓存等地方持有一定的状态成为一种是事实上存在,并将长期存在、被广泛使用的主流的方案。 - 可缓存(Cacheability)
无状态服务虽然提升了系统的可见性、可靠性和可伸缩性,但降低了系统的网络性。“降低网络性”的通俗解释是某个功能如果使用有状态的设计只需要一次(或少量)请求就能完成,使用无状态的设计则可能会需要多次请求,或者在请求中带有额外冗余的信息。为了缓解这个矛盾,REST 希望软件系统能够如同万维网一样,允许客户端和中间的通讯传递者(譬如代理)将部分服务端的应答缓存起来。当然,为了缓存能够正确地运作,服务端的应答中必须明确地或者间接地表明本身是否可以进行缓存、可以缓存多长时间,以避免客户端在将来进行请求的时候得到过时的数据。运作良好的缓存机制可以减少客户端、服务器之间的交互,甚至有些场景中可以完全避免交互,这就进一步提高了性能。 - 分层系统(Layered System)
这里所指的并不是表示层、服务层、持久层这种意义上的分层。而是指客户端一般不需要知道是否直接连接到了最终的服务器,抑或连接到路径上的中间服务器。中间服务器可以通过负载均衡和共享缓存的机制提高系统的可扩展性,这样也便于缓存、伸缩和安全策略的部署。该原则的典型的应用是内容分发网络(Content Distribution Network,CDN)。如果你是通过网站浏览到这篇文章的话,你所发出的请求一般(假设你在中国国境内的话)并不是直接访问位于 GitHub Pages 的源服务器,而是访问了位于国内的 CDN 服务器,但作为用户,你完全不需要感知到这一点。我们将在“透明多级分流系统”中讨论如何构建自动的、可缓存的分层系统。 - 统一接口(Uniform Interface)
这是 REST 的另一条核心原则,REST 希望开发者面向资源编程,希望软件系统设计的重点放在抽象系统该有哪些资源上,而不是抽象系统该有哪些行为(服务)上。这条原则你可以类比计算机中对文件管理的操作来理解,管理文件可能会进行创建、修改、删除、移动等操作,这些操作数量是可数的,而且对所有文件都是固定的、统一的。如果面向资源来设计系统,同样会具有类似的操作特征,由于 REST 并没有设计新的协议,所以这些操作都借用了 HTTP 协议中固有的操作命令来完成。
统一接口也是 REST 最容易陷入争论的地方,基于网络的软件系统,到底是面向资源更好,还是面向服务更合适,这事情哪怕是很长时间里都不会有个定论,也许永远都没有。但是,已经有一个基本清晰的结论是:面向资源编程的抽象程度通常更高。抽象程度高意味着坏处是往往距离人类的思维方式更远,而好处是往往通用程度会更好。用这样的语言去诠释 REST,大概本身就挺抽象的,笔者还是举个例子来说明:譬如,几乎每个系统都有的登录和注销功能,如果你理解成登录对应于 login()服务,注销对应于 logout()服务这样两个独立服务,这是“符合人类思维”的;如果你理解成登录是 PUT Session,注销是 DELETE Session,这样你只需要设计一种“Session 资源”即可满足需求,甚至以后对 Session 的其他需求,如查询登陆用户的信息,就是 GET Session 而已,其他操作如修改用户信息等都可以被这同一套设计囊括在内,这便是“抽象程度更高”带来的好处。
想要在架构设计中合理恰当地利用统一接口,Fielding 建议系统应能做到每次请求中都包含资源的 ID,所有操作均通过资源 ID 来进行;建议每个资源都应该是自描述的消息;建议通过超文本来驱动应用状态的转移。 - 按需代码(Code-On-Demand (opens new window))
按需代码被 Fielding 列为一条可选原则。它是指任何按照客户端(譬如浏览器)的请求,将可执行的软件程序从服务器发送到客户端的技术,按需代码赋予了客户端无需事先知道所有来自服务端的信息应该如何处理、如何运行的宽容度。举个具体例子,以前的Java Applet (opens new window)技术,今天的WebAssembly (opens new window)等都属于典型的按需代码,蕴含着具体执行逻辑的代码是存放在服务端,只有当客户端请求了某个 Java Applet 之后,代码才会被传输并在客户端机器中运行,结束后通常也会随即在客户端中被销毁掉。将按需代码列为可选原则的原因并非是它特别难以达到,而更多是出于必要性和性价比的实际考虑。
RMM 的成熟度
描述是这样的:
医生预约系统
作为一名病人,我想要从系统中得知指定日期内我熟悉的医生是否具有空闲时间,以便于我向该医生预约就诊。
第 0 级
医院开放了一个/appointmentService的 Web API,传入日期、医生姓名作为参数,可以得到该时间段该名医生的空闲时间,该 API 的一次 HTTP 调用如下所示:
1 | |
然后服务器会传回一个包含了所需信息的回应:
1 | |
得到了医生空闲的结果后,我觉得 14:00 的时间比较合适,于是进行预约确认,并提交了我的基本信息:
1 | |
如果预约成功,那我能够收到一个预约成功的响应:
1 | |
如果发生了问题,譬如有人在我前面抢先预约了,那么我会在响应中收到某种错误信息:
1 | |
到此,整个预约服务宣告完成,直接明了,我们采用的是非常直观的基于 RPC 风格的服务设计似乎很容易就解决了所有问题……了吗?
第 1 级
第 0 级是 RPC 的风格,如果需求永远不会变化,也不会增加,那它完全可以良好地工作下去。但是,如果你不想为预约医生之外的其他操作、为获取空闲时间之外的其他信息去编写额外的方法,或者改动现有方法的接口,那还是应该考虑一下如何使用 REST 来抽象资源。
通往 REST 的第一步是引入资源的概念,在 API 中基本的体现是围绕着资源而不是过程来设计服务,说的直白一点,可以理解为服务的 Endpoint 应该是一个名词而不是动词。此外,每次请求中都应包含资源的 ID,所有操作均通过资源 ID 来进行,譬如,获取医生指定时间的空闲档期:
1 | |
然后服务器传回一组包含了 ID 信息的档期清单,注意,ID 是资源的唯一编号,有 ID 即代表“医生的档期”被视为一种资源:
1 | |
我还是觉得 14:00 的时间比较合适,于是又进行预约确认,并提交了我的基本信息:
1 | |
后面预约成功或者失败的响应消息在这个级别里面与之前一致,就不重复了。比起第 0 级,第 1 级的特征是引入了资源,通过资源 ID 作为主要线索与服务交互,但第 1 级至少还有三个问题并没有解决:一是只处理了查询和预约,如果我临时想换个时间,要调整预约,或者我的病忽然好了,想删除预约,这都需要提供新的服务接口。二是处理结果响应时,只能靠着结果中的code、message这些字段做分支判断,每一套服务都要设计可能发生错误的 code,这很难考虑全面,而且也不利于对某些通用的错误做统一处理;三是并没有考虑认证授权等安全方面的内容,譬如要求只有登陆用户才允许查询医生档期时间,某些医生可能只对 VIP 开放,需要特定级别的病人才能预约,等等。
第 2 级
第 1 级遗留三个问题都可以靠引入统一接口来解决。HTTP 协议的七个标准方法是经过精心设计的,只要架构师的抽象能力够用,它们几乎能涵盖资源可能遇到的所有操作场景。REST 的做法是把不同业务需求抽象为对资源的增加、修改、删除等操作来解决第一个问题;使用 HTTP 协议的 Status Code,可以涵盖大多数资源操作可能出现的异常,而且 Status Code 可以自定义扩展,以此解决第二个问题;依靠 HTTP Header 中携带的额外认证、授权信息来解决第三个问题,这个在实战中并没有体现,请参考安全架构中的“凭证”相关内容。
按这个思路,获取医生档期,应采用具有查询语义的 GET 操作进行:
1 | |
然后服务器会传回一个包含了所需信息的回应:
1 | |
我仍然觉得 14:00 的时间比较合适,于是又进行预约确认,并提交了我的基本信息,用以创建预约,这是符合 POST 的语义的:
1 | |
如果预约成功,那我能够收到一个预约成功的响应:
1 | |
如果发生了问题,譬如有人在我前面抢先预约了,那么我会在响应中收到某种错误信息:
1 | |
第 3 级
第 2 级是目前绝大多数系统所到达的 REST 级别,但仍不是完美的,至少还存在一个问题:你是如何知道预约 mjones 医生的档期是需要访问/schedules/1234这个服务 Endpoint 的?也许你甚至第一时间无法理解为何我会有这样的疑问,这当然是程序代码写的呀!但 REST 并不认同这种已烙在程序员脑海中许久的想法。RMM 中的 Hypermedia Controls、Fielding 论文中的 HATEOAS 和现在提的比较多的“超文本驱动”,所希望的是除了第一个请求是有你在浏览器地址栏输入所驱动之外,其他的请求都应该能够自己描述清楚后续可能发生的状态转移,由超文本自身来驱动。所以,当你输入了查询的指令之后:
1 | |
服务器传回的响应信息应该包括诸如如何预约档期、如何了解医生信息等可能的后续操作:
1 | |
如果做到了第 3 级 REST,那服务端的 API 和客户端也是完全解耦的,你要调整服务数量,或者同一个服务做 API 升级将会变得非常简单。
不足和争议
以下是笔者所见过的怀疑 REST 能否在实践中真正良好应用的部分争议问题,笔者将自己的观点总结如下:
- 面向资源的编程思想只适合做 CRUD,面向过程、面向对象编程才能处理真正复杂的业务逻辑
- REST 与 HTTP 完全绑定,不适合应用于要求高性能传输的场景中
- REST 不利于事务支持
这个问题首先要看你怎么看待“事务(Transaction)”这个概念。如果“事务”指的是数据库那种的狭义的刚性 ACID 事务,那除非完全不持有状态,否则分布式系统本身与此就是有矛盾的(CAP 不可兼得),这是分布式的问题而不是 REST 的问题。如果“事务”是指通过服务协议或架构,在分布式服务中,获得对多个数据同时提交的统一协调能力(2PC/3PC),譬如WS-AtomicTransaction (opens new window)、WS-Coordination (opens new window)这样的功能性协议,这 REST 确实不支持,假如你已经理解了这样做的代价,仍决定要这样做的话,Web Service 是比较好的选择。如果“事务”只是指希望保障数据的最终一致性,说明你已经放弃刚性事务了,这才是分布式系统中的正常交互方式,使用 REST 肯定不会有什么阻碍,谈不上“不利于”。当然,对此 REST 也并没有什么帮助,这完全取决于你系统的事务设计,我们会在事务处理中再详细讨论。 - REST 没有传输可靠性支持
是的,并没有。在 HTTP 中你发送出去一个请求,通常会收到一个与之相对的响应,譬如 HTTP/1.1 200 OK 或者 HTTP/1.1 404 Not Found 诸如此类的。但如果你没有收到任何响应,那就无法确定消息到底是没有发送出去,抑或是没有从服务端返回回来,这其中的关键差别是服务端到底是否被触发了某些处理?应对传输可靠性最简单粗暴的做法是把消息再重发一遍。这种简单处理能够成立的前提是服务应具有幂等性 (opens new window)(Idempotency),即服务被重复执行多次的效果与执行一次是相等的。HTTP 协议要求 GET、PUT 和 DELETE 应具有幂等性,我们把 REST 服务映射到这些方法时,也应当保证幂等性。对于 POST 方法,曾经有过一些专门的提案(如POE (opens new window),POST Once Exactly),但并未得到 IETF 的通过。对于 POST 的重复提交,浏览器会出现相应警告,如 Chrome 中“确认重新提交表单”的提示,对于服务端,就应该做预校验,如果发现可能重复,返回 HTTP/1.1 425 Too Early。另,Web Service 中有WS-ReliableMessaging (opens new window)功能协议用于支持消息可靠投递。类似的,由于 REST 没有采用额外的 Wire Protocol,所以除了事务、可靠传输这些功能以外,一定还可以在 WS-*协议中找到很多 REST 不支持的特性。 - REST 缺乏对资源进行“部分”和“批量”的处理能力
这个观点笔者是认同的,这很可能是未来面向资源的思想和 API 设计风格的发展方向。REST 开创了面向资源的服务风格,却肯定仍并不完美。以 HTTP 协议为基础给 REST 带来了极大的便捷(不需要额外协议,不需要重复解决一堆基础网络问题,等等),但也是 HTTP 本身成了束缚 REST 的无形牢笼。这里仍通过具体例子来解释 REST 这方面的局限性:譬如你仅仅想获得某个用户的姓名,RPC 风格中可以设计一个“getUsernameById”的服务,返回一个字符串,尽管这种服务的通用性实在称不上“设计”二字,但确实可以工作;而 REST 风格中你将向服务端请求整个用户对象,然后丢弃掉返回的结果中该用户除用户名外的其他属性,这便是一种“过度获取”(Overfetching)。REST 的应对手段是通过位于中间节点或客户端的缓存来缓解这种问题,但此缺陷的本质是由于 HTTP 协议完全没有对请求资源的结构化描述能力(但有非结构化的部分内容获取能力,即今天多用于断点续传的Range Header (opens new window)),所以返回资源的哪些内容、以什么数据类型返回等等,都不可能得到协议层面的支持,要做你就只能自己在 GET 方法的 Endpoint 上设计各种参数来实现。而另外一方面,与此相对的缺陷是对资源的批量操作的支持,有时候我们不得不为此而专门设计一些抽象的资源才能应对。譬如你准备把某个用户的名字增加一个“VIP”前缀,提交一个 PUT 请求修改这个用户的名称即可,而你要给 1000 个用户加 VIP 时,如果真的去调用 1000 次 PUT,浏览器会回应你 HTTP/1.1 429 Too Many Requests,老板则会揍你一顿。此时,你就不得不先创建一个(如名为“VIP-Modify-Task”)任务资源,把 1000 个用户的 ID 交给这个任务,最后驱动任务进入执行状态。又譬如你去网店买东西,下单、冻结库存、支付、加积分、扣减库存这一系列步骤会涉及到多个资源的变化,你可能面临不得不创建一种“事务”的抽象资源,或者用某种具体的资源(譬如“结算单”)贯穿这个过程的始终,每次操作其他资源时都带着事务或者结算单的 ID。HTTP 协议由于本身的无状态性,会相对不适应(并非不能够)处理这类业务场景。
目前,一种理论上较优秀的可以解决以上这几类问题的方案是GraphQL (opens new window),这是由 Facebook 提出并开源的一种面向资源 API 的数据查询语言,如同 SQL 一样,挂了个“查询语言”的名字,但其实 CRUD 都有涉猎。比起依赖 HTTP 无协议的 REST,GraphQL 可以说是另一种“有协议”的、更彻底地面向资源的服务方式。然而凡事都有两面,离开了 HTTP,它又面临着几乎所有 RPC 框架所遇到的那个如何推广交互接口的问题。
2.2事务处理
2.2.1 本地事务
2.2.2全局事务
XA 事务
为了解决分布式事务的一致性问题,X/Open组织(后来并入了The Open Group)提出了一套名为X/Open XA(XA 是 eXtended Architecture 的缩写)的处理事务架构,其核心内容是定义了全局的事务管理器(Transaction Manager,用于协调全局事务)和局部的资源管理器(Resource Manager,用于驱动本地事务)之间的通信接口。XA 接口是双向的,能在一个事务管理器和多个资源管理器(Resource Manager)之间形成通信桥梁,通过协调多个数据源的一致动作,实现全局事务的统一提交或者统一回滚,现在我们在 Java 代码中还偶尔能看见的 XADataSource、XAResource 这些名字都源于此。
不过,XA 并不是 Java 的技术规范(XA 提出那时还没有 Java),而是一套语言无关的通用规范,所以 Java 中专门定义了JSR 907 Java Transaction API,基于 XA 模式在 Java 语言中的实现了全局事务处理的标准,这也就是我们现在所熟知的 JTA。JTA 最主要的两个接口是:
- 事务管理器的接口:
javax.transaction.TransactionManager。这套接口是给 Java EE 服务器提供容器事务(由容器自动负责事务管理)使用的,还提供了另外一套javax.transaction.UserTransaction接口,用于通过程序代码手动开启、提交和回滚事务。 - 满足 XA 规范的资源定义接口:
javax.transaction.xa.XAResource,任何资源(JDBC、JMS 等等)如果想要支持 JTA,只要实现 XAResource 接口中的方法即可。
