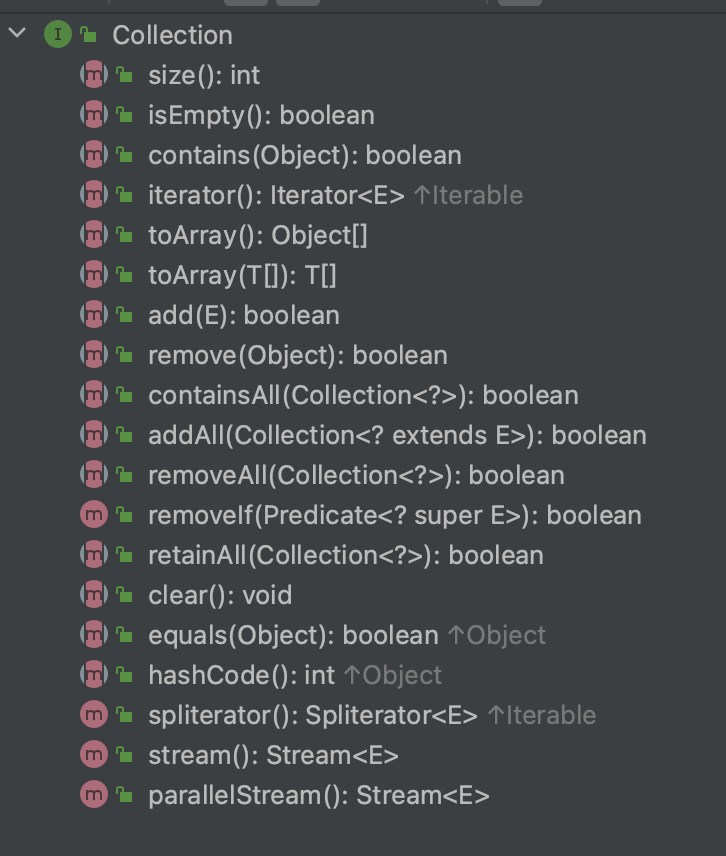
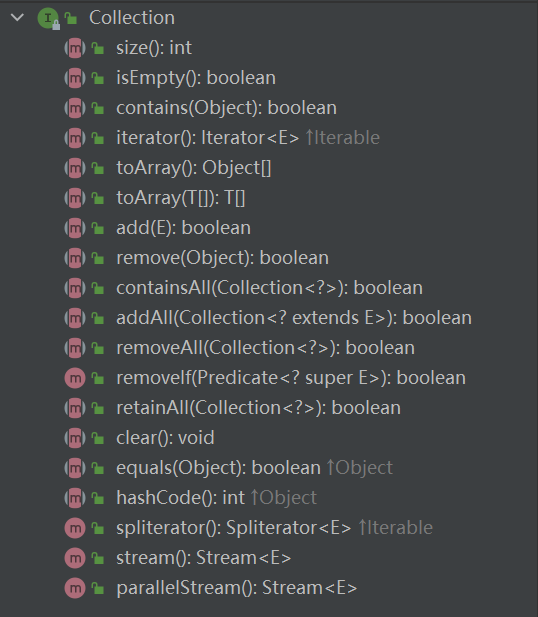
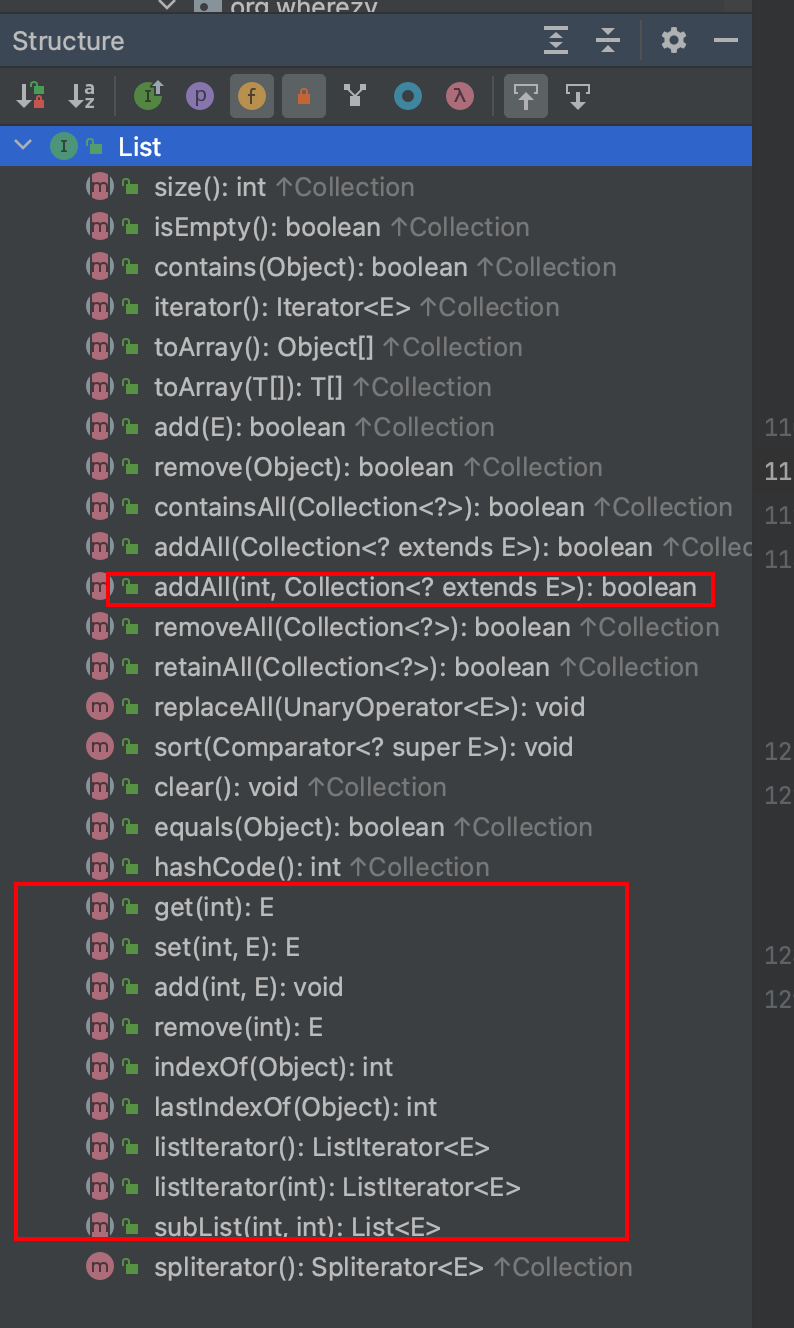
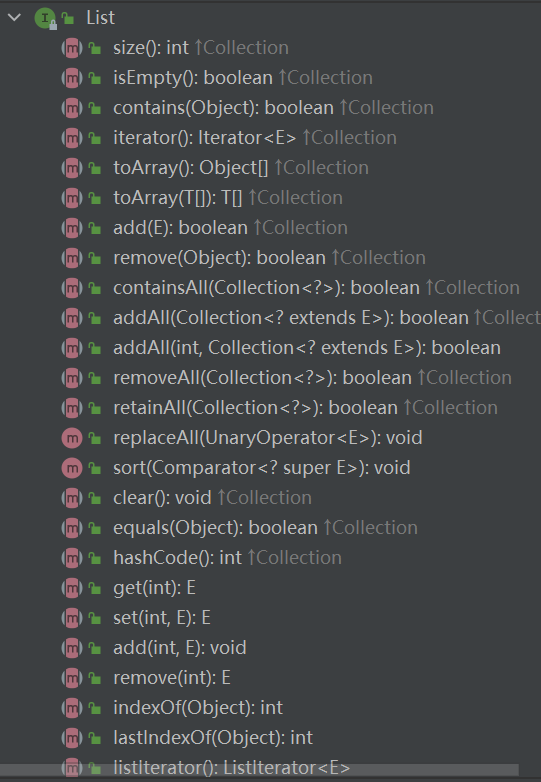
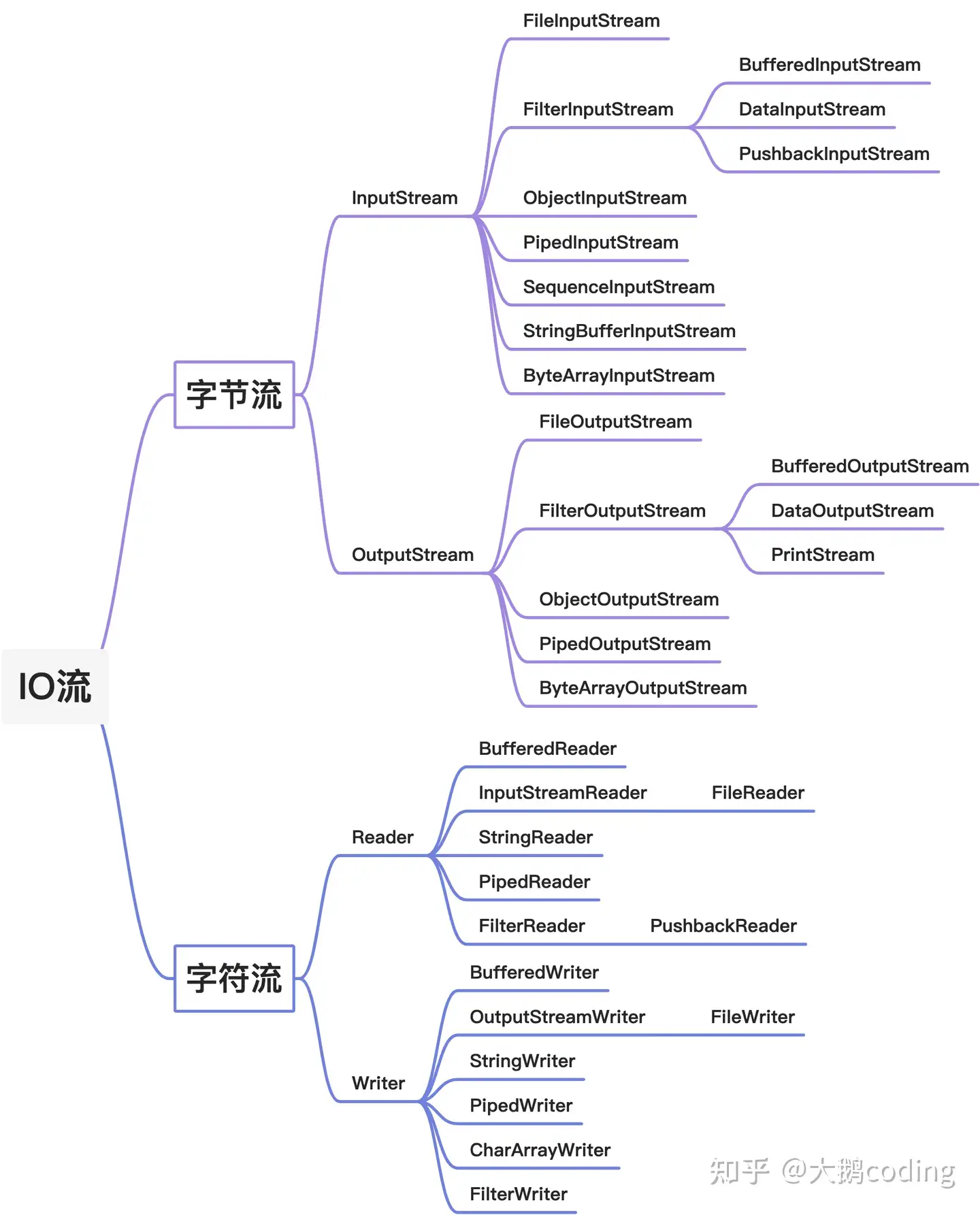
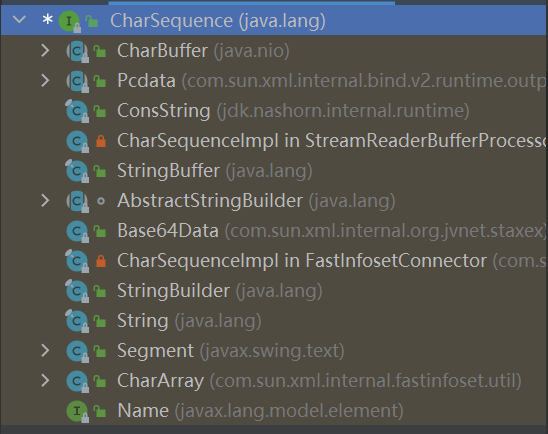
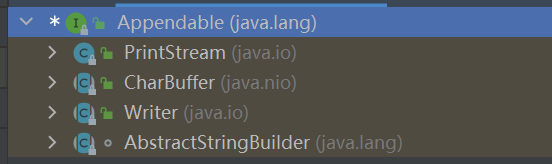
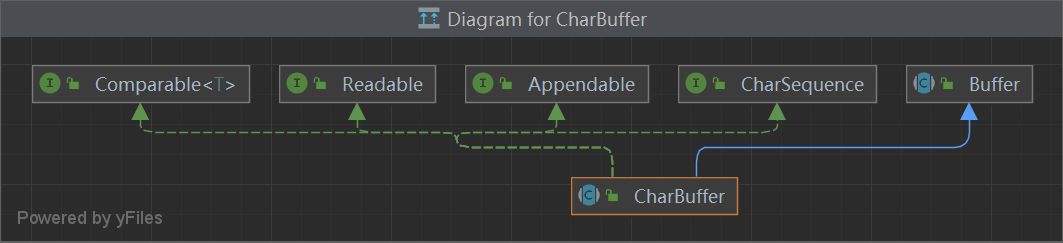
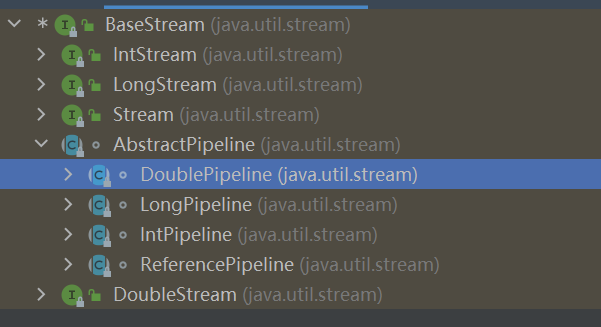
List size isEmpty contains iterator toArray toArray add remove containsAll addAll addAll removeAll retainAll replaceAll sort clear equals hashCode get set add remove indexOf lastIndexOf listIterator listIterator subList spliterator
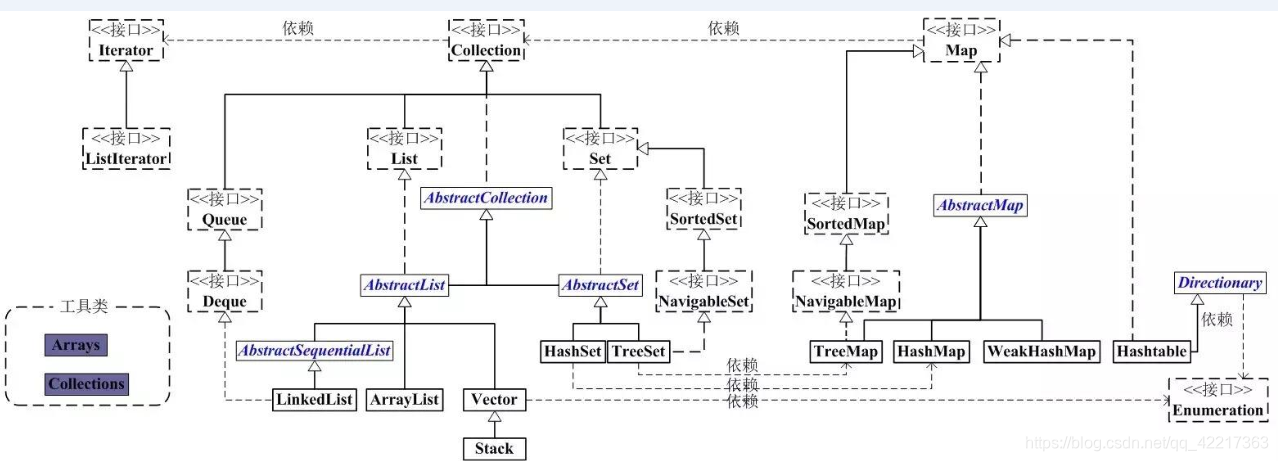
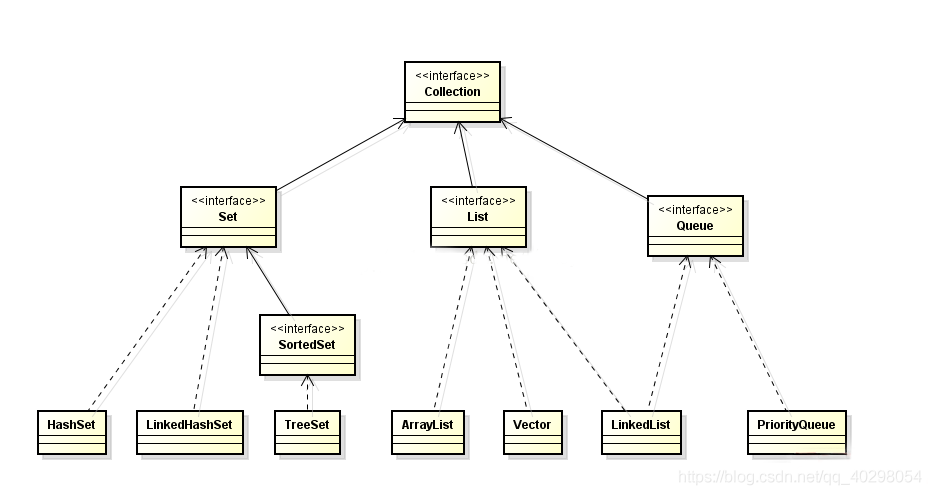
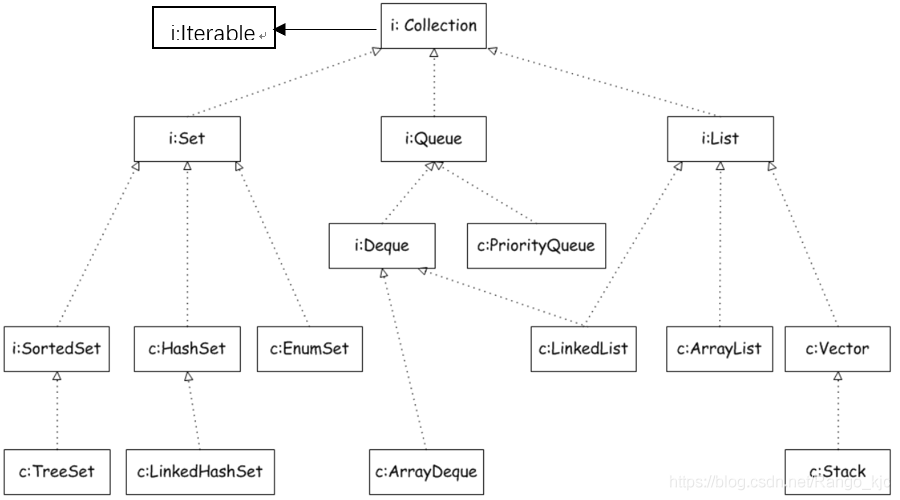
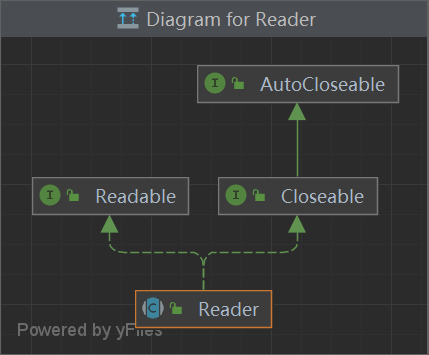
一、List有序,可重复
ArrayList 优点:底层数据结构是数组,查询快,增删慢。
缺点:线程不安全,效率高
Vector 优点:底层数据结构是数组,查询快。增删慢。
缺点:线程安全,效率低
Stack继承自Vector,实现一个后进先出的堆栈。
LinkedList 优点:底层数据结构是链表,查询慢,增删快。
缺点:线程不安全,效率高
List集合特有的一些方法,如sort默认实现
1 2 3 4 5 6 7 8 9 10 11 12 13
defaultvoidsort(Comparator<? super E> c) { // 转为数组 Object[] a = this.toArray(); // 数组排序 Arrays.sort(a, (Comparator) c); ListIterator<E> i = this.listIterator(); // 数组复制到集合 for (Object e : a) { i.next(); i.set((E) e); } }
/** * Retrieves, but does not remove, the head of this queue. This method * differs from {@link #peek peek} only in that it throws an exception * if this queue is empty. * * @return the head of this queue * @throws NoSuchElementException if this queue is empty */ E element();
/* * * @implSpec * <p>The default implementation behaves as if: * <pre>{@code * for (T t : this) * action.accept(t); * }</pre> * * @param action The action to be performed for each element * @throws NullPointerException if the specified action is null * @since 1.8 */ defaultvoidforEach(Consumer<? super T> action) { Objects.requireNonNull(action); for (T t : this) { action.accept(t); } }
/** * Creates a {@link Spliterator} over the elements described by this * {@code Iterable}. * * @implSpec * The default implementation creates an * <em><a href="Spliterator.html#binding">early-binding</a></em> * spliterator from the iterable's {@code Iterator}. The spliterator * inherits the <em>fail-fast</em> properties of the iterable's iterator. * * @implNote * The default implementation should usually be overridden. The * spliterator returned by the default implementation has poor splitting * capabilities, is unsized, and does not report any spliterator * characteristics. Implementing classes can nearly always provide a * better implementation. * * @return a {@code Spliterator} over the elements described by this * {@code Iterable}. * @since 1.8 */ default Spliterator<T> spliterator() { return Spliterators.spliteratorUnknownSize(iterator(), 0); } }
