从Paxos到Zookeeper 分布式一致性原理与实践
MySQL技术内幕 InnoDB存储引擎 第2版
第一章 MySOL体系结构和存储引擎
定义数据库和实例
在数据库领域中有两个词很容易混淆,这就是“数据库” (database)和“实例” ( i n s t a n c e )。 作 为 常 见 的 数 据 库 术 语 , 这 两 个 词 的 定 义 如 下 。
- 数据库:物理操作系统 文件或其他形式文件类型的集合。在MysQL 数据库中,数据 库文件可以是frn 、MYD、MYI、ibd 结尾的文件。当使用NDB引擎时,数据库的 文 件 可 能 不 是 操 作 系 统 上的 文 件 , 而 是 存 放 于 内 存 之 中 的 文件 , 但 是 定 义 仍 然 不 变 。
- 实例:MySQL 数据库由后台线程以及一个共享内存区组成。共享内存可以被运行 的后合线程所共享。需要牢记的是,数据库实例才是真正用于操作数据库文件的。
MySQL体系結枸
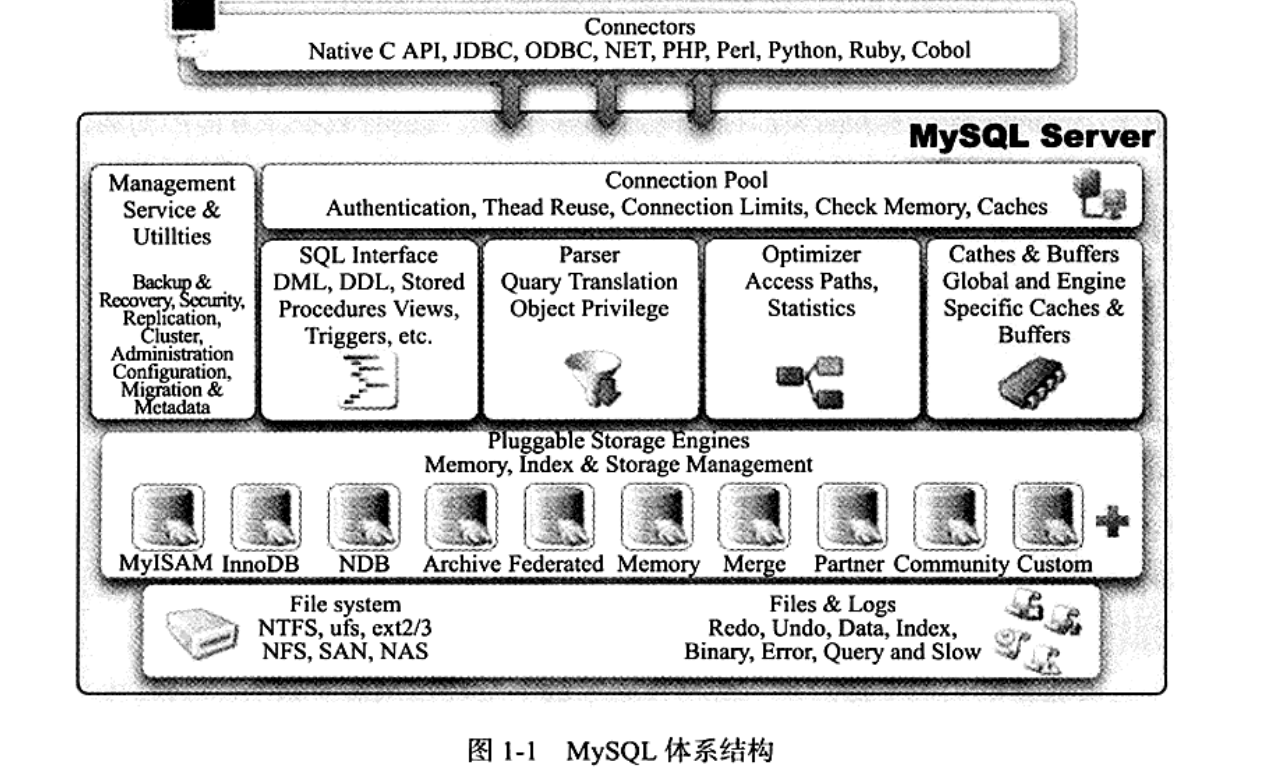
从图1-1可以发现,MysQL 由以下几部分组成: 连 接池组件
- 管理服务和工具组件
- SQL 接口组件
- 查询分析器组件
- 优化器组件
- 缓冲 (Cache)组件
- 插 件式存储 引擎
- 物理文件
MySQL存储引擎
—InnoDB 存储引擎
InoDB存储引擎支持事务,其设计目标主要面向在线事务处理 (OLTP)的应用。 其 特 点 是 行 锁 设 计 、 支 持 外 键 , 并 支 持 类 似 于 O r a c l e 的 非 锁 定 读, 即 默 认 读 取 操 作 不 会 产生锁。从MySQL 数据库5. 5. 8 版本开始,InnoDB 存储引擎是默认的存储引擎。
- Inn oDB 存储引擎将 数据放在一 个逻辑的 表空间中,这个表空间就像黑盒一样由I n n o D B 存 储 引 擎 自 身 进 行 管 理 。 丛 M y s Q L 4 . 1 (包 括 4 . 1 ) 版 本 开 始 , 它 可 以 将 每 个 InnoDB 存储引擎的表单独存放到 一个独立的ibd 文件中。此外,InnoDB 存储引擎支持 用裸设备 (rowdisk )用来建立其表空间。
- InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了sQL 标准的4种隔离级别,默认为REPEATABLE 级别。
- 同时,使用一种被称为next key l o c k i n g 的 策 略 来 避 免 幻 读 (p h a n t o m ) 现 象 的 产 生 。
- 除 此 之 外 , I n n o D B 储 存 引 擎 还 提 供了插人缓冲(insert buffer)、 二次写(double write)、自适应哈希索引(adaptivehash in dex ) 、 预 读 (read ahead ) 等 高 性 能 和 高 可 用 的 功 能 。
- 对 于 表 中 数 据 的 存 储 , I n n o D B 存 储 引 擎 采 用 了 聚 集 (c l u s t e r e d ) 的 方 式 , 因 此 每 张 表的存储都是按主键的顺序进行存放。如果没有显式地在表定义时指定主键,IonoDB存 储 引 擎 会 为 每 一 行 生 成 一 个 6 字 节 的 R O W I D , 并 以 此 作 为 主键 。
—MyISAM 存储引擎
- MyISAM 存储引警不支持事务、表锁设计,支持全文索引,主要面向 一些OLAP数 据 库 应 用 。
- MyISAM存储引擎的另 一个与众不同的地方是它 的 缓 冲 池 只 缓 存 (c a c h e ) 素 引 文 件 , 而 不 绥 冲 数 据 文 件 , 这 点 和 大 多 数 的 数 据 库 都 非 常 不同。
- MyISAM 存储引擎表由MYD 和MYI 组成,MYD 用来存放数据文件,MYI 用来存 放索引文件。
可以通过使用myisampac k 工具来进一步压缩数据文件,因为myisampack 工具使用赫夫曼 (Huffman )编码静态算法来压缩数据,因此使用myisampack 工具压缩 后的表是只读的,当然用户也可以通过myisar pack 来解压数据文件
—NDB 存储引擎
- NDB存修到救是一个然群存储引戰,災似于Orael e 的RAC集群,不过号orgel e f A shareeverything架构不同的是,其结构是share nothing的集群架构,因此能提供更高 的 可 用 性 。
- N D B 的 特 点 是 数 据 全 部 放 在 内 存 中 (从 M y s Q L 5 . 1 版 本 开 妢 , 可 以 将 非 索 引数据放在磁盘上),因此主键查找 (primary key 1ookups)的速度极快,并且通过添加 NDB数据存储节点(Data Node)可以线性地提高数据库性能,是高可用、高性能的集群系统。
- NDB存储引擎的连接操作 (JOIN)是在MySQL 数据库层完成的,而不是在存储引擎层完成的。这意味着,复杂的 连按操作需要巨大的网络开销,因此查询速度很慢。如果解决 了这个问题,NDB 存储 警的市场应该是非常巨大的。
—Memory 存储引擎
- Me mor y 存储引警 (之前称 HEA P 存储引擎)将表中的数据存放在内存中, 如果数 据库重启或发生崩溃,表中的数据都将消失。它非常适合用于存储临时数据的临时表, 以及数据仓库中的纬度表。Memor y 存储引擎默认使用哈希索引,而不是我们熟悉的Bt 树素引。
—- Archive 存储引擎
- Ar c h i v e 存 储 引 擎 只 支 持 I N S E R T 和 S EL E C T 操 作 , 从 M y s Q L 5 . 1 开 始 支 持 素引。
- Archive 存储引擎非常适合存储归档数据,如日志信息。 Archive 存储引擎使用行锁来实现高并发的插人操作,但是其本身并不是事务安全的存 储引擎, 其设计 目标 主要是提供高速的插人和压缩 功能。
—Federated 存储引擎
- Federat ed 存储引擎表并不存放数据,它只是指向一台远程MysQL数据库服务器上 的表。这非常类似于SQLServer 的链接服务器和Oracle 的透明网关,不同的是,当前 Feder at ed 存储引擎只支持 MySQL 数据库表,不支持异构数据库表。
—Maria 存储引擎
- Maria 存储引擎是新开发的引擎,设计目标主要是用来取代原有的MyISAM存储引 擎,从而成为MysQL 的默认存储引擎。Maria存储引擎的开发者是MysQL的创始人之一的 M i c h a e l W i d e n i u s 。 因 此 , 它 可 以 看 做 是 M y I S A M 的 后 续 版 本 。
- M a r i a 存 储 引 擎 的 特点是**:支持缓存数据和素引文件,应用了行锁设计,提供了MVCC 功能,支持事务和 非事务安全的选项,以及更好的BLOB 宇符类型的处理性能。**
连接MySQL
本节将介绍连接MySQL 数据库的常用方式。需要理解的是,连接Mys QL 操作是 一个连接进程和MysQL 数据库实例进行通信。从程序设计的角度来说,本质上是进程 通信。如果对进程通信比较 了解,可以知道常用的进程通信方式有管道、命名管道、命名字、TCP/I P 套接字、UNIX 域套接字。Mys QL 数据库提供的连接方式从本质上看都 是上述提及的进程通信方式
第二章 InnoDB存储引擎
版本

2.3 InnoDB体系架构
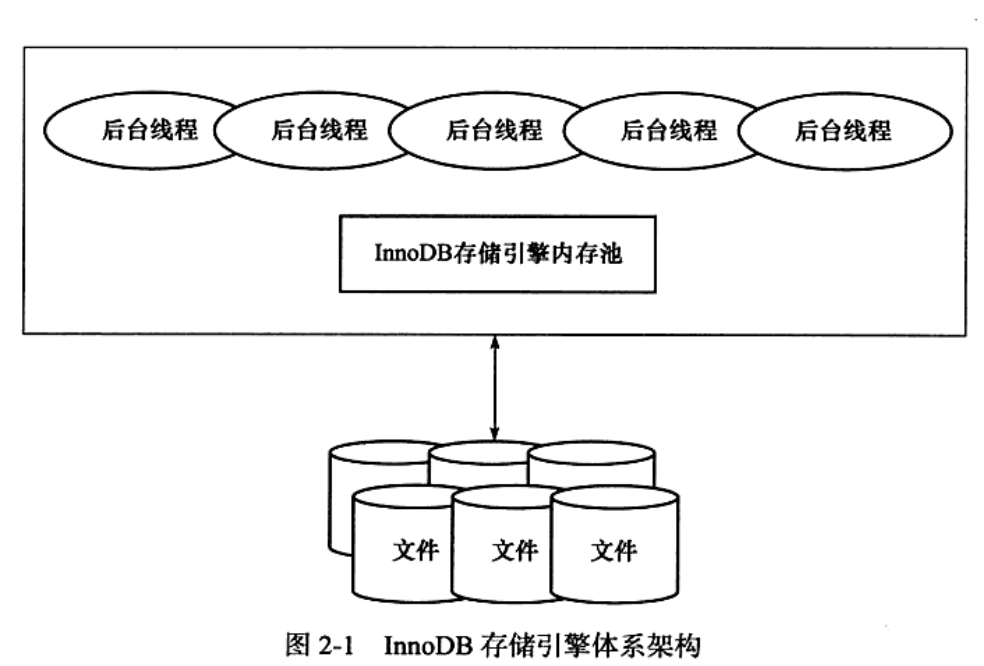
后台线程的主要作用是负责刷新内存池中的数据,保证缓冲池中的内存缓存的是最 近的数据。此外将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生异常的情 况 下In noDB 能恢复到正常运行状态
—后台线程
InnoDB存储引擎是多线程的模型,因此其后台有多个不同的后合线程,负责处理不同的任务
- Master Thread
Master Thread 是 一个非常核心的后台线程, 主要负责将缓冲池中的数据异步刷新 到磁盘,保证数据的一致性,包括脏页的刷新、合并插人缓冲 ( INSERT BUFFER) 、 UNDO页的回收等。 - IO Thread
在InnoDB存储引擎中大量使用了AIO (Async IO)来处理写IO 请求,这样可以极 大提高数据库的性能。而10 Thread 的工作主要是负责这些I0 请求的回调 (call back
处 理 。 InnoD B 1 . 0 版 本 之 前 共 有 4 个 IO Thread , 分 别 是 w r i t e 、 r e a d 、 i n s e r t b u f f e r 和 lo g
10 tbread。 - Purge Thread
事务被提交后,其所使用的undolog 可能不再需要,因此需要PurgeThread 来回收 已经使用并分配的undo页。在InnoDB 1.1版本之前,purge操作仅在InnoDB存储引擎 的Master Thread中完成。而从InnoDB1.1版本开始,purge操作可以独立到单独的线
程中进行,以此来减轻Master Thread的工作,从而提高CPU的使用率以及提升存储引 擎的性能。 - Page Cleaner Thread