JTA 原本是 Java EE 中的技术,一般情况下应该由 JBoss、WebSphere、WebLogic 这些 Java EE 容器来提供支持,但现在Bittronix、Atomikos和JBossTM(以前叫 Arjuna)都以 JAR 包的形式实现了 JTA 的接口,称为 JOTM(Java Open Transaction Manager),使得我们能够在 Tomcat、Jetty 这样的 Java SE 环境下也能使用 JTA。
2PC
XA 将事务提交拆分成为两阶段过程:
- 准备阶段:又叫作投票阶段,在这一阶段,协调者询问事务的所有参与者是否准备好提交,参与者如果已经准备好提交则回复 Prepared,否则回复 Non-Prepared。这里所说的准备操作跟人类语言中通常理解的准备并不相同,对于数据库来说,准备操作是在重做日志中记录全部事务提交操作所要做的内容,它与本地事务中真正提交的区别只是暂不写入最后一条 Commit Record 而已,这意味着在做完数据持久化后并不立即释放隔离性,即仍继续持有锁,维持数据对其他非事务内观察者的隔离状态。
- 提交阶段:又叫作执行阶段,协调者如果在上一阶段收到所有事务参与者回复的 Prepared 消息,则先自己在本地持久化事务状态为 Commit,在此操作完成后向所有参与者发送 Commit 指令,所有参与者立即执行提交操作;否则,任意一个参与者回复了 Non-Prepared 消息,或任意一个参与者超时未回复,协调者将自己的事务状态持久化为 Abort 之后,向所有参与者发送 Abort 指令,参与者立即执行回滚操作。对于数据库来说,这个阶段的提交操作应是很轻量的,仅仅是持久化一条 Commit Record 而已,通常能够快速完成,只有收到 Abort 指令时,才需要根据回滚日志清理已提交的数据,这可能是相对重负载的操作。
以上这两个过程被称为“两段式提交”(2 Phase Commit,2PC)协议,而它能够成功保证一致性还需要一些其他前提条件。
两段式提交原理简单,并不难实现,但有几个非常显著的缺点:
- 单点问题:协调者在两段提交中具有举足轻重的作用,协调者等待参与者回复时可以有超时机制,允许参与者宕机,但参与者等待协调者指令时无法做超时处理。一旦宕机的不是其中某个参与者,而是协调者的话,所有参与者都会受到影响。如果协调者一直没有恢复,没有正常发送 Commit 或者 Rollback 的指令,那所有参与者都必须一直等待。
- 性能问题:两段提交过程中,所有参与者相当于被绑定成为一个统一调度的整体,期间要经过两次远程服务调用,三次数据持久化(准备阶段写重做日志,协调者做状态持久化,提交阶段在日志写入 Commit Record),整个过程将持续到参与者集群中最慢的那一个处理操作结束为止,这决定了两段式提交的性能通常都较差。
- 一致性风险:前面已经提到,两段式提交的成立是有前提条件的,当网络稳定性和宕机恢复能力的假设不成立时,仍可能出现一致性问题。宕机恢复能力这一点不必多谈,1985 年 Fischer、Lynch、Paterson 提出了“FLP 不可能原理”,证明了如果宕机最后不能恢复,那就不存在任何一种分布式协议可以正确地达成一致性结果。该原理在分布式中是与“CAP 不可兼得原理“齐名的理论。而网络稳定性带来的一致性风险是指:尽管提交阶段时间很短,但这仍是一段明确存在的危险期,如果协调者在发出准备指令后,根据收到各个参与者发回的信息确定事务状态是可以提交的,协调者会先持久化事务状态,并提交自己的事务,如果这时候网络忽然被断开,无法再通过网络向所有参与者发出 Commit 指令的话,就会导致部分数据(协调者的)已提交,但部分数据(参与者的)既未提交,也没有办法回滚,产生了数据不一致的问题。
在三段式提交中,如果在 PreCommit 阶段之后发生了协调者宕机,即参与者没有能等到 DoCommit 的消息的话,默认的操作策略将是提交事务而不是回滚事务或者持续等待,这就相当于避免了协调者单点问题的风险。
3PC
三段式提交”(3 Phase Commit,3PC)协议。三段式提交把原本的两段式提交的准备阶段再细分为两个阶段,分别称为 CanCommit、PreCommit,把提交阶段改称为 DoCommit 阶段。其中,新增的 CanCommit 是一个询问阶段,协调者让每个参与的数据库根据自身状态,评估该事务是否有可能顺利完成。将准备阶段一分为二的理由是这个阶段是重负载的操作,一旦协调者发出开始准备的消息,每个参与者都将马上开始写重做日志,它们所涉及的数据资源即被锁住,如果此时某一个参与者宣告无法完成提交,相当于大家都白做了一轮无用功。所以,增加一轮询问阶段,如果都得到了正面的响应,那事务能够成功提交的把握就比较大了,这也意味着因某个参与者提交时发生崩溃而导致大家全部回滚的风险相对变小。因此,在事务需要回滚的场景中,三段式的性能通常是要比两段式好很多的,但在事务能够正常提交的场景中,两者的性能都依然很差,甚至三段式因为多了一次询问,还要稍微更差一些。
2.2.3共享事务
与全局事务里讨论的单个服务使用多个数据源正好相反,共享事务(Share Transaction)是指多个服务共用同一个数据源。
2.2.4分布式事务
TCC 事务
SAGA 事务
与 TCC 相比,SAGA 不需要为资源设计冻结状态和撤销冻结的操作,补偿操作往往要比冻结操作容易实现得多。
2.3透明多级分流系统
2.3.1客户端缓存
HTTP 的强制缓存对一致性处理的策略就如它的名字一样,十分直接:假设在某个时点到来以前,譬如收到响应后的 10 分钟内,资源的内容和状态一定不会被改变,因此客户端可以无须经过任何请求,在该时点前一直持有和使用该资源的本地缓存副本。
根据约定,强制缓存在浏览器的地址输入、页面链接跳转、新开窗口、前进和后退中均可生效,但在用户主动刷新页面时应当自动失效。HTTP 协议中设有以下两类 Header 实现强制缓存。
强制缓存
Expires:Expires 是 HTTP/1.0 协议中开始提供的 Header,后面跟随一个截至时间参数。当服务器返回某个资源时带有该 Header 的话,意味着服务器承诺截止时间之前资源不会发生变动,浏览器可直接缓存该数据,不再重新发请求,示例:
1
2HTTP/1.1 200 OK
Expires: Wed, 8 Apr 2020 07:28:00 GMTExpires 是 HTTP 协议最初版本中提供的缓存机制,设计非常直观易懂,但考虑得并不够周全,它至少存在以下显而易见的问题:
- 受限于客户端的本地时间。譬如,在收到响应后,客户端修改了本地时间,将时间前后调整几分钟,就可能会造成缓存提前失效或超期持有。
- 无法处理涉及到用户身份的私有资源,譬如,某些资源被登录用户缓存在自己的浏览器上是合理的,但如果被代理服务器或者内容分发网络缓存起来,则可能被其他未认证的用户所获取。
- 无法描述“不缓存”的语义。譬如,浏览器为了提高性能,往往会自动在当次会话中缓存某些 MIME 类型的资源,在 HTTP/1.0 的服务器中就缺乏手段强制浏览器不允许缓存某个资源。以前为了实现这类功能,通常不得不使用脚本,或者手工在资源后面增加时间戳(譬如如“xx.js?t=1586359920”、“xx.jpg?t=1586359350”)来保证每次资源都会重新获取。
关于“不缓存”的语义,在 HTTP/1.0 中其实预留了“Pragma: no-cache”来表达,但 Pragma 参数在 HTTP/1.0 中并没有确切描述其具体行为,随后就被 HTTP/1.1 中出现过的 Cache-Control 所替代,现在,尽管主流浏览器通常都会支持 Pragma,但行为仍然是不确定的,实际并没有什么使用价值。
Cache-Control:Cache-Control 是 HTTP/1.1 协议中定义的强制缓存 Header,它的语义比起 Expires 来说就丰富了很多,如果 Cache-Control 和 Expires 同时存在,并且语义存在冲突(譬如 Expires 与 max-age / s-maxage 冲突)的话,规定必须以 Cache-Control 为准。
协商缓存
强制缓存是基于时效性的,但无论是人还是服务器,其实多数情况下都并没有什么把握去承诺某项资源多久不会发生变化。另外一种基于变化检测的缓存机制,在一致性上会有比强制缓存更好的表现,但需要一次变化检测的交互开销,性能上就会略差一些,这种基于检测的缓存机制,通常被称为“协商缓存”。另外,应注意在 HTTP 中协商缓存与强制缓存并没有互斥性,这两套机制是并行工作的,
- 譬如,当强制缓存存在时,直接从强制缓存中返回资源,无须进行变动检查;
- 而当强制缓存超过时效,或者被禁止(no-cache / must-revalidate),协商缓存仍可以正常地工作。
协商缓存有两种变动检查机制,分别是根据资源的修改时间进行检查,以及根据资源唯一标识是否发生变化来进行检查,它们都是靠一组成对出现的请求、响应 Header 来实现的:
2.3.1 服务端缓存
缓存属性
我们设计或者选择缓存至少会考虑以下四个维度的属性:
- 吞吐量:缓存的吞吐量使用 OPS 值(每秒操作数,Operations per Second,ops/s)来衡量,反映了对缓存进行并发读、写操作的效率,即缓存本身的工作效率高低。
- 命中率:缓存的命中率即成功从缓存中返回结果次数与总请求次数的比值,反映了引入缓存的价值高低,命中率越低,引入缓存的收益越小,价值越低。
- 扩展功能:缓存除了基本读写功能外,还提供哪些额外的管理功能,譬如最大容量、失效时间、失效事件、命中率统计,等等。
- 分布式支持:缓存可分为“进程内缓存”和“分布式缓存”两大类,前者只为节点本身提供服务,无网络访问操作,速度快但缓存的数据不能在各个服务节点中共享,后者则相反。
命中率与淘汰策略
- FIFO(First In First Out):优先淘汰最早进入被缓存的数据。FIFO 实现十分简单,但一般来说它并不是优秀的淘汰策略,越是频繁被用到的数据,往往会越早被存入缓存之中。如果采用这种淘汰策略,很可能会大幅降低缓存的命中率。
- LRU(Least Recent Used):优先淘汰最久未被使用访问过的数据。LRU 通常会采用 HashMap 加 LinkedList 双重结构(如 LinkedHashMap)来实现,以 HashMap 来提供访问接口,保证常量时间复杂度的读取性能,以 LinkedList 的链表元素顺序来表示数据的时间顺序,每次缓存命中时把返回对象调整到 LinkedList 开头,每次缓存淘汰时从链表末端开始清理数据。对大多数的缓存场景来说,LRU 都明显要比 FIFO 策略合理,尤其适合用来处理短时间内频繁访问的热点对象。但相反,它的问题是如果一些热点数据在系统中经常被频繁访问,但最近一段时间因为某种原因未被访问过,此时这些热点数据依然要面临淘汰的命运,LRU 依然可能错误淘汰价值更高的数据。
- LFU(Least Frequently Used):优先淘汰最不经常使用的数据。LFU 会给每个数据添加一个访问计数器,每访问一次就加 1,需要淘汰时就清理计数器数值最小的那批数据。LFU 可以解决上面 LRU 中热点数据间隔一段时间不访问就被淘汰的问题,但同时它又引入了两个新的问题,首先是需要对每个缓存的数据专门去维护一个计数器,每次访问都要更新,在上一节“吞吐量”里解释了这样做会带来高昂的维护开销;另一个问题是不便于处理随时间变化的热度变化,譬如某个曾经频繁访问的数据现在不需要了,它也很难自动被清理出缓存。
扩展功能
一套标准的 Map 接口(或者来自JSR 107 (opens new window)的 javax.cache.Cache 接口)就可以满足缓存访问的基本需要,不过在“访问”之外,专业的缓存往往还会提供很多额外的功能。笔者简要列举如下:
- 加载器:许多缓存都有“CacheLoader”之类的设计,加载器可以让缓存从只能被动存储外部放入的数据,变为能够主动通过加载器去加载指定 Key 值的数据,加载器也是实现自动刷新功能的基础前提。
- 淘汰策略:有的缓存淘汰策略是固定的,也有一些缓存能够支持用户自己根据需要选择不同的淘汰策略。
- 失效策略:要求缓存的数据在一定时间后自动失效(移除出缓存)或者自动刷新(使用加载器重新加载)。
- 事件通知:缓存可能会提供一些事件监听器,让你在数据状态变动(如失效、刷新、移除)时进行一些额外操作。有的缓存还提供了对缓存数据本身的监视能力(Watch 功能)。
- 并发级别:对于通过分段加锁来实现的缓存(以 Guava Cache 为代表),往往会提供并发级别的设置。可以简单将其理解为缓存内部是使用多个 Map 来分段存储数据的,并发级别就用于计算出使用 Map 的数量。如果将这个参数设置过大,会引入更多的 Map,需要额外维护这些 Map 而导致更大的时间和空间上的开销;如果设置过小,又会导致在访问时产生线程阻塞,因为多个线程更新同一个 ConcurrentMap 的同一个值时会产生锁竞争。
- 容量控制:缓存通常都支持指定初始容量和最大容量,初始容量目的是减少扩容频率,这与 Map 接口本身的初始容量含义是一致的。最大容量类似于控制 Java 堆的-Xmx 参数,当缓存接近最大容量时,会自动清理掉低价值的数据。
- 引用方式:支持将数据设置为软引用或者弱引用,提供引用方式的设置是为了将缓存与 Java 虚拟机的垃圾收集机制联系起来。
- 统计信息:提供诸如缓存命中率、平均加载时间、自动回收计数等统计。
- 持久化:支持将缓存的内容存储到数据库或者磁盘中,进程内缓存提供持久化功能的作用不是太大,但分布式缓存大多都会考虑提供持久化功能。
表 4-4 几款主流进程内缓存方案对比
| ConcurrentHashMap | Ehcache | Guava Cache | Caffeine | |
|---|---|---|---|---|
| 访问性能 | 最高 | 一般 | 良好 | 优秀 接近于 ConcurrentHashMap |
| 淘汰策略 | 无 | 支持多种淘汰策略 FIFO、LRU、LFU 等 | LRU | W-TinyLFU |
| 扩展功能 | 只提供基础的访问接口 | 并发级别控制 失效策略 容量控制 事件通知 统计信息 …… | 大致同左 | 大致同左 |
分布死缓存
2.3.2域名解析
早期的域名必须带有这个点才能被 DNS 正确解析,如今几乎所有的操作系统、DNS 服务器都可以自动补上结尾的点号,然后开始如下解析步骤:
客户端先检查本地的 DNS 缓存,查看是否存在并且是存活着的该域名的地址记录。DNS 是以存活时间 (opens new window)(Time to Live,TTL)来衡量缓存的有效情况的,所以,如果某个域名改变了 IP 地址,DNS 服务器并没有任何机制去通知缓存了该地址的机器去更新或者失效掉缓存,只能依靠 TTL 超期后的重新获取来保证一致性。后续每一级 DNS 查询的过程都会有类似的缓存查询操作,再遇到时笔者就不重复叙述了。
客户端将地址发送给本机操作系统中配置的本地 DNS(Local DNS),这个本地 DNS 服务器可以由用户手工设置,也可以在 DHCP 分配时或者在拨号时从 PPP 服务器中自动获取到。
本地 DNS 收到查询请求后,会按照“是否有
1
www.icyfenix.com.cn的权威服务器”→“是否有
1
icyfenix.com.cn的权威服务器”→“是否有
1
com.cn的权威服务器”→“是否有
1
cn的权威服务器”的顺序,依次查询自己的地址记录,如果都没有查询到,就会一直找到最后点号代表的根域名服务器为止。这个步骤里涉及了两个重要名词:
- 权威域名服务器(Authoritative DNS):是指负责翻译特定域名的 DNS 服务器,“权威”意味着这个域名应该翻译出怎样的结果是由它来决定的。DNS 翻译域名时无需像查电话本一样刻板地一对一翻译,根据来访机器、网络链路、服务内容等各种信息,可以玩出很多花样,权威 DNS 的灵活应用,在后面的内容分发网络、服务发现等章节都还会有所涉及。
- 根域名服务器(Root DNS)是指固定的、无需查询的顶级域名 (opens new window)(Top-Level Domain)服务器,可以默认为它们已内置在操作系统代码之中。全世界一共有 13 组根域名服务器(注意并不是 13 台,每一组根域名都通过任播 (opens new window)的方式建立了一大群镜像,根据维基百科的数据,迄今已经超过 1000 台根域名服务器的镜像了)。13 这个数字是由于 DNS 主要采用 UDP 传输协议(在需要稳定性保证的时候也可以采用 TCP)来进行数据交换,未分片的 UDP 数据包在 IPv4 下最大有效值为 512 字节,最多可以存放 13 组地址记录,由此而来的限制。
现在假设本地 DNS 是全新的,上面不存在任何域名的权威服务器记录,所以当 DNS 查询请求按步骤 3 的顺序一直查到根域名服务器之后,它将会得到“
cn的权威服务器”的地址记录,然后通过“cn的权威服务器”,得到“com.cn的权威服务器”的地址记录,以此类推,最后找到能够解释www.icyfenix.com.cn的权威服务器地址。通过“
