秋招面经
面试常见
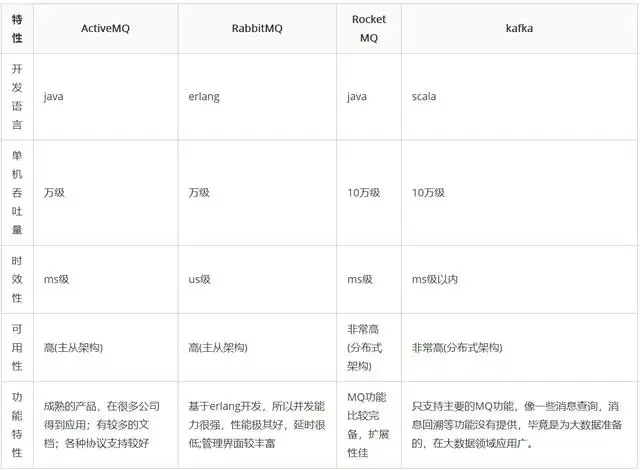
TCP 粘包/拆包
1 | |
GOD – 可看
推荐阅读:
《全链路异步,让你的 SpringCloud 性能优化10倍+》
《阿里一面:你做过哪些代码优化?来一个人人可以用的极品案例》
《阿里二面:千万级、亿级数据,如何性能优化? 教科书级 答案来了》
《峰值21WQps、亿级DAU,小游戏《羊了个羊》是怎么架构的?》
《Springcloud gateway 底层原理、核心实战 (史上最全)》
《分库分表 Sharding-JDBC 底层原理、核心实战(史上最全)》
《clickhouse 超底层原理 + 高可用实操 (史上最全)》
《队列之王: Disruptor 原理、架构、源码 一文穿透》
《环形队列、 条带环形队列 Striped-RingBuffer (史上最全)》
《一文搞定:SpringBoot、SLF4j、Log4j、Logback、Netty之间混乱关系(史上最全)》
《缓存之王:Caffeine 源码、架构、原理(史上最全,10W字 超级长文)》
《Java Agent 探针、字节码增强 ByteBuddy(史上最全)》
《Zookeeper Curator 事件监听 - 10分钟看懂》
目录
- 说在前面
- DDD(Domain Driven Design)理解
- DDD的基本概念
- DDD四种模式
- DDD建模方法
- DDD分层架构
- 领域驱动设计一般分为两个阶段
- 阶段一:战略阶段
- 阶段二:战术阶段
- 领域驱动落地框架
- DDD实战
- DDD 与微服务的关系
- 最后浓缩一下:DDD的四重边界
- 参考文献:
- [推荐阅读:
——–自己的——–
其他
问题
项目重点:
- 总结重点 —- 先总后分
技能点:
- 面试突出自己的重点
我的公司面试
1 | |
一分钟自我介绍
技能点介绍:
在开发逸游天下的时候,接触到的JVM ,并利用JVM的监控工具 JProfile 进行过调优,以及JMeter进行压力测试,检测方案的性能。
比如:文章模块有获取文章评论的需求,设计的时候,讲文章的评论内容和 评论关系,作为两个1-1的关联实体。
我们通过 子评论,获取当前 子评论 下的 评论评论的时候,需要递归查询;
当时实现的时候出现一个失误,每次查询一个 评论实体,就根据评论实体的 内容id 去查询评论内容;- 这就导致了频繁的 查询 MySQL(每一层都要进行一次查询 comment),
- 背景:在进行 压测的时候,有50%的请求直接报错。
- 定位流程:(具体流程)通过JProfile 观察到,大量线程阻塞,并且线程数很高;此外 连接池对象 HiKariConnect 占用的内存比较大,最终定位到具体逻辑,
- 结论:分析得出,为递归查询时,导致了大量的 MySQL的请求,从而造成了 请求无法响应,线程阻塞 和 连接池连接数居高
- 通过两点优化: 在MySQL 进行递归查询,查询评论内容的时候,直接采用批量查询,减少请求MySQL 的查询次数。
问题:
为什么 评论内容 和 评论 分开 :减少递归查询时评论关系的时候,MySQL IO次数
就算分开,也可以通过 rootid, 区分??:在 根评论下的子评论,查找该子评论的 树型关系时
这个子评论的 树形关系有两个:一个是子评论,一个是父评论
需要找到父评论为空位置,即 通过当前 子评论,找到当前子评论的 根父评论,然后通过根父评论,找到这个根下的所有子评论
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16WITH RECURSIVE cte AS (
-- 初始查询,找到当前子评论的根父评论
SELECT comment_id, parent_id, content
FROM comments
WHERE comment_id = [当前子评论的id]
UNION ALL
-- 递归查询,找到根父评论下的所有子评论
SELECT c.comment_id, c.parent_id, c.content
FROM comments c
INNER JOIN cte ON c.parent_id = cte.comment_id
)
SELECT *
FROM cte
WHERE parent_id IS NULL;1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22<!-- commentsMapper.xml -->
<mapper namespace="com.example.CommentsMapper">
<select id="findRootAndDescendants" resultType="com.example.Comment">
WITH RECURSIVE cte AS (
SELECT comment_id, parent_id, content
FROM comments
WHERE comment_id = #{childCommentId}
UNION ALL
SELECT c.comment_id, c.parent_id, c.content
FROM comments c
INNER JOIN cte ON c.parent_id = cte.comment_id
)
SELECT *
FROM cte
WHERE parent_id IS NULL;
</select>
</mapper>
项目介绍:
项目驱动技能点学习:
- 开发的时候总会遇到各种问题,每次都会有各种调用栈信息,所以看来一下报错的调用栈,外加debug的时候需要进行源码追踪,所以看了很多源码,例如:spring boot 配合 spring framework
- 看源码需要有很多设计模式的技巧,比如spring boot的 简单工厂模式,aop代理模式,单例模式、原型模式、事件监听模式,模板方法模式,以及一些 面向切面编程的特性 等等,所以学习了 23种设计模式
- 既然学了,刚好当时想要做一个 工具,因为建表语句和数据库测试数据比较难写,所以就搞了一个 sql-mock 进行模拟数据的生成,这个项目就用到一些涉及模式:简单工厂、单例模式、策略者模式、建造者模式builder、方言模式, 进行设计与实现
- 第二项目就是主要以 spring security 和 ES 搜索为主,进行 权限管理 和 图书高效、复杂搜索; 在使用spring security的时候,就顺便看来一下鉴权流程,然后在逸游天下 中用到了,并自定义了短信登录的验证方式。
- 1、第三个项目也是微服务架构项目,由五个团队成员共同开发,分别是两个前端,两个后端,一个负责项目总览。我主要负责的后端的订单模块,秒杀模块,鉴权模块,文章模块,搜索模块 模块的设计于实现。