PageCleaner Thread 是在InnoDB1.2.x版本中引人的。其作用是将之前版本中脏页 的刷新操作都放人到单独的线程中来完成。而其日的是为了減轻原Master Thread的工作 及对于用户查询线程的阻塞,进 一步提高InnoDB存储引擎的性能。
—内存
缓冲池
Inno DB 存储引擎是基 于磁盘存储的,并将 其中的记录按照页的方式进行管理。因此 可将其视为基于磁盘的数据库系统(Disk-base Database)。在数据库系统中,由于CPU 速度与磁 盘速度之间的鸿沟,基于磁盘的数据库系统通常使用缓冲池技术来提高数据库 的整体性能。- 在数据库中进行读取页的操作,首先將从磁盘读到的页存放在缓冲池中, 这个过程称为将页“FIX〞在绥冲池中。下一次再读相同的页时,首先判断该页是否在 缓冲池中。若在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘 上的 页 。
- 对于数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷 新到磁盘上
缓冲池中缓存的数据页类型有:素引页、数据页、undo 页、插人缓冲 ( i n s e r t b u f f e r )、 自 适 应 哈 希 素 引 ( a d a p t i v e h a s h i n d e x ) 、 I n n o D B 存 储 的 锁 信 息 ( l o c k i i n f o )、 数 据 字 典 信 息 ( d a t a d i c t i o n a r y ) 等 。
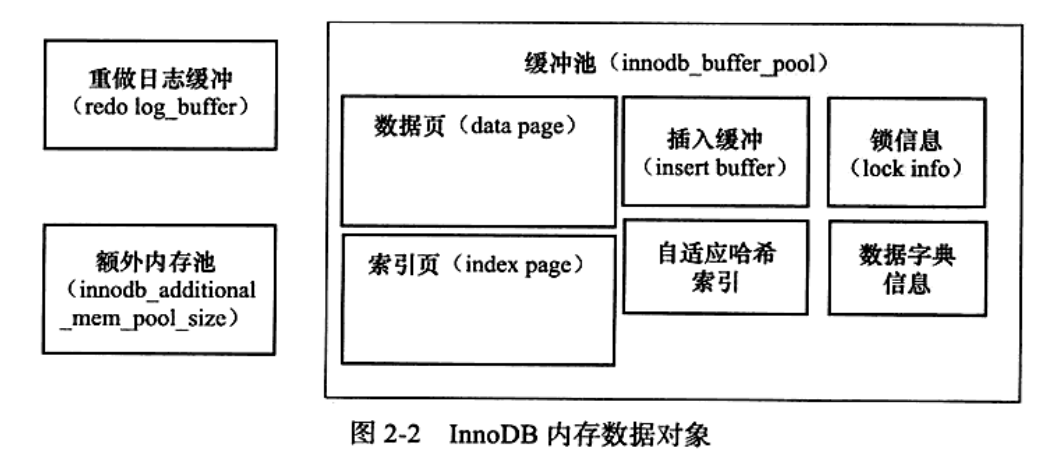
LRUList、Free List 和Flush List
重做日志缓冲
三种情况下会将重做日志缓冲中的内容刷新到外部磁盘的重做日志文件中。 又Master Thread 每一秒将重做日志缓冲刷新到重做日志文件;
又每个事务提交时会将重做日志缓冲刷新到重做日志文件;
又 当重做 日志缓冲池剩余空间小于 1/2 时,重做日志缓冲刷新到重做 日志文件。额外的内存池
在IDnoDB存储引擎中,对内存的管理是通过 一种称为内存堆(heap) 的方式进行的。在对 一些数据结构本身的内存进行分配时,需要从额外的内存池中进行 申请,当该区域的内存不够时,会以缓冲池中进行申谱。
例如,分配了缓冲池(ipmodb buffer_pool ),但是每个缓冲池中的帧缓冲 (frame buffer )还有对应的缓冲控制对象
(buffercontrol block),这些对象记录了一些诸奶LRU、锁、等待等信息,而这个对象的 内存需要从额外内存池中申请。
2.4 Checkpoint 技术
因此Checkpoint (检查点)技术的目的是解决以下几个问题: 又缩短数据库的恢复时间;
又 缓冲池不够用时,将脏页刷新到磁盘: 又重做日志不可用时,刷新胜页。
当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint 之前的页都 己经刷新回磁盘。故数据库只需对Checkpoint 后的重做日志进行恢复。这样就大大缩短
了恢 复 的 时 间 。
此外,当缓冲池不够用时,根据LRU 算法会滥出最近最少使用的页,若此页为脏 页,那么需要强制执行Checkpoint ,将脏页也就是页的新版本刷回磁盘。
因此Checkpoint (检查点)技术的目的是解决以下几个问题:
- 缩短数据库的恢复时间;
- 缓冲池不够用时,将脏页刷新到磁盘:
- 重做日志不可用时,刷新胜页
有 两 种 C h e c k p o i n t , 分 别 为:
- Sharp Checkpoint
- Fuzzy Checkpoint
SharpCheckpoint 发生在数据库关闭时将所有的脏页都刷新回 磁盘,这是默认的工作 方式,即参数innodb fast shutdown=1。
2.5 Master Thread 工作方式
2.6 InnoDB关键特性
2.6.1 插入缓冲
1、Insert Buffer
insertBuffer可能是InnoDB存储引擎关键特性中最令人激动与兴奋的 一个功能。不
过这个名字可能会让人认为插人缓冲是缓冲池中的一个组成部分。其实不然,IonoDB 缓 冲池中有Insert Bufter 信息固然不错,但是Insert Buffer 和数据页一样,也是物理页的一个组成部分。
I n s e r t B u f f e r 的 使 用 需 要 同 时 满 足 以 下两 个 条 件:
索引是辅助素引 (secondaryindex);
索引不是唯一 (unique)的
InnoDB从1.0.x版本开始引人了Change Buffer,可将其视为Insert Buffer的升级。 从这个版本开始,InnoDB存储引擎可以对DML操作— —-INSERT、DELETE、UPDATE
都进行缓冲,他们分别是:Insert Buffer、Delete Buffer、Purge buffer。
当然和之前Insert Buffer一样,Change Buffer 适用的对象依然是非唯一的辅助素引。
对一条记录进行UPDATE 操作可能分为两个过程: 又将记录标记为已删除;
又 真正将记录删除。
2.6.2 两次写
如果说InsertBuffer带给IanoDB存储引擎的是性能上的提升,那么doublewrite (两 次写)带给InnoDB 存储引擎的是数据页的可靠性。
当发生数据库宕机时,可能IanoDB 存储引擎正在写人某个页到表中,而这个页只 写了一部分,比如16KB的页,只写了前4KB,之后就发生了宕机,这种情况被称为部 分 写 失 效 ( p a r t i a l p a g e w r i t e )。 在 I n n o D B 存 储 引 擎 末 使 用 d o u b l e w r i t e 技 术 前 , 曾 经 出现过因为部分写失效而导致数据丟失的情况。
有经验的DBA 也许会想,如果发生写失效,可以通过重做日志进行恢复。这是一个办法。但是必须清楚地认识到,重做日志中记录的是对页的物理操作,如偏移量800 , 写 aaaa ,记录。如果这个页本身已经发生了损坏,再对其进行重做是没有意义的。这 就是说,在应用(apply)重做日志前,用户需要 一个页的副本,当写人失效发生时,先 通过页的副本来还原该页,再进行重做,这就是doublewrite。
doublewrite 由两部分组成,一部分是内存中的doublewrite buffer,大小为2MB,另 一部分是物理磁盘上共享表空间中连续的128 个页,即2个区(extent),大小同样为 2MB。在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memopy函数将 脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer 再分两次,每次
IMB顺序地写人共享表空间的物理磁盘上,然后马上调用fsync 两数,同步磁盘,避免 缓冲写带来的问题。在这个过程中,因为doublewrite 页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite 页的写人后,再将doublewrite buffer 中的页 写 人 各 个 表 空 间 文 件 中 , 此 时 的 写 人 则 是 离 散 的 。

2.6.3 自适应哈希索引
哈 希 (h a s h ) 是 一 种 非 常 快 的 查 找 方 法 , 在 一 般 情 况 下 这 种 查 找 的 时 间 复 杂 度 为0(1),即一般仅需要一次查找就能定位数据。而B+树的查找次数,取决于B+ 树的高度,在生产环境中,B+ 树的高度一般为了4 层,故需要了4 次的查询。 IanoDB存储引擎会监控对表上各素引页的查询。如果观察到建立哈希索引可以带来速度提升,則建立哈希索引,称之方自适 哈希索引(Adaptive Hash Index, AHI). AHI 是通过缓冲池的Bt 树页构造而来,因此建立的速度很快,而且不需要对整张表构 建哈希索引。InnoDB存储引擎会自动根据访问的频率和模式来自动地为某些热点页建立 哈希索引。
2.6.4 异 步 10
用户可以通过开启和关闭Native AIO功能来比较InnoDB性能的提升。官方的测试 显示,启用Native AI0,恢复速度可以提高75%。
在 nnoDB 存储引擎中,read ahead 方式的读取都是通过 A1O 完成,脏页的刷新, 即磁盘的写人操作则全部由AIO 完成。
2.6.5 刷新邻接页(脏页)
InnD B 存 储 引 l 擎 还 提 供 了 F l u s h N e i g h b o r P a g e ( 刷 新 邻 接 页 ) 的 特 性 。其 工 作 原 理 为:当刷新一个脏页时,InnoDB存储引擎会检测该页所在区 (extent )的所有页,如果 是脏页,那么一起进行刷新。这样做的好处显而易见,通过AIO可以将多个10 写人操 作合并为 一个10 操作,故该工作机制在传统机械磁盘下有着显著的优势。但是需要考 虑到 下面两个问题:
又是不是可能将不怎么脏的页进行了写人,而该页之后又会很快变成脏页? 又 固态硬盘有着较高的 IOPS ,是否还需要这个特性?
