JVM业务
JVM业务
JDK命令
jvm调优监控工具jps、jstack、jmap、jhat、jstat使用详解 - 好奇成传奇 - 博客园 (cnblogs.com)
| 名称 | 主要功能 |
|---|---|
| jps | JVM Process Status Tool,显示指定系统内所有HotSpot虚拟机进程 |
| jstat | JVM Statistics Minitoring Tool,用于收集HotSpot虚拟机各方面的运行数据 |
| jinfo | Configuration Info for Java,显示虚拟机配置信息 |
| jmap | Memory Map for Java,生成虚拟机的内存转储快照(heapdump)文件 |
| jhat | (Java Heap Analysis Tool) / JVM Heap Dump Browser,用于分析heapdump文件,它会建立一个HTTP/HTML服务器,让用户可以在浏览器上查看分析结果 |
| jstack | Stack Trace for Java,显示虚拟机的线程快照 |
| jcmd |
jstack, jstat, jps, jinfo, jmap jhat
JVM内存模型(JMM)
工作内存(高速缓存,寄存器)和主内存
工作内存(虚拟机栈,本地方法栈)和主内存(堆和方法区)
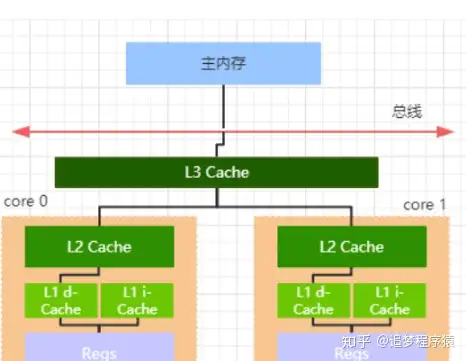
MESI协议
MESI是一种比较常用的缓存一致性协议,MESI表示缓存行的四种状态,分别是:
1、M(Modify) 表示共享数据只缓存在当前 CPU 缓存中,并且是被修改状态,也就是缓存的数据和主内存中的数据不一致
2、E(Exclusive) 表示缓存的独占状态,数据只缓存在当前CPU缓存中,并且没有被修改
3、S(Shared) 表示数据可能被多个 CPU 缓存,并且各个缓存中的数据和主内存数据一致
4、I(Invalid) 表示缓存已经失效
在 MESI 协议中,每个缓存的缓存控制器不仅知道自己的读写操作,而且也监听(snoop)其它CPU的读写操作。
对于 MESI 协议,从 CPU 读写角度来说会遵循以下原则:
CPU读请求:缓存处于 M、E、S 状态都可以被读取,I 状态CPU 只能从主存中读取数据
CPU写请求:缓存处于 M、E 状态才可以被写。对于S状态的写,需要将其他CPU中缓存行置为无效才行。
JVM – 专栏
(13条消息) JVM从入门到精通_VectorUx的博客-CSDN博客
垃圾回收器
CMS
终于把CMS垃圾收集器搞懂了~ - 掘金 (juejin.cn)
G1
看完这篇G1垃圾收集器的总结就足以吊打面试官了~ - 掘金 (juejin.cn)
日志分析
https://juejin.cn/post/7029130033268555807
Serial GC
1 | |
GC-回收类型、GC出发原名、收集器名称、(回收区域)回收前后内存变化,堆内存变化、回收耗时:
- 2021-09-09T14:44:04.813-GC事件开始的时间点。+0800表示当前时区为东八区,这只是一个标识。0.163是GC事件相对于JVM启动时间的间隔,单位是秒
- GC - 用来区分Minor GC还是Full GC的标志。GC表明这是一次小型GC(Minor GC),即年轻代GC。Allocation Failure 表示触发GC的原因。本次GC事件是由于对象分配失败,即年轻代中没有空间来存放新生成的对象引起的。