www.icyfenix.com.cn的权威服务器”,查询www.icyfenix.com.cn的地址记录,地址记录并不一定就是指 IP 地址,在 RFC 规范中有定义的地址记录类型已经多达数十种 (opens new window),譬如 IPv4 下的 IP 地址为 A 记录,IPv6 下的 AAAA 记录、主机别名 CNAME 记录,等等。
缺点:
- 典型的问题是响应速度,当极端情况(各级服务器均无缓存)下的域名解析可能导致每个域名都必须递归多次才能查询到结果,显著影响传输的响应速度,譬如图 4-1 所示高达 310 毫秒的 DNS 查询。
- 另一种可能更严重的缺陷是 DNS 的分级查询意味着每一级都有可能受到中间人攻击的威胁,产生被劫持的风险。
另一种新的 DNS 工作模式:HTTPDNS (opens new window)(也称为 DNS over HTTPS,DoH)。它将原本的 DNS 解析服务开放为一个基于 HTTPS 协议的查询服务,替代基于 UDP 传输协议的 DNS 域名解析,通过程序代替操作系统直接从权威 DNS 或者可靠的 Local DNS 获取解析数据,从而绕过传统 Local DNS。这种做法的好处是完全免去了“中间商赚差价”的环节,不再惧怕底层的域名劫持,能够有效避免 Local DNS 不可靠导致的域名生效缓慢、来源 IP 不准确、产生的智能线路切换错误等问题。
2.3.3传输链路
传输链路优化(Transmission Optimization)
今天的传输链路优化原则,在若干年后的未来再回头看它们时,其中多数已经成了奇技淫巧,有些甚至成了反模式 (opens new window)。
经过客户端缓存的节流、经过 DNS 服务的解析指引,程序发出的请求流量便正式离开客户端,踏上以服务器为目的地的旅途了,这个过程就是本节的主角:传输链路。
连接数优化
传输压缩
快速UDP 网络连接
2.3.4内容分发网络
内容分发
目前主要有以下两种主流的内容分发方式:
- 主动分发(Push):分发由源站主动发起,将内容从源站或者其他资源库推送到用户边缘的各个 CDN 缓存节点上。这个推送的操作没有什么业界标准可循,可以采用任何传输方式(HTTP、FTP、P2P,等等)、任何推送策略(满足特定条件、定时、人工,等等)、任何推送时间,只要与后面说的更新策略相匹配即可。由于主动分发通常需要源站、CDN 服务双方提供程序 API 接口层面的配合,所以它对源站并不是透明的,只对用户一侧单向透明。主动分发一般用于网站要预载大量资源的场景。譬如双十一之前一段时间内,淘宝、京东等各个网络商城就会开始把未来活动中所需用到的资源推送到 CDN 缓存节点中,特别常用的资源甚至会直接缓存到你的手机 APP 的存储空间或者浏览器的localStorage (opens new window)上。
- 被动回源(Pull):被动回源由用户访问所触发全自动、双向透明的资源缓存过程。当某个资源首次被用户请求的时候,CDN 缓存节点发现自己没有该资源,就会实时从源站中获取,这时资源的响应时间可粗略认为是资源从源站到 CDN 缓存节点的时间,再加上资源从 CDN 发送到用户的时间之和。因此,被动回源的首次访问通常是比较慢的(但由于 CDN 的网络条件一般远高于普通用户,并不一定就会比用户直接访问源站更慢),不适合应用于数据量较大的资源。被动回源的优点是可以做到完全的双向透明,不需要源站在程序上做任何的配合,使用起来非常方便。这种分发方式是小型站点使用 CDN 服务的主流选择,如果不是自建 CDN,而是购买阿里云、腾讯云的 CDN 服务的站点,多数采用的就是这种方式。
CND应用
CDN 可以做的事情简要列举,以便读者有个总体认知。
- 加速静态资源:这是 CDN 本职工作。
- 安全防御:CDN 在广义上可以视作网站的堡垒机,源站只对 CDN 提供服务,由 CDN 来对外界其他用户服务,这样恶意攻击者就不容易直接威胁源站。CDN 对某些攻击手段的防御,如对DDoS 攻击 (opens new window)的防御尤其有效。但需注意,将安全都寄托在 CDN 上本身是不安全的,一旦源站真实 IP 被泄漏,就会面临很高的风险。
- 协议升级:不少 CDN 提供商都同时对接(代售 CA 的)SSL 证书服务,可以实现源站是 HTTP 协议的,而对外开放的网站是基于 HTTPS 的。同理,可以实现源站到 CDN 是 HTTP/1.x 协议,CDN 提供的外部服务是 HTTP/2 或 HTTP/3 协议、实现源站是基于 IPv4 网络的,CDN 提供的外部服务支持 IPv6 网络,等等。
- 状态缓存:第一节介绍客户端缓存时简要提到了状态缓存,CDN 不仅可以缓存源站的资源,还可以缓存源站的状态,譬如源站的 301/302 转向就可以缓存起来让客户端直接跳转、还可以通过 CDN 开启HSTS (opens new window)、可以通过 CDN 进行OCSP 装订 (opens new window)加速 SSL 证书访问,等等。有一些情况下甚至可以配置 CDN 对任意状态码(譬如 404)进行一定时间的缓存,以减轻源站压力,但这个操作应当慎重,在网站状态发生改变时去及时刷新缓存。
- 修改资源:CDN 可以在返回资源给用户的时候修改它的任何内容,以实现不同的目的。譬如,可以对源站未压缩的资源自动压缩并修改 Content-Encoding,以节省用户的网络带宽消耗、可以对源站未启用客户端缓存的内容加上缓存 Header,自动启用客户端缓存,可以修改CORS (opens new window)的相关 Header,将源站不支持跨域的资源提供跨域能力,等等。
- 访问控制:CDN 可以实现 IP 黑/白名单功能,根据不同的来访 IP 提供不同的响应结果,根据 IP 的访问流量来实现 QoS 控制、根据 HTTP 的 Referer 来实现防盗链,等等。
- 注入功能:CDN 可以在不修改源站代码的前提下,为源站注入各种功能,图 4-7 是国际 CDN 巨头 CloudFlare 提供的 Google Analytics、PACE、Hardenize 等第三方应用,在 CDN 下均能做到无须修改源站任何代码即可使用。
2.3.4负载均衡
无论在网关内部建立了多少级的负载均衡,从形式上来说都可以分为两种:四层负载均衡和七层负载均衡。在详细介绍它们是什么以及如何工作之前,我们先来建立两个总体的、概念性的印象。
- 四层负载均衡的优势是性能高,七层负载均衡的优势是功能强。
- 做多级混合负载均衡,通常应是低层的负载均衡在前,高层的负载均衡在后(想一想为什么?)。
现在所说的“四层负载均衡”其实是多种均衡器工作模式的统称,“四层”的意思是说这些工作模式的共同特点是维持着同一个 TCP 连接,而不是说它只工作在第四层。事实上,这些模式主要都是工作在二层(数据链路层,改写 MAC 地址)和三层(网络层,改写 IP 地址)上,单纯只处理第四层(传输层,可以改写 TCP、UDP 等协议的内容和端口)的数据无法做到负载均衡的转发,因为 OSI 的下三层是媒体层(Media Layers),上四层是主机层(Host Layers),既然流量都已经到达目标主机上了,也就谈不上什么流量转发,最多只能做代理了。但出于习惯和方便,现在几乎所有的资料都把它们统称为四层负载均衡,笔者也同样称呼它为四层负载均衡,如果读者在某些资料上看见“二层负载均衡”、“三层负载均衡”的表述,应该了解这是在描述它们工作的层次,与这里说的“四层负载均衡”并不是同一类意思。下面笔者来介绍几种常见的四层负载均衡的工作模式。
表 4-1 OSI 七层模型
| 层 | 数据单元 | 功能 | |
|---|---|---|---|
| 7 | 应用层 Application Layer | 数据 Data | 提供为应用软件提供服务的接口,用于与其他应用软件之间的通信。典型协议:HTTP、HTTPS、FTP、Telnet、SSH、SMTP、POP3 等 |
| 6 | 表达层 Presentation Layer | 数据 Data | 把数据转换为能与接收者的系统格式兼容并适合传输的格式。 |
| 5 | 会话层 Session Layer | 数据 Data | 负责在数据传输中设置和维护计算机网络中两台计算机之间的通信连接。 |
| 4 | 传输层 Transport Layer | 数据段 Segments | 把传输表头加至数据以形成数据包。传输表头包含了所使用的协议等发送信息。典型协议:TCP、UDP、RDP、SCTP、FCP 等 |
| 3 | 网络层 Network Layer | 数据包 Packets | 决定数据的传输路径选择和转发,将网络表头附加至数据段后以形成报文(即数据包)。典型协议:IPv4/IPv6、IGMP、ICMP、EGP、RIP 等 |
| 2 | 数据链路层 Data Link Layer | 数据帧 Frame | 负责点对点的网络寻址、错误侦测和纠错。当表头和表尾被附加至数据包后,就形成数据帧(Frame)。典型协议:WiFi(802.11)、Ethernet(802.3)、PPP 等。 |
| 1 | 物理层 Physical Layer | 比特流 Bit | 在物理网络上传送数据帧,它负责管理电脑通信设备和网络媒体之间的互通。包括了针脚、电压、线缆规范、集线器、中继器、网卡、主机接口卡等。 |
-2.3.4.1数据链路层
数据链路层负载均衡所做的工作,是修改请求的数据帧中的 MAC 目标地址,让用户原本是发送给负载均衡器的请求的数据帧,被二层交换机根据新的 MAC 目标地址转发到服务器集群中对应的服务器(后文称为“真实服务器”,Real Server)的网卡上,这样真实服务器就获得了一个原本目标并不是发送给它的数据帧。

-2.3.4.2网络层
两种常见的修改方式。
第一种是保持原来的数据包不变,新创建一个数据包,把原来数据包的 Headers 和 Payload 整体作为另一个新的数据包的 Payload,在这个新数据包的 Headers 中写入真实服务器的 IP 作为目标地址,然后把它发送出去。经过三层交换机的转发,真实服务器收到数据包后,必须在接收入口处设计一个针对性的拆包机制,把由负载均衡器自动添加的那层 Headers 扔掉,还原出原来的数据包来进行使用。这样,真实服务器就同样拿到了一个原本不是发给它(目标 IP 不是它)的数据包,达到了流量转发的目的。那时候还没有流行起“禁止套娃”的梗,所以设计者给这种“套娃式”的传输起名叫做“IP 隧道 (opens new window)”(IP Tunnel)传输,也还是相当的形象。

而且,对服务器进行虚拟 IP 的配置并不是在任何情况下都可行的,尤其是当有好几个服务共用一台物理服务器的时候,此时就必须考虑第二种修改方式——改变目标数据包:直接把数据包 Headers 中的目标地址改掉,修改后原本由用户发给均衡器的数据包,也会被三层交换机转发送到真实服务器的网卡上,而且因为没有经过 IP 隧道的额外包装,也就无须再拆包了。但问题是这种模式是通过修改目标 IP 地址才到达真实服务器的,如果真实服务器直接将应答包返回客户端的话,这个应答数据包的源 IP 是真实服务器的 IP,也即均衡器修改以后的 IP 地址,客户端不可能认识该 IP,自然就无法再正常处理这个应答了。因此,只能让应答流量继续回到负载均衡,由负载均衡把应答包的源 IP 改回自己的 IP,再发给客户端,这样才能保证客户端与真实服务器之间的正常通信。如果你对网络知识有些了解的话,肯定会觉得这种处理似曾相识,这不就是在家里、公司、学校上网时,由一台路由器带着一群内网机器上网的“网络地址转换 (opens new window)”(Network Address Translation,NAT)操作吗?这种负载均衡的模式的确被称为 NAT 模式,此时,负载均衡器就是充当了家里、公司、学校的上网路由器的作用。NAT 模式的负载均衡器运维起来十分简单,只要机器将自己的网关地址设置为均衡器地址,就无须再进行任何额外设置了。此模式从请求到响应的过程如图 4-10 所示。
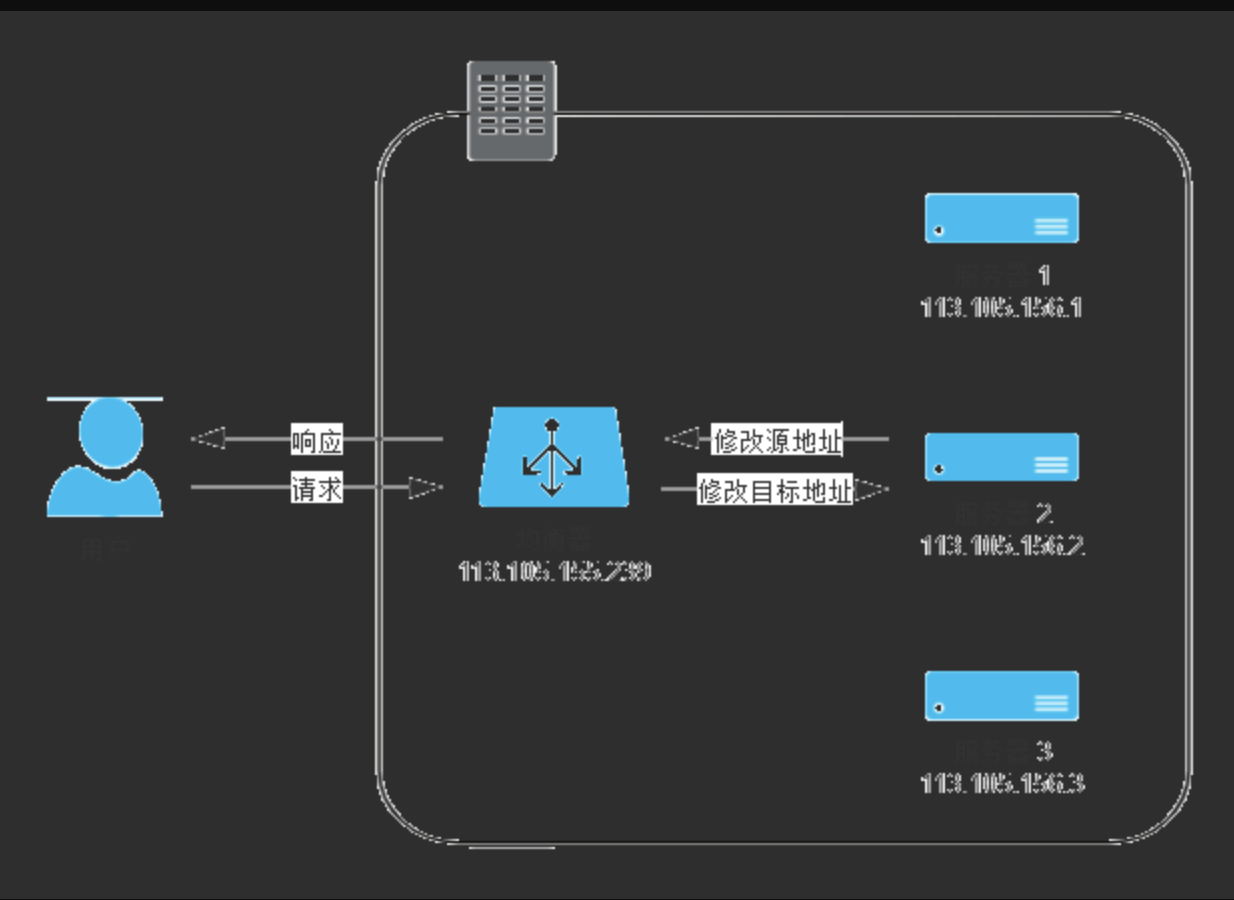
图 4-10 NAT 模式的负载均衡
还有一种更加彻底的 NAT 模式:即均衡器在转发时,不仅修改目标 IP 地址,连源 IP 地址也一起改了,源地址就改成均衡器自己的 IP,称作 Source NAT(SNAT)。这样做的好处是真实服务器无须配置网关就能够让应答流量经过正常的三层路由回到负载均衡器上,做到了彻底的透明。但是缺点是由于做了 SNAT,真实服务器处理请求时就无法拿到客户端的 IP 地址了,从真实服务器的视角看来,所有的流量都来自于负载均衡器,这样有一些需要根据目标 IP 进行控制的业务逻辑就无法进行。
-2.3.4.3应用层
“代理”这个词,根据“哪一方能感知到”的原则,可以分为“正向代理”、“反向代理”和“透明代理”三类。
- 正向代理就是我们通常简称的代理,指在客户端设置的、代表客户端与服务器通信的代理服务,它是客户端可知,而对服务器透明的。
- 反向代理是指在设置在服务器这一侧,代表真实服务器来与客户端通信的代理服务,此时它对客户端来说是透明的。
- 至于透明代理是指对双方都透明的,配置在网络中间设备上的代理服务,譬如,架设在路由器上的透明翻墙代理。
-2.3.4.4均衡策略与实现
从功能和应用的角度去介绍一些常见的均衡策略。
- 轮循均衡(Round Robin):每一次来自网络的请求轮流分配给内部中的服务器,从 1 至 N 然后重新开始。此种均衡算法适合于集群中的所有服务器都有相同的软硬件配置并且平均服务请求相对均衡的情况。
- 权重轮循均衡(Weighted Round Robin):根据服务器的不同处理能力,给每个服务器分配不同的权值,使其能够接受相应权值数的服务请求。譬如:服务器 A 的权值被设计成 1,B 的权值是 3,C 的权值是 6,则服务器 A、B、C 将分别接收到 10%、30%、60%的服务请求。此种均衡算法能确保高性能的服务器得到更多的使用率,避免低性能的服务器负载过重。
- 随机均衡(Random):把来自客户端的请求随机分配给内部中的多个服务器,在数据足够大的场景下能达到相对均衡的分布。
- 权重随机均衡(Weighted Random):此种均衡算法类似于权重轮循算法,不过在分配处理请求时是个随机选择的过程。
- 一致性哈希均衡(Consistency Hash):根据请求中某一些数据(可以是 MAC、IP 地址,也可以是更上层协议中的某些参数信息)作为特征值来计算需要落在的节点上,算法一般会保证同一个特征值每次都一定落在相同的服务器上。一致性的意思是保证当服务集群某个真实服务器出现故障,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
- 响应速度均衡(Response Time):负载均衡设备对内部各服务器发出一个探测请求(例如 Ping),然后根据内部中各服务器对探测请求的最快响应时间来决定哪一台服务器来响应客户端的服务请求。此种均衡算法能较好的反映服务器的当前运行状态,但这最快响应时间仅仅指的是负载均衡设备与服务器间的最快响应时间,而不是客户端与服务器间的最快响应时间。
- 最少连接数均衡(Least Connection):客户端的每一次请求服务在服务器停留的时间可能会有较大的差异,随着工作时间加长,如果采用简单的轮循或随机均衡算法,每一台服务器上的连接进程可能会产生极大的不平衡,并没有达到真正的负载均衡。最少连接数均衡算法对内部中需负载的每一台服务器都有一个数据记录,记录当前该服务器正在处理的连接数量,当有新的服务连接请求时,将把当前请求分配给连接数最少的服务器,使均衡更加符合实际情况,负载更加均衡。此种均衡策略适合长时处理的请求服务,如 FTP 传输。
从实现角度来看,负载均衡器的实现分为“软件均衡器”和“硬件均衡器”两类。
- 在软件均衡器方面,又分为直接建设在操作系统内核的均衡器和应用程序形式的均衡器两种。前者的代表是 LVS(Linux Virtual Server),后者的代表有 Nginx、HAProxy、KeepAlived 等,前者性能会更好,因为无须在内核空间和应用空间中来回复制数据包;而后者的优势是选择广泛,使用方便,功能不受限于内核版本。
- 在硬件均衡器方面,往往会直接采用应用专用集成电路 (opens new window)(Application Specific Integrated Circuit,ASIC)来实现,有专用处理芯片的支持,避免操作系统层面的损耗,得以达到最高的性能。这类的代表就是著名的 F5 和 A10 公司的负载均衡产品。
2.4架构安全性
——-第三章《分布式的基石》———
3.1分布式共识算法
Paxos
Multi Paxos
Gossip 协议
3.2从类库到服务
3.2.1服务发现
至少有(但不限于)以下三个问题是必须考虑并得到妥善解决的:
对消费者来说,外部的服务由谁提供?具体在什么网络位置?
对生产者来说,内部哪些服务需要暴露?哪些应当隐藏?应当以何种形式暴露服务?以什么规则在集群中分配请求?
对调用过程来说,如何保证每个远程服务都接收到相对平均的流量,获得尽可能高的服务质量与可靠性?