为此,InnoDB存储引擎从1.2.x版本开始提供了参数innodb_flush neighbors,用 来控制是否启用该特性。对于传统机械硬盘建议启用该特性,而对于固态硬盘有着超高 IOPs 性能的磁盘,则建议將该参数设置为0,即关闭此特性。
第三章 文件
本章將分析构成MySQL 数据库和IanoDB 存储引警表的各种类型文件。这些文件 有以下这些。
- 参数文件:告诉MysQL 实例启动时在哪里可以找到数据库文件,并且指定某些 初始化参数,这些参数定义了某种内存结构的大小等设置,还会介绍各种参数的 类型。
- 日志文件:用来记录MysQL 实例对某种条件做出;响应时写入的文件,如错误日 志文件、 二进制日志文件、慢查询日志文件、查询日志文件等。
- socket 文件:当用UNIX域套接字方式进行连接时需要的文件。
- pid 文件:MysQL 实例的进程D 文件。
- MysQL 表结构文件:用来存放MysQL 表结构定义文件。 又存储引擎文件:因为MysQL 表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据。这些存储引擎真正存储了记录和素引等数据。本章主要介绍 与InnoDB有关的存储引擎文件。
参数文件
可以把数据库参数看成一个键/ 值 (key/value)对。
Mys QL 数据库中的参数可以分为两类:
- 动 态 (d y n a m i c ) 参 数
- 静态 ( st ati c )参数
动态参数意味着可以在Mys QL 实例运行中进行更改,静态参数说明在整个实例生 命周期内都不得进行更改,就好像是只读(read only)的。可以通过SET命令对动态的 参数值进行修改,SET 的语法如 下:
1 | |
日志文件
- 错误日志 (error log)
- ニ 迸 制 日 志 (bin l o g )
- 慢 査 洵 日 志 (slow query l o g )
- 查询日志 ( log )
—错误日志 (数据库优化)
错误日志文件对MysQL 的启动、运行、关闭过程进行了记录。MySQL DBA 在遇到问题时应该首先查看该文件以便定位问题。该文件不仅记录了所有的错误信息,也记 录一些警告信息或正确的信息。用户可以通过命令SHOWVARIABLES LIKE”10g-error 来定位该文件,
SHON VARIABLES LIKE ‘10g_error’ 1G;
—慢查询日志 (SQL优化)
通过错误日志得到一些关于数据库优化的信息,而慢查询日志 ( sl ow 1og )可帮助 DBA 定位可能存在问题的 SQL 语句,从而进行 SQL 语句层面的优 化
使用:
在默认情况下,MysQL 数据库并不启动慢查询日志,用户需要 手工将这个参数设 ‡ ON:
mysq1> SHOW VARIABLES LIKE ‘long_query_time’\G;
mysql> SHOW VARIABLES LIKE ‘log_slow_queries’\G;
1、定义时间(开启slow log)long_query_time
2、查询日志。log_slow_queries
3、查询未使用索引的sql日志 1og_queries_not_using_indexes
- 首先,设置long_guery time 这个网值后,MysQL数据库会 记录运行时间超过该值的所有SQL语向,但运行时间正好等于long guery_time 的情况并不会被记录下。也就是说,在源代码中判断的是大于long_quer y_time,而非大于等 于。其次,从MysQL5. 1开始,long_guery_time 开始以微秒记录SQL语句运行的时间,之前仅用秒为单位记录。而这样可以更精确地记录$QL的运行时间,供DBA 分析。对 DBA来说,一条SQL 语句运行0.5秒和0.05 秒是非常不同的,前者可能己经进行了表 扫,后面可能是进行 了索引。
- 另一 个和 慢 查询 日志 有 关的 参 数 是 1og_queries_not_using_indexes , 如 果运 行 的 S QL 语句没有使用索引,则MySQL 数据库同样会将这条SQL 语句记录到慢查询日志文件。
首先确认打开了1og_queries_not using_indexes:
mysg1> SHOWVARIABLES LIKE “1og_gueries_not_using_indexes’1G;
—查询日志
查询日志记录了所有对MysQL 数据库请求的信息,无论这些请求是否得到了正雄 的执行。默认文件名为: 主机名. 1og。
[root@nineyou0-43 datal# tail nineyou0-43.1og
—二进制日志
二 进 制 日 志 (b i n a r y l o g ) 记 录 了 对 M y s Q L 数 据 库 执 行 更 改 的 所 有 操 作 , 但 是 不 包 括SELECT 和SHOW这类操作,因为这类操作对数据本身并没有修改。
二进制日志主要有以 下几种作用。
- 恢 复 ( r e c o v e r y ) :
某 些 数 据 的 恢 复 需 要 二进 制 日 志 , 例 如 , 在 一 个 数 据 库 全 备 文 件恢复后,用户可以通过二进制日志进行point-in-time 的恢复。 - 复制 (replication ):
其原理与恢复类似,通过复制和执行二进制日志使一台远程 的 M y s Q L 数 据 库 (一 般 称 为 s l a v e 或 s t a n d b y ) 与 一 台 M y s Q L 数 据 库 (一 般 称 为master 或primary)进行实时同步。 - 审计(audit) :
用户可以通过二进制日志中的信息来进行审计,判断是否有对数 据库进行注入的攻击。
开启:通过配置参数1og-bin [-name了可以启动一进制日志。如果不指定narmd. 则黩认豆 进制日志文件名为主机名,后级名为二进制日志的序列号,所在路径为数据库所在目录
( d a t a d i r ), 如 :
当使用事务的表存储引擎 (如InnoDB存储引擎)时,所有未提交 (uncommitted)
的二进制日志会被记录到一个缓存中去,等该事务提交 (committed)时直按将缓冲中 的 二进制日志写人 二进制日志文件,而该缓冲的大小由binlog_cache_size 决定,默认大 小为32K。
- binlog_cache size 是基于会话(session)的,当一个线程 开始一个事务时,MysQL 会自动分配一个大小为binlog_cache_size 的缓存,因此该值 的设置需要相当小心,不能设置过大。
- 当一个事务的记录大于设定的binl og_cache_size 时,Mys QL 会把缓冲中的日志写人 一个临时文件中,因此该值又不能设得太小。
binlog_format 参数十分重要,它影响了记录二进制日志的格式。
- 在MysQL 5. 1版本 之 前 , 没 有 这 个 参 数 。 所 有 二 进 制 文 件 的 格 式 都 是 基 于 S Q L 语 句 (s t a t e m e n t ) 级 别 的 ,
因此基 于这个格式的二进制日志文件的复制 (Replication)和Oracle 的逻辑Standby 有点 相 似 。 同 时 , 对 于 复 制 是 有 一定 要 求 的 。 如 在 主 服 务 器 运 行 r a n d 、 u u i d 等 两 数 , 又 或 者使用触发器等操作,这些都可能会导致主从服务器上表中数据的不一致 (not sync)。 - 另一个影响是,会发现InnoDB 存储引擎的默认事务隔离级别是REPEATABLE READ。这 其 实 也 是 因 为 二 进 制 日 志 文件 格 式 的 关 系 , 如 果 使 用 R E A D C O M M I T T E D 的 事 务 隔 离 级 别 (大 多 数 数 据 库 , 如 O r a c l e , M i c r o s o f t S Q L. S e r v e r 数 据 库 的 默 认 隔 离 级 别 ) , 会 出现类似丟失更新的现象,从而出现主从数据库上的数据不一致。
MysQL 5. 1开始引人了binlog_tormat 参数,该参数可设的值有STATEMENT、ROW 和MIXED。
- ( 1)STATEMENT 格式和之前的MySQL 版本一样, 二进制日志文件记录的是日志的逻辑SQL 语句。
- (2)在ROW格式下,二进制日志记录的不再是简单的SQL语向了,而是记录表的行更改情况。 基于ROW格式的复制类似于Oracle 的物理Standby (当然,还是有些区 别)。同时,对上述提及的Statement 格式下复制的问题子以解决。从MysQL 5. 1版本 开始,如果设置了binlog_format 为ROW,可以将InnoDB 的事务隔离基本设为READ COMMI TTED, 以获得更好的 并发性。
- (3 ) 在 M I X E D 格 式 下 , M y S Q L 默 认 采 用 S T A T E M E N T 格 式 进 行 二 进 制 日 志 文 件 的记录,但是在一些情况下会使用ROW格式,可能的情况有:
- 1 表的存储引擎为NDB,这时对表的DML 操作都会以ROW格式记录。
- 2)使用了UUITDO、USERO、CURRENT_USERO、FOUND ROWSO、ROW_COUNTO 等不确定函数。
- 3)使用 了INSERT DEL AY 语句。
- 4)使用了用户定义两数 (UDF )。
- 5)使用了临时表 (temporary table)。
套接字(socket)文件
前面提到过,在UNIx 系统下本地连接MysQL可以采用UN区域套接字方式,这 种方式需要一个套接宇 (socket )文件。套接字文件可由参数socket 控制。一般在/tmp 目录 下,名为mysql.sock:
mysq1>SHOW VARIABLES LIKE ‘ s o c k e t ‘\G;
PID文件
当MysQL 实例启动时,会將自己的进程1D写人一个文件中一—该文件即为pid 文 件。该文件可由参数pid fil e 控制,默认位于数据库目录下,文件名为主机名pid:
mysql> show variables like ‘ pid_file’\G;
表结构定义文件
因为MySQL 插件式存储引擎的体 系结构的关系,MySQL 数据的存储是根据表进行 的,每个表都会有与之对应的文件。但不论表采用何种存储引擎,MysQL 都有一个以 frm 为后缀名的文件,这个文件记录了该表的表结构定义。
frm还用来存放视图的定义,如用户创建了一个v a视图,那么对应地会产生一
个v a.frm 文件,用来记录视图的定义,该文件是文本文件,可以直接使用cat 命令进行 查看:
InnoDB 存储引擎文件
MySQL 数据库本身的文件,和存储引擎无关。除 了这些文件 外,每个表存储引擎还有其自己独有的文件。
本节将具体介绍与IonoDB存储引擎密切 相关的文件,这些文件包括重做日志文件(redo log)、表空间文件。
—表空间文件
IanoDB采用将存储的数据按表空间 (tablespace )进行存放的设计。在默认配置 下会有一个初始大小为10MB,名为ibdatal 的文件。该文件就是默认的表空间文件 ( tablespac efile),用戸可以通 参数i nnodb_data_f ile_pat he対其迷行没置,格式如下:
innodb_data_file_path=datafile_spec1] ; datafile_spec2] . . . 用户可以通过多个文件组成一 个表空间,同时制定文件的属性, 如:
[mysqld]
innodb _data_file_path = /db/ibdatal :2000M;/ dr2/cb/ibdat.a2:2000M:autoextend
—重做日志文件
当实例或介质失败 mediafailure)时,重做日志文件就能派上用场。例如,数据库 由于所在主机掉电导致实例失败,Inn oDB 存储引擎会使用重做日志恢复到掉电前的时 刻,以此来保证数据的完整性。
在InnoDB存储引禁的数据目录下会有两个名为ib_logfile0 和 ib_logfle1 的文件。在MysQL 官方手册中将其称为InnoDB存储引擎的日志文件,不过更淮确的定义应该是**重做日志文件 (redo log file )**。
参数innodb_1og_file_size 指定每个重做日志文件的大小。在InnoDB1.2.x版本之前, 重 做 日 志 文 件 总 的 大 小 不 得 大 于等 于 4 G B , 而 1. 2 . x 版 本 将 该 限 制 扩 大 为 了 5 1 2 G B 。
参数innodb_1og_fil es_in_group 指定 了日志文件组中重做日志文件的数量,默认为2。
参数innodb_mirrored 1og_eroups 指定了日志镜像文件组的数量,默认为1,表示只 有 一个日志文件组,没有镜像。若磁盘本身已经做了高可用的方案,如磁盘阵列,那么 可以不开启重做日志镜像的功能。
最后,参数innodb1oggtouphome dir指定了日志文 件 组 所 在 路 径 , 默 认 为 !, 表 示 在 M y S Q L 数 据 库 的 数 据 目 录 下 。 以 下 显 示 了 一 个 关 于
bin log 和 redo log的区别:
既然同样是记录事务日志,和之前介绍的二进制日志有什么区别?