- DefNew表示垃圾收集器的名称。这个名称表示:年轻到使用的单线程、标记-复制、STW的垃圾收集器。139776K->17472K 表示在垃圾收集之前和之后的年轻代使用量。(157248K) 表示年轻代的总空间大小。分析可得,GC之后年轻代使用率为11%。
- 139776K->45787K 表示在垃圾收集前后整个堆内存的使用情况,(506816K)表示整个堆的大小
- 0.0165501 secs - GC事件的持续时间,单位:秒
- [Times: user=0.00 sys=0.02, real=0.02 secs] 表示此次GC事件的持续时间,通过三个部分来衡量:user 表示所有GC线程消耗的CPU时间;sys 表示系统调用和系统等待事件消耗的时间;real表示应用程序暂停的时间
Parallel GC
1 | |
内容:Minor GC + Full GC + Heap内存情况
第四部分:堆内存分布
- PSYoungGen total 75776K, used 63884K:年轻代占用75776K,,使用了63884K
- eden space 65024K, 98% used,伊甸区占用了新生代65024K,其中98%被使用
- from space 10752K, 0% used
- to space 10752K, 0% used
- ParOldGen total 180736K, used 180448K,老年代总共180736K,使用了180448K
- Metaspace used 2766K, capacity 4486K, committed 4864K, reserved 1056768K:元数据区总计使用了2766K,容量是4486K,JVM保证可用的大小是4864K,保留空间1GB左右
- class space used 307K, capacity 386K, committed 512K, reserved 1048576K,class space使用了307K,容量是386K
CMS GC
1 | |
相较于上面的集中GC日志:
回收过程
这里多了一点 CMS 的Major GC的回收过程分析:(这里体现了更多回收细节)
- 初始化标记
- 并发标记
- 重新标记
- 并发清除
阶段1:初始标记
该阶段是STW的阶段,目的是标记所有的根对象包括根对象直接引用的对象,以及被年轻代中所有存活对象引用对象速度很快
1 | |
GC (CMS Initial Mark)—这个阶段的名称为“ Initial Mark”[1 CMS-initial-mark: 205370K(349568K)]表示老年代的使用量以及老年代的大小223428K(506816K), 0.0001030 secs–当前堆内存的使用量,以及可用的堆内存大小、GC消耗的时间,时间0.1毫秒,非常短,因为要标记的对象很少[Times: user=0.00 sys=0.00, real=0.00 secs]–初始标记暂停的时间,可以看到被忽略不计了
阶段2:并发标记
并发标记是从“初始标记”阶段编辑的根元素开始,标记所有存活的对象,GC线程与用户线程同时运行。
1 | |