这三个问题的解决方案,在微服务架构中通常被称为“服务发现”、“服务的网关路由”和“服务的负载均衡”。
3.2.2网关路由
网关职责
在单体架构下,我们一般不太强调“网关”这个概念,为各个单体系统的副本分发流量的负载均衡器实质上承担了内部服务与外部请求之间的网关角色。在微服务环境中,网关的存在感就极大地增强了,甚至成为了微服务集群中必不可少的设施之一。
其中原因并不难理解:微服务架构下,每个服务节点都可能由不同团队负责,都有着自己独立的、互不相同的接口,如果服务集群缺少一个统一对外交互的代理人角色,那外部的服务消费者就必须知道所有微服务节点在集群中的精确坐标(在服务发现中解释过“服务坐标”的概念),这样,消费者不仅会受到服务集群的网络限制(不能确保集群中每个节点都有外网连接)、安全限制(不仅是服务节点的安全,外部自身也会受到如浏览器同源策略 (opens new window)的约束)、依赖限制(服务坐标这类信息不属于对外接口承诺的内容,随时可能变动,不应该依赖它),就算是调用服务的程序员,自己也不会愿意记住每一个服务的坐标位置来编写代码。由此可见,微服务中网关的首要职责就是作为统一的出口对外提供服务,将外部访问网关地址的流量,根据适当的规则路由到内部集群中正确的服务节点之上,因此,微服务中的网关,也常被称为“服务网关”或者“API 网关”,微服务中的网关首先应该是个路由器,在满足此前提的基础上,网关还可以根据需要作为流量过滤器来使用,提供某些额外的可选的功能,譬如安全、认证、授权、限流、监控、缓存,等等(这部分内容在后续章节中有专门讲解,这里不会涉及)
网关 = 路由器(基础职能) + 过滤器(可选职能)
网络 I/O 模型
人们把网络 I/O 模型总结为两类、五种模型:两类是指同步 I/O与异步 I/O,五种是指在同步 IO 中又分有划分出阻塞 I/O、非阻塞 I/O、多路复用 I/O和信号驱动 I/O四种细分模型。
网关还有最后一点必须关注的是它的可用性问题。任何系统的网络调用过程中都至少会有一个单点存在,这是由用户只通过唯一的一个地址去访问系统所决定的。即使是淘宝、亚马逊这样全球多数据中心部署的大型系统也不例外。对于更普遍的小型系统(小型是相对淘宝这些而言)来说,作为后端对外服务代理人角色的网关经常被视为整个系统的入口,往往很容易成为网络访问中的单点,这时候它的可用性就尤为重要。由于网关的地址具有唯一性,就不像之前服务发现那些注册中心那样直接做个集群,随便访问哪一台都可以解决问题。为此,对网关的可用性方面,我们应该考虑到以下几点:
- 网关应尽可能轻量,尽管网关作为服务集群统一的出入口,可以很方便地做安全、认证、授权、限流、监控,等等的功能,但给网关附加这些能力时还是要仔细权衡,取得功能性与可用性之间的平衡,过度增加网关的职责是危险的。
- 网关选型时,应该尽可能选择较成熟的产品实现,譬如 Nginx Ingress Controller、KONG、Zuul 这些经受过长期考验的产品,而不能一味只考虑性能选择最新的产品,性能与可用性之间的平衡也需要权衡。
- 在需要高可用的生产环境中,应当考虑在网关之前部署负载均衡器或者等价路由器 (opens new window)(ECMP),让那些更成熟健壮的设施(往往是硬件物理设备)去充当整个系统的入口地址,这样网关也可以进行扩展了。
BBF网关
为多种客户端(前端)提供不同的支持
提到网关的唯一性、高可用与扩展,笔者顺带也说一下近年来随着微服务一起火起来的概念“BFF”(Backends for Frontends)。这个概念目前还没有权威的中文翻译,在我们讨论的上下文里,它的意思是,网关不必为所有的前端提供无差别的服务,而是应该针对不同的前端,聚合不同的服务,提供不同的接口和网络访问协议支持。譬如,运行于浏览器的 Web 程序,由于浏览器一般只支持 HTTP 协议,服务网关就应提供 REST 等基于 HTTP 协议的服务,但同时我们亦可以针对运行于桌面系统的程序部署另外一套网关,它能与 Web 网关有完全不同的技术选型,能提供出基于更高性能协议(如 gRPC)的接口来获得更好的体验。在网关这种边缘节点上,针对同一样的后端集群,裁剪、适配、聚合出适应不一样的前端的服务,有助于后端的稳定,也有助于前端的赋能。
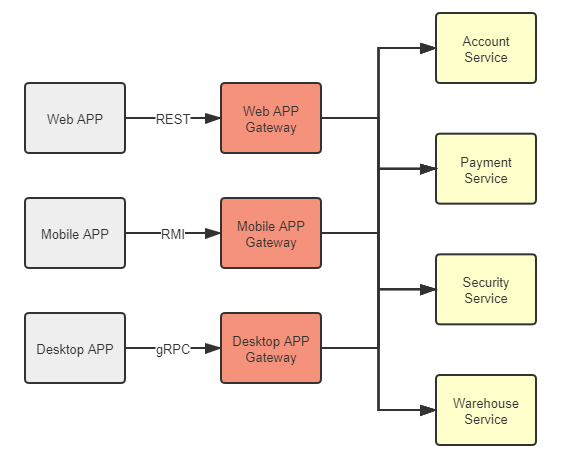
图 7-3 BFF 网关
3.2.3客户端负载均衡
服务发现、网关路由、负载均衡和服务容错,在细节上看,其中部分职责又是有交叉的,并不是服务注册中心就只关心服务发现,网关只关心路由,均衡器只关心流量负载均衡。譬如,步骤 1 服务发现的过程中,“根据请求来源的物理位置来分配机房”这个操作本质上是根据请求中的特征(地理位置)进行流量分发,这实际是一种路由行为。实际系统中,在 DNS 服务器(DNS 智能线路)、服务注册中心(如 Eureka 等框架中的 Region、Zone 概念)或者负载均衡器(可用区负载均衡,如 AWS 的 NLB,或 Envoy 的 Region、Zone、Sub-zone)中都有可能实现。
3.3流量治理
容错性设计
Since services can fail at any time, it’s important to be able to detect the failures quickly and, if possible, automatically restore service
由于服务随时都有可能崩溃,因此快速的失败检测和自动恢复就显得至关重要
3.3.1流量容错
熔断与降级
1 | |
3.3.1.1容错策略
常见的容错策略有以下几种:
故障转移(Failover):高可用的服务集群中,多数的服务——尤其是那些经常被其他服务所依赖的关键路径上的服务,均会部署有多个副本。这些副本可能部署在不同的节点(避免节点宕机)、不同的网络交换机(避免网络分区)甚至是不同的可用区(避免整个地区发生灾害或电力、骨干网故障)中。故障转移是指如果调用的服务器出现故障,系统不会立即向调用者返回失败结果,而是自动切换到其他服务副本,尝试其他副本能否返回成功调用的结果,从而保证了整体的高可用性。
故障转移的容错策略应该有一定的调用次数限制,譬如允许最多重试三个服务,如果都发生报错,那还是会返回调用失败。原因不仅是因为重试是有执行成本的,更是因为过度的重试反而可能让系统处于更加不利的状况。譬如有以下调用链:Service A → Service B → Service C
假设 A 的超时阈值为 100 毫秒,而 B 调用 C 花费 60 毫秒,然后不幸失败了,这时候做故障转移其实已经没有太大意义了,因为即时下一次调用能够返回正确结果,也很可能同样需要耗费 60 毫秒时间,时间总和就已经触及 A 服务的超时阈值,所以在这种情况下故障转移反而对系统是不利的。
快速失败(Failfast):还有另外一些业务场景是不允许做故障转移的,故障转移策略能够实施的前提是要求服务具备幂等性,对于非幂等的服务,重复调用就可能产生脏数据,引起的麻烦远大于单纯的某次服务调用失败,此时就应该以快速失败作为首选的容错策略。譬如,在支付场景中,需要调用银行的扣款接口,如果该接口返回的结果是网络异常,程序是很难判断到底是扣款指令发送给银行时出现的网络异常,还是银行扣款后返回结果给服务时出现的网络异常的。为了避免重复扣款,此时最恰当可行的方案就是尽快让服务报错,坚决避免重试,尽快抛出异常,由调用者自行处理。
安全失败(Failsafe):在一个调用链路中的服务通常也有主路和旁路之分,并不见得其中每个服务都是不可或缺的,有部分服务失败了也不影响核心业务的正确性。譬如开发基于 Spring 管理的应用程序时,通过扩展点、事件或者 AOP 注入的逻辑往往就属于旁路逻辑,典型的有审计、日志、调试信息,等等。属于旁路逻辑的另一个显著特征是后续处理不会依赖其返回值,或者它的返回值是什么都不会影响后续处理的结果,譬如只是将返回值记录到数据库,并不使用它参与最终结果的运算。对这类逻辑,一种理想的容错策略是即使旁路逻辑调用实际失败了,也当作正确来返回,如果需要返回值的话,系统就自动返回一个符合要求的数据类型的对应零值,然后自动记录一条服务调用出错的日志备查即可,这种策略被称为安全失败。
沉默失败(Failsilent):如果大量的请求需要等到超时(或者长时间处理后)才宣告失败,很容易由于某个远程服务的请求堆积而消耗大量的线程、内存、网络等资源,进而影响到整个系统的稳定。面对这种情况,一种合理的失败策略是当请求失败后,就默认服务提供者一定时间内无法再对外提供服务,不再向它分配请求流量,将错误隔离开来,避免对系统其他部分产生影响,此即为沉默失败策略。
故障恢复(Failback):故障恢复一般不单独存在,而是作为其他容错策略的补充措施,一般在微服务管理框架中,如果设置容错策略为故障恢复的话,通常默认会采用快速失败加上故障恢复的策略组合。它是指当服务调用出错了以后,将该次调用失败的信息存入一个消息队列中,然后由系统自动开始异步重试调用。
故障恢复策略一方面是尽力促使失败的调用最终能够被正常执行,另一方面也可以为服务注册中心和负载均衡器及时提供服务恢复的通知信息。故障恢复显然也是要求服务必须具备幂等性的,由于它的重试是后台异步进行,即使最后调用成功了,原来的请求也早已经响应完毕,所以故障恢复策略一般用于对实时性要求不高的主路逻辑,同时也适合处理那些不需要返回值的旁路逻辑。为了避免在内存中异步调用任务堆积,故障恢复与故障转移一样,应该有最大重试次数的限制。并行调用(Forking):上面五种以“Fail”开头的策略是针对调用失败时如何进行弥补的,以下这两种策略则是在调用之前就开始考虑如何获得最大的成功概率。并行调用策略很符合人们日常对一些重要环节进行的“双重保险”或者“多重保险”的处理思路,它是指一开始就同时向多个服务副本发起调用,只要有其中任何一个返回成功,那调用便宣告成功,这是一种在关键场景中使用更高的执行成本换取执行时间和成功概率的策略。
广播调用(Broadcast):广播调用与并行调用是相对应的,都是同时发起多个调用,但并行调用是任何一个调用结果返回成功便宣告成功,广播调用则是要求所有的请求全部都成功,这次调用才算是成功,任何一个服务提供者出现异常都算调用失败,广播调用通常会被用于实现“刷新分布式缓存”这类的操作。
表 8-1 常见容错策略优缺点及应用场景对比
| 容错策略 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| 故障转移 | 系统自动处理,调用者对失败的信息不可见 | 增加调用时间,额外的资源开销 | 调用幂等服务 对调用时间不敏感的场景 |
| 快速失败 | 调用者有对失败的处理完全控制权 不依赖服务的幂等性 | 调用者必须正确处理失败逻辑,如果一味只是对外抛异常,容易引起雪崩 | 调用非幂等的服务 超时阈值较低的场景 |
| 安全失败 | 不影响主路逻辑 | 只适用于旁路调用 | 调用链中的旁路服务 |
| 沉默失败 | 控制错误不影响全局 | 出错的地方将在一段时间内不可用 | 频繁超时的服务 |
| 故障恢复 | 调用失败后自动重试,也不影响主路逻辑 | 重试任务可能产生堆积,重试仍然可能失败 | 调用链中的旁路服务 对实时性要求不高的主路逻辑也可以使用 |
| 并行调用 | 尽可能在最短时间内获得最高的成功率 | 额外消耗机器资源,大部分调用可能都是无用功 | 资源充足且对失败容忍度低的场景 |
| 广播调用 | 支持同时对批量的服务提供者发起调用 | 资源消耗大,失败概率高 | 只适用于批量操作的场景 |
3.3.1.2容错设计模式
1 | |
断路器模式
断路器的基本思路是很简单的,就是通过代理(断路器对象)来一对一地(一个远程服务对应一个断路器对象)接管服务调用者的远程请求。断路器会持续监控并统计服务返回的成功、失败、超时、拒绝等各种结果,当出现故障(失败、超时、拒绝)的次数达到断路器的阈值时,它状态就自动变为“OPEN”,后续此断路器代理的远程访问都将直接返回调用失败,而不会发出真正的远程服务请求。通过断路器对远程服务的熔断,避免因持续的失败或拒绝而消耗资源,因持续的超时而堆积请求,最终的目的就是避免雪崩效应的出现。
断路器本质是一种快速失败策略的实现方式
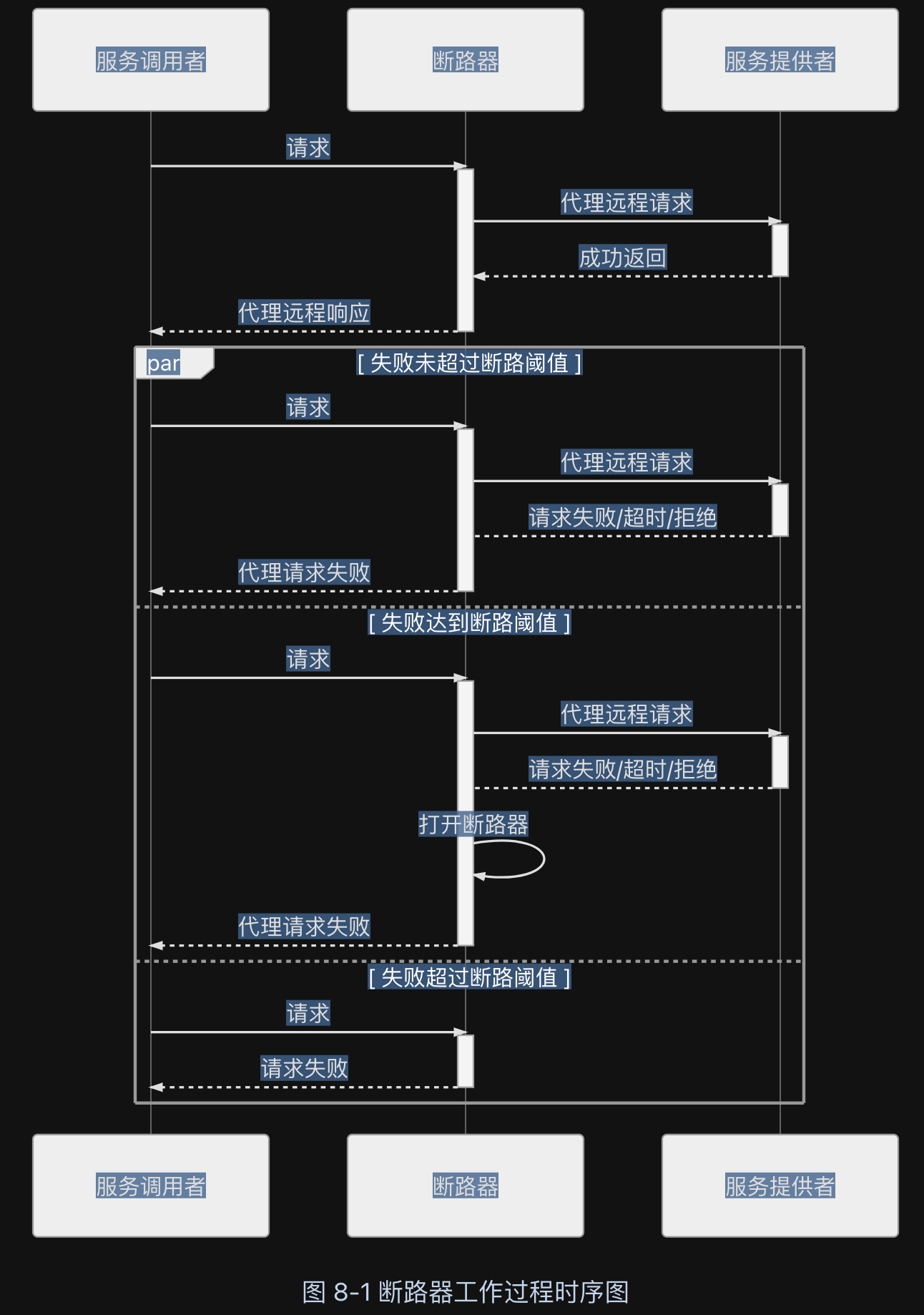
从调用序列来看,断路器就是一种有限状态机,断路器模式就是根据自身状态变化自动调整代理请求策略的过程。一般要设置以下三种断路器的状态:
- CLOSED:表示断路器关闭,此时的远程请求会真正发送给服务提供者。断路器刚刚建立时默认处于这种状态,此后将持续监视远程请求的数量和执行结果,决定是否要进入 OPEN 状态。
- OPEN:表示断路器开启,此时不会进行远程请求,直接给服务调用者返回调用失败的信息,以实现快速失败策略。
- HALF OPEN:这是一种中间状态。断路器必须带有自动的故障恢复能力,当进入 OPEN 状态一段时间以后,将“自动”(一般是由下一次请求而不是计时器触发的,所以这里自动带引号)切换到 HALF OPEN 状态。该状态下,会放行一次远程调用,然后根据这次调用的结果成功与否,转换为 CLOSED 或者 OPEN 状态,以实现断路器的弹性恢复。
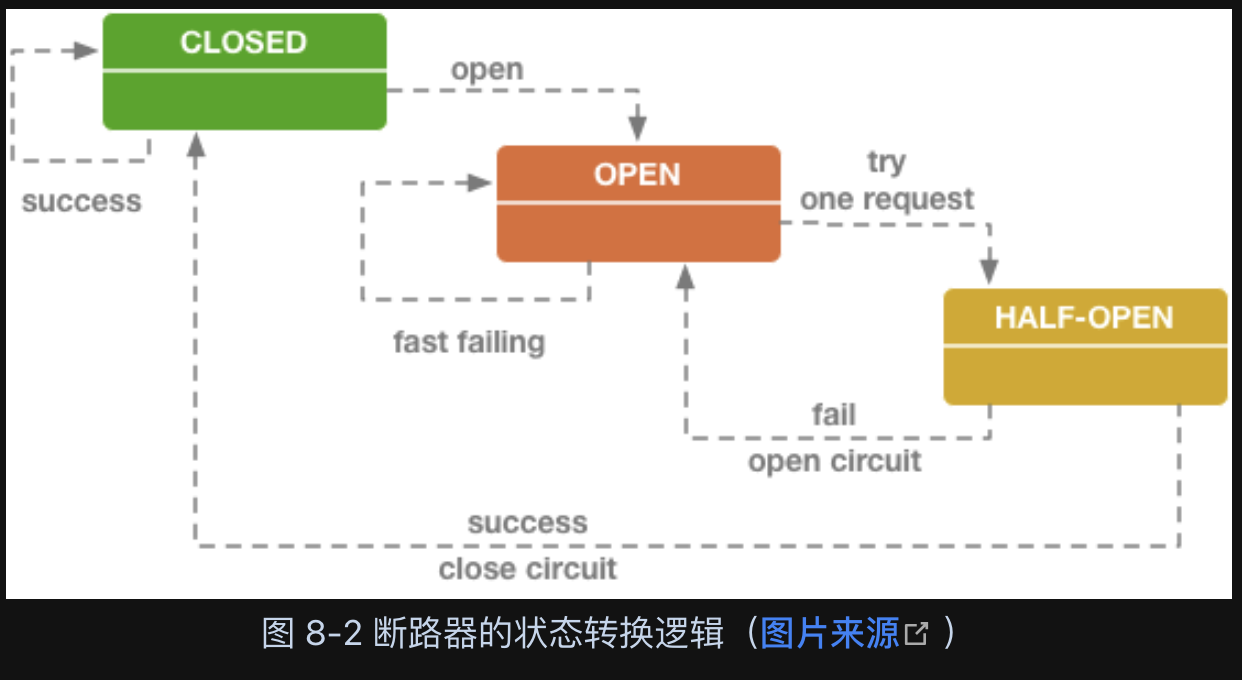
比较可行的办法是在以下两个条件同时满足时,断路器状态转变为 OPEN:
- 一段时间(譬如 10 秒以内)内请求数量达到一定阈值(譬如 20 个请求)。这个条件的意思是如果请求本身就很少,那就用不着断路器介入。
- 一段时间(譬如 10 秒以内)内请求的故障率(发生失败、超时、拒绝的统计比例)到达一定阈值(譬如 50%)。这个条件的意思是如果请求本身都能正确返回,也用不着断路器介入。
以上两个条件同时满足时,断路器就会转变为 OPEN 状态。
熔断 和 降级
服务熔断和服务降级之间的联系与差别。断路器做的事情是自动进行服务熔断,这是一种快速失败的容错策略的实现方法。在快速失败策略明确反馈了故障信息给上游服务以后,上游服务必须能够主动处理调用失败的后果,而不是坐视故障扩散,这里的“处理”指的就是一种典型的服务降级逻辑
下游:断路器熔断 - 熔断
上游:服务处理 - 降级
舱壁隔离模式
一个微服务治理中常听见的概念:服务隔离。舱壁隔离模式是常用的实现服务隔离的设计模式,舱壁这个词是来自造船业的舶来品,它原本的意思是设计舰船时,要在每个区域设计独立的水密舱室,一旦某个舱室进水,也只是影响这个舱室中的货物,而不至于让整艘舰艇沉没。这种思想就很符合容错策略中失败静默策略。
一种可行的解决办法是为每个服务单独设立线程池,这些线程池默认不预置活动线程,只用来控制单个服务的最大连接数。

局部线程池有一个显著的弱点,它额外增加了 CPU 的开销,每个独立的线程池都要进行排队、调度和下文切换工作。
为应对这种情况,还有一种更轻量的可以用来控制服务最大连接数的办法:信号量机制(Semaphore)。如果不考虑清理线程池、客户端主动中断线程这些额外的功能,仅仅是为了控制一个服务并发调用的最大次数,可以只为每个远程服务维护一个线程安全的计数器即可,并不需要建立局部线程池。具体做法是当服务开始调用时计数器加 1,服务返回结果后计数器减 1,一旦计数器超过设置的阈值就立即开始限流,在回落到阈值范围之前都不再允许请求了。由于不需要承担线程的排队、调度、切换工作,所以单纯维护一个作为计数器的信号量的性能损耗,相对于局部线程池来说几乎可以忽略不计。
以上介绍的是从微观的、服务调用的角度应用的舱壁隔离设计模式,舱壁隔离模式还可以在更高层、更宏观的场景中使用,不是按调用线程,而是按功能、按子系统、按用户类型等条件来隔离资源都是可以的。
譬如,根据用户等级、用户是否 VIP、用户来访的地域等各种因素,将请求分流到独立的服务实例去,这样即使某一个实例完全崩溃了,也只是影响到其中某一部分的用户,把波及范围尽可能控制住。一般来说,我们会选择将服务层面的隔离实现在服务调用端或者边车代理上,将系统层面的隔离实现在 DNS 或者网关处。
重试模式
在实践中,重试模式面临的风险反而大多来源于太过简单而导致的滥用。我们判断是否应该且是否能够对一个服务进行重试时,应同时满足以下几个前提条件:
- 仅在主路逻辑的关键服务上进行同步的重试,不是关键的服务,一般不把重试作为首选容错方案,尤其不该进行同步重试。
- 仅对由瞬时故障导致的失败进行重试。尽管一个故障是否属于可自愈的瞬时故障并不容易精确判定,但从 HTTP 的状态码上至少可以获得一些初步的结论,譬如,当发出的请求收到了 401 Unauthorized 响应,说明服务本身是可用的,只是你没有权限调用,这时候再去重试就没有什么意义。功能完善的服务治理工具会提供具体的重试策略配置(如 Envoy 的Retry Policy (opens new window)),可以根据包括 HTTP 响应码在内的各种具体条件来设置不同的重试参数。
- 仅对具备幂等性的服务进行重试。如果服务调用者和提供者不属于同一个团队,那服务是否幂等其实也是一个难以精确判断的问题,但仍可以找到一些总体上通用的原则。譬如,RESTful 服务中的 POST 请求是非幂等的,而 GET、HEAD、OPTIONS、TRACE 由于不会改变资源状态,这些请求应该被设计成幂等的;PUT 请求一般也是幂等的,因为 n 个 PUT 请求会覆盖相同的资源 n-1 次;DELETE 也可看作是幂等的,同一个资源首次删除会得到 200 OK 响应,此后应该得到 204 No Content 响应。这些都是 HTTP 协议中定义的通用的指导原则,虽然对于具体服务如何实现并无强制约束力,但我们自己建设系统时,遵循业界惯例本身就是一种良好的习惯。
- 重试必须有明确的终止条件,常用的终止条件有两种:
- 超时终止:并不限于重试,所有调用远程服务都应该要有超时机制避免无限期的等待。这里只是强调重试模式更加应该配合上超时机制来使用,否则重试对系统很可能反而是有害的,笔者已经在前面介绍故障转移策略时举过具体的例子,这里就不重复了。
- 次数终止:重试必须要有一定限度,不能无限制地做下去,通常最多就只重试 2 至 5 次。重试不仅会给调用者带来负担,对于服务提供者也是同样是负担。所以应避免将重试次数设的太大。此外,如果服务提供者返回的响应头中带有Retry-After (opens new window)的话,尽管它没有强制约束力,我们也应该充分尊重服务端的要求,做个“有礼貌”的调用者。
3.3.2限流控制
场景应用题
已知条件:
- 系统中一个业务操作需要调用 10 个服务协作来完成
- 该业务操作的总超时时间是 10 秒
- 每个服务的处理时间平均是 0.5 秒
- 集群中每个服务均部署了 20 个实例 副本
求解以下问题:
- 单个用户访问,完成一次业务操作,需要耗费系统多少处理器时间?