2、这个项目考虑分布式情况下的问题,比如分布式锁解决同步问题,rabbitmq 实现saga 事务,分布式调度xxl-job的简单使用,秒杀模块的多极限流、以及 多域 的token 权限验证。
3、这里也借鉴了微服务设计模式的 网关模式 统一权限处理,至于 服务发现、远程调用、
4、后来,接触到 DDD,并简单看过一点领域模型的概念,就使用领域驱动模式对项目进行了重构,核心域有:文章、商品、订单、优惠;支撑域有:用户、库存、物流; 通用域:鉴权、支付、评论与回复
二面:
1、就你如果做缓存,同步策略是什么,怎么保证的一致性,考虑了持久化吗,如果宕机了怎么办,会丢失数据吗,丢失了怎么办
2、结合项目的实际场景和八股来答
3、持久化机制说出来,再考虑你项目对丢失数据的影响大不大,然后配置了哪个持久化策略
4、我经常被问,如果让你现在考虑,应该怎么设计呢
1 | |
恒生-挂 9/26
9/26 线下
线下面试“气质”比较重要
金山办公 武汉- 面试挂 9/25
一面 - 9/25
1、自我介绍
- 计算机网络+操作系统
2、IO 多路复用
2、socket模型(具体步骤:应该分为客户端和服务端进行回答,没答好)
2、半连接队列的位置在哪(意识到不在socket、在协议栈中,操作系统内核维护。。 没答上来)
(问我怎么学的,我不可能真看Linux吧,看书、看面经呗 — 估计开始怀疑我的成分了,呜呜)
- Java:
3、JDK1.7 和 1.8 的 hashmap区别,在那个包下(java.util.*)
redist相关:
4、redis 的zset 底层数据结构,什么情况下使用压缩列表(128个,64byte)
5、如何学习的redis(看书、官方文档),redis 官网地址(redis.io)、set命令 的 参数列表,redis 命令复杂度为o(n)
1 | |
5、项目中哪些地方用到了redis
5、十万、百万数据量如何进行实时排序,
6、Docker 常见命令,DockerFile 放置路径、主要有哪些参数
6、SQL 优化,大表和小表的join 如何优化
当处理大表和小表的JOIN操作时,以下是一个示例的解决方案:
- 小表驱动大表:
1 | |
在这个示例中,将小表作为驱动表,大表作为被驱动表。通过将小表放在前面,可以减少大表的扫描和匹配操作,提高查询效率。
- 使用索引:
1 | |
在这个示例中,为参与JOIN操作的列创建了索引,通过索引加快数据的查找和匹配速度。可以根据实际情况选择合适的列创建索引。
- 使用临时表:
1 | |
在这个示例中,先将大表根据条件筛选出需要的数据存储在临时表中,然后再与小表进行JOIN操作。通过减少JOIN操作的数据量,提高查询效率。
- 分批处理:
1 | |
在这个示例中,将大表和小表分成多个批次进行JOIN操作,每次处理一部分数据。通过分批处理,可以减少内存的占用和查询的时间,提高整体的性能。
需要根据具体的业务需求和数据库系统来选择和实施适合的优化策略。以上示例仅供参考,具体的解决方案需要根据实际情况进行调整和优化。
如果你有特定的业务场景或更具体的需求,可以提供更多的信息,以便提供更具体的解决方案示例。
6、介绍一下实习主要是做什么的,实现的那几个需求
反问:主语言是go (准备面试题)
40min
绿盟- 面试挂 10/7
一面- 9/22
1 | |
二面 - 10/7
1、网络协议层提升 QPS的 方法
- 负载均衡
- TCP / IP 层 :
- 缓存:Nginx 缓存、CDN分发器 、
2、ES – 倒排索引的数据结构
3、ES 的集群模式
4、RPC 为什么快:估计从 TCP角度出发
5、如何提升 QPS :
景旺 - 准备offer - 10/31 offer
转岗 7000 测试 拒绝
1+2 == 20min -10/9
- 思想考察
- 实习经历介绍
- 对加班的看法
- 对制造业的看法
滴滴 - 11/24 排序挂 - 11/29 oc
- 我们是滴滴网约车核心的后端研发团队,参与网约车核心出行、出行中台、智能补贴引擎等公司级核心项目的研发,致力于用技术体系解决出行业务中复杂的纠纷与安全等负向问题,提升滴滴用户的体验及满意度。技术上你会面对滴滴复杂业务领域的技术体系建设。团队技术氛围浓厚,成长迅速。
一面-10/11
Redis 的
CAP理论
rabbitmq 的 cp、ap:cp
Reactor 模型
算法:八皇后问题
二面-10/11
项目battle:
介绍一下项目的难点:先总后分
battle了半天的 分布式事务:2pc、3pc、TCC、最终一致性
算法:二叉树的最右边列表集合(BFS,保证 空间复杂度,保证高效)
三面-10/11
多线程:core线程数目一般如何确定:计算密集性、IO密集性
进程如何 进程调度算法
Redis 的内存淘汰策略:7种(本来知道的,面试官邪魅一笑,我就没说了,只说了LRU、LFU)
Reactor + IO 多路复用的 多线程数据传输模型:epoll 监听Socket的Read 和 write 如何保证是同一个
- 考虑单Reactor 多线程,则 read、write 都是由 main线程负责,可以保证是同一个socket 的fd
Mysql的 redo、undo log 作用,补充了 bin log 、 replay log
介绍一下 领域驱动设计:领域模型、限界上下文、领域通用语言、服务设计
算法:司机、订单、收益:如何使得收益最大化
有效组合:
- 司机之间 订单不重复,
- 可以有订单没有被接收
D1 o1 o2 o3 2
D1 02 1.5
D2 o3 1.2
金升阳 - 候选-11/6 offer
10k + 每年调薪
一面-hr面 - 10/12
为什么选择广州
技能点介绍
对于工资的期待
二面 - 10/13
自我介绍
CAP 业务,具体的业务
CAP理论在分布式系统设计中具有重要的指导意义。下面是一些具体的业务应用场景,展示了CAP理论在实际中的应用: 电子商务平台:在电子商务平台中,一致性和可用性是非常重要的。用户需要能够随时访问和购买商品,同时订单和库存等数据需要保持一致。在这种情况下,可以通过使用分布式数据库和复制机制来实现数据的高可用性和一致性。 社交媒体平台:在社交媒体平台中,可用性和分区容错性是关键。用户需要能够实时发布和查看动态,同时平台需要能够处理大量的用户请求。在这种情况下,可以使用分布式消息队列和负载均衡等技术来实现高可用性和分区容错性。 金融交易系统:在金融交易系统中,一致性和可用性都是至关重要的。交易数据需要保持一致性,同时用户需要能够随时进行交易操作。在这种情况下,可以使用分布式事务和数据复制等技术来实现数据的一致性和高可用性。 物联网平台:在物联网平台中,可用性和分区容错性是关键。设备需要能够实时上传数据,并能够被远程访问和控制。在这种情况下,可以使用分布式数据存储和消息队列等技术来实现高可用性和分区容错性。 需要注意的是,不同的业务场景对CAP特性的需求可能有所不同。在实际应用中,需要根据具体的业务需求和系统特点来进行权衡和选择。有时候可能需要在一致性、可用性和分区容错性之间做出取舍,根据业务的重要性和实际需求来确定最合适的方案1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