CMS-concurrent-mark-start表明当前为CMS的并发标记阶段0.003/0.003 secs-此阶段的持续时间,分别是GC线程消耗的时间和实际消耗的时间[Times: user=0.00 sys=0.00, real=0.00 secs]-对于并发阶段来说这些时间并没有多少意义,因为啥从并发标记时刻计算的,而这段时间应用程序也在执行,所以这个时间至少一个大概的值
阶段3:并发预清理
此阶段也是与用户线程同时运行的,主要是来出来“并发标记”阶段“脏卡”的老年代对象,为了减少Final Remark阶段STW的时间,可通过-XX:-CMSPrecleaningEnabled关闭,默认开启。
1 | |
与“并发标记”阶段相同
阶段4:可取消的并发预清理
具体此阶段的流程这里就不细讲了,目的与“并发预清理”一样,也是为了减少Final Remark阶段STW的时间,在进入Final Remark阶段前尽量等到一个Minor GC。具体的可以看我这篇CMS垃圾收集器。
1 | |
可以看到预清理过程中,发生了三次Minor GC。
阶段5:最终标记
最终标记是CMS GC中的第二次STW,也是最后一次,该阶段重新扫描堆中的对象,因为之前的预清理阶段是并发执行的,有可能GC线程跟不上应用线程的修改速度,该阶段需要扫描新生代+GC Roots + 被标记为“脏区”的对象,如果预清理阶段没有做好,这一步扫描新生代会非常耗时
1 | |
CMS Final Remark-阶段名称,最终标记阶段YG occupancy: 20972 K (157248 K)- 当前年轻代的使用量和总容量Rescan (parallel) , 0.0002117 secs- 在程序暂停后进行重新扫描,已完成存活对象的标记。并行执行,耗时0.0002117 secsweak refs processing, 0.0000083 secs- 第一个子阶段,处理弱引用,耗时0.0002117 secsclass unloading, 0.0002509 secs- 第二个子阶段,卸载不使用的类,耗时0.0002509 secsscrub symbol table, 0.0003192 secs- 第三个子阶段,清理符号表,即持有class级别的metadata的符号表(symbol table)1 CMS-remark: 335528K(349568K)- 此阶段完成后老年代的使用量和总容量356500K(506816K), 0.0009630 secs- 此阶段完成整个堆内存的使用量和总容量,耗时
阶段6:并发清除
此阶段也是与用户线程同时运行的,删除不再使用的对象,并回收他们占用的内存空间,由于是与用户线程并发执行,因此可能会产生“浮动垃圾”
1 | |
与前边的阶段类似,不再讲解
阶段7:并发重置
此阶段也是与用户线程同时运行的,重置CMS算法相关的内部结构,下次触发GC时就可以直接使用
1 | |
具体CMS GC后老年代内存使用量是多少这里并不能分析出来,只能通过后边的Minor GC日志分析,例如本次CMS GC后的Minor GC日志如下
1 | |
计算出来老年代的使用率大约为83%,这个使用率并不度,说明了什么问题呢,一般就是分配的内存小了,毕竟我们才指定了512M最大堆内存
Full GC
当并发模式失败(Concurrent mod failure)会触发Full GC。
- 并发模式失败:CMS大部分阶段是与用户线程并发执行的,如果在执行垃圾收集时用户线程创建的对象直接往老年代分配,但是没有足够的内存,就会报Concurrent mode failure