答:0.5 × 10 = 5 Sec CPU Time(opens new window)- 集群中每个服务每秒最大能处理多少个请求?
答:(1 ÷ 0.5) × 20 = 40 QPS(opens new window)- 假设不考虑顺序且请求分发是均衡的,在保证不超时的前提下,整个集群能持续承受最多每秒多少笔业务操作?
答:40 × 10 ÷ 5 = 80 TPS(opens new window)- 如果集群在一段时间内持续收到 100 TPS 的业务请求,会出现什么情况?
答:这就超纲了小学水平,得看你们家架构师的本事了。
如果不做任何处理的话,更可能出现的结果是这 100 个请求中的每一个都开始了处理,但是大部分请求完成了其中 10 次服务调用中的 8 次或者 9 次,然后就超时没有然后了。多数服务调用都白白浪费掉,没有几个请求能够走完整笔业务操作。譬如早期的 12306 系统就明显存在这样的问题,全国人民都上去抢票的结果是全国人民谁都买不上票。
一个健壮的系统需要做到恰当的流量控制,更具体地说,需要妥善解决以下三个问题:
- 依据什么限流?:要不要控制流量,要控制哪些流量,控制力度要有多大,等等这些操作都没法在系统设计阶段静态地给出确定的结论,必须根据系统此前一段时间的运行状况,甚至未来一段时间的预测情况来动态决定。
- 具体如何限流?:解决系统具体是如何做到允许一部分请求能够通行,而另外一部分流量实行受控制的失败降级,这必须了解掌握常用的服务限流算法和设计模式。
- 超额流量如何处理?:超额流量可以有不同的处理策略,也许会直接返回失败(如 429 Too Many Requests),或者被迫使它们进入降级逻辑,这种被称为否决式限流。也可能让请求排队等待,暂时阻塞一段时间后继续处理,这种被称为阻塞式限流。
3.3.2.1流量统计指标
要做流量控制,首先要弄清楚到底哪些指标能反映系统的流量压力大小。相较而言,容错的统计指标是明确的,容错的触发条件基本上只取决于请求的故障率,发生失败、拒绝与超时都算作故障;但限流的统计指标就不那么明确了,限流中的“流”到底指什么呢?要解答这个问题,我们先来理清经常用于衡量服务流量压力,但又较容易混淆的三个指标的定义:
- 每秒事务数(Transactions per Second,TPS):TPS 是衡量信息系统吞吐量的最终标准。“事务”可以理解为一个逻辑上具备原子性的业务操作。譬如你在 Fenix’s Bookstore 买了一本书,将要进行支付,“支付”就是一笔业务操作,支付无论成功还是不成功,这个操作在逻辑上是原子的,即逻辑上不可能让你买本书还成功支付了前面 200 页,又失败了后面 300 页。
- 每秒请求数(Hits per Second,HPS):HPS 是指每秒从客户端发向服务端的请求数(请将 Hits 理解为 Requests 而不是 Clicks,国内某些翻译把它理解为“每秒点击数”多少有点望文生义的嫌疑)。如果只要一个请求就能完成一笔业务,那 HPS 与 TPS 是等价的,但在一些场景(尤其常见于网页中)里,一笔业务可能需要多次请求才能完成。譬如你在 Fenix’s Bookstore 买了一本书要进行支付,尽管逻辑上它是原子的,但技术实现上,除非你是直接在银行开的商城中购物能够直接扣款,否则这个操作就很难在一次请求里完成,总要经过显示支付二维码、扫码付款、校验支付是否成功等过程,中间不可避免地会发生多次请求。
- 每秒查询数(Queries per Second,QPS):QPS 是指一台服务器能够响应的查询次数。如果只有一台服务器来应答请求,那 QPS 和 HPS 是等价的,但在分布式系统中,一个请求的响应往往要由后台多个服务节点共同协作来完成。譬如你在 Fenix’s Bookstore 买了一本书要进行支付,尽管扫描支付二维码时客户端只发送了一个请求,但这背后服务端很可能需要向仓储服务确认库存信息避免超卖、向支付服务发送指令划转货款、向用户服务修改用户的购物积分,等等,这里面每次内部访问都要消耗掉一次或多次查询数。
3.3.2.1限流设计模式
流量计数器模式
(固定窗口 / 计数器算法)
滑动时间窗模式
滑动时间窗的工作过程:
- 将数组最后一位的元素丢弃掉,并把所有元素都后移一位,然后在数组第一个插入一个新的空元素。这个步骤即为“滑动窗口”。
- 将计数器中所有统计信息写入到第一位的空元素中。
- 对数组中所有元素进行统计,并复位清空计数器数据供下一个统计周期使用。
这种限流也有其缺点,它通常只适用于否决式限流,超过阈值的流量就必须强制失败或降级,很难进行阻塞等待处理,也就很难在细粒度上对流量曲线进行整形,起不到削峰填谷的作用。
漏桶模式
1 | |
不过,由于请求总是有超时时间的,所以缓冲区大小也必须是有限度的,当注水速度持续超过出水速度一段时间以后,水池终究会被灌满,此时,从网络的流量整形的角度看是体现为部分数据包被丢弃,而在信息系统的角度看就体现为有部分请求会遭遇失败和降级。
漏桶在代码实现上非常简单,它其实就是一个以请求对象作为元素的先入先出队列(FIFO Queue),队列长度就相当于漏桶的大小,当队列已满时便拒绝新的请求进入。漏桶实现起来很容易,困难在于如何确定漏桶的两个参数:桶的大小和水的流出速率。
现实中系统的处理速度往往受到其内部拓扑结构变化和动态伸缩的影响,所以能够支持变动请求处理速率的令牌桶算法往往可能会是更受程序员青睐的选择。
令牌桶算法
1 | |
程序编码:
- 让系统以一个由限流目标决定的速率向桶中注入令牌,譬如要控制系统的访问不超过 100 次,速率即设定为 1/100=10 毫秒。
- 桶中最多可以存放 N 个令牌,N 的具体数量是由超时时间和服务处理能力共同决定的。如果桶已满,第 N+1 个进入的令牌会被丢弃掉。
- 请求到时先从桶中取走 1 个令牌,如果桶已空就进入降级逻辑。
简化实现:令牌桶模式的实现看似比较复杂,每间隔固定时间就要放新的令牌到桶中,但其实并不需要真的用一个专用线程或者定时器来做这件事情,只要在令牌中增加一个时间戳记录,每次获取令牌前,比较一下时间戳与当前时间,就可以轻易计算出这段时间需要放多少令牌进去,然后一次性放入即可,所以真正编码并不会显得复杂。
Java 代码实现
以下是四种常见的限流算法及其概念、优缺点以及Java实现代码:
固定窗口算法(Fixed Window Algorithm):
概念:将时间划分为固定大小的窗口,每个窗口内允许通过的请求数量是固定的。
优点:简单易实现。
缺点:可能出现突发流量,无法应对短时间内的高峰请求。
Java实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24javacopy codepublic class FixedWindowRateLimiter {
private int limit;
private long windowStart;
private int count;
public FixedWindowRateLimiter(int limit) {
this.limit = limit;
this.windowStart = System.currentTimeMillis();
this.count = 0;
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
if (currentTime - windowStart >= 1000) {
windowStart = currentTime;
count = 0;
}
if (count < limit) {
count++;
return true;
}
return false;
}
}
滑动窗口算法(Sliding Window Algorithm):
概念:将时间划分为多个窗口,每个窗口内允许通过的请求数量是固定的,窗口会随时间滑动。
优点:相对于固定窗口算法,更平滑地处理流量。
缺点:实现较为复杂。
Java实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33javacopy codepublic class SlidingWindowRateLimiter {
private int limit;
private long windowSize;
private long[] window;
private int count;
public SlidingWindowRateLimiter(int limit, long windowSize) {
this.limit = limit;
this.windowSize = windowSize;
this.window = new long[limit];
this.count = 0;
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
if (currentTime - window[0] >= windowSize) {
shiftWindow();
count = 0;
}
if (count < limit) {
window[count] = currentTime;
count++;
return true;
}
return false;
}
private void shiftWindow() {
for (int i = 1; i < limit; i++) {
window[i - 1] = window[i];
}
}
}
令牌桶算法(Token Bucket Algorithm):
概念:系统以固定的速率生成令牌,每个请求需要消耗一个令牌才能通过。
优点:可以应对突发流量,具有较好的平滑性。
缺点:实现较为复杂。
Java实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40javacopy codepublic class TokenBucketRateLimiter {
private int limit;
private long lastRequestTime;
private double tokens;
public TokenBucketRateLimiter(int limit, double rate) {
this.limit = limit;
this.lastRequestTime = System.currentTimeMillis();
this.tokens = 0;
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
refillTokens(rate);
}
}, 0, 1000);
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
double elapsedTime = (currentTime - lastRequestTime) / 1000.0;
tokens += elapsedTime * limit;
if (tokens > limit) {
tokens = limit;
}
if (tokens >= 1) {
tokens--;
lastRequestTime = currentTime;
return true;
}
return false;
}
private void refillTokens(double rate) {
tokens += rate;
if (tokens > limit) {
tokens = limit;
}
}
}
漏桶算法(Leaky Bucket Algorithm):
概念:系统以固定的速率处理请求,多余的请求会被丢弃或延迟处理。
优点:可以平滑流量,控制请求的处理速率。
缺点:可能导致请求的延迟。
Java实现代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class LeakyBucketRateLimiter {
private int limit;
private long lastRequestTime;
private int tokens;
public LeakyBucketRateLimiter(int limit, int rate) {
this.limit = limit;
this.lastRequestTime = System.currentTimeMillis();
this.tokens = 0;
Timer timer = new Timer();
timer.schedule(new TimerTask() {
@Override
public void run() {
releaseToken(rate);
}
}, 0, 1000 / rate);
}
public synchronized boolean allowRequest() {
long currentTime = System.currentTimeMillis();
if (currentTime - lastRequestTime >= 1000) {
tokens = 0;
}
if (tokens < limit) {
tokens++;
lastRequestTime = currentTime;
return true;
}
return false;
}
private void releaseToken(int rate) {
if (tokens > 0) {
tokens--;
}
}
}
分布式限流
- 一种常见的简单分布式限流方法是将所有服务的统计结果都存入集中式缓存(如 Redis)中,以实现在集群内的共享,并通过分布式锁、信号量等机制,解决这些数据的读写访问时并发控制的问题。在可以共享统计数据的前提下,原本用于单机的限流模式理论上也是可以应用于分布式环境中的,可是其代价也显而易见:(问题)每次服务调用都必须要额外增加一次网络开销,所以这种方法的效率肯定是不高的,流量压力大时,限流本身反倒会显著降低系统的处理能力。
- 只要集中式存储统计信息,就不可避免地会产生网络开销,为了缓解这里产生的性能损耗,一种可以考虑的办法是在令牌桶限流模式基础上进行“货币化改造”,即不把令牌看作是只有准入和不准入的“通行证”,而看作数值形式的“货币额度”。当请求进入集群时,首先在 API 网关处领取到一定数额的“货币”,为了体现不同等级用户重要性的差别,他们的额度可以有所差异,譬如让 VIP 用户的额度更高甚至是无限的。我们将用户 A 的额度表示为 QuanityA。由于任何一个服务在响应请求时都需要消耗集群一定量的处理资源,所以访问每个服务时都要求消耗一定量的“货币”,假设服务 X 要消耗的额度表示为 CostX,那当用户 A 访问了 N 个服务以后,他剩余的额度 LimitN即表示为:
LimitN = QuanityA - ∑NCostX
此时,我们可以把剩余额度 LimitN作为内部限流的指标,规定在任何时候,只要一旦剩余额度 LimitN小于等于 0 时,就不再允许访问其他服务了。此时必须先发生一次网络请求,重新向令牌桶申请一次额度,成功后才能继续访问,不成功则进入降级逻辑。除此之外的任何时刻,即 LimitN不为零时,都无须额外的网络访问,因为计算 LimitN是完全可以在本地完成的。
问题:
基于额度的限流方案对限流的精确度有一定的影响,可能存在业务操作已经进行了一部分服务调用,却无法从令牌桶中再获取到新额度,因“资金链断裂”而导致业务操作失败。这种失败的代价是比较高昂的,它白白浪费了部分已经完成了的服务资源,但总体来说,它仍是一种并发性能和限流效果上都相对折衷可行的分布式限流方案。上一节提到过,对于分布式系统容错是必须要有、无法妥协的措施。但限流与容错不一样,做分布式限流从不追求“越彻底越好”,往往需要权衡方案的代价与收益。
1 | |
3.4 可靠通信
3.4.1 零信任网络
零信任安全模型的特征
Google论文地址:《BeyondProd: A New Approach to Cloud-Native Security (opens new window)》
零信任安全的中心思想是不应当以某种固有特征来自动信任任何流量,除非明确得到了能代表请求来源(不一定是人,更可能是另一台服务)的身份凭证,否则一律不会有默认的信任关系。在 2019 年,Google 发表了一篇在安全与研发领域里都备受关注的论文《BeyondProd: A New Approach to Cloud-Native Security (opens new window)》(BeyondCorp 和 BeyondProd 是谷歌最新一代安全框架的名字,从 2014 年起已连续发表了 6 篇关于 BeyondCorp 和 BeyondProd 的论文),此文中详细列举了传统的基于边界的网络安全模型与云原生时代下基于零信任网络的安全模型之间的差异,并描述了要完成边界安全模型到零信任安全模型的迁移所要实现的具体需求点,笔者将其翻译转述为如表 9-1 所示内容。
表 9-1 传统网络安全模型与云原生时代零信任模型对比
| 传统、边界安全模型 | 云原生、零信任安全模型 | 具体需求 |
|---|---|---|
| 基于防火墙等设施,认为边界内可信 | 服务到服务通信需认证,环境内的服务之间默认没有信任 | 保护网络边界(仍然有效);服务之间默认没有互信 |
| 用于特定的 IP 和硬件(机器) | 资源利用率、重用、共享更好,包括 IP 和硬件 | 受信任的机器运行来源已知的代码 |
| 基于 IP 的身份 | 基于服务的身份 | 同上 |
| 服务运行在已知的、可预期的服务器上 | 服务可运行在环境中的任何地方,包括私有云/公有云混合部署 | 同上 |
| 安全相关的需求由应用来实现,每个应用单独实现 | 由基础设施来实现,基础设施中集成了共享的安全性要求。 | 集中策略实施点(Choke Points),一致地应用到所有服务 |
| 对服务如何构建、评审、实施的安全需求的约束力较弱 | 安全相关的需求一致地应用到所有服务 | 同上 |
| 安全组件的可观测性较弱 | 有安全策略及其是否生效的全局视图 | 同上 |
| 发布不标准,发布频率较低 | 标准化的构建和发布流程,每个微服务变更独立,变更更频繁 | 简单、自动、标准化的变更发布流程 |
| 工作负载通常作为虚拟机部署或部署到物理主机,并使用物理机或管理程序进行隔离 | 封装的工作负载及其进程在共享的操作系统中运行,并有管理平台提供的某种机制来进行隔离 | 在共享的操作系统的工作负载之间进行隔离 |
Google 的实践探索