## 保融科技-oc 10/17 offer
10/17 - oc - 11k - 当天逼签三方,违约金11k
### 一面-10/14
- 群面-1h
0、自我介绍 1min
1、线程池介绍
2、日志介绍
3、集合:HashMap 和 线程安全问题
4、异常是什么,请详细介绍
5、讨论业务问题:A、B 转账,银行业务
6、1min - 1.5 min 介绍实习经历
7、如何理解乐观锁和悲观锁
- 乐观锁和悲观锁是并发控制的两种不同策略,用于解决多线程或多进程环境下的数据访问冲突问题。
1. 乐观锁:
- 乐观锁的基本思想是假设并发访问的数据不会发生冲突,因此在读取数据时不会加锁,只有在更新数据时才会进行冲突检测。
- 乐观锁通常使用版本号或时间戳等机制来实现。在读取数据时,会记录下数据的版本号或时间戳。在更新数据时,会比较当前数据的版本号或时间戳与之前读取的版本号或时间戳是否一致,如果一致则更新成功,否则表示数据已被其他线程修改,需要进行冲突处理。
- 乐观锁适用于读操作远远多于写操作的场景,可以提高并发性能,但需要处理冲突的情况。
2. 悲观锁:
- 悲观锁的基本思想是假设并发访问的数据会发生冲突,因此在读取和更新数据时都会加锁,以防止其他线程对数据的修改。
- 悲观锁通常使用互斥锁(如Mutex)或读写锁(如ReadWriteLock)来实现。在读取数据时,会获取共享锁,允许其他线程同时读取数据;在更新数据时,会获取排他锁,阻止其他线程读取或写入数据,直到当前线程完成操作。
- 悲观锁适用于写操作频繁的场景,可以确保数据的一致性,但会降低并发性能。
需要根据具体的业务场景和数据访问模式选择合适的锁策略。乐观锁适用于读多写少的场景,可以提高并发性能;悲观锁适用于写多读少或读写操作频繁的场景,可以确保数据的一致性。
希望这个解答能够帮助你理解乐观锁和悲观锁的概念。如果还有任何疑问,请随时提问。
8、业务题:select 期间进行 update 会不会影响 select的结果 — read view ,read commit / repeated – 不影响
总结:都是一些很大问题,一组人(8个)各自说明、补充完善,每人一下,时间就过去了。
### 二面-10/15 - 40min
1、自我介绍
2、如何学习的这么多技能点
3、如何理解DDD(简历中有写到)
4、接下来就是照抄的问题:
- 大学假期,最有成就感的一件事
- 你自己的优点是什么
- 你的缺点是什么
- 父母对你的影响
- 遇到的最大的挫折是什么
- ……
## 武汉多比特-oc - 10/19 offer
10/19 - oc
10k + 900 , 五险一金12% ,拒
### 一面-10/16
1、自我介绍+项目介绍
业务:
2、多线程 读取一个文件夹下的文件(s)内容,如何判断读取完成,进行接下来的任务(CountDownLatch)
3、select —> update / insert == 通过锁的方式控制流程
- select … for update 如何加锁 – 间隙锁 / next-key
4、什么时候使用索引、 什么时候创建索引
5、项目中的rabbitmq 如何设置来保证 主从模式的一致性
6、什么时候索引,索引优化的方式
7、事务的隔离级别
### 二面-10/16
1、最近在阅读什么书籍
2、看b站视频 和 看书 有什么区别
3、什么时候
## 中通-Java - 11/9 排序挂
### 一面 - 10/17 - 30min
- 问题:
- 1、尽量多关注业务的使用
- 2、技术不在于多,而在于精
- 3、
0、字我介绍
1、Integer 和 int 的使用场景
2、秒杀的压测 - 侧重于哪些,不要讲高性能
3、如何快速融入团队(实习)
- 体验文档 :了解项目的业务,从使用者角度分析项目
4、深拷贝 和 浅拷贝 的区别,如何快速实现深拷贝
5、值传递 和 引用传递
6、
### 二面-10/23 - 30min
设计模式有哪些应用
设计模式的优缺点有哪些
MyBatis 的源码 - 如何实现分页 、拦截器有哪些
> MyBatis是一个流行的Java持久层框架,它提供了一些拦截器(Interceptor)来扩展和定制其行为。以下是一些常用的MyBatis拦截器:
>
> 1. Executor拦截器(ExecutorInterceptor):用于拦截执行器(Executor)的操作,如查询、更新等。可以在执行SQL语句之前或之后进行一些自定义的处理。
> 2. StatementHandler拦截器(StatementHandlerInterceptor):用于拦截语句处理器(StatementHandler)的操作,如预处理SQL语句、设置参数等。可以在执行SQL语句之前或之后进行一些自定义的处理。
> 3. ParameterHandler拦截器(ParameterHandlerInterceptor):用于拦截参数处理器(ParameterHandler)的操作,如设置参数值等。可以在设置参数之前或之后进行一些自定义的处理。
> 4. ResultSetHandler拦截器(ResultSetHandlerInterceptor):用于拦截结果集处理器(ResultSetHandler)的操作,如处理查询结果集、映射结果等。可以在处理结果集之前或之后进行一些自定义的处理。
>
> 这些拦截器可以通过实现MyBatis提供的Interceptor接口来自定义。通过拦截器,可以在MyBatis的执行过程中插入自定义的逻辑,例如日志记录、性能监控、权限控制等。
>
> 需要注意的是,拦截器的顺序非常重要,它们按照配置的顺序依次执行。可以通过MyBatis的配置文件或注解来配置拦截器,并指定它们的顺序。
Bean的生命周期
AOP
项目中遇到的问题,怎么解决,有什么收获 : spring security
### 三面-10/26 - 12min
- 感觉被压制了
1、字我介绍
2、社团负责业务
3、团队协作过程中的问题
4、自我评价:自己在团队协作中的优势
5、有没有offer、薪资问题、为什么拒绝
6、反问。。。
## 金山云 - 11/9 排序挂
### 一面-10/24 - 45min
1、线程的状态、
- 如何进入blocking 状态
- wait、sleep 方法 是否会释放锁,会不会占用cpu
2、线程池
- 参数
- 线程执行流程
- 任务执行出现异常如何处理 – submit 、execute
3、hashmap 和 concurrentHashMap
- 并发安全问题
- CAS的应用
- 如何加锁
-
3、mysql 数据库
- 存储引擎 对比
- 日志文件
- SQL 执行流程
- 5.7 和 8.0 的区别
- B+ \ B \ 二叉树 \ 二叉平衡树 ,为什么采用 B+ 树