privateclassItrimplementsIterator<E> { int cursor; // index of next element to return intlastRet= -1; // index of last element returned; -1 if no such intexpectedModCount= modCount;
Itr() {}
publicbooleanhasNext() { return cursor != size; }
@SuppressWarnings("unchecked") public E next() { checkForComodification(); inti= cursor; if (i >= size) thrownewNoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) thrownewConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; }
publicvoidremove() { if (lastRet < 0) thrownewIllegalStateException(); checkForComodification();
@Override @SuppressWarnings("unchecked") publicvoidforEachRemaining(Consumer<? super E> consumer) { Objects.requireNonNull(consumer); finalintsize= ArrayList.this.size; inti= cursor; if (i >= size) { return; } final Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) { thrownewConcurrentModificationException(); } while (i != size && modCount == expectedModCount) { consumer.accept((E) elementData[i++]); } // update once at end of iteration to reduce heap write traffic cursor = i; lastRet = i - 1; checkForComodification(); }
finalvoidcheckForComodification() { if (modCount != expectedModCount) thrownewConcurrentModificationException(); } } 123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566
public E next() { checkForComodification(); inti= cursor; if (i >= size) thrownewNoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) thrownewConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; } 1234567891011
每次使用next方法是都会调用一个方法checkForComodification(),查看源码
1 2 3 4 5
finalvoidcheckForComodification() { if (modCount != expectedModCount) thrownewConcurrentModificationException(); } 1234
/** * Performs this operation on the given argument. * * @param t the input argument */ voidaccept(T t);