- 首先,二进制日志会记录所有与MysQL 数据库有关的日志记录,包括InoDB、 MyISAM 、Heap 等其他存储引擎的日志。而InnoDB 存储引攀的重做日志只记录有关该 存储引擎本身的事务日志。
- 其次,记录的内容不同,无论用户将 二进制日志文件记录的格式设为STATEMENT 还是ROW,又或者是MI XED,其记录的都是关于一个事务的具体操作内容,即该日志 是逻辑日志。而InnoDB 存储引擎的重做日志文件记录的是关于每个页(Page)的更改 的物理情况。
- 此外,写人的时问也不同,二进制日志文件仅在事务提交前进行提交,即只写磁盘一次,不论这时该事务多大。而在事务进行的过程中,却不断有重做日志条目(redo entry)被写人到重做日志文件中
重做日志组的配置:
mysq1>SHOW VARIABLES LIKE innodblog§’\G;

写入重做日志流程:
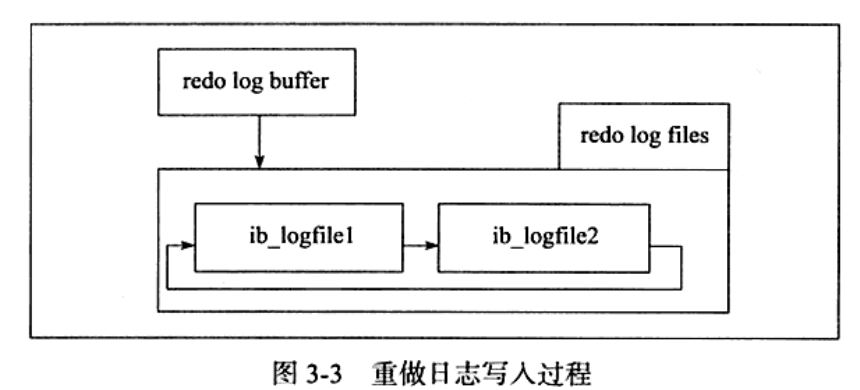
- 主 线 程 (m a s t e r t h r e a d ), 知 道 在 主 线 程 中 每 秒 会 将 重 做 日 志缓冲写人磁盘的重做日志文件中,不论事务是否已经提交。
- 另 一个触发写磁盘的过程是 由参数inodbfush1og_at trx_comr it 控制,表示在提交(commit)操作时,处理重做 • 日志的方式。
小结
- 本 章 介 绍 了与 M y S Q L 数 据 库 相 关 的 一 些 文 件 , 并 了 解 了 文 件 可 以 分 为 M y s Q L 数 据库文件以及与各存储引擎相关的文件。与MysQL 数据库有关的文件中,错误文件和 二进制日志文件非常重要。当MysQL 数据库发生任何错误时,DBA 首先就应该去查看错 误文件,从文件提示的内容中找出问题的所在。当然,错误文件不仅记录了错误的内容, 也 记 录 了 警 告 的 信 息 , 通 过 一些 警 告 也 有 助 于 D B A 对 于 数 据 库 和 存 储 号l 擎 进 行 优 化 。
- 二进制 日志的作用 非常 关键,可以用来进行point in time 的恢复以及复制
(replication)环境的搭建。因此,建议在任何时候时都启用 二进制日志的记录。从 MysQL 5.1开始,二进制日志支特STATEMENT、ROW、MIX 三种格式,这样可以更 好地保证从数据库与主数据库之问数据的 一致性。当然DBA应该十分清楚这三种不同 格式之间的差异。 - 本章的最后介绍了和InnoDB 存储引擎相关的文件,包括表空间文件和重做日志文 件。
- 表空间文件是用来管理IanoDB存储引擎的存储,分为共享表空间和独立表空间。
- 重做日志非常的重要,用来记录InnoDB 存储引攀的事务日志,也因为重做日志的存在, 才使得InnoDB 存储引擎可以提供可靠的事务。
第四章 表
4.1 索引组织表
在 I n n o D B 存 储 引 擎 表 中 , 每 张 表 都 有 个 主 键 ( P r i m a r y K e y ) , 如 果 在 创 建 表 时 没 有 显 式 地 定 义 主键 , 则 I a n o D B 存 储 引 擎 会 按 如 下 方式选择或创建 主键:
- 首先判断表中是否有非空的唯一索引(Unique NOTNULL),如果有,则该列即 为主键。
- 如果不符合上述条件,InnoDB存储引擎自动创建 一个6字节大小的指针。
选择建表时第 一个定义的非空唯一索引为主键
1 | |
4.2 InnoDB逻辑存储结构
从InoDB存储引警的逻辑存储结构看,所有数据都被逻辑地存放在 一个空问中,称 之 为 表 空 间 (t a b l e s p a c e )。 表 空 间 又 由 段 ( s e g m e n t ) 、 区 (e x t e n t )、 页 (p a g e ) 组 成 。 页 在 一些此 文 档 中 有 时 也 称 为 块 ( b l o c k )
(数据段:叶子结点、非叶子结点、回滚。段)
4.2.1 表空间
在 默 认 情 识 下 I n n o D B 存 储 引 擎 有 一 个 共 享 表 空 间 i b d a t a l , 即所有数据都存放在这个表空间内。如果用户启用了参数inodbfile per table,则每张 表 内 的 数 据 可 以 单 独 放 到 一 个 表空 间 内 。
如果启用了innodbfile per table 的参数,需要注意的是每张表的表空间内存放的只 是数据、索引和插人绥冲Bitmap 页,其他类的数据,如**回滚(undo)信息,插人缓冲 索引页、系统事务信息,二次写缓冲(Double write bufrer)**等还是存放在原来的共享表 空间内。这同时也说明了另一个问题:即使在启用了参数inodb_file_per_table 之后,共 享表空问还是会不断地增加其大小。
4.2.2 段
表空间是由各个段组成的,常见的段有数据段、素引段、回滚段等。 因为前面已经介绍过 了In no DB 存储引擎表是索引组织的 ( index or gani zed ) ,因此数据 即素引,索引即数据。
那么数据段即为Bt 树的叶子书点(图4-1的Leaf nodesegment),
素引段即为B+树的非索引节点(图4-1的Non-leaf node segment)。回滚段较为特殊, 将会在后面的章节进行单独的介绍。
4.2.3 区
区是由连续页组成的空间,在任何情况下每个区的大小都为IMB。为了保证区中页 的连续性,IonoDB存储引禁一次从磁盘申请4~5个区。在默认情况下,InnoDB存储 引擎页的大小为16KB,即一个区中 一共有64 个连续的页。
I mODB1.0x阪本始引人第以、即録代的大小町以通さ参数KEX.PyOCKS SIZE 设置为2K、4K 、8K,因此每个区对应页的数量就应该为 512、256、128
4.2.4 页
IDnoDB有页(Page)的概念(也可以称为块),页是InnoDB 磁 盘管理 的最小单位。在 InnoDB 存储引擎中,默认每 个页的大小为 16KB。而从 IanoDB 1.2.x版本开始,可以通过参数innodb_page_size 将页的大小设置为4K、8K、
16K。若设置完成,则所有表中页的大小都为inmodb_page_sizc,不可以对其再次进行修 改。除非通过mysqldump 导人和导出操作来产生新的库。
在I noDB存储引擎中,常见的页类型有:
- 数据页 (B-tree Node)。 ***
- undo 页 (undo Log Page) ***
- 系统 页 ( S y s t e m P a g e )
- 事务数据页 ( Transac tion sy stem Page )
- 插人缓冲位图页 (InsertBufferBitmap)
- 插人缓冲空闲列表页(InsertBuffer FreeList)
- 未 压 缩 的 二进 制 大 对 象 页 ( U n c o m p r e s s e d B L O B P a g e )
- 压缩的二进制大对象页(compressed BLOBPage)
4.2.5 行
I n n o D B 存 储 引 擎 是 面 向 列 的 ( r o w - o r i e n t e d ), 也 就 说 数 据 是 按 行 进 行 存 放 的 。 每 个
页存放的行记录也是有硬性定义的,最多允许存放16KB/ 2- 200 行的记录,即7992行 记录。
InnoDB行记录格式
—Compact 行记录格式
Compact 行记录是在MysQL 5.0中引人的,其设计目标是高效地存储数据。

- 非NULL 变长字段长度列 表,并且其是按照列的顺序逆序放置的,其长度为:
- 又 若列的长度小于 255 字节,用 1 字节表示;
- 又若大于255 个字节,用2 字节表示。
(变长字段的长度最大不可以超过2 字节,这是因在Mys QL 数据库中VARCHAR类 型的最大长度限制为65535。)
- 变长字段之后的第 二个部分是NULL 标志位,该位指示了 该行数据中是否有NULL 值,有则用1表示。该部分所占的宇节应该为1字节。
- 是 记 录 头 信 息 (r e c o r d h e a d e r ) , 固 定 占 用 5 字 节 (4 0 位 ), 每 位 的 含 义 见 表 4 - 1 。
—Redundant 行记录格式
Redundant是MysQL5.0版本之前InoDB的行记录存储方式
—行溢出数据
从错误消息可以看到InnoDB 存储引擎并不支持65535 长度的VARCHAR。这是因 为还有别的开销,通过实际测试发现能存放VARCHIAR类型的最大长度为65532。
—Compressed 和 Dynamic 行记录格式
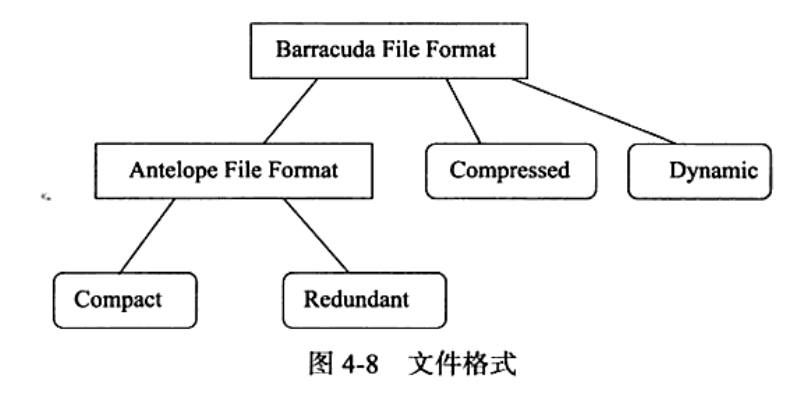
InnoDB 1.0.x 版本开始引人了新的文件格式 (fle format,用户可以理解为新的页格式),
- 以前支持的Compact 和Redundant 格式称为Antelope 文件格式,
- 新的文件格式称为Barracuda 文件格式。Barracuda 文件格式下拥有两种新的行记录格式:Compressed 和Dynamic
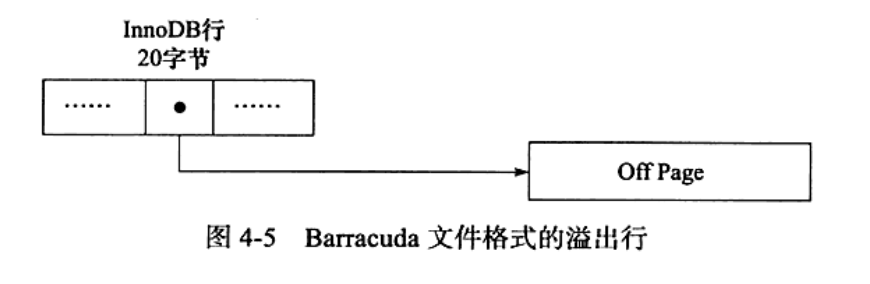
存放行溢出数据 off page
- 对于存放在BLOB 中的数据采用 了完全的行溢出的方式, 如 图4-5所示,在数据页中只存放20个字节的指针,实际的数据都存放在Off Page 中,
- 而之前的Compact 和Redundant 两种格式会存放768 个前缀字节。
Compressed 行记录格式的另一个功能就是,存储在其中的行数据会以zli b 的算法进 行 压 缩, 因 此 对 于B L O B 、T E X T 、 V A R C H A R 这 类 大长 度 类 型 的数 据 能 够 进 行 非常 有 效 的存储
NamedFileFormats机制
InnoDB存储引擎将1.0.x版本之前的文件格式(file format)定义为Antelope,将这 个版本支持的 文件格式定义为Barracuda 。新的文件格式总是包含 于之前的版本的页格 式。
InnoDB存储引通过Named File Formats 机制来解决 不 同 版 本 下页 结 构 兼 容 性 的 问 题 。
—CHAR的行结构存储
Inno DB 数据页结构
InnoDB数据页由以下了个部分组成,如图4-6 所示。
FileHeader (文件头)
Page Header (页头)
• Infimun #ll Supremum Records
User Records (用户记录,即行记录)
FreeSpace (空闲空间)
PageDirectory (页目录)
FileTrailer (文件结尾信息)
其中File Header 、Page Header 、File Trailer 的大小是固定的,分别为38、56、8 字 节,这些空间用来标记该页的一些信息,如Checksum,数据页所在B+树索引的层数 等。UserRecords、FreeSpace、Page Directory这些部分为实际的行记录存储空间,因此 大小是动态的
约束
视图
视图在数据库中发挥着重要的作用。视图的主要用途之一是被用做 一个抽象装置, 特 别 是 对 于 一些 应 用 程 序 , 程 序 本 身 不 需 要 关 心 基 表 (b a s e t a b l e ) 的 结 构 , 只 需 要 按 照 祝阁定义来取数据或更新数据,因此,视因同时在 一定程度上起到 一个安全层的作用
—物化视图
概念