笔者照 Google 论文所述来回答这个问题:为了保护服务集群内的代码与基础设施,Google 设计了一系列的内部工具,才最终得以实现前面所说的那些安全原则:
- 为了在网络边界上保护内部服务免受 DDoS 攻击,设计了名为 Google Front End(名字意为“最终用户访问请求的终点”)的边缘代理,负责保证此后所有流量都在 TLS 之上传输,并自动将流量路由到适合的可用区域之中。
- 为了强制身份只来源于服务,设计了名为 Application Layer Transport Security(应用层传输安全)的服务认证机制,这是一个用于双向认证和传输加密的系统,自动将服务与它的身份标识符绑定,使得所有服务间流量都不必再使用服务名称、主机 IP 来判断对方的身份。
- 为了确保服务间不再有默认的信任关系,设计了 Service Access Policy(服务访问策略)来管理一个服务向另一个服务发起请求时所需提供的认证、鉴权和审计策略,并支持全局视角的访问控制与分析,以达成“集中、共享的安全策略实施点”这条原则。
- 为了实现仅以受信的机器运行来源已知的代码,设计了名为 Binary Authorization(二进制授权)的部署时检查机制,确保在软件供应链的每一个阶段,都符合内部安全检查策略,并对此进行授权与鉴权。同时设计了名为 Host Integrity(宿主机完整性)的机器安全启动程序,在创建宿主机时自动验证包括 BIOS、BMC、Bootloader 和操作系统内核的数字签名。
- 为了工作负载能够具有强隔离性,设计了名为gVisor (opens new window)的轻量级虚拟化方案,这个方案与此前由 Intel 发起的Kata Containers (opens new window)的思路异曲同工。目的都是解决容器共享操作系统内核而导致隔离性不足的安全缺陷,做法都是为每个容器提供了一个独立的虚拟 Linux 内核,譬如 gVisor 是用 Golang 实现了一个名为Sentry (opens new window)的能够提供传统操作系统内核的能力的进程,严格来说无论是 gVisor 还是 Kata Containers,尽管披着容器运行时的外衣,但本质上都是轻量级虚拟机。
3.4.2 服务安全
3.5可观测性
日志、追踪、度量

- 日志(Logging):日志的职责是记录离散事件,通过这些记录事后分析出程序的行为,譬如曾经调用过什么方法,曾经操作过哪些数据,等等。打印日志被认为是程序中最简单的工作之一,调试问题时常有人会说“当初这里记得打点日志就好了”,可见这就是一项举手之劳的任务。输出日志的确很容易,但收集和分析日志却可能会很复杂,面对成千上万的集群节点,面对迅速滚动的事件信息,面对数以 TB 计算的文本,传输与归集都并不简单。对大多数程序员来说,分析日志也许就是最常遇见也最有实践可行性的“大数据系统”了。
- 追踪(Tracing):单体系统时代追踪的范畴基本只局限于栈追踪 (opens new window)(Stack Tracing),调试程序时,在 IDE 打个断点,看到的 Call Stack 视图上的内容便是追踪;编写代码时,处理异常调用了
Exception::printStackTrace()方法,它输出的堆栈信息也是追踪。微服务时代,追踪就不只局限于调用栈了,一个外部请求需要内部若干服务的联动响应,这时候完整的调用轨迹将跨越多个服务,同时包括服务间的网络传输信息与各个服务内部的调用堆栈信息,因此,分布式系统中的追踪在国内常被称为“全链路追踪”(后文就直接称“链路追踪”了),许多资料中也称它为“分布式追踪 (opens new window)”(Distributed Tracing)。追踪的主要目的是排查故障,如分析调用链的哪一部分、哪个方法出现错误或阻塞,输入输出是否符合预期,等等。 - 度量(Metrics):度量是指对系统中某一类信息的统计聚合。譬如,证券市场的每一只股票都会定期公布财务报表,通过财报上的营收、净利、毛利、资产、负债等等一系列数据来体现过去一个财务周期中公司的经营状况,这便是一种信息聚合。Java 天生自带有一种基本的度量,就是由虚拟机直接提供的 JMX(Java Management eXtensions)度量,诸如内存大小、各分代的用量、峰值的线程数、垃圾收集的吞吐量、频率,等等都可以从 JMX 中获得。度量的主要目的是监控(Monitoring)和预警(Alert),如某些度量指标达到风险阈值时触发事件,以便自动处理或者提醒管理员介入。
3.5.1事件日志
1 | |
3.5.2链路追踪
3.5.3聚合度量
———第四章《不可变基础设施》———
4.1虚拟化容器
4.1.1 容器的崛起
4.1.2 从容器构建系统
4.1.3 以应用为中心的封装
Kubernetes
概念
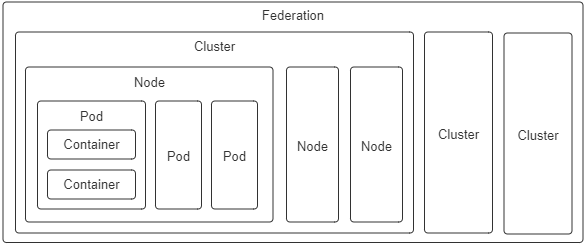
- 容器(Container):延续了自 Docker 以来一个容器封装一个应用进程的理念,是镜像管理的最小单位。
- 生产任务(Pod):补充了容器化后缺失的与进程组对应的“容器组”的概念,Pod 中容器共享 UTS、IPC、网络等名称空间,是资源调度的最小单位。
- 节点(Node):对应于集群中的单台机器,这里的机器即可以是生产环境中的物理机,也可以是云计算环境中的虚拟节点,节点是处理器和内存等资源的资源池,是硬件单元的最小单位。
- 集群(Cluster):对应于整个集群,Kubernetes 提倡理念是面向集群来管理应用。当你要部署应用的时候,只需要通过声明式 API 将你的意图写成一份元数据(Manifests),将它提交给集群即可,而无需关心它具体分配到哪个节点(尽管通过标签选择器完全可以控制它分配到哪个节点,但一般不需要这样做)、如何实现 Pod 间通信、如何保证韧性与弹性,等等,所以集群是处理元数据的最小单位。
- 集群联邦(Federation):对应于多个集群,通过联邦可以统一管理多个 Kubernetes 集群,联邦的一种常见应用是支持跨可用区域多活、跨地域容灾的需求。
资源 与 控制器
额外知识:Kubernates 的资源对象与控制器
目前,Kubernetes 已内置支持相当多的资源对象,并且还可以使用CRD(Custom Resource Definition)来自定义扩充,你可以使用
kubectl api-resources来查看它们。笔者根据用途分类列举了以下常见的资源:
- 用于描述如何创建、销毁、更新、扩缩 Pod,包括:Autoscaling(HPA)、CronJob、DaemonSet、Deployment、Job、Pod、ReplicaSet、StatefulSet
- 用于配置信息的设置与更新,包括:ConfigMap、Secret
- 用于持久性地存储文件或者 Pod 之间的文件共享,包括:Volume、LocalVolume、PersistentVolume、PersistentVolumeClaim、StorageClass
- 用于维护网络通信和服务访问的安全,包括:SecurityContext、ServiceAccount、Endpoint、NetworkPolicy
- 用于定义服务与访问,包括:Ingress、Service、EndpointSlice
- 用于划分虚拟集群、节点和资源配额,包括:Namespace、Node、ResourceQuota
这些资源在控制器管理框架中一般都会有相应的控制器来管理,笔者列举常见的控制器,按照它们的启动情况分类如下:
- 必须启用的控制器:EndpointController、ReplicationController、PodGCController、ResourceQuotaController、NamespaceController、ServiceAccountController、GarbageCollectorController、DaemonSetController、JobController、DeploymentController、ReplicaSetController、HPAController、DisruptionController、StatefulSetController、CronJobController、CSRSigningController、CSRApprovingController、TTLController
- 默认启用的可选控制器,可通过选项禁止:TokenController、NodeController、ServiceController、RouteController、PVBinderController、AttachDetachController
- 默认禁止的可选控制器,可通过选项启用:BootstrapSignerController、TokenCleanerController
弹性 与 韧性
故障恢复、滚动更新、自动扩缩这些特性,在云原生中时代里常被概括成服务的弹性(Elasticity)与韧性(Resilience),ReplicaSet、Deployment、Autoscaling 的用法,也属于是所有 Kubernetes 教材资料都会讲到的“基础必修课”。如果你准备学习 Kubernetes 或者其他云原生相关技术,笔者建议最好不要死记硬背地学习每个资源的元数据文件该如何编写、有哪些指令、有哪些功能,更好的方式是站在解决问题的角度去理解为什么 Kubernetes 要设计这些资源和控制器,理解为什么这些资源和控制器会被设计成现在这种样子。
4.2容器间网络
1 | |
CNI / CNM(容器网络 接口/模型)
CNI和CNM都是用于容器网络方面的技术。
CNI是Container Networking Interface(容器网络接口)的缩写,是一种用于容器网络的独立桥接技术。CNI允许多种容器运行时使用相同的网络体系结构和网络插件,从而方便容器网络之间的互操作性和扩展性。CNI使用插件架构,提供标准化的API和数据格式,从而可以轻松地为容器设计和实现新的网络插件。常见的CNI插件包括Bridge、Calico、Flannel等。
相比之下,CNM是Docker的容器网络模型(Container Network Model)的缩写,它是Docker在容器网络方面的标准。CNM通过使用网络驱动程序和容器的命名空间机制来实现容器网络。CNM提供了多种内置网络驱动程序和自定义网络驱动程序的支持,并支持容器在单一或多个网络中运行的多种拓扑。CNM网络驱动程序包括bridge、host、macvlan、overlay等。
简言之,CNI和CNM都是容器网络方面的技术,CNI是较为通用的桥接网络方案,支持多个容器运行时;而CNM是Docker原生的容器网络技术,提供多种内置网络驱动程序,适用于Docker生态环境。
-Docker的三种网路模式
Docker网络有三种模式:bridge、host和none。
Bridge模式:Bridge是Docker默认的网络模式。在Bridge网络中,Docker将创建一个名为
docker0的虚拟网络桥接器,并分配一个自动分配的IP段给桥接器。每个容器都将被分配一个从该网段中分配的IP地址。容器之间可以进行通信,但与容器之外的主机的通信需要进行端口映射。因此,该模式适用于简单的应用程序,例如Web应用程序和数据库等。Host模式:在Host模式下,容器与主机使用相同的网络命名空间,可以使用主机的IP地址和端口进行通信。该模式适用于需要最大化网络性能的应用程序,例如高流量Web应用程序和数据库等。
None模式:在None模式下,容器没有默认的网络接口,并且无法直接与外界通信,需要手动创建和配置网络。该模式适用于不需要网络连接的容器,例如调试或数据存储等。
综上所述,Bridge模式是Docker的默认网络模式,在容器之间隔离网络,但可以使用端口映射与主机或其他容器通信。Host模式允许容器与主机共享网络命名空间,以获得更好的网络性能,适用于高性能应用程序。None模式适用于不需要网络连接的容器。选择适当的网络模式取决于您的容器应用程序所需的网络连接方式以及需要的网络性能和安全性等要素。
-docker 本地 / 全局 网络
在Docker中,本地网络和全局网络的实现方式可以分为以下两类:
- 本地网络实现方式:
Bridge网络:Bridge网络是Docker的默认网络模式,它允许容器通过一个虚拟网桥连接到宿主机的物理网络,可以通过创建自定义桥接器来扩展这个网络。
Host网络:Host网络模式允许容器和宿主机共享一个网络命名空间,所有容器都可以被视为宿主机上的应用程序。Host网络性能更高,但缺乏网络隔离。
Macvlan网络:Macvlan网络模式允许将Docker容器接入物理网络,每个容器可以使用独立的MAC地址和IP地址。
- 全局网络实现方式:
Overlay网络:这是一种基于Docker的多主机容器网络模型,可以在多个Docker宿主机上创建一个虚拟的覆盖网络,使用VXLAN技术将多个Docker宿主机的容器连接在一起,并将这些容器放置在同一个Layer-2网络中。
Weaveworks Flannel:这是一种简单的软件定义网络(SDN)解决方案,旨在为Docker容器提供多主机SDN功能。
Project Calico:这是一个开放源码的vNetworking和网络安全项目,它允许在一个分布式环境中提供容器网络。
综上所述,本地网络和全局网络的实现方式包括Bridge、Host和Macvlan网络模式,以及Overlay、Flannel和Calico等全局网络模式。选取合适的网络模式,取决于应用程序的特性、安全性和性能需求,还需要考虑Docker的网络单一主机内还是在跨多个主机之间等方面的限制。
-Overlay docker
Overlay网络是一种基于Docker的多主机容器网络模型,可以在多个Docker宿主机上创建一个虚拟的覆盖网络。在Overlay网络中,Docker宿主机可以连接到同一个租户网络中,这个租户网络可以跨越多个Docker宿主机。Overlay网络使用VXLAN技术将多个Docker宿主机的容器连接在一起,并将这些容器放置在同一个Layer-2网络中。
Overlay网络具有以下特点:
跨主机通信:Overlay网络支持在多个Docker宿主机上创建相同的虚拟网络,即可以在多个Docker宿主机上连接同一个租户网络。
路由优化:Overlay网络使用VXLAN技术将多个Docker宿主机上的容器连接在一起,并对IP流量进行分段和路由优化。
容错性:在Overlay网络中,当某个Docker宿主机出现故障或离线时,容器可以迁移到其他Docker宿主机上。
安全性:Overlay网络可以提供加密和身份验证等安全机制,从而保证容器之间的网络安全。
Overlay网络适用于需要容器互联的分布式应用程序,例如数据分析、大数据应用程序和分布式数据库等。 在这些应用程序中,需要将多个容器放置在同一个虚拟网络中,并保证这些容器可以进行快速的、可靠的通信,Overlay网络可以满足这些需求。
4.2.1Linux 网络虚拟化
Linux 网络虚拟化 | 凤凰架构 (jingyecn.top)
4.2.2容器网格与生态
4.3持久化存储
4.3.1Kubernetes 的存储设计
Volumn
docker的Volumn 和 Mount
Mount 是动词,表示将某个外部存储挂载到系统中,Volume 是名词,表示物理存储的逻辑抽象,目的是为物理存储提供有弹性的分割方式。
Docker 内建支持了三种挂载类型,分别是 Bind(mount type=bind)、Volume(mount type=volume)和 tmpfs(mount type=tmpfs),如图 13-1 所示。其中 tmpfs 用于在内存中读写临时数据,与本节主要讨论的对象持久化存储并不相符,所以后面我们只着重关注 Bind 和 Volume 两种挂载类型。
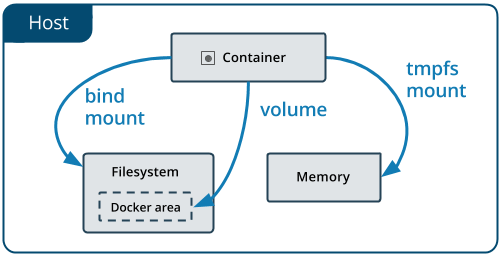
图 13-1 Docker 的三种挂载类型(图片来自Docker 官网文档 (opens new window))
Bind Mount 是 Docker 最早提供的(发布时就支持)挂载类型,作用是把宿主机的某个目录(或文件)挂载到容器的指定目录(或文件)下,譬如以下命令中参数-v表达的意思就是将外部的 HTML 文档挂到 Nginx 容器的默认网站根目录下:
1 | |
请注意,虽然命令中-v参数是volume的缩写,但-v最初只是用来创建 Bind Mount 而不是创建 Volume Mount 的,这种迷惑的行为也并非 Docker 的本意,只是由于 Docker 刚发布时考虑得不够周全,随随便便就在参数中占用了“Volume”这个词,到后来真的需要扩展 Volume 的概念来支持 Volume Mount 时,前面的-v已经被用户广泛使用了,所以也就只得如此将就着继续用。从 Docker 17.06 版本开始,它在 Docker Swarm 中借用了mount参数过来,这个参数默认创建的是 Volume Mount,可以通过明确的 type 子参数来指定另外两种挂载类型。上面命令可以等价于mount版本如下形式:
1 | |
从 Bind Mount 到 Volume Mount,实质是容器发展过程中对存储抽象能力提升的外在表现。从“Bind”这个名字,以及 Bind Mount 的实际功能可以合理地推测,Docker 最初认为“Volume”就只是一种“外部宿主机的磁盘存储到内部容器存储的映射关系”,但后来眉头一皱发现事情并没有那么简单:存储的位置并不局限只在外部宿主机、存储的介质并不局限只是物理磁盘、存储的管理也并不局限只有映射关系。
静态存储分配
persistentVolumn 与 PersistentVolumnClaim
Kubernetes 官方给出的概念定义也特别强调了 PersistentVolume 是由管理员(运维人员)负责维护的,用户(开发人员)通过 PersistentVolumeClaim 来匹配到合乎需求的 PersistentVolume。
PersistentVolume & PersistentVolumeClaim
A PersistentVolume (PV) is a piece of storage in the cluster that has been provisioned by an administrator.
A PersistentVolumeClaim (PVC) is a request for storage by a user.