/** * Returns a composed {@code Consumer} that performs, in sequence, this * operation followed by the {@code after} operation. If performing either * operation throws an exception, it is relayed to the caller of the * composed operation. If performing this operation throws an exception, * the {@code after} operation will not be performed. * * @param after the operation to perform after this operation * @return a composed {@code Consumer} that performs in sequence this * operation followed by the {@code after} operation * @throws NullPointerException if {@code after} is null // con1.accept(name); // con2.accept(name); // 返回一个组合的Consumer con1.andThen(con2) -- 封装为一个Consumer = .accept(name); -- 接收参数 // 将两个Consumer封装为一个Consumer, // 在一个Consumer中调用两个的accept(t),传递参数 */ default Consumer<T> andThen(Consumer<? super T> after) { Objects.requireNonNull(after); return (T t) -> { accept(t); after.accept(t); }; } }
Predicate接口
Predicate< T >:常用的四个方法
boolean test(T t):对给定的参数进行判断(判断逻辑由Lambda表达式实现),返回一个布尔值 default Predicate< T > negate():返回一个逻辑的否定,对应逻辑非 default Predicate< T > and():返回一个组合判断,对应短路与 default Predicate< T > or():返回一个组合判断,对应短路或 isEqual():测试两个参数是否相等 Predicate< T >:接口通常用于判断参数是否满足指定的条件
R apply(T t):将此函数应用于给定的参数 default< V >:Function andThen(Function after):返回一个组合函数,首先将该函数应用于输入,然后将after函数应用于结果 Function<T,R>:接口通常用于对参数进行处理,转换(处理逻辑由Lambda表达式实现),然后返回一个新值
private Object readObject0(boolean unshared)throws IOException { booleanoldMode= bin.getBlockDataMode(); if (oldMode) { intremain= bin.currentBlockRemaining(); if (remain > 0) { thrownewOptionalDataException(remain); } elseif (defaultDataEnd) { /* * Fix for 4360508: stream is currently at the end of a field * value block written via default serialization; since there * is no terminating TC_ENDBLOCKDATA tag, simulate * end-of-custom-data behavior explicitly. */ thrownewOptionalDataException(true); } bin.setBlockDataMode(false); }
case TC_CLASSDESC: case TC_PROXYCLASSDESC: return readClassDesc(unshared);
case TC_STRING: case TC_LONGSTRING: return checkResolve(readString(unshared));
case TC_ARRAY: return checkResolve(readArray(unshared));
case TC_ENUM: return checkResolve(readEnum(unshared));
case TC_OBJECT: return checkResolve(readOrdinaryObject(unshared));
case TC_EXCEPTION: IOExceptionex= readFatalException(); thrownewWriteAbortedException("writing aborted", ex);
case TC_BLOCKDATA: case TC_BLOCKDATALONG: if (oldMode) { bin.setBlockDataMode(true); bin.peek(); // force header read thrownewOptionalDataException( bin.currentBlockRemaining()); } else { thrownewStreamCorruptedException( "unexpected block data"); }
case TC_ENDBLOCKDATA: if (oldMode) { thrownewOptionalDataException(true); } else { thrownewStreamCorruptedException( "unexpected end of block data"); }