- 索引有哪些,ABCD - ABD 联合索引使用问题,索引下推,回表是什么
算法 + SQL
- 表:姓名、科目、成绩,问:如何获取每个科目最大成绩的学生信息
```SQL
SELECT s.*
FROM students s
JOIN (
SELECT 科目, MAX(成绩) AS 最高成绩
FROM students
GROUP BY 科目
) t ON s.科目 = t.科目 AND s.成绩 = t.最高成绩;
122. 买卖股票的最佳时机 II - 力扣(LeetCode)
- 两种方案:动态规划、差分数组(贪心)
二面-10/26-30min
介绍一些秒杀模块逻辑
上次面试的算法和SQL 思路
聊天-30min
同程旅游 - 11/2 - 排序挂
- 主要是做搜索的
- 和hr battle薪资,把我挂了
一面-10/25 - 30min
自我介绍+ 介绍项目介绍
秒杀模块的业务逻辑
搜索模块如何实现的,大概逻辑
文章搜索 有哪些关键词作为搜索
ES 的相关概念,建立索引流程、mapping映射、document、index
spring boot 的启动流程
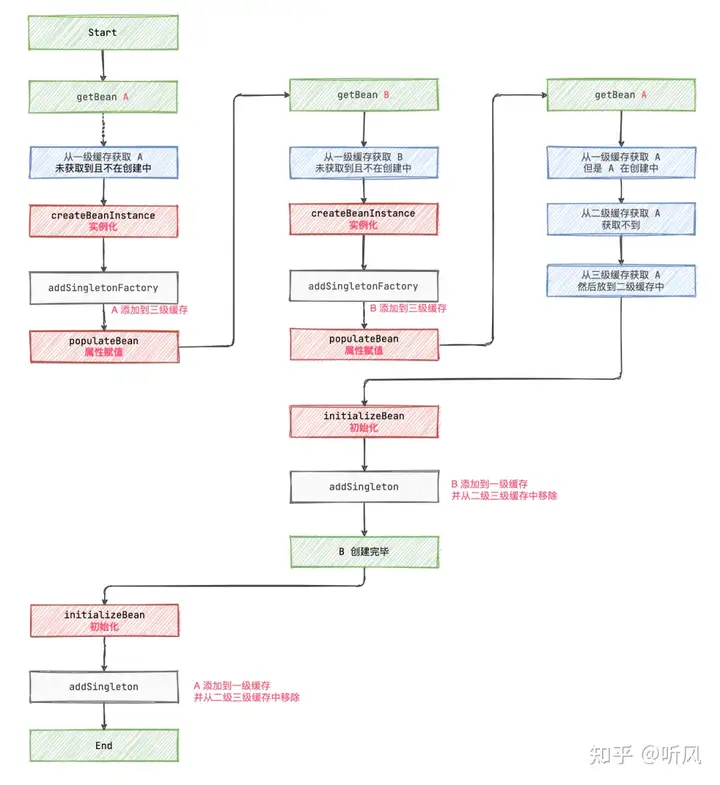
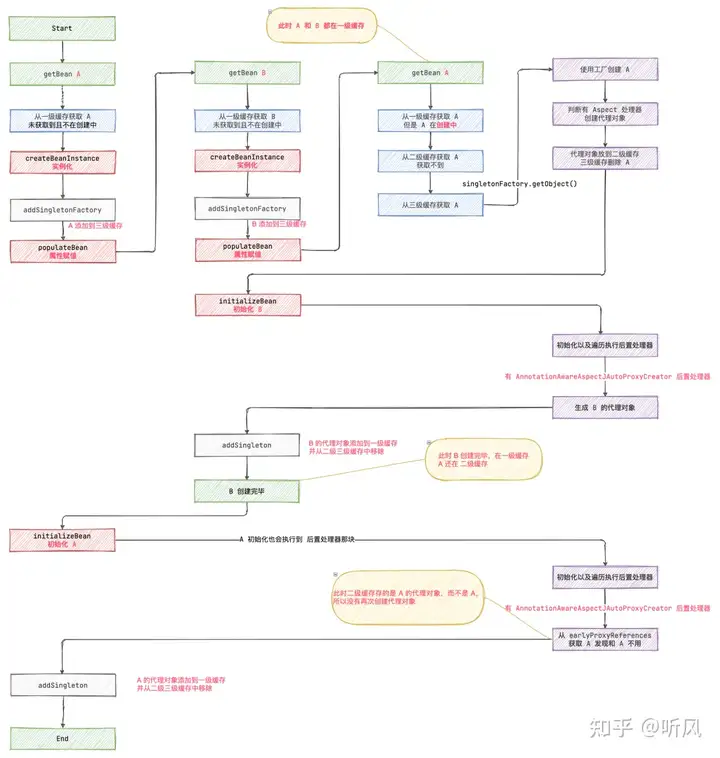
三级缓存:彻底搞懂Spring之三级缓存解决循环依赖问题 - 知乎 (zhihu.com)
spring boot 的相关注解
算法:
- leetcode : 购买股票的方式最大收益 –
- 两种方案 - dp 和 贪心
二面-10/31-40min
两道编程题:二分 + 单例模式
实习经历:
- 项目介绍
- 作业调度
- 项目的上线流程
ES 的使用、分片、副本
- IK 分词器
场景题
- CPU 突然升高
- Java的GC
- 线程数 – 业务 x N
- 业务本身的问题 — DFS / BFS
- JVM 调优 – 年轻代、老年代内存设置
三面-11/2 - 15min
正常liu’cheng
博思软件-10/26 拒
- 薪资太低,达不到要求
一面-hr面-10/26-20min
无自我介绍
实习遇到的问题,怎么解决的
Java开发的流程大概是怎样的 – 迭代开发流程
金山办公 广州
一面-10/30 - 40min
1、http1.0 和 1.1
- http 几个请求的区别
2、TCP 和 http 的长连接 keepAlive 是一个东西吗
不是4.15 TCP Keepalive 和 HTTP Keep-Alive 是一个东西吗? | 小林coding (xiaolincoding.com)
如何开启长连接
要开启HTTP的长连接,需要在HTTP协议层面进行设置,并且不需要显式地开启TCP层的Keep-Alive。
在HTTP/1.1中,默认情况下,连接是持久化的,也就是说,客户端和服务器之间的连接会保持打开状态,以便在同一个连接上发送多个请求和响应。这样可以减少连接的建立和关闭的开销,提高性能。
要开启HTTP的长连接,可以通过以下方式:
- 在HTTP请求头中添加”Connection: keep-alive”字段。这告诉服务器要保持连接打开。
- 在HTTP响应头中添加”Connection: keep-alive”字段。这告诉客户端要保持连接打开。
- 在服务器端,可以通过配置服务器软件(如Apache、Nginx等)来设置长连接的超时时间,以控制连接的保持时间。
需要注意的是,虽然HTTP的长连接可以提高性能,但长时间保持连接也会占用服务器资源。因此,在实际应用中,需要根据具体的业务需求和服务器的负载情况来合理设置长连接的超时时间。
至于TCP层的Keep-Alive,它是一种TCP协议的机制,用于检测连接是否仍然有效。在HTTP的长连接中,默认情况下,浏览器和服务器会自动发送TCP层的Keep-Alive探测包,以保持连接的有效性。因此,不需要显式地开启TCP层的Keep-Alive。
如果您需要更多关于HTTP长连接的信息,建议使用以下查询词进行搜索:HTTP长连接 keep-alive
3、什么是虚拟内存
4、进程和线程的区别
5、spring 的注入方式有哪些,项目中常用的是哪一种、为什么
6、为什么会去开发一个项目,出发点是什么
算法:输入一个数组,输出 ai 的下一个大于的 aj – (j- i) 的值;例如 3 1 4 — 2 1 0
- 方法:单调栈的方式
场景题
用户表:能否使用 身份证 作为主键索引
- 不是有序的
- 区分度不高,不能作为索引
用户表- 主键索引、联合索引、索引排序字段:
- 索引 和 limit 优化,limit 10, 和 limit 1000, 10; 如何优化
- 联合索引的生效问题:A B , B , A or B
数据200亿条,如何进行读取到文件中:
- 自行考虑 单机还是多机,文件是一个还是多个
- 如果考虑节点宕机,如何进行恢复
二面 - 11/13
- 30min
1、你如何理解设计模,会如何给没听说过的人介绍设计模式
2、Map - 插入1亿数据,会发生什么:解决hash冲突、复杂度问题、值覆盖
3、如何统计网页的日活、原理 :hyperloglog、概率 + 伯努利方程
4、如果设计搜索,不借助ES、MySQL ,设计一个根据名词 进行图书搜素,你会如何设计:
- 分词器 + 倒排索引 -==
5、你会如何设计倒排索引,如何进行 document_id 的取并集操作
- 双指针、bitmap
6、top 100 问题
轻度科技 - 11/15 - 实习offer
- 2h 10-12k
- 需要提前实习,判断薪资
15min - 测评
30min - hr面
45 min - monitor面
1、Java 如何管理内存-流程,发生大量full-gc 怎么办
2、实习经历介绍
3、Java 多线程 – 线程池的参数、使用
4、为什么采用 redis + lua
- 先将分布式锁的 原子性 问题 :原子加锁、原子解锁、自动续期、可重入
- 信号量 semaphore 机制
- 最后 lua 的逻辑问题
5、http 和 https 的区别 :
- https 的加密流程
- 对称加密方式有哪些:AES、DES
- 非堆成加密方式有哪些:ECDHE
图源素 - 11/24 oc
- 8-13k, 需要提前实习,拒了
一面 - 11/16 - 20min
1、equals 和 == 的区别,深拷贝 和 浅拷贝,如何实现 copyProperties方法
2、了解哪些 关系型数据库 和 非关系型数据库,如何理解多个关系型数据库的不同之处
3、实习经历介绍,有没有负责专业的领域,spring boot 还是 spring cloud
4、docker run 的参数有哪些,网络通信问题
5、如何理解 领域驱动设计
6、spirng boot 和 spring framework的区别