- 晋升失败:新生代做Minor GC的时候,老年代没有足够的空间用来存放晋升的对象,则会报Concurrent mode failure;如果由于内存碎片问题导致无法分配,就会报晋升失败
可以看到下边的日志,先发生了一次concurrent mode failure,后边紧接着发生了一次Full GC
1 | |
G1 GC
1 | |
JVM 调优
性能指标
-★ 响应时间(Response Time: RT)
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回的响
应结束,整个过程所耗费的时间。
HPS(Hits Per Second) :每秒点击次数,单位是次/秒。
★TPS(Transaction per Second):系统每秒处理交易数,单位是笔/秒。
★QPS(Query per Second):系统每秒处理查询次数,单位是次/秒。
对于互联网业务中,如果某些业务有且仅有一个请求连接,那么 TPS=QPS=HPS,一
般情况下用 TPS 来衡量整个业务流程,用 QPS 来衡量接口查询次数,用 HPS 来表
示对服务器单击请求。
无论 TPS、QPS、HPS,此指标是衡量系统处理能力非常重要的指标,越大越好,根据经
验,一般情况下:
金融行业:1000TPS50000TPS,不包括互联网化的活动(秒杀等)100000TPS,不包括互联网化的活动
保险行业:100TPS
制造行业:10TPS5000TPS1000000TPS
互联网电子商务:10000TPS
互联网中型网站:1000TPS50000TPS10000TPS
互联网小型网站:500TPS
最大响应时间(Max Response Time) 指用户发出请求或者指令到系统做出反应(响应)
的最大时间。
最少响应时间(Mininum ResponseTime) 指用户发出请求或者指令到系统做出反应(响
应)的最少时间。
90%响应时间(90% Response Time) 是指所有用户的响应时间进行排序,第 90%的响应时间。
从外部看,性能测试主要关注如下三个指标
吞吐量可以理解为TPS或QPS:每秒钟系统能够处理的请求数、任务数。
响应时间:服务处理一个请求或一个任务的耗时。
错误率:一批请求中结果出错的请求所占比例。
(13条消息) <JVM下篇:性能监控与调优篇>03-JVM监控及诊断工具-GUI篇_VectorUx的博客-CSDN博客
压力测试
谷粒商城分布式高级(五)—— 性能压测(压力测试 & 性能监控 & nginx动静分离 ) - 沧海一粟hr - 博客园 (cnblogs.com)
火焰图
1. 场景描述:
因为生产环境组件服务进程执行缓慢导致部分资源无法释放,进而引起了各种任务超时。研究源码发现,部分执行过长的是操作都是在单线程中串行 。这就意味着,单个过程的执行效率会影响到整个流程的调度周期。为此,我们需要对部分组件源码进行改造,串行改并行。
串行改并行,我们要小心流程执行顺序之间的依赖关系和各个线程对共享变量的读写。这里的前提是我们得知道改哪里。其实我们的需求很明确,执行过程耗时长的我们优先改造,也就是我们需要找到组件的性能瓶颈。但是如何确认呢?最终,我是通过火焰图观察,找出了耗时比较长的过程。下面记录一下这个过程,以便日后需要的时候可以有所帮助。
2. 火焰图