Oracle 数据库支特物化视图——该视图不是基于基表的虚表,而是根据基表实际存 在的实表,即物化视图的数据存储在非易失的存储设备上。
- 物化视因可以用于预先计算 并保存多表的链接(JOIN)或聚集(GROUP BY)符耗时较多的SQL操作结果。这样, 在执行复杂有询时,就可以避免进行这些耗时的操作,从而快速得到结果。
- 物化视图的好处是对于一些复杂的统计类查询能直接查出结果。
在Microsoft SQL Server 数据库中,称这种视图为索引视图。
MySQL不支持物化视图,但是可以通过触发器等机制自己实现
创建
物化视图的创建方式包括以下两种:
BUILD IMMEDIATE (立即)
BUILD DEFERRED(referred - 使用时)
BUILDI MEDIATE是默认的创建方式,在创建物化视图的时候就生成数据,而 BUILDDEFERED 则在创建物化视图时不生成数据,以后根据需要再生成数据。
模式
物化视图的刷新是指当基表发生了DML 操作后,物化视图何时采用哪种方式和基 表进行同步。刷新的模式有两种:
- ON DEMAND
- ON COMMIT
ON DEMAND 意味着物化视图在用户需要的时候进行刷新,ON COMMIT 意味着物 化视图在对基表的DML 操作提交的同时进行刷新。
刷新
刷 新 的 方法 有 四 种 :
- FAST
- COMPLETE
- FORCE
- NEVER
- F A S T 刷 新 采 用 增 量 刷 新 , 只 刷 新 自 上次 刷 新 以 后 进 行 的 修 改 。
- C O M P L E T E 刷 新 是 对整个物化视图进行完全的刷新。
- 如果选择FORCE方式,则数据库在刷新时会去判断是否可以进行快速刷新,如果可以,则采用FAST 方式,否则采用COMPLETE的方式。
- NEVER 是指物化视因不进行任何刷新。
分区表
—分区概述
分区的过程是将一个表或素引分 解为多个更小、更可管理的部分。
就访问数据库的应用而言,从逻辑 上讲,只有一个表 或 一个素引,但是在物理上这个表或素引可能由数十个物理分区组成。每个分区都是独 立的对象,可以独自处理,地可以作为一个更大对象的一部分进行处理。
Mys QL 数据库支持的分区类型为水平分区,并不支持垂直分区
MysQL 数 据 库 的 分 区 是 局 部 分 区 索 引 , 一个 分 区 中 既 存 放 了 数 据 又 存 放 了 素 引 。
而 全 局 分 区 是 指,数据存放在各个分区中,但是所有数据的素引放在一个对象中。
◎ 水平分区,指将同一表中不同行的记录分配到不同的物理文件中。 -
垂直分区,指将同一表中不同列的记录分配到不同的物理 文体中。
—分区类型
当前MysQL 数据库支持以下几种类型的分区。
- R A N G E 分 区 : 行 数 据 基 于 屈 于 一个 给 定 连 续 区 间 的 列 值 被 放 人 分 区 。 M y S Q L 5 . 5 开始支持 RANGE COLUMNS 的分区。
- LIST 分区:和RANGE分区类型,只是LIST 分区面向的是离散的值。MysQL 5. 5 开 始 支持 L I S T C O L U M N S 的 分 区 。
- HASH分区:根据用户自定义的表达式的返回值来进行分区,返回值不能为负数。
- KEY 分区:根据MySQL 数据库提供的哈希两数来进行分区
—子分区(复合)
子分区 (subpartitioning)是在分区的基础上再进行分区,有时也称这种分区为复合 分区(composite partitioning)。MySQL数据库允许在RANGE和LIST的分区上再进行 H A S H 或 K E Y 的 子分 区
数据库的应用分为两类:
- 一类是OLTP (在线事务处理),如Blog、电子商务、网络 游戏等;
- 另 一类是OLAP (在线分析处理),如数据仓库、数据集市
对 于OLAP 的应用,分区的确 是可以很好地提高查询的性能,因为OL AP 应用大多 数查询需要频繁地扫描 一张很大的表。
对于OLTP 的应用,分区应该非常小心。在这种应用下,通常不可能会获取一 张大表中10%的数据,大部分都是通过素引返回几条记录即可。而根据B+树索引的原
理可知,对于一张大表,一般的B+树需要2 ~3次的磁密10。因此B+树可以很好地 完成操作,不需要分区的帮助,并且设计不好的分区会带来严重的性能问题。
第五章 索引与算法
5.3 B+树
5.4 B+ 树索引
但是B+ 素引在数据库中有 一个特点是高扇出性(当前),因此在数据库中,B树的两度一般都在2一4层,这也號选说在找花一健催的行记录时最生只瑞要子到台女 10,这倒不错。因为当前一般的机械磁盘每秒至少可以做100次10,2~ 4次的10 意 昧着査吋 同只需0.02~0.04秒
数据库中的B+树索引可以分为聚集索引 (clustered inex)和辅助索引 (secondary inde x )e ,但是 不管是聚 集还是辅 助的素引,其内部都是B + 树的,即高度 平衡的,叶子 节点存放着所有的数据。聚集素引与辅助素引不同的是,叶子节点存放的是否是一整行
的信息
5.4.1 聚 集 索引
之前已经介绍过了,InnoDB 存储引擎表是索引组织表,即表中数据按照主键顺序存 放。而聚集素引 (clust ered index )就是按照每张表的主键构造一棵B+树,同时叶子节点中存放的即为整张表的行记录数据,也将聚集索引的叶子节点称为数据页。聚集索引 的 这 个 特 性 决 定 了素 引 组 织 表 中 数 据 也 是 索 引 的 一 部 分 。 同 B + 树 数 据 结构 一 样 , 每 个 数据页都通过一个双向链表来进行链接。 由于实际的数据页只能按照一棵B+树进行排序,因此每张表只能拥有一个聚集索 引。
5.4.2 辅助索引
对 于 辅 助 素 引 (S e c o n d a r y I n d e x , 也 称 非 聚 集 索 引 ), 叶 子 节 点 并 不 包 含 行 记 录 的
全部数据。叶子节点除了包含键值以外,每个叶子节点中的索引行中还包含了一个书签 b ookmark )。该书签用来告诉InnoDB存储引擎哪里可以找到与索引相对应的行数据。由 于InnoDB 存储引擎表是索引组织表,因此 Inno DB 存储引擎的辅助索引的 书签就是相应
行数据的聚集素引键。
5. 6 B + 树索引的使用
5.6.2 联合索引
联合素引是指对表上的多个列进行索引。前面讨论的情况都是只对表上的一个列进行 泰引。联合素引的创建方法与单个索引创建的方法一样,不同之处仅在于有多个索引列。
5.6.3 覆盖素引
InnoDB 存储引擎 支持覆盖索引 (covering index,或称索引覆盖),即从辅助索引中就可以得到查询的记录,而不需要查询聚集素引中的记录。使用覆盖素引的 一个好处是 辅助索引不包含整行记录的所有信息,故其大小要远小于聚集索引,因此可以减少大量 的10 操作。
5.6.6 Multi-Range Read 优化
MySQL5.6版本开始支持Multi-RangeRead (MRR)优化。Multi-RangeRead优化的
目的就是为了滅少磁盘的随机访问,并且将随机访问转化为较为顺序的数据访问,这对 于10-bound类型的SQL查询语句可带来性能极大的提升。Multi-Range Read优化可适 用于range, ref,cqref类型的查询。
M R R 优 化 有 以 下几 个 好 处 :
- MRR 使数据访问变得较为顺序。在查询辅助素引时,首先根据得到的查询结果, 按照主键进行排序,并按照主键排序的顺序进行 书签查找。
- 減少缓冲池中页被替换的次数。
- 批量处理对键值的查询操作。
对 于Inn oDB 和MyI SAM 存储引擎的范围查询和 JOIN 查询操作,MRR 的工作方式 如 下:
- 将查询得到的辅助素引键值存放于一个缓存中,这时缓存中的数据是根据辅助索 引键值排序的。
- 将 缓 存 中 的 键 值 根 据 R o WI D 进 行 排 序 。
- 根据 ROWID 的排序顺 序来访问 实际的数据 文件。
此外,若InnoDB存储引擎或者MyISAM 存储引擎的缓冲池不是足够大,即不能 存放下一张表中的所有数据,此时频繁的离散读操作还会导致绥存中的页被替换出绥冲 池,然后又不断地被读人缓冲池。若是按照主键顺序进行访问,则可以将此重复行为降为最低
5.6.7 Index Condition Pushdown (ICP)优化
索引条件下推
- 不支持Index ConditionPushdown, 当进行索引查询时, 首先根据素引来查找记录,然后再根据 WHERE 条件来
过滤记录。 - 在支持Index Condition Pushdown后,MysQL数据库会在取出素引的同时, 判断是否可以进行 WHERE 条件的过滤,也就是将 WHERE 的部分过滤操作放在 了存储 引擎层。在某些查询下,可以大大减少上层SQL层对记录的素取 (fetch),从而提高数 据库的整体性能。
5.7 哈希索引
5.7.3 自适应哈希泰引
自适应哈希素引采用之前讨论的哈希表的方式实现。不同的是,这仅是数据库自 身创建并使用的,DBA本身并不能对其进行千预。自适应哈希素引经哈希函数映射 到一个哈希表中,因此对于字典类型的查找 非常快速
全文检索
从InnoDB 1. 2. x 版本开始,InnoDB 存储引擎开始支持全文检素,其支持MyISAM 存储引擎的全部功能,并且还支持其他的一些特性
—倒排索引
全文检索通常使用倒排素引(inverted index)来实现。倒排索引同B+树素引一样, 也是一种素引结构。它在辅助表(auxiliarytabie)中存储了单词与单词自身在 一个或多 个文档中所在位置之间的映射。这通常利用关联数组实现,其拥有两种表现形式:
- i n v e r t e d f l e i n d e x , 其 表 现形 式 为 { 单 词, 单 词 所 在 文 档 的 1 D ;
- fall invertedindex,其表现形式为{单词,(单词所在文档的D,在具体文档中的位置)

Documentid 表示进行全文检索文档的Id,Text 表示存储的内容
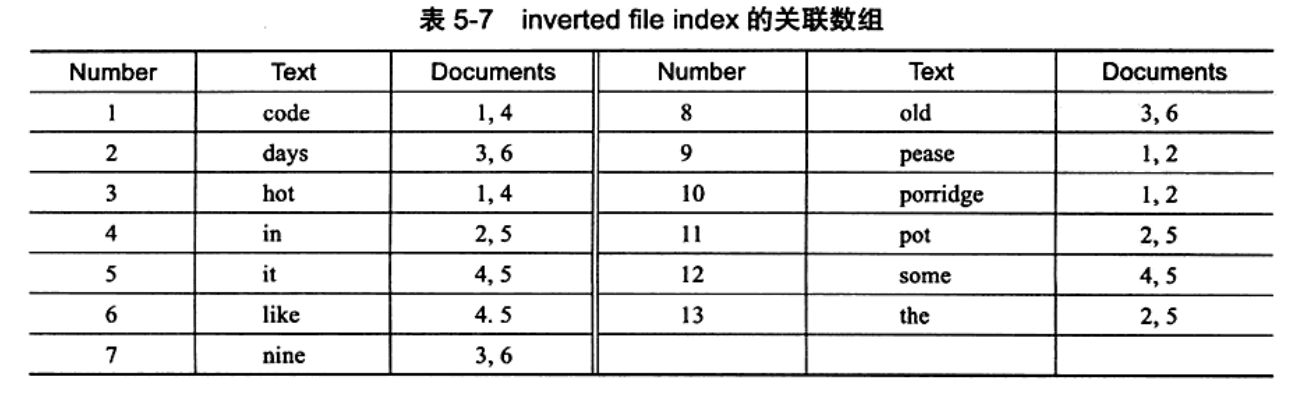
单 词 c o d e 存 在 于 文 档 1 和 4 中 , 单 词 d a y s 存 在 与 文 档 了和 6 中 。 之 厦 要 要进行全文查询就简单了,可以直接根据Documents 得到包含查询关键字的文档。
- “对 于inverted fle index,其仅存取文档Id,而full inverted index存储的是对(pair),即 ( D o c u m e n t i d , P o s i t i o n ) ,
- 而full inverted index存储的是对(pair),即 ( D o c u m e n t i d , P o s i t i o n ) , 因 此 其 存 储 的 倒 排 素 引 如 表 5- 8 所 示 。
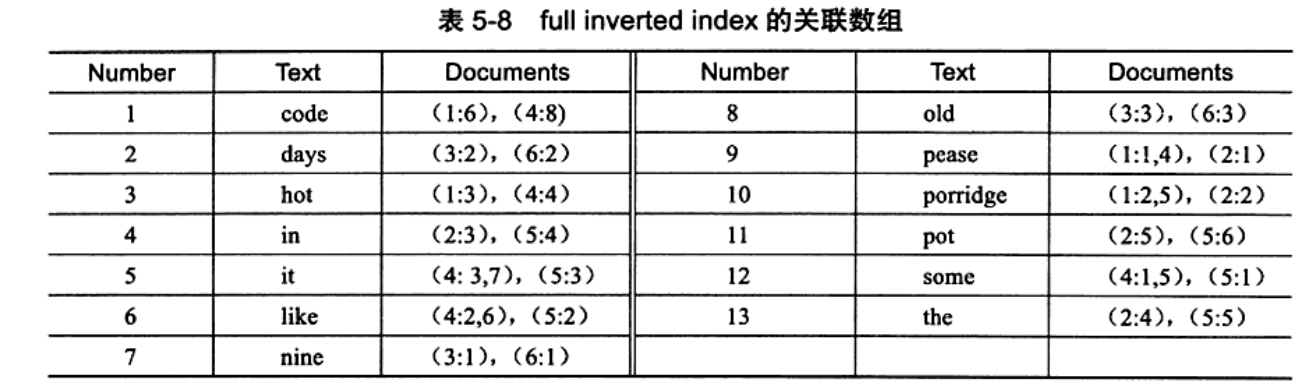
f u l l i n v e r t e d i n d e x 还 存 储 了 单 词 所 在 的 位 置 信 息 , 如 c o d e 这 个 单 词 出 现 在 ( 1 : 6 ),
即文档1的第6 个单词为code。相比之下,full inverted index 占用更多的空间,但是能 更好地定位数据,并扩充一些其他的搜索特性。
—InnoDB全文检索
InnoDB存储引擎从1.2.x版本开始支持全文检索的技术,其采用full inverted index 的方式。在InnoDB存储引擎中,将(Documentld,Position)视为一个“iist ”。因此在全文检素的表中(创建倒排索引后的那张表,类似5-8),有两个列, 一个是word宇段,另 一个是ilist 字段,并且在word 宇段上 有设有索引。