Spring Boot和Spring Framework是两个相关但有一些区别的Java开发框架。
- Spring Framework:Spring Framework是一个全功能的Java开发框架,提供了广泛的功能和模块,包括依赖注入、面向切面编程、数据访问、事务管理、Web开发等。Spring Framework需要手动配置和集成各个模块,开发者需要编写大量的配置代码。它适用于需要灵活性和定制性的大型企业级应用。
- Spring Boot:Spring Boot是基于Spring Framework的快速开发框架,旨在简化Spring应用程序的配置和部署。它提供了自动配置和约定优于配置的原则,减少了开发者的配置工作。Spring Boot还集成了常用的第三方库和工具,如嵌入式Web服务器、数据库访问、安全性等。它适用于快速开发和构建微服务、云原生应用和快速原型开发等场景。
总结来说,Spring Framework是一个全功能的Java开发框架,需要手动配置和集成各个模块,适用于大型企业级应用。而Spring Boot是基于Spring Framework的快速开发框架,提供了自动配置和约定优于配置的原则,适用于快速开发和构建微服务等场景。
二面 - 11/20 - 30 min
- 综合面的感觉
远算科技 - 11/22 OC
- 一天四面,+ CEO 面 = 五面
一面 - 1h - 11/16
0、如何理解 C++、Java、Golang 的区别,他们适用场景是什么
- C会被取代吗
- Golang 相较于 Java 的优势、劣势
- C++、Java和Golang是三种不同的编程语言,它们有以下区别和适用场景:
- C++是一种通用的编程语言,它继承了C语言的特性,并添加了面向对象编程的支持。C++适用于需要高性能和底层控制的应用,如游戏开发、系统编程和嵌入式开发等。
- Java是一种面向对象的编程语言,它具有平台无关性和强大的生态系统。Java适用于构建大型企业级应用、Web应用、移动应用和分布式系统等。
- Golang(Go)是一种开源的编程语言,它具有简洁的语法、高效的并发性和内置的并发模型。Golang适用于构建高并发的网络服务、分布式系统和云原生应用等。
C语言不会被完全取代,因为它在系统编程和嵌入式领域仍然具有重要的地位。C语言具有高效的性能和对硬件的底层控制能力,因此在需要直接操作硬件或对性能要求极高的场景下仍然被广泛使用。
Golang相较于Java的优势和劣势:
- 优势:
- 并发性:Golang内置了轻量级的协程(goroutine)和通信机制(channel),使得编写高并发程序更加简单和高效。
- 性能:Golang具有高效的垃圾回收机制和编译器优化,可以提供较高的性能。
- 简洁性:Golang具有简洁的语法和标准库,使得代码编写和维护更加容易。
- 部署和构建:Golang的编译器可以将代码编译为独立的可执行文件,无需依赖其他运行时环境,方便部署和分发。
- 劣势:
- 生态系统:相对于Java而言,Golang的生态系统相对较小,一些第三方库和工具可能不如Java丰富。
- 泛用性:Golang在某些领域的支持可能不如Java成熟,特别是在企业级应用和大型系统方面。
需要根据具体的项目需求和技术要求来选择合适的编程语言。
1、二叉树的遍历方式:前、中、后
2、图的遍历方式:深度、广度优先遍历
3、第一范式、第二范式、第三范式:
- 一:不可分割的列
- 一 + 消除 部分依赖
- 二 + 消除 传递依赖
4、现代操作系统常用的内存管理方式:段页式内存管理
段页式内存管理是一种将分段和分页两种内存管理技术结合起来的方法,它相较于分段和分页有以下优势:
- 灵活性:段页式内存管理结合了分段和分页的优点,可以同时提供段和页的灵活性。每个进程可以被划分为多个段,每个段可以进一步划分为多个页。这样可以更好地适应不同程序的内存需求,提供更灵活的内存管理方式。
- 地址空间的隔离:分段和分页都可以提供地址空间的隔离,但它们各自的方式有一定的局限性。分段只能将地址空间划分为不同的逻辑段,而分页只能将地址空间划分为固定大小的页。而段页式内存管理可以同时提供段和页的划分,既可以将地址空间划分为不同的逻辑段,又可以将每个段划分为固定大小的页,从而更好地实现地址空间的隔离。
- 内存利用率:段页式内存管理可以更好地利用内存空间。分段和分页都存在一定的内部碎片问题,而段页式内存管理可以通过将段划分为固定大小的页来减少内部碎片。这样可以提高内存的利用率,减少内存浪费。
- 保护和权限控制:段页式内存管理可以提供更细粒度的保护和权限控制。每个段和每个页都可以设置不同的访问权限,从而实现更精细的内存保护和权限控制。这对于提高系统的安全性和稳定性非常重要。
需要注意的是,段页式内存管理也存在一些缺点,比如管理复杂性增加、内存访问的开销增加等。因此,在选择内存管理技术时,需要根据具体的应用场景和需求进行权衡和选择。
如果您有其他问题,请随时提问。
5、怎么理解 《领域驱动设计》
6、常见的排序算法有哪些【O(n logn) 复杂度的 】
7、二十三种设计模式分为那三大类:
- 创造者模式:管理对象、实例 (单例模式、享元模式、工厂模式)
- 结构型模式:搭建多个实例之间的关系架构 – (桥接模式、门面者模式)
- 行为型模式:控制实例的具体行为、方法调用(解释器模式、模板方法)
算法:
- 下楼梯(水仙花数) + 括号匹配(栈 + 判断)
二面 - 1h - 11/16
1、
2、HTTPS 相比与 HTTP 的区别在哪
3、操作系统 内核态 和 用户态的区别:
操作系统中的内核态和用户态是指不同的特权级别或权限级别,用于区分操作系统内核和用户程序的执行环境。它们之间的区别如下:
- 特权级别:内核态是操作系统内核运行的特权级别,具有最高的权限,可以执行特权指令和访问系统资源。用户态是用户程序运行的特权级别,权限较低,受到限制,不能直接访问系统资源和执行特权指令。
- 访问权限:在内核态下,操作系统内核可以直接访问和操作系统的所有资源,包括硬件设备、内存等。而在用户态下,用户程序只能通过系统调用接口间接地访问操作系统提供的服务和资源。
- 执行能力:在内核态下,操作系统内核可以执行特权指令,如修改页表、中断处理等,具有更高的执行能力。而在用户态下,用户程序不能直接执行特权指令,只能执行受限的指令集。
- 安全性:内核态和用户态的划分可以提高系统的安全性。内核态下的操作系统内核可以对系统资源进行保护和管理,防止用户程序对系统造成破坏。用户态下的用户程序受到操作系统的保护,不能直接访问和修改系统资源,从而保护系统的稳定性和安全性。
通过将操作系统内核和用户程序的执行环境划分为内核态和用户态,可以实现对系统资源的保护和管理,提高系统的安全性和稳定性。
如果您有其他问题,请随时提问。
4、分布式共识算法:Raft介绍、Paxos、zookeeper 和 ETCD 的区别
5、讲一下 常见的网络协议层,以及每层常见的协议有哪些
6、你了解云计算是什么吗?