PersistentVolume 是由管理员负责提供的集群存储。
PersistentVolumeClaim 是由用户负责提供的存储请求。
使用:
两者配合工作的具体过程如下。
管理员准备好要使用的存储系统,它应是某种网络文件系统(NFS)或者云储存系统,一般来说应该具备跨主机共享的能力。
管理员根据存储系统的实际情况,手工预先分配好若干个 PersistentVolume,并定义好每个 PersistentVolume 可以提供的具体能力。譬如以下例子所示:
1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: PersistentVolume
metadata:
name: nginx-html
spec:
capacity:
storage: 5Gi # 最大容量为5GB
accessModes:
- ReadWriteOnce # 访问模式为RWO
persistentVolumeReclaimPolicy: Retain # 回收策略是Retain
nfs: # 存储驱动是NFS
path: /html
server: 172.17.0.2以上 YAML 中定义的存储能力具体为:
- 存储的最大容量是 5GB。
- 存储的访问模式是“只能被一个节点读写挂载”(ReadWriteOnce,RWO),另外两种可选的访问模式是“可以被多个节点以只读方式挂载”(ReadOnlyMany,ROX)和“可以被多个节点读写挂载”(ReadWriteMany,RWX)。
- 存储的回收策略是 Retain,即在 Pod 被销毁时并不会删除数据。另外两种可选的回收策略分别是 Recycle ,即在 Pod 被销毁时,由 Kubernetes 自动执行
rm -rf /volume/*这样的命令来自动删除资料;以及 Delete,它让 Kubernetes 自动调用 AWS EBS、GCE PersistentDisk、OpenStack Cinder 这些云存储的删除指令。 - 存储驱动是 NFS,其他常见的存储驱动还有 AWS EBS、GCE PD、iSCSI、RBD(Ceph Block Device)、GlusterFS、HostPath,等等。
用户根据业务系统的实际情况,创建 PersistentVolumeClaim,声明 Pod 运行所需的存储能力。譬如以下例子所示:
1
2
3
4
5
6
7
8
9
10kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-html-claim
spec:
accessModes:
- ReadWriteOnce # 支持RWO访问模式
resources:
requests:
storage: 5Gi # 最小容量5GB以上 YAML 中声明了要求容量不得小于 5GB,必须支持 RWO 的访问模式。
Kubernetes 创建 Pod 的过程中,会根据系统中 PersistentVolume 与 PersistentVolumeClaim 的供需关系对两者进行撮合,如果系统中存在满足 PersistentVolumeClaim 声明中要求能力的 PersistentVolume 则撮合成功,将它们绑定。如果撮合不成功,Pod 就不会被继续创建,直至系统中出现新的或让出空闲的 PersistentVolume 资源。
以上几步都顺利完成的话,意味着 Pod 的存储需求得到满足,继续 Pod 的创建过程,整个过程如图 13-4 所示。

图 13-4 PersistentVolumeClaim 与 PersistentVolume 运作过程(图片来自《Kubernetes in Action (opens new window)》)
问题
Kubernetes 对 PersistentVolumeClaim 与 PersistentVolume 撮合的结果是产生一对一的绑定关系,“一对一”的意思是 PersistentVolume 一旦绑定在某个 PersistentVolumeClaim 上,直到释放以前都会被这个 PersistentVolumeClaim 所独占,不能再与其他 PersistentVolumeClaim 进行绑定。这意味着即使 PersistentVolumeClaim 申请的存储空间比 PersistentVolume 能够提供的要少,依然要求整个存储空间都为该 PersistentVolumeClaim 所用,这有可能会造成资源的浪费。譬如,某个 PersistentVolumeClaim 要求 3GB 的存储容量,当前 Kubernetes 手上只剩下一个 5GB 的 PersistentVolume 了,此时 Kubernetes 只好将这个 PersistentVolume 与申请资源的 PersistentVolumeClaim 进行绑定,平白浪费了 2GB 空间。假设后续有另一个 PersistentVolumeClaim 申请 2GB 的存储空间,那它也只能等待管理员分配新的 PersistentVolume,或者有其他 PersistentVolume 被回收之后才被能成功分配。
动态存储分配
关键词:Provisioner、StorageClass、
所谓的动态存储分配方案,是指在用户声明存储能力的需求时,不是期望通过 Kubernetes 撮合来获得一个管理员人工预置的 PersistentVolume,而是由特定的资源分配器(Provisioner)自动地在存储资源池或者云存储系统中分配符合用户存储需要的 PersistentVolume,然后挂载到 Pod 中使用,完成这项工作的资源被命名为 StorageClass,它的具体工作过程如下:
管理员根据储系统的实际情况,先准备好对应的 Provisioner。Kubernetes 官方已经提供了一系列预置的 In-Tree Provisioner (opens new window),放置在
kubernetes.io的 API 组之下。其中部分 Provisioner 已经有了官方的 CSI 驱动,譬如 vSphere 的 Kubernetes 自带驱动为kubernetes.io/vsphere-volume,VMware 的官方驱动为csi.vsphere.vmware.com。管理员不再是手工去分配 PersistentVolume,而是根据存储去配置 StorageClass。Pod 是可以动态扩缩的,而存储则是相对固定的,哪怕使用的是具有扩展能力的云存储,也会将它们视为存储容量、IOPS 等参数可变的固定存储来看待,譬如你可以将来自不同云存储提供商、不同性能、支持不同访问模式的存储配置为各种类型的 StorageClass,这也是它名字中“Class”(类型)的由来,譬如以下例子所示:
1
2
3
4
5
6
7
8apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs #AWS EBS的Provisioner
parameters:
type: gp2
reclaimPolicy: Retain用户依然通过 PersistentVolumeClaim 来声明所需的存储,但是应在声明中明确指出该由哪个 StorageClass 来代替 Kubernetes 处理该 PersistentVolumeClaim 的请求,譬如以下例子所示:
1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: standard-claim
spec:
accessModes:
- ReadWriteOnce
storageClassName: standard #明确指出该由哪个StorageClass来处理该PersistentVolumeClaim的请求
resource:
requests:
storage: 5Gi如果 PersistentVolumeClaim 中要求的 StorageClass 及它用到的 Provisioner 均是可用的话,那这个 StorageClass 就会接管掉原本由 Kubernetes 撮合 PersistentVolume 与 PersistentVolumeClaim 的操作,按照 PersistentVolumeClaim 中声明的存储需求,自动产生出满足该需求的 PersistentVolume 描述信息,并发送给 Provisioner 处理。
Provisioner 接收到 StorageClass 发来的创建 PersistentVolume 请求后,会操作其背后存储系统去分配空间,如果分配成功,就生成并返回符合要求的 PersistentVolume 给 Pod 使用。
以上几步都顺利完成的话,意味着 Pod 的存储需求得到满足,继续 Pod 的创建过程,整个过程如图 13-5 所示。

图 13-5 StorageClass 运作过程(图片来自《Kubernetes in Action (opens new window)》)
Dynamic Provisioning 与 Static Provisioning 并不是各有用途的互补设计,而是对同一个问题先后出现的两种解决方案。你完全可以只用 Dynamic Provisioning 来实现所有的 Static Provisioning 能够实现的存储需求,包括那些不需要动态分配的场景
4.3.2容器存储与生态
in-tree和 out-of-tree
在 Kubernetes 中,In-Tree 插件是指被标记为已稳定并内置在核心代码中的插件,而 Out-of-Tree 插件是指托管在 independent 项目中并与 Kubernetes API 耦合的插件。
应用场景方面,In-Tree 插件提供稳定的内置功能,包括 kubelet plugins、FlexVolume 和 CSI drivers 等,它们都内置在 Kubernetes 使用的代码库中,易于使用和部署;而 Out-of-Tree 插件通常更加专业、通用和灵活,它们可以为不同的场景和应用提供更加细粒度的控制和自定义配置,比如 Metrics Server、KubeDB等。它们通常作为 Kubernetes 插件来使用,并且可以在 Kubernetes 社区管理的托管项目中进行开发和维护。
具体介绍两种方式的含义:
In-Tree 插件: In-Tree 插件是指将 Kubernetes 插件编写成 Kubernetes 核心代码库的一部分。这种方式使得插件开发人员可以访问 Kubernetes 源代码,并且该插件的发布、部署和维护非常方便。这种插件通常需要经过审核才能被合并到 Kubernetes 的代码库中,并且受到 Kubernetes 团队的长期支持。由于 In-Tree 插件内置在 Kubernetes 中,因此它们的稳定性、性能和安全性非常高。
Out-of-Tree 插件: Out-of-Tree 插件则是指将 Kubernetes 插件作为独立的项目开发、测试并发布。这种方式使得插件开发人员可以以更加灵活和自由的方式开发插件,同时,它们可以对 Kubernetes 的版本和配置进行更加细粒度的控制,以确保其与 Kubernetes API 的兼容性。此外,由于 Out-of-Tree 插件和 Kubernetes 开发具有松散的耦合度,因此它们也可以更加灵活和快速地实现一些非常特定的、满足某些应用需求的功能。
综上所述,两种 Kubernetes 插件的方式各有优缺点,开发人员可以根据应用场景的实际需求,选择适当的插件,并根据需求与可行性选择对应的方式进行开发、测试和部署。
三种存储方式
目前出现过的存储系统和设备均可以划分到块存储、文件存储和对象存储这三种存储类型之中,划分的根本依据其实并非各种存储是如何储存数据的——那完全是存储系统私有的事情,更合理的划分依据是各种存储提供何种形式的接口供外部访问数据,不同的外部访问接口将反过来影响到存储的内部结构、性能与功能表现。虽然块存储、文件存储和对象存储可以彼此协同工作,但它们各自都有自己明确的擅长领域与优缺点,理解它们的工作原理,因地制宜地选择最适合的存储才能让系统达到最佳的工作状态。笔者按照它们出现的时间顺序分别介绍如下:
块存储:块存储是数据存储的最古老形式,数据都储存在固定长度的一个或多个块 (opens new window)(Block)中,想要读写访问数据,就必须使用与存储相匹配的协议(SCSI、SATA、SAS、FCP、FCoE、iSCSI……)来进行的。如果你是按顺序阅读本书内容的话,那笔者建议你类比上一章网络通讯中网络栈的数据流动过程,把存储设备中由块构成的信息流与网络设备中由数据包构成的信息流进行对比,事实上,像 iSCSI 这种协议真的就是建设在 TCP/IP 网络之上,上层以 SCSI 作为应用层协议对外提供服务的。
我们熟悉的硬盘就是最经典的块存储设备,以机械硬盘为例,一个块就是一个扇区,大小通常在 512 Bytes 至 4096 Bytes 之间。老式机械硬盘用柱面-磁头-扇区号 (opens new window)(Cylinder-Head-Sector,CHS)组成的编号进行寻址,现代机械硬盘只用一个逻辑块编号 (opens new window)(Logical Block Addressing,LBA)进行寻址。为了便于管理,硬盘通常会以多个块(这些块甚至可以来自不同的物理设备,譬如磁盘阵列的情况)来组成一个逻辑分区(Partition),将分区进行高级格式化 (opens new window)之后就形成了卷(Volume),这便与上节“Kubernetes 存储设计”中提到“Volume 是源于操作系统的概念”衔接了起来。
块存储由于贴近底层硬件,没有文件、目录、访问权限等的牵绊,所以性能通常都是最优秀的,吞吐量高,延迟低。尽管人类作为信息系统的最终用户,并不会直接面对块来操作数据,多数应用程序也是基于文件而不是块来读写数据的,但是操作系统内核中许多地方就直接通过块设备 (opens new window)(Block Device)接口来访问硬盘,一些追求 I/O 性能的软件,譬如高性能的数据库也会支持直接读写块设备以提升磁盘 I/O。块存储的特点是具有排它性,一旦块设备被某个客户端挂载后,其它客户端就无法再访问上面的数据了,因此,Kubernetes 中挂载的块存储大多访问模式都要求必须是 RWO(ReadWriteOnce)的。
文件存储:文件存储是最贴近人类用户的数据存储形式,数据存储在长度不固定的文件之中,用户可以针对文件进行新增、写入、追加、移动、复制、删除、重命名等各种操作,通常文件存储还会提供有文件查找、目录管理、权限控制等额外的高级功能。文件存储的访问不像块存储那样有五花八门的协议,POSIX (opens new window)接口(Portable Operating System Interface,POSIX)已经成为了事实标准,被各种商用的存储系统和操作系统共同支持。具体 POSIX 的文件操作接口笔者就不去举例罗列了,你不妨类比 Linux 下的各种文件管理命令来自行想象一下。
绝大多数传统的文件存储都是基于块存储之上去实现的,“文件”这个概念的出现是因为“块”对人类用户来说实在是过于难以使用、难以管理了。可以近似地认为文件是由块所组成的更高级存储单位。对于固定不会发生变动的文件,直接让每个文件连续占用若干个块,在文件头尾加入标志区分即可,磁带、CD-ROM、DVD-ROM 就采用了由连续块来构成文件的存储方案;但对于可能发生变动的场景,就必须考虑如何跨多个不连续的块来构成为文件。这种需求在数据结构角度看只需在每个块中记录好下一个块的地址,形成链表结构即可满足。但是链表的缺点是只能依次顺序访问,这样访问文件中任何内容都要从头读取多个块,显然过于低效了。真正被广泛运用的解决方案是把形成链表的指针整合起来统一存放,这便形成了文件分配表 (opens new window)(File Allocation Table,FAT)的概念。既然已经有了专门组织块结构来构成文件的分配表,那在表中再加入其他控制信息,就能很方便地扩展出更多的高级功能,譬如除了文件占用的块地址信息外,加上文件的逻辑位置就形成了目录,加上文件的访问标志就形成了权限,还可以再加上文件的名称、创建时间、所有者、修改者等一系列的元数据信息来构成其他应用形式。人们把定义文件分配表应该如何实现、储存哪些信息、提供什么功能的标准称为文件系统 (opens new window)(File System),FAT32、NTFS、exFAT、ext2/3/4、XFS、BTRFS 等都是很常用的文件系统。而前面介绍存储插件接口时提到的对分区进行高级格式化操作,实际上就是在初始化一套空白的文件系统,供后续用户与应用程序访问。
文件存储相对于块存储来说是更高层次的存储类型,加入目录、权限等元素后形成的树状结构以及路径访问方式方便了人类理解、记忆和访问;文件系统能够提供哪个进程打开或正在读写某个文件的信息,这也有利于文件的共享处理。但在另一方面,计算机需要把路径进行分解,然后逐级向下查找,最后才能查找到需要的文件,要从文件分配表中确定具体数据存储的位置,要判断文件的访问权限,要记录每次修改文件的用户与时间,这些额外操作对于性能产生负面影响也是无可避免的,因此,如果一个系统选择不采用文件存储的话,那磁盘 I/O 性能一般就是最主要的决定因素。
对象储存:对象存储 (opens new window)是相对较新的数据存储形式,是一种随着云数据中心的兴起而发展起来的存储,是以非结构化数据为目标的存储方案。这里的“对象”可以理解为一个元数据及与其配对的一个逻辑数据块的组合,元数据提供了对象所包含的上下文信息,譬如数据的类型、大小、权限、创建人、创建时间,等等,数据块则存储了对象的具体内容。你也可以简单地理解为数据和元数据这两样东西共同构成了一个对象。每个对象都有属于自己的全局唯一标识,这个标识会直接开放给最终用户使用,作为访问该对象的主要凭据,通常会是 UUID 的形式。对象存储的访问接口就是根据该唯一标识,对逻辑数据块进行的读写删除操作,通常接口都会十分简单,甚至连修改操作都不会提供。
对象存储基本上只会在分布式存储系统之上去实现,由于对象存储天生就有明确的“元数据”概念,不必依靠文件系统来提供数据的描述信息,因此,完全可以将一大批对象的元数据集中存放在某一台(组)服务器上,再辅以多台 OSD(Object Storage Device)服务器来存储对象的数据块部分。当外部要访问对象时,多台 OSD 能够同时对外发送数据,因此对象存储不仅易于共享、容量庞大,还能提供非常高的吞吐量。不过,由于需要先经过元数据查询确定 OSD 存放对象的确切位置,该过程可能涉及多次网络传输,延迟方面就会表现得相对较差。
由于对象的元数据仅描述对象本身的信息,与其他对象都没有关联,换而言之每个对象都是相互独立的,自然也就不存在目录的概念,可见对象存储天然就是扁平化的,与软件系统中很常见的 K/V 访问相类似,不过许多对象存储会提供 Bucket 的概念,用户可以在逻辑上把它看作是“单层的目录”来使用。由于对象存储天生的分布式特性,以及极其低廉的扩展成本,使它很适合于CDN一类的应用,拿来存放图片、音视频等媒体内容,以及网页、脚本等静态资源。
4.4资源与调度
关键词:node、pod、predicate算法、etcd
1 | |
默认调度器
本节的最后一部分,我们回过头来探讨开篇提出的问题:Kubernetes 是如何撮合 Pod 与 Node 的,这其实也是最困难的一个问题。调度是为新创建出来的 Pod 寻找到一个最恰当的宿主机节点去运行它,这句话里就包含有“运行”和“恰当”两个调度中关键过程,它们具体是指:
- 运行:从集群所有节点中找出一批剩余资源可以满足该 Pod 运行的节点。为此,Kubernetes 调度器设计了一组名为 Predicate 的筛选算法。
- 恰当:从符合运行要求的节点中找出一个最适合的节点完成调度。为此,Kubernetes 调度器设计了一组名为 Priority 的评价算法。
这两个算法的具体内容稍后笔者会详细解释,这里要先说明白一点:在几个、十几个节点的集群里进行调度,调度器怎么实现都不会太困难,但是对于数千个乃至更多节点的大规模集群,要实现高效的调度就绝不简单。请你想象一下,若一个由数千节点组成的集群,每次 Pod 的创建都必须依据各节点的实时资源状态来确定调度的目标节点,然而各节点的资源是随着程序运行无时无刻都在变动的,资源状况只有它本身才清楚,如果每次调度都要发生数千次的远程访问来获取这些信息的话,那压力与耗时都难以降下来。结果不仅会令调度器成为集群管理的性能瓶颈,还会出现因耗时过长,某些节点上资源状况已发生变化,调度器的资源信息过时而导致调度结果不准确等问题。
Scheduler
Clusters and their workloads keep growing, and since the scheduler’s workload is roughly proportional to the cluster size, the scheduler is at risk of becoming a scalability bottleneck.
由于调度器的工作负载与集群规模大致成正比,随着集群和它们的工作负载不断增长,调度器很有可能会成为扩展性瓶颈所在。
—— Omega: Flexible, Scalable Schedulers for Large Compute Clusters (opens new window),Google
针对以上问题,Google 在论文《Omega: Flexible, Scalable Schedulers for Large Compute Clusters (opens new window)》里总结了自身的经验,并参考了当时Apache Mesos (opens new window)和Hadoop on Demand (opens new window)(HOD)的实现,提出了一种共享状态(Shared State)的双循环调度机制。这种调度机制后来不仅应用在 Google 的 Omega 系统(Borg 的下一代集群管理系统)中,也同样被 Kubernetes 继承了下来,它整体的工作流程如图 14-1 所示:
.png?token=AUR75HYFUW7PUZJREHST5P3EQXPEQ)
图 14-1 状态共享的双循环
状态共享的双循环中第一个控制循环可被称为“Informer Loop”,它是一系列Informer (opens new window)的集合,这些 Informer 持续监视 Etcd 中与调度相关资源(主要是 Pod 和 Node)的变化情况,一旦 Pod、Node 等资源出现变动,就会触发对应 Informer 的 Handler。Informer Loop 的职责是根据 Etcd 中的资源变化去更新调度队列(Priority Queue)和调度缓存(Scheduler Cache)中的信息,譬如当有新 Pod 生成,就将其入队(Enqueue)到调度队列中,如有必要,还会根据优先级触发上一节提到的插队和抢占操作。又譬如有新的节点加入集群,或者已有节点资源信息发生变动,Informer 也会将这些信息更新同步到调度缓存之中。
另一个控制循环可被称为“Scheduler Loop”,它的核心逻辑是不停地将调度队列中的 Pod 出队(Pop),然后使用 Predicate 算法进行节点选择。Predicate 本质上是一组节点过滤器(Filter),它根据预设的过滤策略来筛选节点,Kubernetes 中默认有三种过滤策略,分别是:
- 通用过滤策略:最基础的调度过滤策略,用来检查节点是否能满足 Pod 声明中需要的资源。譬如处理器、内存资源是否满足,主机端口与声明的 NodePort 是否存在冲突,Pod 的选择器或者nodeAffinity (opens new window)指定的节点是否与目标相匹配,等等。
- 卷过滤策略:与存储相关的过滤策略,用来检查节点挂载的 Volume 是否存在冲突(譬如将一个块设备挂载到两个节点上),或者 Volume 的可用区域是否与目标节点冲突,等等。在“Kubernetes 存储设计”中提到的 Local PersistentVolume 的调度检查,便是在这里处理的。
- 节点过滤策略:与宿主机相关的过滤策略,最典型的是 Kubernetes 的污点与容忍度机制 (opens new window)(Taints and Tolerations),譬如默认情况下 Kubernetes 会设置 Master 节点不允许被调度,这就是通过在 Master 中施加污点来避免的。之前提到的控制节点处于驱逐状态,或者在驱逐后一段时间不允许调度,也是在这个策略里实现的。
Predicate 算法所使用的一切数据均来自于调度缓存,绝对不会去远程访问节点本身。只有 Informer Loop 与 Etcd 的监视操作才会涉及到远程调用,Scheduler Loop 中除了最后的异步绑定要发起一次远程的 Etcd 写入外,其余全部都是进程内访问,这一点是调度器执行效率的重要保证。
调度缓存就是两个控制循环的共享状态(Shared State),这样的设计避免了每次调度时主动去轮询所有集群节点,保证了调度器的执行效率。但是并不能完全避免因节点信息同步不及时而导致调度过程中实际资源发生变化的情况,譬如节点的某个端口在获取调度信息后、发生实际调度前被意外占用了。为此,当调度结果出来以后,kubelet 真正创建 Pod 以前,还必须执行一次 Admit 操作,在该节点上重新做一遍 Predicate 来进行二次确认。
经过 Predicate 算法筛选出来符合要求的节点集,会交给 Priorities 算法来打分(0-10 分)排序,以便挑选出“最恰当”的一个。“恰当”是带有主观色彩的词语,Kubernetes 也提供了不同的打分规则来满足不同的主观需求,譬如最常用的 LeastRequestedPriority 规则,它的计算公式是:
1 | |
从公式上很容易看出这就是在选择处理器和内存空闲资源最多的节点,因为这些资源剩余越多,得分就越高。经常与它一起工作的是 BalancedResourceAllocation 规则,它的公式是:
1 | |
此公式中 cpuFraction、memoryFraction、volumeFraction 的含义分别是 Pod 请求的处理器、内存和存储资源占该节点上对应可用资源的比例,variance 函数的作用是计算资源之间的差距,差距越大,函数值越大。由此可知 BalancedResourceAllocation 规则的意图是希望调度完成后,所有节点里各种资源分配尽量均衡,避免节点上出现诸如处理器资源被大量分配、而内存大量剩余的尴尬状况。Kubernetes 内置的其他的评分规则还有 ImageLocalityPriority、NodeAffinityPriority、TaintTolerationPriority 等等,有兴趣的话可以阅读 Kubernetes 的源码,笔者就不再逐一解释了。
经过 Predicate 的筛选、Priorities 的评分之后,调度器已经选出了调度的最终目标节点,最后一步是通知目标节点的 kubelet 可以去创建 Pod 了。调度器并不会直接与 kubelet 通讯来创建 Pod,它只需要把待调度的 Pod 的nodeName字段更新为目标节点的名字即可,kubelet 本身会监视该值的变化来接手后续工作。不过,从调度器在 Etcd 中更新nodeName,到 kubelet 从 Etcd 中检测到变化,再执行 Admit 操作二次确认调度可行性,最后到 Pod 开始实际创建,这个过程可能会持续一段不短的时间,如果一直等待这些工作都完成了才宣告调度最终完成,那势必也会显著影响调度器的效率。实际上 Kubernetes 调度器采用了乐观绑定(Optimistic Binding)的策略来解决此问题,它会同步地更新调度缓存中 Pod 的nodeName字段,并异步地更新 Etcd 中 Pod 的nodeName字段,这个操作被称为绑定(Binding)。如果最终调度成功了,那 Etcd 与调度缓存中的信息最终必定会保持一致,否则,如果调度失败了,那将会由 Informer 来根据 Pod 的变动,将调度成功却没有创建成功的 Pod 清空nodeName字段,重新同步回调度缓存中,以便促使另外一次调度的开始。
最后,请注意笔者在这一个部分的小标题用的是“默认调度器”,这是强调以上行为仅是 Kubernetes 默认的行为。对调度过程的大部分行为,你都可以通过 Scheduler Framework 暴露的接口来进行扩展和自定义,如下图所示,绿色的部分就是 Scheduler Framework 暴露的扩展点。由于 Scheduler Framework 属于 Kubernetes 内部的扩展机制(通过 Golang 的 Plugin 机制来实现的,需静态编译),通用性与本章提到的其他扩展机制(CRI、CNI、CSI 那些)无法相提并论,属于较为高级的 Kubernetes 管理技能了,这里笔者仅在这里简单地提一下,就不多做介绍了。
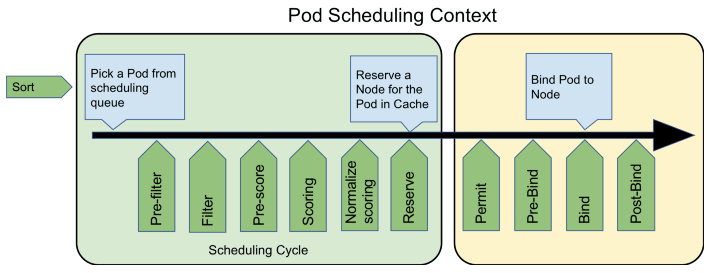
图 14-2 Scheduler Framework 的可扩展性(图片来源 (opens new window))
4.5服务网格
服务网格(Service Mesh)
A service mesh is a dedicated infrastructure layer for handling service-to-service communication. It’s responsible for the reliable delivery of requests through the complex topology of services that comprise a modern, cloud native application. In practice, the service mesh is typically implemented as an array of lightweight network proxies that are deployed alongside application code, without the application needing to be aware.