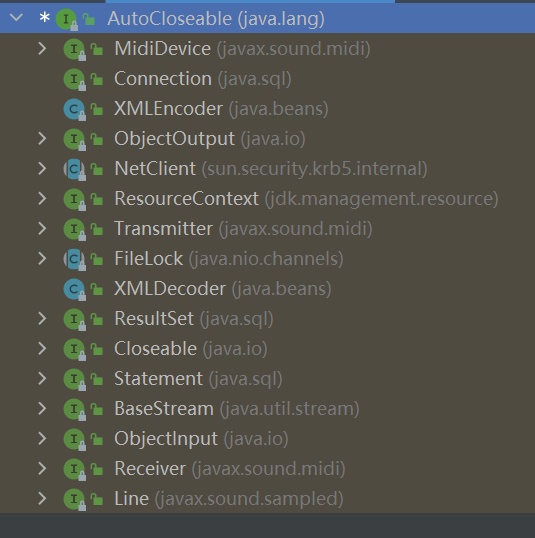
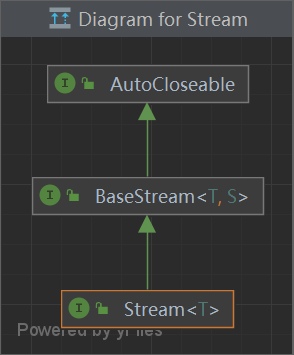
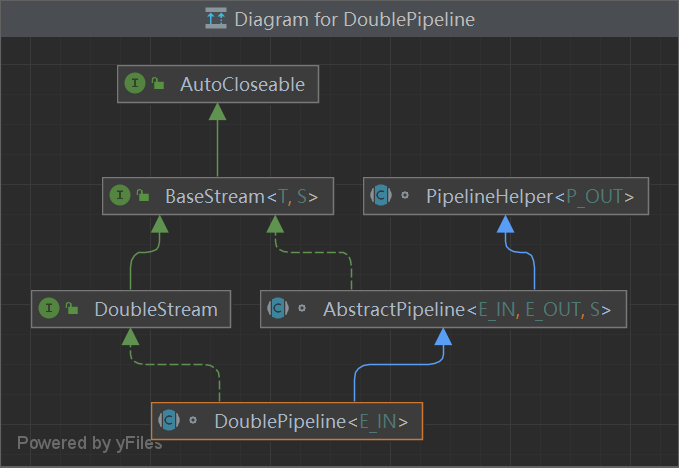
/* The {@link #close()} method of an {@code AutoCloseable} * object is called automatically when exiting a {@code * try}-with-resources block for which the object has been declared in * the resource specification header.*/ publicinterfaceAutoCloseable { voidclose()throws Exception; }
/** * Appends the specified character sequence to this <tt>Appendable</tt>. */ Appendable append(CharSequence csq)throws IOException;
/** * Appends a subsequence of the specified character sequence to this * <tt>Appendable</tt>. * * <p> An invocation of this method of the form <tt>out.append(csq, start, * end)</tt> when <tt>csq</tt> is not <tt>null</tt>, behaves in * exactly the same way as the invocation */ Appendable append(CharSequence csq, int start, int end)throws IOException;
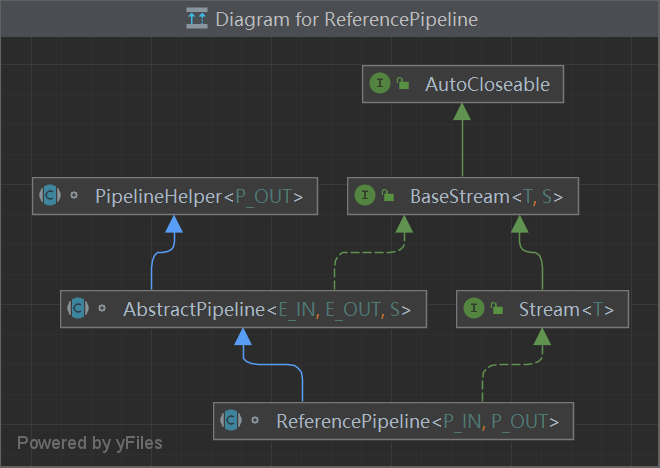
// @param <P_OUT> type of output elements from the pipeline abstractclassPipelineHelper<P_OUT> {
/** * Gets the stream shape for the source of the pipeline segment. * * @return the stream shape for the source of the pipeline segment. */ abstract StreamShape getSourceShape();
/** * Gets the combined stream and operation flags for the output of the described * pipeline. This will incorporate stream flags from the stream source, all * the intermediate operations and the terminal operation. * * @return the combined stream and operation flags * @see StreamOpFlag */ abstractintgetStreamAndOpFlags();
/** * Returns the exact output size of the portion of the output resulting from * applying the pipeline stages described by this {@code PipelineHelper} to * the the portion of the input described by the provided * {@code Spliterator}, if known. If not known or known infinite, will * return {@code -1}. * * @apiNote * The exact output size is known if the {@code Spliterator} has the * {@code SIZED} characteristic, and the operation flags * {@link StreamOpFlag#SIZED} is known on the combined stream and operation * flags. * * @param spliterator the spliterator describing the relevant portion of the * source data * @return the exact size if known, or -1 if infinite or unknown */ abstract<P_IN> longexactOutputSizeIfKnown(Spliterator<P_IN> spliterator);