云计算:
云计算是一种基于互联网的计算模式,通过网络提供计算资源和服务。它将计算能力、存储空间和应用程序等资源集中在数据中心,并通过互联网按需提供给用户。用户可以通过云服务提供商提供的接口和工具,根据自己的需求快速获取和使用这些资源和服务。
云计算具有以下特点:
- 弹性伸缩:云计算可以根据用户的需求进行弹性伸缩,即根据实际的计算负载自动调整计算资源的规模。用户可以根据需要增加或减少计算资源,以适应业务的变化。
- 按需自助服务:云计算提供了按需自助服务的方式,用户可以根据自己的需求自主选择和使用云服务。用户可以根据需要随时申请、配置和管理计算资源,而无需事先进行大量的投资和部署。
- 共享资源池:云计算通过共享资源池的方式提供计算资源和服务。多个用户可以共享同一组资源,根据需要进行分配和使用。这种共享方式可以提高资源的利用率和效率。
- 高可靠性和可用性:云计算通过在多个数据中心分布计算资源和数据副本,提供高可靠性和可用性的服务。即使某个数据中心发生故障,用户的数据和应用程序仍然可以在其他数据中心继续运行。
- 按使用付费:云计算采用按使用付费的模式,用户只需根据实际使用的资源和服务付费,避免了传统IT基础设施的高成本投资和维护费用。
云计算在各个领域都有广泛的应用,包括云存储、云服务器、云数据库、云应用开发等。它为用户提供了灵活、高效和经济的计算资源和服务,推动了数字化转型和创新的发展。
云原生:
云原生(Cloud Native)是一种软件开发和部署的方法论,旨在充分利用云计算的优势,构建弹性、可扩展和可靠的应用程序。云原生应用程序是专门为云环境设计和构建的,具有以下特点:
- 容器化:云原生应用程序通常使用容器技术(如Docker)进行打包和部署。容器化可以提供隔离性、可移植性和可复制性,使应用程序更加灵活和可管理。
- 微服务架构:云原生应用程序采用微服务架构,将应用程序拆分为多个小型、独立的服务。每个服务都可以独立开发、部署和扩展,提高了应用程序的灵活性和可伸缩性。
- 弹性伸缩:云原生应用程序可以根据实际负载的变化进行弹性伸缩。通过自动化的方式,根据需求增加或减少容器实例的数量,以适应不同的负载情况。
- 自动化管理:云原生应用程序借助自动化工具和平台,实现自动化的部署、监控、扩展和恢复等管理操作。这样可以减少人工操作的复杂性和错误,并提高应用程序的可靠性和可维护性。
- 云原生基础设施:云原生应用程序依赖于云原生基础设施,如容器编排平台(如Kubernetes)、服务网格(如Istio)和持续交付工具链等。这些基础设施提供了丰富的功能和工具,支持云原生应用程序的构建和管理。
云原生的目标是提供更高效、可靠和可扩展的应用程序,以满足现代云计算环境下的需求。它强调敏捷开发、持续交付和自动化管理,促进了软件开发和运维的协同和创新。
7、传统文件系统 与 OSS 对象存储的区别
传统文件系统和OSS(Object Storage Service)对象存储有以下几个主要区别:
- 数据组织方式:传统文件系统以文件和目录的形式组织数据,使用层次结构来管理文件和目录的关系。而OSS对象存储以对象的形式存储数据,每个对象都有一个唯一的标识符(Key),对象之间没有层次结构的关系。
- 存储方式:传统文件系统将文件存储在物理磁盘上,通过文件系统的索引结构来管理文件的存储和访问。而OSS对象存储将对象以分布式的方式存储在多个服务器上,通过对象存储系统的分布式架构来管理对象的存储和访问。
- 数据访问方式:传统文件系统通过文件路径来访问文件,可以直接读取和写入文件的内容。而OSS对象存储通过对象的唯一标识符(Key)来访问对象,可以通过HTTP或SDK等方式进行对象的上传、下载和删除等操作。
- 数据一致性:传统文件系统通常提供强一致性的数据访问,即读取到的数据是最新的。而OSS对象存储通常提供的是最终一致性,即在一定时间内读取到的数据可能不是最新的,但会保证最终数据的一致性。
- 可扩展性和容量:OSS对象存储具有良好的可扩展性和高容量存储能力,可以存储大规模的数据,并且可以根据需求进行动态扩展。而传统文件系统的扩展性和容量受限于单个服务器的硬件和存储能力。
需要根据具体的应用场景和需求来选择使用传统文件系统还是OSS对象存储。传统文件系统适用于需要直接访问文件和目录结构的场景,而OSS对象存储适用于需要大规模存储和分布式访问的场景。
如果您有其他问题,请随时提问。
算法:
- 二叉树的每层最左边的数集合(广度优先遍历) + 找到前k 小的数(快排)
三面 - 30min - 11/16
- 聊天为主
hr 面 - 30min - 11/16
- 正常的hr面问题
CEO面 - 30min - 11/20
类似于 hr 面
阿里- 钉钉 - Java
一面 - 11/27
- 53min
- 算法:K个升序链表的排序
有没有面过阿里的其他部门
实习篇:先介绍简历里的实习内容
1、docker、k8s 的了解程度
2、CLS、COS 、k8s 文件下载
3、有没有遇到哪些问题,需要关注哪些问题,有没有相关的检测指标
4、spring aop + dynamicDataSource : region分区与数据库问题
5、COS 依赖下载:临时预签名
项目篇:介绍项目内容
1、项目人员配置,负责内容
2、分布式锁介绍
3、分布式事务介绍
4、项目有没有搭建
基础篇:
1、thread 的sleep 和 wait 的区别
2、JVM的类的加载流程
- 当时答得一般,估计g了
阿里-钉钉- 运维开发
1 | |
——–其他的——–
得物 - 9 /16
1、redis分布锁有哪些 实现机制 setnx
- setnx - redis + lua 脚本
2、mysql类型转换索引失效的问题
mysql 索引失效:
类型转化导致,int -》varchar,varchar -》int == mysql 支持 字符串->数组, (隐式类型转化)- MySQL 在遇到字符串和数字比较的时候,会自动把字符串转为数字,然后再进行比较。
表达式
函数
%xxx == 左模糊匹配,
最左匹配原则,< | <= | > | >=
where 中的 or 有一个不是索引因为
3、AOP用了哪些设计模式
- 代理模式
- 策略模式 – 生成代理的策略(JDK、CGlib)
- 装饰者模式:不修改原有代码,对业务逻辑进行增强
4、vilotail除了可见性还有什么 为什么单线程不需要这个关键字多线程需要
5、多线程通信方式
- 消息队列 - rabbitmq
- 共享内存
- 同步队列
- 信号量 / 锁
- socket
6、CPU几级缓存
7、JMM模型
8、mysql 能解决幻读吗
9、MVCC能解决幻读吗
10、hash map为什么是不安全的 哪些方法是不安全的
11、currenthashmap为什么是安全的
12、为什么线程A看不到线程B的变量
绿盟 - 9/15
1 | |
浪潮
什么是RBAC鉴权模型,我实习是怎么做细粒度鉴权的
spring的aop
分布式事务讲讲
注册中心用什么做的,nacos和gateway怎么用的
chatgpt怎么解析sql的
枚举用户id越权访问资源漏洞怎么解决的
常见的安全问题
项目中有做过压测吗,平时会看那些指标
JMeter,指标:吞吐量、访问时间、QPS、并发数、错误率、
火焰图
JProfileter
多线程、锁下有哪些注意事项
Jmeter 压力测试
在JMeter进行性能测试时,可以关注以下几个常见的压测指标:
- 吞吐量(Throughput):表示系统在单位时间内处理的请求数量。通常以每秒请求数(Requests per Second,RPS)来衡量,较高的吞吐量表示系统能够处理更多的请求。
- 响应时间(Response Time):表示系统处理请求所需的时间。可以关注平均响应时间、最大响应时间、最小响应时间等指标,较低的响应时间表示系统的性能较好。
- 并发用户数(Concurrency):表示同时发送请求的用户数量。通过观察并发用户数的变化,可以了解系统在不同负载下的性能表现。