。在IanoDB存储引擎中,为了提高全文检素的并行性能,共 有6张AuxiliaryTable
- Auxili ary Table 是持久的表,存放于磁盘 上。然而在InnoDB 存储引擎的全文索引 中,还有另外一个重要的概念FTSIndexCache (全文检素素引缓存),其用来提高全文
检索的性能。 - FTSIndexCache是一个红黑树结构,其根据(word, ilist)进行排序。这意味着插人的数据已经更新了对应的表,但是对全文素引的更新可能在分词操作后还在-FTSIndes Cache 中,Auxiliar y Table 可能込没有更新。
InnoDB 存儲引擎会批量対Auxili ary Table 进行更新,而不是每次插人后更新 一次Auxiliary Table。
说明:
当对全文检素进行查询时, Auxiliary Table首先会将在FTSIndexCache中対 的word宇段合并到AuxiliaryTable 中,然后再进行查询。
这种merge 操作非常类似之前介绍的Insert Buffer 的功能,不同 的是Inser t Buffer 是一个持久的对象,并且其是B+树的结构。然而FTS Index Cache 的
作 用 又 和 I n s e r t B u f f e r 是 类 似 的 , 它 提 高 了 I n n o D B 存 储 引 擎 的 性 能 , 并 且 由 于其 根 据 红 黑树排序后进行批量插人,其产生的 Auxili ar y Tabl e 相对较小。
当前InnoDB存储引擎的全文检素还存在以下的限制:
- 每张表只能有一个全文检索的素引。
- 由我列组合而成的全文检素的素引列必须使用相同的字符集与排序规则。
- 不 支 持 没 有 单 词 界 定 符 (d e l i m i t e r ) 的 语 言 , 如 中 文 、 日 语 、 韩 语 等 。
5 . 8 . 4 全 文检 索
MysQL数据库支持全文检索(Full-Text Search)的查询,其语法为:
1 | |
第六章 锁
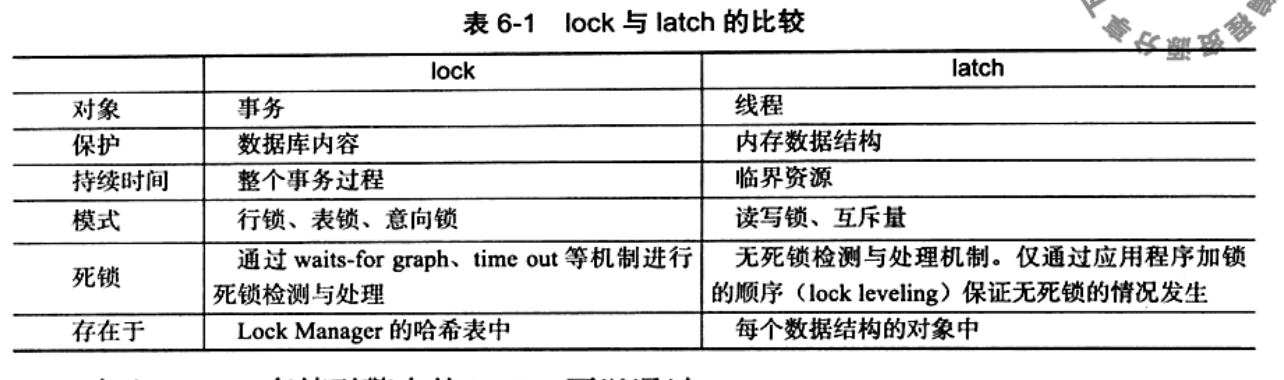
lock 和 latch
- latch 一般称为门锁 (轻量级的锁),因为其要求锁定的时间必领非常短。若持续的时间长,则应用的性能会非常差。在InnoDB存储引擎中,latch又可以分为mutex (互斥量)和rwlock (读写锁)。其目的是用来保证并发线程操作临界资源的正确性,并且 通常没有死锁检测的机制。
- lock 的对象是事务,用来锁定的是数据库中的对象,如表、页、行。并且一般lock 的对象仅在事务commit或ro1lback 后进行释放 (不同事务隔离级别释放的时间可能不同 )。 此 外 , l o c k , 正 如 在 大 多 数 数 据 库 中 一样 , 是 有 死 锁 机 制 的
6.3 InnoDB的锁
6.3.1 锁类型
InnoDB 存储引擎实现了如下两种标准的行级锁:
- 共 享 锁 (S L o c k ), 允 许 事 务 读 一 行 数 据 。
- 排他锁 (XLock),允许事务删除或更新一行数据。
I n n o D B 存 储 引 擎 支 持 多 粒 度 (granular ) 锁 定 , 这 种 锁 定 允 许 事 务 在 行 级 上 的 锁和表级上的锁同时存在。为了支持在不同粒度上进行加锁操作,InnoDB 存储引孳支持 一 种 额 外 的 锁 方 式 , 称 之 为 意 向 锁 (I n t e n t i o n L o c k )。 意 向 锁 是 将 锁 定 的 对 象 分 为 多 个 层 次,意向锁意味着事务希望在更细粒度 ( fine granularity )上进行加锁,
InnoDB 存储引擎支持意向锁设计比较简练,其意向锁即为表级别的锁。设计目的 主要是为了在一个事务中揭示下一行將被请求的锁类型。其支持两种意向锁:
- 1 ) 意 向 共 享 锁 ( IS Lock ), 事 务 想 要 获 得 一 张 表 中 某 几 行 的 共 享 锁
- 2)意向排他锁 (IXLock),事务想要获得一张表中某几行的排他锁
监控锁:
在INFORMATION SCHEMA架构下添加了表NNODB_TRX、 INNODBLOCKS、INNODB LOCK_WAI TS。通过这三张表,用户可以更简单地监控当 前事务并分析可能存在的锁问题。我们将通过具体的示例来分析这三张表, 在之前, 首 先了*看表6-5中表I NODB_TRX的定义,其由8个字段组成。
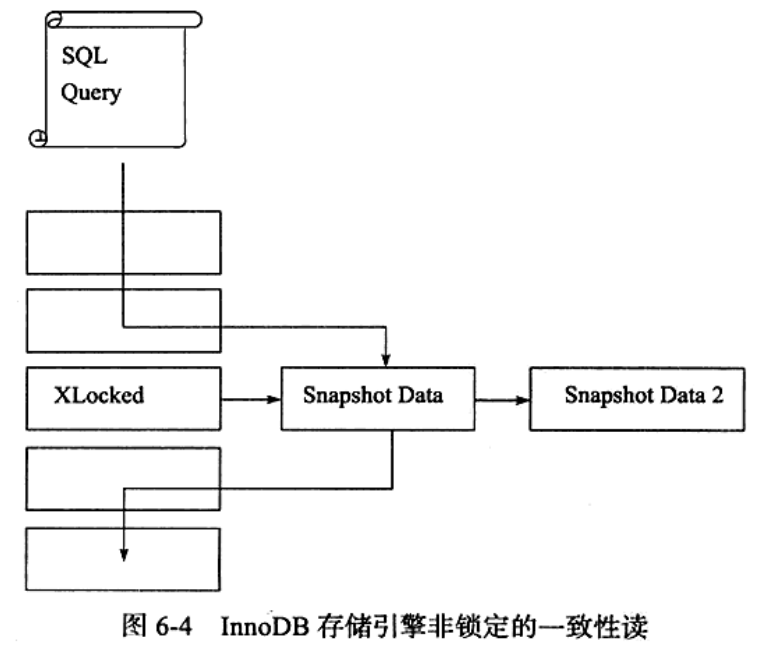
6.3.2 一致性非锁定读(MVCC)
- 在READ COMMITTED 事务隔离级别 下,对于快照数据,非一致 性读总是读取被锁定行的最新一份快照数据。
- 而在REPEATABLE READ事务隔离级别 下,对于快照数据,非一致性读总是读取事务开始时的行数据版本
6.3.3 一致性锁定读
对于SELECT 语句支
持两种一致性的锁定读 (locking read)操作:
- SELECT-•FOR UPDATE
- SELEC T.. LOCK IN SHARE MODE
SELECT• FOR UPDATE对读取的行记录加一个×锁,其他事务不能对已锁定的行加上任何锁。
SELECT• LOCK INSFTAREMODE对读取的行记录加一个s 锁,其他事 务可以向被锁定的行加s 锁,但是如果加×锁,则会被阻塞。
对 于一致性非锁定读,即使读取的行已被执行了SELECT…•FOR UPDATE,也是可 以进行读取的,这和之前讨论的情况一样。此外,SELECT• FORUPDATE, SELECT• L O C K I N S H A R E M O D E 必 须 在 一 个事 务 中, 当 事 务 提 交 了 , 锁 也 就 释 放 了 。 因 此 在 使 用 上述两句SELECT 锁定语句时,务必加上BEGIN, START TRANSACTION 或者SET AUTOCOMMIT=0.
6.3.4 自增长与锁
插人操作会依据这个自增长的计数器值加1赋 子自增长列。这个实现方式称做AUTO-INC Locking。这种锁其实是采用一种特殊的表锁机制,为了提高插人的性能,锁 不是在一个事务完成后才释放,而是在完成对自增长值插人的SQL 语向后立即释放。
- 虽 然 A U T O - I N C L o c k i n g 从 一定 程 度 上 提 高 了 并 发 插 人 的 效 率 , 但 还 是 存 在 一些 性 能上的问题。首先,对于有自增长值的列的并发插人性能较差,事务必须等待前一个插人的完成 (虽然不用等待事务的完成)。
- 其次,对于INSERT• •SELECT 的大数据量的插 人会影响插人的性能,
- 因为另一个事务中的插人会被阻塞。从 M y s Q L 5 . 1 . 2 2 版 本 开 始 , I n n o D B 存 储 引 擎 中 提 供 了一 种 轻 量 级 互 斥 量 的 自 增 长 实现机制,这种机制大大提高了自增长值插人的性能。并且从该版本开始,IanoDB存储
引禁提供了一个参数innodb_autoine lock_mode來控制自增长的模式,该参数的默认值为
在IonoDB存储引擎中,自增长值的列必须是索引,同时必领是家引的第 个列。如果不是第一个列,则MysQL数据库会抛出异常,而MyISAM存储引擎没着这 个问题
—外键和锁
锁的算法
—行锁的3种算法
1 | |
I n n o D B 存 储 引 擎 有 了种 行 锁 的 算 法 , 其 分 别 是 :
- Record Lock:单个行记录上的锁
- Gap Lock:间隙锁,锁定一个范围,但不包含记录本身
- Next-KeyLock: GapLock+RecordLock,锁定一个范围,并且锁定记录本身
—解决Phantom Problem
PhantomProblem是指在同 一事务下,连续执行两次同样的SQL语句可能导致不同 的结果,第二次的SQL 语句可能会返回之前不存在的行。
- 在默认的事务隔离级别 下,即REPEATABLE READ 下,InnoDB存储引擎采用Next-Key Locking 机制来避免Phantom Problem (幻像问题)。
- 这点可能不同于与其他的数据 库 , 如 Or a c l e 数 据 库, 因 为 其 可 能 需 要 在 S E R I A L I Z A B L E 的 事 务 隔 离 级 别 下才 能 解 決 P h an t o m P r o b l e m 。
InnoDB存储引擎采用Next-Key Locking 的算法避免Phantom Problem。对于上述的 SQL 语句SELECT*FROMtWHEREa>2FORUPDATE,其锁住的不是5这单个值,而是对(2,十∞)这个范围加了x 锁。因此任何对于这个范围的插人都是不被允许的,从 而避免Phantom Problem。
InnoDB 存储引擎默认的事务隔离级别是REPEATABLEREAD,在该隔离级别下, 其采用Next-KeyLocking的方式来加锁。
而在事务隔离级别READCOMMI TTED下, 其仅采用Record Lock,
1 | |
1 | |
1 | |
锁问题
—脏读
脏读指的就是在不同的事务下,当前事务可以读到另外事务未提交的数据,简单来说 就 是 可 以 读 到 脏 数 据 。 (read uncommit)
读发生的 条件是需要事务的隔离级别为READUNCOMMITTED
—不可重复读
在 第 一个 事 务 中 的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的情况,这种情况称为不 可重复读。(read commit)
隔离级别设置为READCOMMITTED,在这种隔离级别下允许不 可重复读的现象。
InnoDB 存储引擎的默认事务隔离 级别是READREPEATABLE,采用Next-Key Lock 算法,避免了不可重复读的现象。
—丟失更新
丢失更新是另一个锁导致的问题,简单来说其就是一个事务的更新操作会被另一个 事务的更新操作所覆盖,从而导致数据的不 一致。
- 虽然数据库能阻止丢失更新问题的产生,但是在生产应用中还有另一个逻辑意义的丢失更新问题,而导致该问题的并不是因为数据库本身的问题。
- 实际上,在所有多用户 计算机系统环境下都有可能产生这个问题
锁升级
锁 升 级 (L o c k E s c a l a t i o n ) 是 指 将 当 前 锁 的 粒 度 降 低 。 举 例 来 说 , 数 据 库 可 以 把 一 个表的1000 个行锁升级为 一个页锁,或者将页锁升级为表锁。
第七章 事务
InnoDB 存储引擎默认支持的隔离级别是REPEATABLE READ,但是与标准SQL 不同的是,InnoDB存储引警在REPEATABLE READ事务隔离级别下,使用Next-Key L o c k 锁 的 算 法 , 因 此 避 免 幻 读 的 产 生 。 这 与 其 他 数 据 库 系 统 (如 Mi c r o s o f t S Q L S e r v er
数据库)是不同的。所以说,InnoDB存储引擎在默认的REPEATABLE READ的事务隔 离级别下已经能完全保证事务的隔离性要求,即达到SQL 标准的SERI ALIZABLE隔离 级别。
7.1 事物
7.1.1 概述
A ( A t o m i c i t y ), 原 子 性 。
假设取款的流程为:
- 1)登录 A TM 机 平台,验证密码 。
- 2 )从远程银行的数据库中,取得账户的信息。
- 3用 户 在 A T M 机 上输 人 欲 提 取 的 金 额 。
- 4)从远程银行的数据库中,更新账户信息。
- 5 ) A TM 机 出 款 。
- 6 )用户取钱。
整个取款的操作过程应该视为原子操作,即要么都做,要么都不做。
C (consistency),一致性。一致性指事务将数据库从一种状态转变为下一种一致 的状态。在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
I ( isolation ),隔离性。隔离性还有其他的称呼,如并发控制 (concurrencycontrol)、
可串行化 (serializability)、锁 (locking)等。事务的隔离性要求每个读写事务的对象对 其他事务的操作对象能相互分离,即该事务提交前对其他事务都不可见,通常这使用锁 来实现。当前数据库系统中都提供了一种粒度锁‘granular lock)的策略,允许事务仅锁 住 一个实体对象的子集,以此来提高事务之间的并发度
D ( d u r a b i l i t y ), 持 久 性 。 事 务 一旦 提 交 , 其 结 果 就 是 永 久 性 的 。 即 使 发 生 宕 机 等 故 障,数据库也能特数据恢复。需要注意的是,只能从事务本身的角度来保证结果的永久 性。例如,在事务提交后,所有的变化都是永久的。
- 即使当数据库因为崩溃而需要恢复 时,也能保证恢复后提交的数据都不会丢失。
- 但若不是数据库本身发生故障,而是一些 外部的原因,如RAID 卡损坏、自然灾害等原因导致数据库发生问题,那么所有提交的 数 据 可 能 都 会 丢 失 。
因 此 持 久 性 保 证 事 务 系 统 的 高 可 靠 性 ( Ht i g h R e l i a b i l i t y ) , 而 不 是 高 可 用 性 (H i g h A v a i l a b i l i t y ) 。 对 于 高 可 用 性 的 实 现 , 事 务 本 身 并 不 能 保 证 , 需 要 一 些 系 统 共同配合来完成。
7.1.2 事务的分类
从事务理论的角度来说,可以把事务分为以下几种类型:
- 扁平事务(Flat Transactions)
- 带有保存点的扁平事务 (Flat Transactionswith Savepoints) 又链事务 (ChainedTransactions)
- 嵌套事务 (Nested Transactions)
- 分布式事务 (DistributedTransactions)
扁平事务
保存点
嵌套事务
保存点
7.2 事务的实现
底层原理的实现,包括文件格式 的解读
7.2.1 Redo
基本概念
重做日志用来实现事务的持久性,即事务ACID 中的D。其由两部分组成 : 一是内
存 中 的 重 做 日 志 缓 冲 ( r e d o 1 o g b u f f e r ), 其 是 易 失 的 ; 二 是 重 做 日 志 文 件 ( r e d o l o g f l e ) , 其是持久的。
InnoDB是事务的存储引擎,其通过Force Log at Commit 机制实现事务的持久
性 , 即 当 事 务 提 交 (C O M M I T ) 时 , 必 须 先 将 该 事 务 的 所 有 日 志 写 人 到 重 做 日 志 文 件
进行持久化,待事务的COMMIT操作完成才算完成。这里的日志是指重做日志,在 IanoDB存储引擎中,由两部分组成,即redo1og和undo1og。redo 1og用米保证事务的 持久性,undo 1og用来帮助事务回滚及MVCC的功能。redo 1og 基本上都是顺序写的,
在数据库运行时不需要对redo 1og 的文件进行读取操作。而undo 1og 是需要进行随机读 写的。
为了确保每次日志都写人重做日志文件,在每次将重做日志绥冲写人重做日志文件 后,IDnoDB存储引擎都需要调用一次fsync 操作。由于重做日志文件打开并没有使用 。DI RECT 选项,因此重做日志缓冲先写人文件系统缓存。log block
在InoDB存储引擎中,重做日志都是以512- 字节进行存储的。这意味着重做日志 缓存、重做日志文件都是以块 (block)的方式进行保存的,称之为重做日志块 (redo l o g b l o c k ), 每 块 的 大 小 为 5 1 2 字 节 。
7.2.2 undo
基本概念
重做日志记录了事务的行为,可以很好地通过其对页进行“重做” 操作。但是事务 有时还需要进行回滚操作,这时就需要undo。因此在对数据库进行修改时,InnoDB 存 储引擎不但会产生redo,还会产生一定量的undo。这样如果用户执行的事务或语句由于 某 种 原 因 失 败 了, 又 或 者 用 户 用 一 条 R O L L B A C K 语 句 请 求 回 滚 , 就 可 以 利 用 这 些 u n d o 信息将数据回滚到修改之前的样子。
r e d o 存 放 在 重 做 日 志 文 件 中, 与 r e d o 不 同 , u n d o 存 放 在 数 据 库 内 部 的 一 个 特 殊 段
( s e g m e n t ) 中 , 这 个 段 称 为 u n d o 段 (u n d o s e g m e n t ) 。 u n d o 段 位 于 共 享 表 空 间 内 。 可 以
通过py_innodb_page_info.py 工具来查看当前共享表空间中undo的数量。如下代码显示 当前的共享表空间ibdatal 内有2222 个undo页。undo 存储管理
InoDB存储引擎对undo的管理同样 用段的方式。但是这个段和之前介绍的段有 所不同。首先InnoDB存储引擎有ro1lback segment,每个回滚段种记录了1024个undo
1og segment,而在每个undo log segment 段中进行undo 页的申请。共享表空间偏移量 为了的页(0,5)记录了所有rollbacksegment header所在的页,这个页的类型为FIL_PAGE_TYPE_SYS.
在InnoDB1. 1版本之前(不包括1. 1版本),只有一个rollbacksegment,因此支持同时在线的事务限制为1024。虽然对绝大多数的应用来说都已经够用,但不管怎么说这是 一个瓶颈。从1 1版本开始InnoDB 支持最大128 个rollback segment,故其支持同时在
线的事务限制提高到了 128*1024。 虽然InnoDB1.1版本支持了128个rollbacksegment,但是这些rollbacksegment 都存储于共享表空间中。从InnoDB1.2版本开始,可通过参数对rollbacksegment 做进一步 的设營。这些参数包括:- innodbundodirectory
- innodb_undo_logs
- innodb_undo_tablespaces
参数innodb_undo_directory用于设置rollbacksegment 文件所在的路径。这意味着 rollback segment 可以存放在共享表空问以外的位置,即可以设置为独立表空间。
undo log 格式
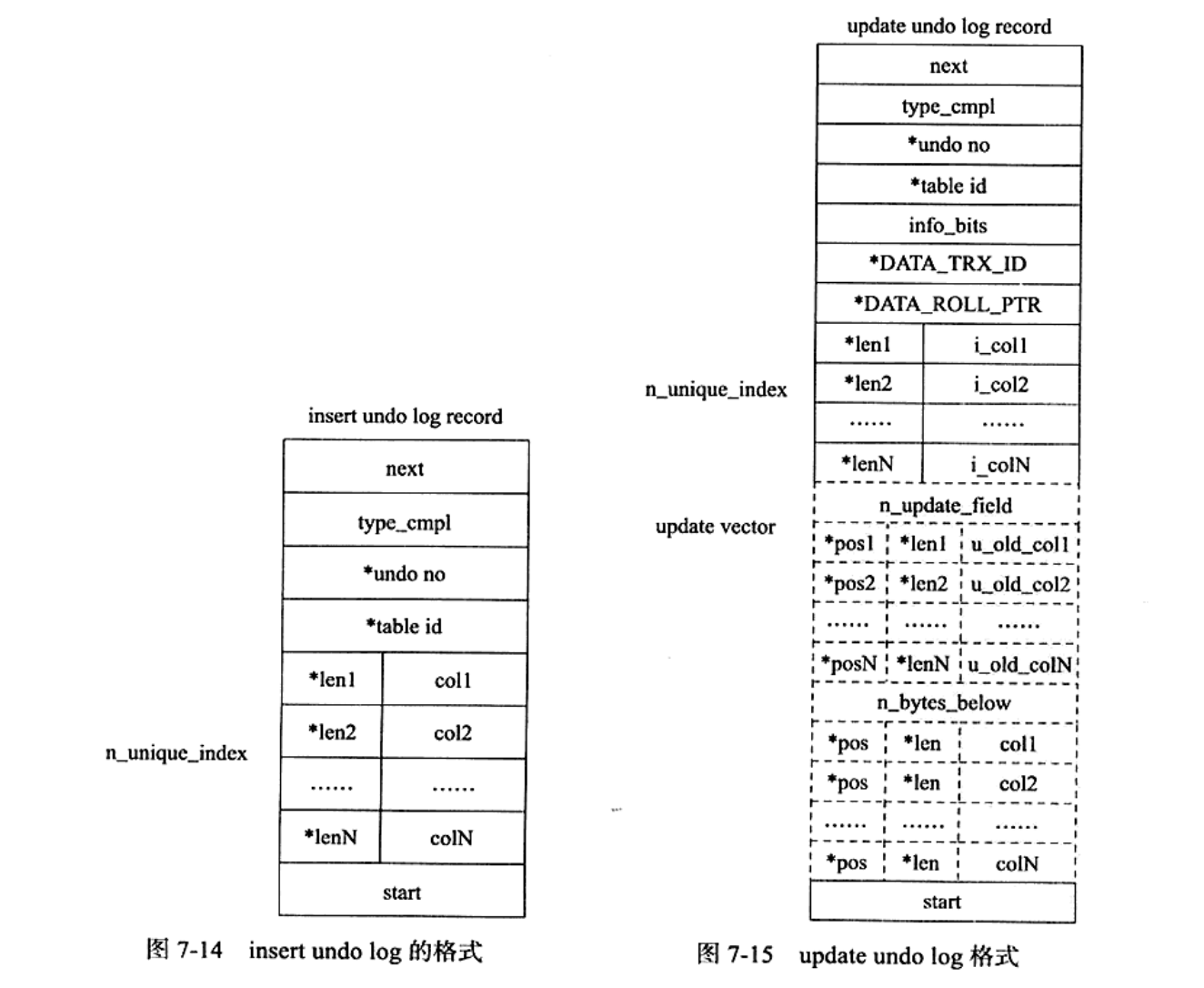
在InnoDB存储引擎中,undo 1og 分为:
• insert undo log
O update undo log
i n s e r t u n d o 1o g 是 指 在 i n s e r t 操 作 中 产 生 的 u n d o 1o g 。 因 为 i n s e r t 操 作 的 记 录 , 只 对
事务本身可见,对其他事务不可见(这是事务隔离性的要求),故该undo 10g 可以在事 务提交后直接删除。不需要进行 pur ge 操作。
第八章 备份与恢复
8.1 备 份 与 恢 复
概 述 可以根据不同的类型来划分备份的方法。根据备份的方法不同可以将备份分为:
HotBackup (热备)
Cold Backup (冷备)
WarmBackup (温备)
Hot Backup 是指数据库运行中直接备份,对正在运行的数据库操作没有任何的影 响。这种方式在MySQL官方手册中称为OnlineBackup(在线备份)。
ColdBackup 是指备份操作是在数据库停止的情况 下,这种备份最为简单,一般只需要复制相关的数据库物 理 文 件 即 可 。 这 种 方 式 在 M y s Q L 官 方 手 册 中 称 为 O 9 i n e B a c k u p ( 离 线 备 份 )。
W a r m Bckup 备份同样是在数据库运行中进行的,但是会对当前数据库的操作有所影响,如加 一 个全局读锁以保证备份数据的 一致性。
按照备份后文件的内容,备份叉可以分为:
- 逻辑备份
- 裸 文件畚份
在MySQL数据库中,逻辑备份是指备份出的文件内容是可读的,一般是文本文件。内容一般是由一系条sQL谭何,或者是表内交际数据组成。如mysoldu里B和 SELECT*INTO OU TFILE 的方法。这类方法的好处是可以观察导出文件的内容, 一般适 用于数据库的升级、迁移等工作。但其缺点是恢复所需要的时问往往较长。 裸文件备份是指复制数据库的物理文件,既可以是在数据库运行中的复制 (如 ibbackup、xtrabackup 这类工具),也可以是在数据库停止运行时直接的数据文件复制。 这类备份的恢复时间往往较逻辑备份短很多。
若按照备份数据库的内容来分,备份又可以分为:
- 完全备份
- 增 量备 份
- 日志备份
完全备份是指对数据库进行一个完整的备份。
增量备份是指在上次完全备份的基础 上,对于更改的数据进行备份。
日志备份 主要是指对MySQL 数据库二进制日志的备份,通过对一个完全备份进行二进制日志的重做 (replay)来完成数据库的point-in-time 的恢 复工作。MysQL 数据库复制 (replication)的原理就是异步实时地将二进制日志重做传 送并应用到从 (slave/standby )数据库。
8.7 复制
8.7. 1 复制的工作原理
复制(replication)是MysQL数据库提供的 一种高可用高性能的解决方案,一般用 来建立大型的应用。总体来说,replicat ion 的工作原理分为以 下3 个步骤:
- 1 ) 主 服 务 器 (m a s t e r ) 把 数 据 更 改 记 录 到 二进 制 日 志 (b i n l o g ) 中 。
- 2 ) 从 服 务 器 ( s l a v e ) 把 主 服 务 器 的 二进 制 日 志 复 制 到 自 己 的 中 继 日 志 ( r e l a y l o g ) 中 。
- 从 服 务 器 重 做 中 继 日 志 中 的 日 志 , 把 更 改 应 用 到 自 己 的 数 据 库 上 , 以 达 到 数 据的最终 一致性。
8.7.2 快照+复制的备份架构
复制可以用来作为备份,但功能不仅限于备份,其主要功能如下:
- 数据分布。由于MysQL 数据库提供的复制并不需要很大的带宽要求,因此可以 在不同的数据中心之间实现数据的复制 。
- 读取的负载平衡。通过建立兰个从服纺羅,可粉读取平均地分布到这訾金照我 器 中 , 并 且 减 少 了 主 服 务 器 的 压 力。 一 般 通 过 D N S 的 R o u n d - R o b i n 和 L i n u x 的
LVS 功能都可以实现负载平衡。 又数据库备份。复制对备份很有帮助,但是从服务器不是备份,不能完全代替备份。 又高可用性和故障转移。通过复制建立的从服务器有助于故障转移,减少故障的停
机时间和恢复时间
其他 - 2. 什么是 MVCC?