/** * Applies the pipeline stages described by this {@code PipelineHelper} to * the provided {@code Spliterator} and send the results to the provided * {@code Sink}. * * @implSpec * The implementation behaves as if: * <pre>{@code * intoWrapped(wrapSink(sink), spliterator); * }</pre> * * @param sink the {@code Sink} to receive the results * @param spliterator the spliterator describing the source input to process */ abstract<P_IN, S extendsSink<P_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator);
/** * Pushes elements obtained from the {@code Spliterator} into the provided * {@code Sink}. If the stream pipeline is known to have short-circuiting * stages in it (see {@link StreamOpFlag#SHORT_CIRCUIT}), the * {@link Sink#cancellationRequested()} is checked after each * element, stopping if cancellation is requested. * * @implSpec * This method conforms to the {@code Sink} protocol of calling * {@code Sink.begin} before pushing elements, via {@code Sink.accept}, and * calling {@code Sink.end} after all elements have been pushed. * * @param wrappedSink the destination {@code Sink} * @param spliterator the source {@code Spliterator} */ abstract<P_IN> voidcopyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
/** * Pushes elements obtained from the {@code Spliterator} into the provided * {@code Sink}, checking {@link Sink#cancellationRequested()} after each * element, and stopping if cancellation is requested. * * @implSpec * This method conforms to the {@code Sink} protocol of calling * {@code Sink.begin} before pushing elements, via {@code Sink.accept}, and * calling {@code Sink.end} after all elements have been pushed or if * cancellation is requested. * * @param wrappedSink the destination {@code Sink} * @param spliterator the source {@code Spliterator} */ abstract <P_IN> voidcopyIntoWithCancel(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator);
/** * Takes a {@code Sink} that accepts elements of the output type of the * {@code PipelineHelper}, and wrap it with a {@code Sink} that accepts * elements of the input type and implements all the intermediate operations * described by this {@code PipelineHelper}, delivering the result into the * provided {@code Sink}. * * @param sink the {@code Sink} to receive the results * @return a {@code Sink} that implements the pipeline stages and sends * results to the provided {@code Sink} */ abstract<P_IN> Sink<P_IN> wrapSink(Sink<P_OUT> sink);