- 错误率(Error Rate):表示请求中出现错误的比例。可以关注错误请求数量、错误百分比等指标,较低的错误率表示系统的稳定性较好。
- CPU 使用率(CPU Usage):表示系统的 CPU 利用率。通过监控 CPU 使用率,可以了解系统在压力下的资源消耗情况。
- 内存使用量(Memory Usage):表示系统的内存占用情况。通过监控内存使用量,可以了解系统在压力下的资源消耗情况。
- 网络吞吐量(Network Throughput):表示系统在单位时间内传输的数据量。通过监控网络吞吐量,可以了解系统在压力下的网络性能。
这些指标可以帮助评估系统的性能和稳定性,并发现潜在的性能问题。在进行压测时,可以使用JMeter的聚合报告、图表和监控工具来收集和分析这些指标。
如果您需要更具体的信息,请提供更多上下文或使用web_search函数进行搜索。
汇总报告

腾讯云智
一面
1 | |
get 和 mget 流程 、优点
get指令用于获取单个键的值,而mget指令用于同时获取多个键的值。它们的底层执行流程如下:
- 对于get指令,Redis会根据给定的键,从内存中查找对应的值。如果找到了该键对应的值,则返回该值;如果没有找到,则返回空值。
- 对于mget指令,Redis会同时查找多个键的值。它会遍历给定的键列表,逐个查找每个键对应的值。如果找到了某个键对应的值,则将该值添加到结果列表中;如果没有找到,则将空值添加到结果列表中。最后,Redis会返回结果列表,其中包含了每个键对应的值。
这两个指令的好处如下:
- get指令的好处是可以快速获取单个键的值。它适用于需要获取单个键的场景,可以减少网络传输的开销。
- mget指令的好处是可以一次性获取多个键的值。它适用于需要同时获取多个键的场景,可以减少网络传输的次数,提高效率。
总的来说,get指令适用于获取单个键的值,而mget指令适用于同时获取多个键的值。根据具体的需求,选择合适的指令可以提高操作的效率。
redis 的 16个数据库
Redis中的多个数据库(database)功能可以在以下场景下使用:
- 数据隔离:如果您的应用程序需要在不同的数据集之间进行隔离,可以使用多个数据库。每个数据库可以存储不同的数据集,这样可以更好地组织和管理数据。
- 多租户应用:如果您的应用程序是一个多租户(multi-tenant)应用,即多个用户共享同一个应用实例,但需要隔离彼此的数据,可以使用多个数据库。每个租户可以拥有自己的数据库,这样可以确保数据的隔离性和安全性。
- 数据分片:如果您的数据量非常大,单个数据库无法满足性能需求,可以使用多个数据库进行数据分片。将数据按照某种规则(如哈希、范围等)分散存储在不同的数据库中,可以提高读写性能和扩展性。
需要注意的是,多个数据库之间是相互独立的,它们之间没有直接的数据共享或交互。每个数据库都有自己的键空间,操作一个数据库不会影响其他数据库的数据。
MySQL 底层join
MySQL使用了多种算法来执行JOIN操作,具体使用哪种算法取决于查询的条件、表的大小和索引的使用情况。以下是MySQL中常见的JOIN算法:
- Nested Loop Join(嵌套循环连接):这是最基本的JOIN算法,它使用两个嵌套的循环来处理JOIN操作。对于每个外部表的行,内部表都会被扫描一次,以找到匹配的行。这种算法适用于小表或者没有合适的索引的情况。
- Block Nested Loop Join(块嵌套循环连接):这是对嵌套循环连接的改进,它将内部表分成多个块,每次处理一个块。这样可以减少内部表的扫描次数,提高性能。
- Hash Join(哈希连接):这种算法适用于连接的列没有索引的情况。它使用哈希表来构建连接关系,首先将内部表的连接列的值进行哈希处理,然后将哈希值与外部表的连接列进行比较,找到匹配的行。
- Sort Merge Join(排序合并连接):这种算法适用于连接的列有索引的情况。它首先对两个表的连接列进行排序,然后按照排序后的顺序进行合并。这种算法需要额外的排序操作,但可以避免重复的扫描。
13、mysql 的 sql 语句优化、思路
微云创想
一面
分布式锁
1、先介绍使用的数据结构
2、介绍使用技巧
3、介绍达成的效果
4、介绍作用的过程
5、对比多种分布式锁的实现方式
1 | |
锐锢商城 - 9/11 实习offer
- 练手,拒了
二面
1、SPI机制 – JDBC、
2、PostProposser 有哪些,作用;他的优缺点是什么
1、一句话概括实习经历,你做了是什么
2、做的最有收获的一件事是什么(思考为什么要选择这个方案,怎么做) – 为什么选择这个方案、这个方案有什么优缺点
4、网络连接、操作系统IO优化
5、
一面
问题
1、自我介绍,上来就嘴瓢,个人信息都没说(学校、掌握技能点、项目、实习经历 – 这些都没说,因为被打断了~)
1、实习项目介绍(没介绍好,他都没听懂) – 从新梳理逻辑(感觉正常面试都g了50%,我是真的菜啊)
1、实习中负责什么,实习项目的难点是什么
2、第二个项目介绍:
2、消息队列的作用
3、mysql 如何解决慢查询:为什么会导致慢查询、如何解决(导致:回表、IO、索引;慢查询日志、explain执行计划-想起来了不会~)
3、mysql 和 redis 如何配合使用(sql复杂查询、redis数据结构、快速响应)
4、redis 可能遇到的业务问题(大key、业务问题:缓存雪崩、击穿、穿透)
5、redis 为什么使用单线程(基于内存、计算密集型、减少多线程协调问题、)
4、消息队列的使用场景、功能(异步解耦、削峰填谷、可靠传输)
5、rabbitMQ 的使用,有哪些组件,作用是什么(product、broker、exchange、queue、channel、consumer)
5、对自己的点评和总结,实习能够带来哪些提升(开发流程、理论-》实践、增长见识)
6、反问
7、个人问题总结
(30min)
总结:
1、总分总结构,先回答出要点,再进行发散,不要一个点讲多了,其他点还没讲
2、这次勉强能够保持清醒,但是问题比较多,rabbitMQ 的使用问题,不够清晰,对项目不太熟悉
3、简单自我点评:这次保持了很长时间的“头脑清醒”,才知道自己有多菜。(指:边面试,边想起来这里不会,那里不会[表情][表情] 虽然嘴上没瓢,但是心里瓢了)
要是换以前,面完感觉自己又行了~
个人问题:
1、消息队列结构,作用
2、mysql explain
3、实习介绍 很垃圾啊
4、总分总模式,很垃圾啊
5、
总结问题 – redis、msql:
Redis的布隆过滤器操作命令:
Redis并没有提供原生的布隆过滤器数据结构,但可以通过使用Redis的位图(BitMap)数据结构来实现布隆过滤器的功能。以下是一些常用的布隆过滤器操作命令:
SETBIT key offset value:将指定偏移量上的位设置为指定的值(0或1)。
GETBIT key offset:获取指定偏移量上的位的值。
BITCOUNT key [start end]:计算指定范围内的位为1的数量。
BITOP operation destkey key [key …]:对多个位图进行逻辑运算,并将结果保存到目标位图中。
MySQL的bin日志格式,row和statement,区别,优缺点:
MySQL的bin日志是用于记录数据库的更改操作,以便在主从复制、数据恢复等场景中使用。MySQL提供了两种不同的bin日志格式:row格式和statement格式。
- Row格式:以行为单位记录每个更改操作的具体内容。它将每个更改操作转换为对受影响行的详细描述,并将这些描述记录到bin日志中。优点是精确记录了每个更改操作的具体细节,可以保证在主从复制中数据的一致性。缺点是bin日志会变得较大,因为需要记录每个更改操作的详细信息。
- Statement格式:以SQL语句为单位记录每个更改操作的原始SQL语句。它将每个更改操作的SQL语句记录到bin日志中。优点是bin日志较小,因为只需要记录SQL语句。缺点是在某些情况下,由于数据库的状态不同,执行相同的SQL语句可能会导致不同的结果,从而可能导致主从复制中的数据不一致。