服务网格是一种用于管控服务间通信的的基础设施,职责是为现代云原生应用支持网络请求在复杂的拓扑环境中可靠地传递。在实践中,服务网格通常会以轻量化网络代理的形式来体现,这些代理与应用程序代码会部署在一起,对应用程序来说,它完全不会感知到代理的存在。
关键词:
透明传输
1 | |
4.5.1透明通信的涅槃
通信的成本
程序间通信作为分布式架构的核心内容,第一章“服务架构演进史”中笔者就已从宏观角度讲述过它的演进过程。这节里,我们会从更微观更聚焦的角度,分析不同时期应用程序如何看待与实现通信方面的非功能性需求,如何做到可靠的通信的,通过以下五个阶段的变化,理解分布式服务的通信是如何逐步演化成本章主角服务网格。
第一阶段:将通信的非功能性需求视作业务需求的一部分,通信的可靠性由程序员来保障。
本阶段是软件企业刚刚开始尝试分布式时选择的早期技术策略。这类系统原本所具有的通信能力一般并不是作为系统功能的一部分被设计出来的,而是遇到问题后修补累积所形成的。开始时,系统往往只具最基本的网络 API,譬如集成了 OKHTTP、gRPC 这样库来访问远程服务,如果远程访问接收到异常,就编写对应的重试或降级逻辑去应对处理。在系统进入生产环境以后,遇到并解决的一个个通信问题,逐渐在业务系统中留下了越来越多关于通信的代码逻辑。这些通信的逻辑由业务系统的开发人员直接编写,与业务逻辑直接共处在一个进程空间之中,如图 15-1 所示(注:本图与后面一系列图片中,笔者均以“断路器”和“服务发现”这两个常见的功能来泛指所有的分布式通信所需的能力,实际上并不局限于这两个功能)。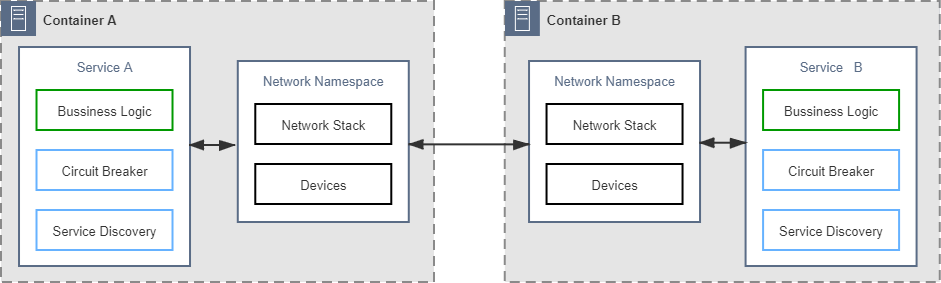 图 15-1 控制逻辑和业务逻辑耦合
图 15-1 控制逻辑和业务逻辑耦合这一阶段的主要矛盾是绝大多数擅长业务逻辑的开发人员都并不擅长处理通信方面的问题,要写出正确、高效、健壮的分布式通信代码,是一项专业性极强的工作。由此决定了大多数的普通软件企业都很难在这个阶段支撑起一个靠谱的分布式系统来。另一方面,把专业的通信功能强加于普通开发人员,无疑为他们带来了更多工作量,尤其是这些“额外的工作”与原有的业务逻辑耦合在一起,让系统越来越复杂,也越来越容易出错。
第二阶段:将代码中的通信功能抽离重构成公共组件库,通信的可靠性由专业的平台程序员来保障。
开发人员解耦依赖的一贯有效办法是抽取分离代码与封装重构组件。微服务的普及离不开一系列封装了分布式通信能力的公共组件库,代表性产品有 Twitter 的 Finagle、Spring Cloud 中的许多组件等。这些公共的通信组件由熟悉分布式的专业开发人员编写和维护,不仅效率更高、质量更好,一般还都提供了经过良好设计的 API 接口,让业务代码既可以使用它们的能力,又无需把处理通信的逻辑散布于业务代码当中。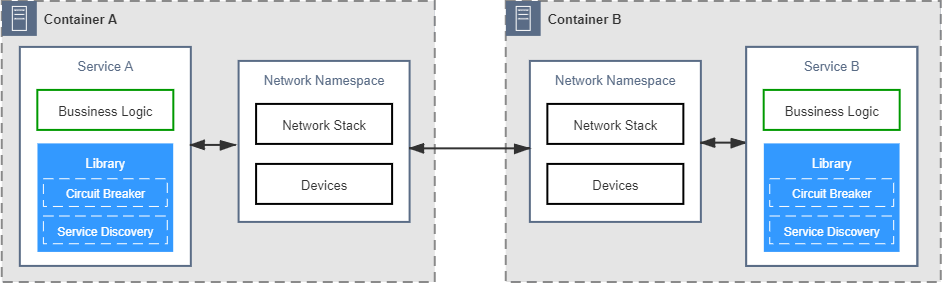 图 15-2 抽取公共的分布式通信组件
图 15-2 抽取公共的分布式通信组件分布式通信组件让普通程序员开发出靠谱的微服务系统成为可能,这是无可抹杀的成绩,但普通程序员使用它们的成本依然很高,不仅要学习分布式的知识、要学习这些公共组件的功能应该如何使用,最麻烦的是,对于同一种问题往往还需学习多种不同的组件才能解决。这是因为通信组件首先是一段特定编程语言开发出来的程序,是与语言绑定的,一个由 Python 编写的组件再优秀,对 Java 系统来说也没有太多的实用价值。目前,基于公共组件库开发微服务仍然是应用最为广泛的解决方案,但肯定不是一种完美的解决方案,这是微服务基础设施完全成熟之前必然会出现的应用形态,同时也一定是微服务进化过程中必然会被替代的过渡形态。
第三阶段:将负责通信的公共组件库分离到进程之外,程序间通过网络代理来交互,通信的可靠性由专门的网络代理提供商来保障。
为了能够把分布式通信组件与具体的编程语言脱钩,也为了避免程序员还要去专门学习这些组件的编程模型与 API 接口,这一阶段进化出了能专门负责可靠通信的网络代理。这些网络代理不再与业务逻辑部署于同一个进程空间,但仍然与业务系统处于同一个容器或者虚拟机当中,可以通过回环设备甚至是UDS (opens new window)(Unix Domain Socket)进行交互,具备相当高的网络性能。只要让网络代理接管掉程序七层或四层流量,就能够在代理上完成断路、容错等几乎所有的分布式通信功能,前面提到过的 Netflix Prana 就属于这类产品的典型代表。
图 15-3 通过网络代理获得可靠的通信能力
通过网络代理来提升通信质量的思路提出以后,它本身使用范围其实并不算特别广泛,但它的方向是正确的。这种思路后来演化出了两种改进形态:一方面,如果将网络代理从进程身边拉远,让它与进程分别处于不同的机器上,这样就可以同时给多个进程提供可靠通信的代理服务,这条路线逐渐形成了今天常见的微服务网关,在网关上同样可以实现流控、容错等功能。另一方面,如果将网络代理往进程方向推近,不仅让它与进程处于一个共享了网络名称空间的容器组之中,还要让它透明并强制地接管通讯,这便形成了下一阶段所说的边车代理。
第四阶段:将网络代理以边车的形式注入到应用容器,自动劫持应用的网络流量,通信的可靠性由专门的通信基础设施来保障。
与前一阶段的独立代理相比,以边车模式运作的网络代理拥有两个无可比拟的优势:第一个优势是它对流量的劫持是强制性的,通常是靠直接写容器的 iptables 转发表来实现。此前,独立的网络代理只有程序首先去访问它,它才能被动地为程序提供可靠通信服务,只要程序依然有选择不访问它的可能性,代理就永远只能充当服务者而不能成为管理者,上阶段的图中保留了两个容器网络设备直接连接的箭头就代表这种可能性,而这一阶段图中,服务与网络名称空间的虚线箭头代表被劫持后应用程序以为存在,但实际并不存在的流量。
另一个优势是边车代理对应用是透明的,无需对已部署的应用程序代码进行任何改动,不需要引入任何的库(这点并不是绝对的,有部分边车代理也会要求有轻量级的 SDK),也不需要程序专门去访问某个特定的网络位置。这意味着它对所有现存程序都具备开箱即用的适应性,无需修改旧程序就能直接享受到边车代理的服务,这样它的适用面就变得十分广泛。目前边车代理的代表性产品有 Linkerd、Envoy、MOSN 等。
图 15-4 边车代理模式
如果说边车代理还有什么不足之处的话,那大概就是来自于运维人员的不满了。边车代理能够透明且具有强制力地解决可靠通信的问题,但它本身也需要有足够的信息才能完成这项工作,譬如获取可用服务的列表,譬如得到每个服务名称对应的 IP 地址,等等。这些信息不会从天上掉下来自动到边车里去,是需要由管理员主动去告知代理,或者代理主动从约定好的位置获取。可见,管理代理本身也会产生额外的通信需求。如果没有额外的支持,这些管理方面的通信都得由运维人员去埋单,由此而生的不满便可以理解。为了管理与协调边车代理,程序间通信进化到了最后一个阶段:服务网格。
第五阶段:将边车代理统一管控起来实现安全、可控、可观测的通信,将数据平面与控制平面分离开来,实现通用、透明的通信,这项工作就由专门的服务网格框架来保障。
从总体架构看,服务网格包括两大块内容,分别是由一系列与微服务共同部署的边车代理,以及用于控制这些代理的管理器所构成。代理与代理之间需要通信,用以转发程序间通信的数据包;代理与管理器之间也需要通信,用以传递路由管理、服务发现、数据遥测等控制信息。服务网格使用数据平面 (opens new window)(Data Plane)通信和控制平面 (opens new window)(Control Plane)通信来形容这两类流量,下图中实线就表示数据平面通信,虚线表示控制平面通信。
图 15-5 服务网格的控制平面通信与数据平面通信(图片来源 (opens new window))
数据平面与控制平面并不是什么新鲜概念,它最初就是用在计算机网络之中的术语,通常是指网络层次的划分,软件定义网络中将解耦数据平面与控制平面作为其最主要特征之一。服务网格把计算机网络的经典概念引入到程序通信之中,既可以说是对程序通信的一种变革创新,也可以说是对网络通信的一种发展传承。
分离数据平面与控制平面的实质是将“程序”与“网络”进行解耦,将网络可能出现的问题(譬如中断后重试、降级),与可能需要的功能(譬如实现追踪度量)的处理过程从程序中拿出,放到由控制平面指导的数据平面通信中去处理,制造出一种“这些问题在程序间通信中根本不存在”的假象,仿佛网络和远程服务都是完美可靠的。这种完美的假象,让应用之间可以非常简单地交互而不必过多考虑异常情况,也能够在不同的程序框架、不同的云服务提供商环境之间平稳地迁移;同时,还能让管理者能够不依赖程序支持就得到遥测所需的全部信息,能够根据角色、权限进行统一的访问控制,这些都是服务网格的价值所在。
数据平面
在“数据平面”和“控制平面”这两节里,笔者会延续服务网格将“程序”与“网络”解耦的思路,介绍几个数据平面通信与控制平面通信中的核心问题是如何解决的。在工业界,数据平面已有 Linkerd、Nginx、Envoy 等产品,控制平面也有 Istio、Open Service Mesh、Consul 等产品,后文中笔者主要是以目前市场占有率最高的 Istio 与 Envoy 为目标进行讲述,但讲述的目的是介绍两种平面通信的技术原理,而不是介绍 Istio 和 Envoy 的功能与用法,这里涉及到的原理在各种服务网格产品中一般都是通用的,并不局限于哪一种具体实现。
数据平面由一系列边车代理所构成,核心职责是转发应用的入站(Inbound)和出站(Outbound)数据包,因此数据平面也有个别名叫转发平面 (opens new window)(Forwarding Plane)。同时,为了在不可靠的物理网络中保证程序间通信最大的可靠性,数据平面必须根据控制平面下发策略的指导,在应用无感知的情况下自动完成服务路由、健康检查、负载均衡、认证鉴权、产生监控数据等一系列工作。为了达成上述的工作目标,至少需要妥善解决以下三个关键问题:
- 代理注入:边车代理是如何注入到应用程序中的?
- 流量劫持:边车代理是如何劫持应用程序的通信流量的?
- 可靠通信:边车代理是如何保证应用程序的通信可靠性的?
代理注入
流量劫持
可靠通行
控制平面
如果说数据平面是行驶中的车辆,那控制平面就是车辆上的导航系统;如果说数据平面是城市的交通道路,那控制平面就是路口的指示牌与交通信号灯。控制平面的特点是不直接参与程序间通信,而只会与数据平面中的代理通信,在程序不可见的背后,默默地完成下发配置和策略,指导数据平面工作。由于服务网格(暂时)没有大规模引入计算机网络中管理平面 (opens new window)(Management Plane)等其他概念,所以控制平面通常也会附带地实现诸如网络行为的可视化、配置传输等一系列管理职能(其实还是有专门的管理平面工具的,譬如Meshery (opens new window)、ServiceMeshHub (opens new window))。笔者仍然以 Istio 为例具体介绍一下控制平面的主要功能。
Istio 在 1.5 版本之前,Istio 自身也是采用微服务架构开发的,将控制平面的职责分解为 Mixer、Pilot、Galley、Citadel 四个模块去实现,其中 Mixer 负责鉴权策略与遥测;Pilot 负责对接 Envoy 的数据平面,遵循 xDS 协议进行策略分发;Galley 负责配置管理,为服务网格提供外部配置感知能力;Citadel 负责安全加密,提供服务和用户层面的认证和鉴权、管理凭据和 RBAC 等安全相关能力。不过,经过两、三年的实践应用,很多用户都有反馈 Istio 的微服务架构有过度设计的嫌疑,lstio 在定义项目目标时,曾非常理想化的提出控制平面的各个组件都应可以独立部署,然而在实际应用场景里却并非如此,独立的组件反而带来了部署复杂、职责划分不清晰等问题。

图 15-9 Istio 1.5 版本之后的架构(图片来自Istio 官方文档 (opens new window))
从 1.5 版本起,Istio 重新回归单体架构,将 Pilot、Galley、Citadel 的功能全部集成到新的 Istiod 之中。当然,这也并不是说完全推翻之前的设计,只是将原有的多进程形态优化成单进程的形态,之前各个独立组件变成了 Istiod 的内部逻辑上的子模块而已。单体化之后出现的新进程 Istiod 就承担所有的控制平面职责,具体包括有:
数据平面交互
:这是部分是满足服务网格正常工作所需的必要工作,具体有:
- 边车注入:在 Kubernetes 中注册 Mutating Webhook 控制器,实现代理容器的自动注入,并生成 Envoy 的启动配置信息。
- 策略分发:接手了原来 Pilot 的核心工作,为所有的 Envoy 代理提供符合 xDS 协议的策略分发的服务。
- 配置分发:接手了原来 Galley 的核心工作,负责监听来自多种支持配置源的数据,譬如 kube-apiserver,本地配置文件,或者定义为网格配置协议 (opens new window)(Mesh Configuration Protocol,MCP)的配置信息。原来 Galley 需要处理的 API 校验和配置转发功能也包含在内。
流量控制
:这通常是用户使用服务网格的最主要目的,具体包括以下几个方面:
- 请求路由:通过VirtualService (opens new window)、DestinationRule (opens new window)等 Kubernetes CRD 资源实现了灵活的服务版本切分与规则路由。譬如根据服务的迭代版本号(如 v1.0 版、v2.0 版)、根据部署环境(如 Development 版、Production 版)作为路由规则来控制流量,实现诸如金丝雀发布这类应用需求。
- 流量治理:包括熔断、超时、重试等功能,譬如通过修改 Envoy 的最大连接数,实现对请求的流量控制;通过修改负载均衡策略,在轮询、随机、最少访问等方式间进行切换;通过设置异常探测策略,将满足异常条件的实例从负载均衡池中摘除,以保证服务的稳定性,等等。
- 调试能力:包括故障注入和流量镜像等功能,譬如在系统中人为的设置一些故障,来测试系统的容错稳定性和系统恢复的能力。又譬如通过复制一份请求流量,把它发送到镜像服务,从而满足A/B 验证 (opens new window)的需要。
通信安全
:包括通信中的加密、凭证、认证、授权等功能,具体有:
可观测性
:包括日志、追踪、度量三大块能力,具体有:
- 日志收集:程序日志的收集并不属于服务网格的处理范畴,通常会使用 ELK Stack 去完成,这里是指远程服务的访问日志的收集,对等的类比目标应该是以前 Nginx、Tomcat 的访问日志。
- 链路追踪:为请求途经的所有服务生成分布式追踪数据并自动上报,运维人员可以通过 Zipkin 等追踪系统从数据中重建服务调用链,开发人员可以借此了解网格内服务的依赖和调用流程。
- 指标度量:基于四类不同的监控标识(响应延迟、流量大小、错误数量、饱和度)生成一系列观测不同服务的监控指标,用于记录和展示网格中服务状态。****