/** * Constructs a @{link Node.Builder} compatible with the output shape of * this {@code PipelineHelper}. * * @param exactSizeIfKnown if >=0 then a builder will be created that has a * fixed capacity of exactly sizeIfKnown elements; if < 0 then the * builder has variable capacity. A fixed capacity builder will fail * if an element is added after the builder has reached capacity. * @param generator a factory function for array instances * @return a {@code Node.Builder} compatible with the output shape of this * {@code PipelineHelper} */ abstract Node.Builder<P_OUT> makeNodeBuilder(long exactSizeIfKnown, IntFunction<P_OUT[]> generator);
/** * Collects all output elements resulting from applying the pipeline stages * to the source {@code Spliterator} into a {@code Node}. * * @implNote * If the pipeline has no intermediate operations and the source is backed * by a {@code Node} then that {@code Node} will be returned (or flattened * and then returned). This reduces copying for a pipeline consisting of a * stateful operation followed by a terminal operation that returns an * array, such as: * <pre>{@code * stream.sorted().toArray(); * }</pre> * * @param spliterator the source {@code Spliterator} * @param flatten if true and the pipeline is a parallel pipeline then the * {@code Node} returned will contain no children, otherwise the * {@code Node} may represent the root in a tree that reflects the * shape of the computation tree. * @param generator a factory function for array instances * @return the {@code Node} containing all output elements */ abstract<P_IN> Node<P_OUT> evaluate(Spliterator<P_IN> spliterator, boolean flatten, IntFunction<P_OUT[]> generator); }
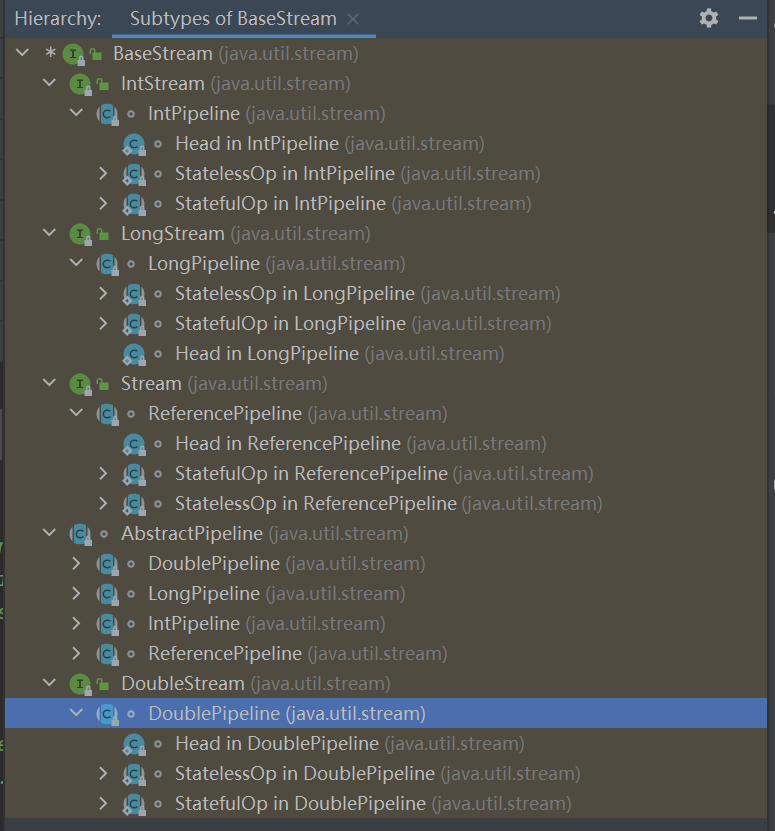
enumStreamShape { /** * The shape specialization corresponding to {@code Stream} and elements * that are object references. */ REFERENCE, /** * The shape specialization corresponding to {@code IntStream} and elements * that are {@code int} values. */ INT_VALUE, /** * The shape specialization corresponding to {@code LongStream} and elements * that are {@code long} values. */ LONG_VALUE, /** * The shape specialization corresponding to {@code DoubleStream} and * elements that are {@code double} values. */ DOUBLE_VALUE }
/* @param <E_IN> type of input elements * @param <E_OUT> type of output elements * @param <S> type of the subclass implementing {@code BaseStream} */ abstractclassAbstractPipeline<E_IN, E_OUT, S extendsBaseStream<E_OUT, S>> extendsPipelineHelper<E_OUT> implementsBaseStream<E_OUT, S> { /** * 初始的包含待处理元素的流 */ @SuppressWarnings("rawtypes") privatefinal AbstractPipeline sourceStage;