火焰图是通过可交互的图片反映出程序执行过程中的调用栈和大致的CPU占用百分比。在火焰图中,顺着Y轴从下往上看表示的是调用顺序,高度表示的就是调用栈的深度。顺着X轴看,一个方法的长度表示的就是这个方法的被抽到的样本数,被抽到的次数越多,占用的CPU时间就越长。当把鼠标放在一个方法上时,会显示一段说明,例如
(5222 samples, 7.6%),这个表示的就是,这个方法在采样期间被采样了5222次,占用总样本的7.6%。注意X轴不表示时间,不是说左边的方法一定在右边之前执行。火焰图应该是高低起伏的,如果都是很宽的平顶,那程序性能就需要重新评测了。另外,火焰图的颜色没有任何含义。
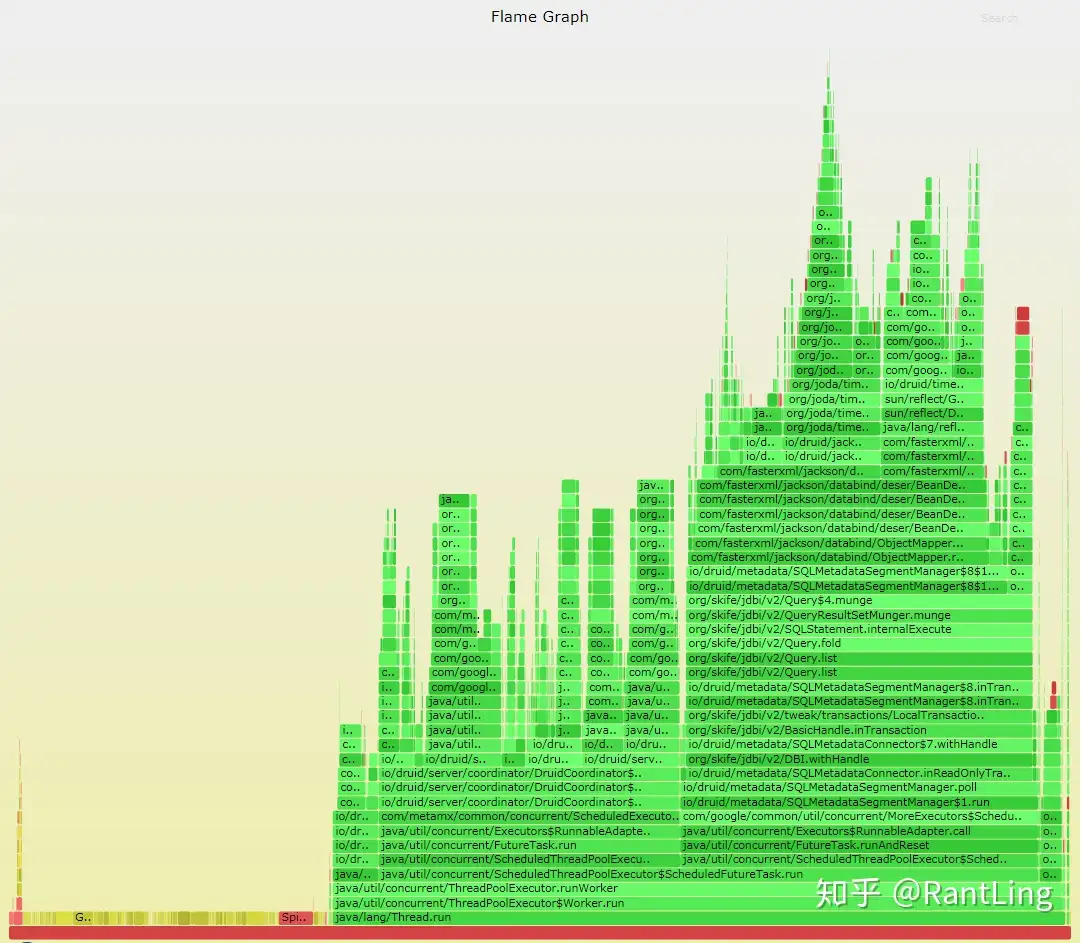
火焰图是可交互的,在浏览器中我们打开火焰图之后可以直接CTRL+F进行搜索。输入完整的方法名或者正则表达式之后,所有匹配到的方法都是高亮显示出来。
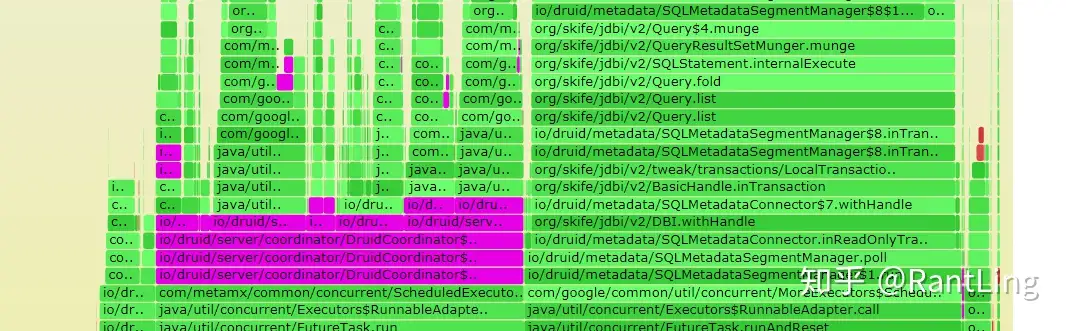
单击这些高亮部分就会放大这一部分,显示选中方法的子方法(被调用的方法)。这样就可以在这张图中搜索自己想要确认的模块,然后找到比较宽的部分,定位到代码,确定是否可以修改。
3. 生成火焰图
3.1 工具
火焰图生成工具:javaPfro.zip 提取码:76o9
这个工具包解压之后会用两个文件夹:async-profiler-master FlameGraph-master
文件夹下部分可执行文件,可能需要755权限。这里不做一一声明,直接更改文件夹下所有文件的权限。chmod -R 755 async-profiler-master/*chmod -R 755 FlameGraph-master/*
3.2 操作步骤
火焰图只是以图片形式展示出了CPU中的调用栈,实际的数据还是需要从CPU中采集。所以生成火焰图共分为两步:采样和生成svg图。
3.2.1 采样
采样使用async-profiler-master工具,具体命令如下:./async-profiler-master/profiler.sh -d 10 -o collapsed -f /tmp/collapsed.txt 1234
以上命令表示的意思是,采样时间为10秒,采样得到的数据重定向到/tmp/collapsed.txt,被采样进程id为1234。
3.2.2 生成svg图
根据采样数据生成svg图,使用的是FlameGraph-master,具体命令如下:./FlameGraph-master/flamegraph.pl --colors=java /tmp/collapsed.txt > flamegraph.svg
命令表示的意思是把/tmp/collapsed.txt这个文件转换svg火焰图,文件名为flamegraph.svg。
然后,把这个文件拉到window环境下,用浏览器就可以打开了。这里我用的是chrome浏览器。
4. 分析火焰图
分析火焰图一般需要先确定需要分析的类或方法名,或者代码入口方法,或者入口类。这样我们可以先定位到一个方法调用,再分析其调用栈。
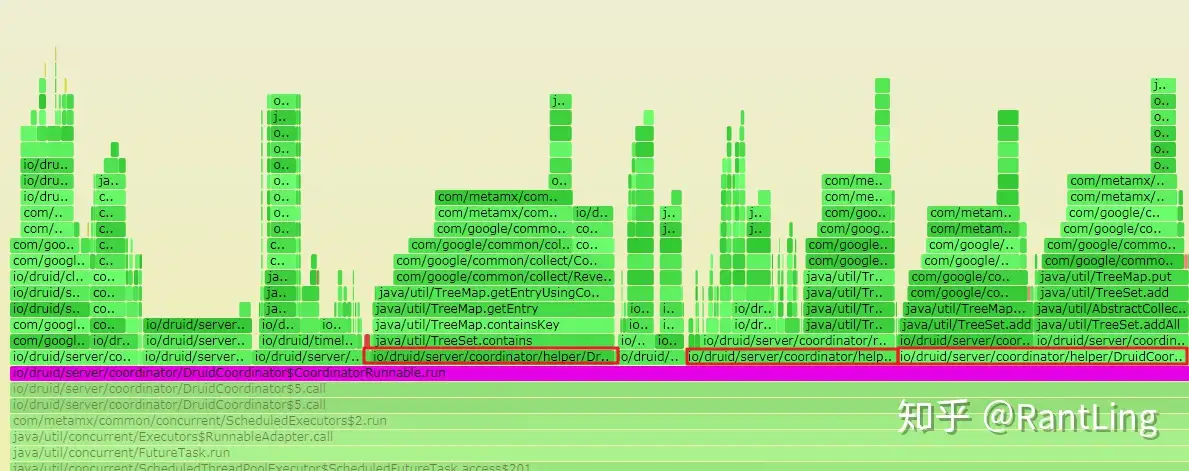
例如,在这张图片中,我确定的方法是定义在CoordinatorRunnable类中的,就可以直接搜索这个类。定位到这个类我们可以明显地看到有三个方法占用了大部分的时间。再继续追踪调用栈。

可以看出,耗时大部分都花费在集合元素的比较上。这里我们如果需要优化的话,可以考虑一下比较器的逻辑或者可以根据场景判断一下是否可以选择其他的集合等等。火焰图实践