看一遍就理解:MVCC原理详解 - 掘金 (juejin.cn)
MVCC,即Multi-Version Concurrency Control (多版本并发控制)。它是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
通俗的讲,数据库中同时存在多个版本的数据,并不是整个数据库的多个版本,而是某一条记录的多个版本同时存在,在某个事务对其进行操作的时候,需要查看这一条记录的隐藏列事务版本id,比对事务id并根据事物隔离级别去判断读取哪个版本的数据。
数据库隔离级别读已提交、可重复读 都是基于MVCC实现的,相对于加锁简单粗暴的方式,它用更好的方式去处理读写冲突,能有效提高数据库并发性能。
3. MVCC实现的关键知识点
3.1 事务版本号
事务每次开启前,都会从数据库获得一个自增长的事务ID,可以从事务ID判断事务的执行先后顺序。这就是事务版本号。
3.2 隐式字段
对于InnoDB存储引擎,每一行记录都有两个隐藏列trx_id、roll_pointer,如果表中没有主键和非NULL唯一键时,则还会有第三个隐藏的主键列row_id。
| 列名 | 是否必须 | 描述 |
|---|---|---|
| row_id | 否 | 单调递增的行ID,不是必需的,占用6个字节。 |
| trx_id | 是 | 记录操作该数据事务的事务ID |
| roll_pointer | 是 | 这个隐藏列就相当于一个指针,指向回滚段的undo日志 |
3.3 undo log
undo log,回滚日志,用于记录数据被修改前的信息。在表记录修改之前,会先把数据拷贝到undo log里,如果事务回滚,即可以通过undo log来还原数据。
可以这样认为,当delete一条记录时,undo log 中会记录一条对应的insert记录,当update一条记录时,它记录一条对应相反的update记录。
undo log有什么用途呢?
- 事务回滚时,保证原子性和一致性。
- 用于MVCC快照读。
3.4 版本链
多个事务并行操作某一行数据时,不同事务对该行数据的修改会产生多个版本,然后通过回滚指针(roll_pointer),连成一个链表,这个链表就称为版本链。如下:
其实,通过版本链,我们就可以看出事务版本号、表格隐藏的列和undo log它们之间的关系。我们再来小分析一下。
- 假设现在有一张core_user表,表里面有一条数据,id为1,名字为孙权:
- 现在开启一个事务A: 对core_user表执行
update core_user set name ="曹操" where id=1,会进行如下流程操作
- 首先获得一个事务ID=100
- 把core_user表修改前的数据,拷贝到undo log
- 修改core_user表中,id=1的数据,名字改为曹操
- 把修改后的数据事务Id=101改成当前事务版本号,并把roll_pointer指向undo log数据地址。
3.5 快照读和当前读
快照读: 读取的是记录数据的可见版本(有旧的版本)。不加锁,普通的select语句都是快照读,如:
1 | |
当前读:读取的是记录数据的最新版本,显式加锁的都是当前读
1 | |
3.6 Read View
- Read View是什么呢? 它就是事务执行SQL语句时,产生的读视图。实际上在innodb中,每个SQL语句执行前都会得到一个Read View。
- Read View有什么用呢? 它主要是用来做可见性判断的,即判断当前事务可见哪个版本的数据~
Read View是如何保证可见性判断的呢?我们先看看Read view 的几个重要属性
- m_ids:当前系统中那些活跃(未提交)的读写事务ID, 它数据结构为一个List。
- min_limit_id:表示在生成ReadView时,当前系统中活跃的读写事务中最小的事务id,即m_ids中的最小值。
- max_limit_id:表示生成ReadView时,系统中应该分配给下一个事务的id值。 === next_limit_id
- creator_trx_id: 创建当前read view的事务ID
Read view 匹配条件规则如下:
- 如果数据事务ID
trx_id < min_limit_id,表明生成该版本的事务在生成Read View前,已经提交(因为事务ID是递增的),所以该版本可以被当前事务访问。 - 如果
trx_id>= max_limit_id,表明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。 - 如果
min_limit_id =<trx_id< max_limit_id,需腰分3种情况讨论
- (1).如果
m_ids包含trx_id,则代表Read View生成时刻,这个事务还未提交,但是如果数据的trx_id等于creator_trx_id的话,表明数据是自己生成的,因此是可见的。- (2)如果
m_ids包含trx_id,并且trx_id不等于creator_trx_id,则Read View生成时,事务未提交,并且不是自己生产的,所以当前事务也是看不见的;- (3).如果
m_ids不包含trx_id,则说明你这个事务在Read View生成之前就已经提交了,修改的结果,当前事务是能看见的。
1 | |
4. MVCC实现原理分析
4.1 查询一条记录,基于MVCC,是怎样的流程
- 获取事务自己的版本号,即事务ID
- 获取Read View
- 查询得到的数据,然后Read View中的事务版本号进行比较。
- 如果不符合Read View的可见性规则, 即就需要Undo log中历史快照;
- 最后返回符合规则的数据
InnoDB 实现MVCC,是通过 Read View+ Undo Log 实现的,Undo Log 保存了历史快照,Read View可见性规则帮助判断当前版本的数据是否可见。
4.2 读已提交(RC)隔离级别,存在不可重复读问题的分析历程
- 创建core_user表,插入一条初始化数据,如下:
- 隔离级别设置为读已提交(RC),事务A和事务B同时对core_user表进行查询和修改操作。
1 | |
执行流程如下:
最后事务A查询到的结果是,name=曹操的记录,我们基于MVCC,来分析一下执行流程:
(1). A开启事务,首先得到一个事务ID为100
(2).B开启事务,得到事务ID为101
(3).事务A生成一个Read View,read view对应的值如下
| 变量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后回到版本链:开始从版本链中挑选可见的记录:
由图可以看出,最新版本的列name的内容是孙权,该版本的trx_id值为100。开始执行read view可见性规则校验:
1 | |
由此可得,trx_id=100的这个记录,当前事务是可见的。所以查到是name为孙权的记录。
(4). 事务B进行修改操作,把名字改为曹操。把原数据拷贝到undo log,然后对数据进行修改,标记事务ID和上一个数据版本在undo log的地址。
(5) 提交事务
(6) 事务A再次执行查询操作,新生成一个Read View,Read View对应的值如下
| 变量 | 值 |
|---|---|
| m_ids | 100 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本链:从版本链中挑选可见的记录:
从图可得,最新版本的列name的内容是曹操,该版本的trx_id值为101。开始执行Read View可见性规则校验:
1 | |
因此,trx_id=101这个记录,对于当前事务是可见的。所以SQL查询到的是name为曹操的记录。
综上所述,在读已提交(RC)隔离级别下,同一个事务里,两个相同的查询,读取同一条记录(id=1),却返回了不同的数据(第一次查出来是孙权,第二次查出来是曹操那条记录),因此RC隔离级别,存在不可重复读并发问题。
4.3 可重复读(RR)隔离级别,解决不可重复读问题的分析
在RR隔离级别下,是如何解决不可重复读问题的呢?我们一起再来看下,
还是4.2小节那个流程,还是这个事务A和事务B,如下:
4.3.1 不同隔离级别下,Read view的工作方式不同
实际上,各种事务隔离级别下的Read view工作方式,是不一样的,RR可以解决不可重复读问题,就是跟Read view工作方式有关。
- 在读已提交(RC)隔离级别下,同一个事务里面,每一次查询都会产生一个新的Read View副本,这样就可能造成同一个事务里前后读取数据可能不一致的问题(不可重复读并发问题)。
| begin | |
|---|---|
| select * from core_user where id =1 | 生成一个Read View |
| / | / |
| / | / |
| select * from core_user where id =1 | 生成一个Read View |
- 在可重复读(RR)隔离级别下,一个事务里只会获取一次read view,都是副本共用的,从而保证每次查询的数据都是一样的。
| begin | |
|---|---|
| select * from core_user where id =1 | 生成一个Read View |
| / | |
| / | |
| select * from core_user where id =1 | 共用一个Read View副本 |
4.3.2 实例分析
我们穿越下,回到刚4.2的例子,然后执行第2个查询的时候:
事务A再次执行查询操作,复用老的Read View副本,Read View对应的值如下
| 变量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本链:从版本链中挑选可见的记录:
从图可得,最新版本的列name的内容是曹操,该版本的trx_id值为101。开始执行read view可见性规则校验:
1 | |
所以,trx_id=101这个记录,对于当前事务是不可见的。这时候呢,版本链roll_pointer跳到下一个版本,trx_id=100这个记录,再次校验是否可见:
1 | |
所以,trx_id=100这个记录,对于当前事务是可见的。即在可重复读(RR)隔离级别下,复用老的Read View副本,解决了不可重复读的问题。
4.4 网络江湖传说,MVCC是否解决了幻读问题呢?
网络江湖有个传说,说MVCC的RR隔离级别,解决了幻读问题,我们来一起分析一下。
4.4.1 RR级别下,一个快照读的例子,不存在幻读问题
由图可得,步骤2和步骤6查询结果集没有变化,看起来RR级别是已经解决幻读问题啦~
4.4.2 RR级别下,一个当前读的例子
假设现在有个account表,表中有4条数据,RR级别。
- 开启事务A,执行当前读,查询id>2的所有记录。
- 再开启事务B,插入id=5的一条数据。
流程如下:
显然,事务B执行插入操作时,阻塞了~因为事务A在执行select ... lock in share mode(当前读)的时候,不仅在id = 3,4 这2条记录上加了锁,而且在id > 2 这个范围上也加了间隙锁。
因此,我们可以发现,RR隔离级别下,加锁的select, update, delete等语句,会使用间隙锁+ 临键锁,锁住索引记录之间的范围,避免范围间插入记录,以避免产生幻影行记录,那就是说RR隔离级别解决了幻读问题???
4.4.3 这种特殊场景,似乎有幻读问题
其实,上图事务A中,多加了update account set balance=200 where id=5;这步操作,同一个事务,相同的sql,查出的结果集不同了,这个结果,就符合了幻读的定义~
作者:捡田螺的小男孩
链接:https://juejin.cn/post/7016165148020703246
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。