/** * The source supplier. Only valid for the head pipeline. Before the * pipeline is consumed if non-null then {@code sourceSpliterator} must be * null. After the pipeline is consumed if non-null then is set to null. */ private Supplier<? extendsSpliterator<?>> sourceSupplier;
/* * Each characteristic takes up 2 bits in a bit set to accommodate * preserving, clearing and setting/injecting information. * * This applies to stream flags, intermediate/terminal operation flags, and * combined stream and operation flags. Even though the former only requires * 1 bit of information per characteristic, is it more efficient when * combining flags to align set and inject bits. * * Characteristics belong to certain types, see the Type enum. Bit masks for * the types are constructed as per the following table: * * DISTINCT SORTED ORDERED SIZED SHORT_CIRCUIT * SPLITERATOR 01 01 01 01 00 * STREAM 01 01 01 01 00 * OP 11 11 11 10 01 * TERMINAL_OP 00 00 10 00 01 * UPSTREAM_TERMINAL_OP 00 00 10 00 00 * * 01 = set/inject * 10 = clear * 11 = preserve * * Construction of the columns is performed using a simple builder for * non-zero values. */ }
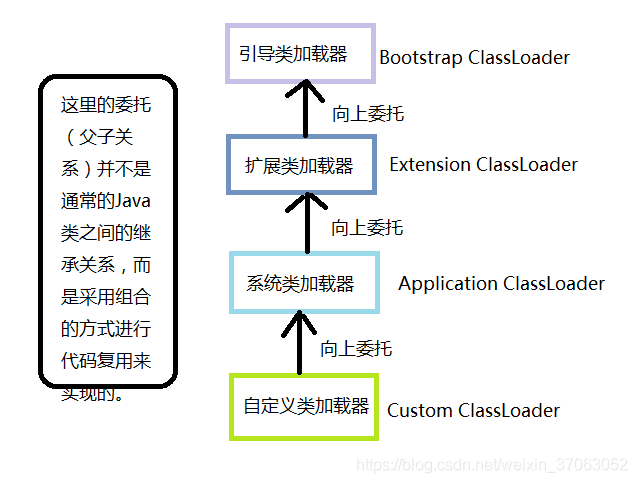
protected final Class<?>defineClass(String name,byte[] b, int off, int len)根据给定的字节数组b转换为Class的实例,off和1en参数表示实际Class信息在byte数组中的位置和长度,其中byte数组b是ClassLoader从外部获取的。这是受保护的方法,只有在自定义ClassLoader子类中可以使用。
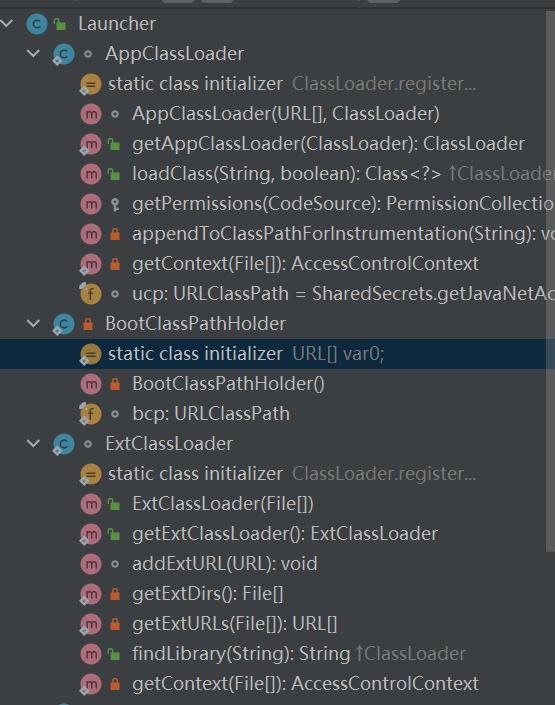
// The parent class loader for delegation // Note: VM hardcoded the offset of this field, thus all new fields // must be added *after* it. privatefinal ClassLoader parent; // 用于类加载 ---双亲委派机制,不建议重写 public Class<?> loadClass(String name) throws ClassNotFoundException { return loadClass(name, false); }
protected Class<?> loadClass(String name, boolean resolve) throws ClassNotFoundException { synchronized (getClassLoadingLock(name)) { // First, check if the class has already been loaded Class<?> c = findLoadedClass(name); if (c == null) { longt0= System.nanoTime(); try { if (parent != null) { // 委派父加载器 parent加载 c = parent.loadClass(name, false); } else { c = findBootstrapClassOrNull(name); } } catch (ClassNotFoundException e) { // ClassNotFoundException thrown if class not found // from the non-null parent class loader } // 如果 父加载器不能加载,则交给当前加载器加载(用于重写加载器) if (c == null) { // If still not found, then invoke findClass in order // to find the class. longt1= System.nanoTime();
// 调用子类的自定义的类加载器方法 c = findClass(name);
// this is the defining class loader; record the stats sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); sun.misc.PerfCounter.getFindClasses().increment(); } } if (resolve) { resolveClass(c); } return c; } } // 建议子类重写 实现自定义类加载器机制 protected Class<?> findClass(String name) throws ClassNotFoundException { thrownewClassNotFoundException(name); }
// the set of parallel capable loader types privatestaticfinal Set<Class<? extendsClassLoader>> loaderTypes = Collections.newSetFromMap( newWeakHashMap<Class<? extendsClassLoader>, Boolean>()); static { // 静态代码块,用于添加类加载器类型 synchronized (loaderTypes) { loaderTypes.add(ClassLoader.class); } }
/** * Registers the given class loader type as parallel capabale. 将给定的 类加载器(AppClassLoader,ExtClassLoader) 注册为可并行 * Returns {@code true} is successfully registered; 如果父类加载器为注册,返回false {@code false} if loader's super class is not registered. */ staticbooleanregister(Class<? extends ClassLoader> c) { synchronized (loaderTypes) { if (loaderTypes.contains(c.getSuperclass())) { // register the class loader as parallel capable // if and only if all of its super classes are. // Note: given current classloading sequence, if // the immediate super class is parallel capable, // all the super classes higher up must be too. loaderTypes.add(c); returntrue; } else { returnfalse; } } } }
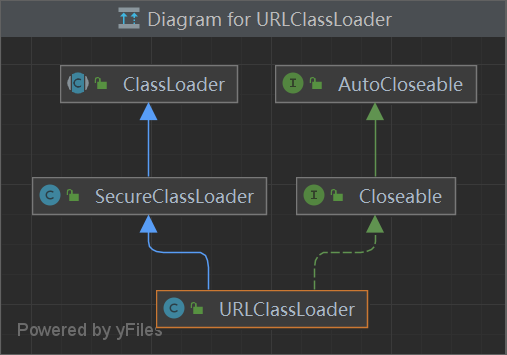
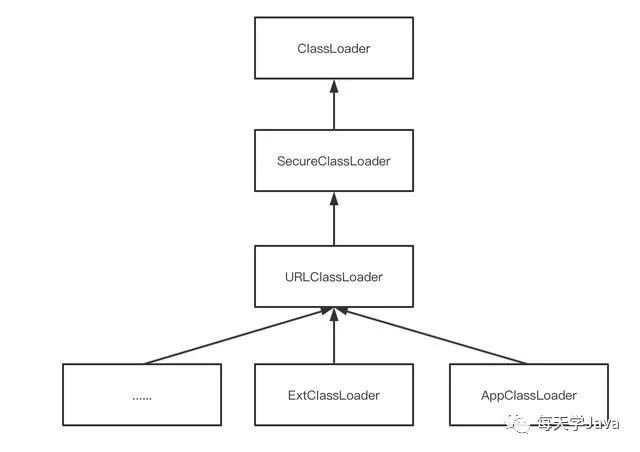
/*这个类扩展了ClassLoader,为定义具有关联代码源和默认情况下由系统策略检索的权限的类提供了额外的支持。*/ publicclassSecureClassLoaderextendsClassLoader { /* * If initialization succeed this is set to true and security checks will * succeed. Otherwise the object is not initialized and the object is * useless. */ privatefinalboolean initialized;
// HashMap that maps CodeSource to ProtectionDomain // @GuardedBy("pdcache") privatefinal HashMap<CodeSource, ProtectionDomain> pdcache = newHashMap<>(11);
publicclassURLClassLoaderextendsSecureClassLoaderimplementsCloseable { /* The search path for classes and resources -- 类和资源 搜索路径*/ privatefinal URLClassPath ucp; /* The context to be used when loading classes and resources 加载类和资源时使用的上下文 */ privatefinal AccessControlContext acc; static { sun.misc.SharedSecrets.setJavaNetAccess ( newsun.misc.JavaNetAccess() { public URLClassPath getURLClassPath(URLClassLoader u) { return u.ucp; }