选择使用哪种bin日志格式取决于具体的需求和场景。一般来说,row格式更加安全可靠,但会占用更多的磁盘空间,而statement格式则更加轻量,但在某些情况下可能会导致数据不一致。
Redis的AOF和RDB持久化的优缺点:
Redis提供了两种持久化方式:AOF(Append-Only File)和RDB(Redis Database)。
AOF持久化的优点:
- 可靠性:AOF持久化记录了每个写操作的日志,可以保证数据的可靠性。
恢复速度:在数据恢复时,AOF持久化可以通过重新执行日志中的写操作来恢复数据,恢复速度相对较快。
可读性:AOF持久化是以文本格式保存的,易于阅读和理解。
AOF持久化的缺点: - 文件大小:AOF文件通常比RDB文件大,占用更多的磁盘空间。
恢复时间:在数据恢复时,AOF持久化需要重新执行所有写操作,恢复时间相对较长。
RDB持久化的优点: - 文件大小:RDB文件通常比AOF文件小,占用较少的磁盘空间。
恢复时间:在数据恢复时,RDB持久化只需要加载一次RDB文件即可完成恢复,恢复时间相对较短。
RDB持久化的缺点: - 可靠性:RDB持久化是通过定期将内存中的数据快照保存到磁盘上,如果在持久化之间发生故障,可能会丢失一部分数据。
选择使用AOF还是RDB持久化取决于对数据可靠性和恢复速度的需求。一般来说,如果对数据的可靠性要求较高,可以选择AOF持久化;如果对恢复速度和磁盘空间的利用率要求较高,可以选择RDB持久化。
万物心选
1 | |
在Java中,static关键字可以修饰以下内容:
静态变量(Static Variables):使用static修饰的变量属于类级别,而不是实例级别。静态变量在类加载时被初始化,所有实例共享同一个静态变量的值。
静态方法(Static Methods):使用static修饰的方法属于类级别,而不是实例级别。静态方法可以直接通过类名调用,无需创建类的实例。
静态代码块(Static Initialization Blocks):使用static修饰的代码块在类加载时执行,用于初始化静态变量或执行其他静态操作。
静态内部类(Static Inner Classes):使用static修饰的内部类与外部类之间没有直接的关联,可以直接通过外部类名访问静态内部类,而不需要先创建外部类的实例。
静态导入(Static Imports):使用static修饰的导入语句,可以直接导入类的静态成员,使其可以直接使用,而无需使用类名限定。
需要注意的是,静态成员属于类级别,不依赖于类的实例化。可以通过类名直接访问静态成员,而不需要创建类的实例。静态成员在内存中只有一份拷贝,被所有实例共享。
1 | |
• 项目是怎么用 DDD 一步一步搭建起来的?
• 领域的边界为什么要这样划分呢?根据是什么?
• 活动库存怎么保证的不超减?
• 库存自增完后再判断的话,怎么保证它的原子性呢?
• 如果用分布式锁,具体怎么做?
• 分布式锁的 value 设置成什么?
• 需要设置超时时间吗?设置成多少?
• 命令怎么写?你直接用 SETNX + EXPIRE 能保证原子性吗?
• 怎么支持可重入呢?
• 用 Hash 还能保证原子性吗?
• 在 Kafka 中,生产者发送流程和消费者的消费流程是怎样的?
• 分库分表用的什么组件?
• 用的哪个字段分的?为什么?
• xxl-job 用来干什么?
• 那你扫描表的时候,是把分库分表的表依次扫描一遍吗?
• ThreadLocal 用来干什么?项目中怎么做的?
• ThreadLocalMap 保存在哪儿的?Map 中的 key-value 分别是什么?
• 为什么 key 要设置成弱引用?
• 外部强引用断开时,key 被回收后,value 还有,这不是会造成内存泄漏吗?这时它内部是怎么处理的呢?
• 什么情况下会清理这些槽位?只有手动清理吗?
• 那为什么 key 不设置成强引用呢?强引用不就不会被垃圾回收了吗?
• 线程池提交任务有什么方式?区别是什么?
• submit 提交一个任务后,主线程会干什么呢?会挂起?
• 如果我要实现多个线程执行完毕后,主线程才继续执行,怎么做?
• CountDownLatch 具体调用那个方法来实现?
• CountDownLatch 怎么实现的?
• AQS 的数据结构是怎样的?
• 双向队列里面具体有哪些数据呢?
• Spring 初始化 Bean 的过程是怎样的?
• 声明 Bean 有哪些注解?
• 依赖注入的注解呢?它们有什么区别?
• 怎么限制 Bean 的扫描范围?
• 初始化 Bean 的时候出现了依赖会怎么样?循环依赖了呢?
• MySQL 索引的类型有哪些?
• 索引的数据结构是怎样的?
• 聚簇索引和非聚簇索引的叶子结点存储的都是数据吗?
• 查询时具体是怎么在这棵树上进行扫描的?
• 如果是非聚簇索引呢?
• 为什么用 B+ 树而不是 B 树或者二叉树?
• 手撕:三个线程分别循环打印 111…、222…、333…,实现打印效果为 123123123…
• 反问
1 | |
1 | |
上述代码实现了一个简单的线程池,包含以下几个关键部分:
ThreadPool类:线程池的主要类,负责创建线程池、提交任务和管理线程。WorkerThread类:工作线程类,继承自Thread,负责从任务队列中取出任务并执行。taskQueue:任务队列,使用BlockingQueue实现,用于存放待执行的任务。execute方法:用于提交任务到线程池,将任务放入任务队列中。
在使用线程池时,可以通过创建ThreadPool对象,并调用execute方法提交任务。线程池会自动从任务队列中取出任务,并由工作线程执行。
需要注意的是,上述代码是一个简单的线程池实现,仅用于演示基本原理。在实际应用中,还需要考虑线程池的大小、任务拒绝策略、线程池的关闭等更多的细节。
希望这个示例能够帮助您理解线程池的基本实现。如果您有更多的问题,请随时提问。
1、MySQL
索引
索引优化
什么时候适用索引?
- 字段有唯一性限制的,比如商品编码;
- 经常用于
WHERE查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。 - 经常用于
GROUP BY和ORDER BY的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
#什么时候不需要创建索引?
WHERE条件,GROUP BY,ORDER BY里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,如果数据库表中,男女的记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引,因为 MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
B+ 树插入流程
B+叶子节点数目
假设
- 非叶子节点内指向其他页的数量为 x
- 叶子节点内能容纳的数据行数为 y
- B+ 数的层数为 z
如下图中所示,Total =x^(z-1) *y 也就是说总数会等于 x 的 z-1 次方 与 Y 的乘积。
innodb 中,一个节点 为一个页,一个页16kb,除去页头等信息大概为 15kb
非叶子节点存储 主键索引(假设为bigint),页号(假设4字节),则每个非叶子节点的索引数目为 15kb / 12b ~= 1280 (x)
根据层高– 2:1280^1 == 1280, 层高为3 : 1280 ^ 2 == 160w
叶子节点为 15kb / 行大小 ==》 假设为 1kb : 15kb / 1kb (y)
叶子节点为 160w
存储行为 160w * y ~= 2k
null 值的影响
在MySQL中,NULL值对索引的影响主要体现在以下几个方面:
- 索引的唯一性:对于唯一索引,NULL值在索引中是允许的,而且可以有多个NULL值。这意味着在唯一索引中,多个NULL值不会被视为重复值。
- 索引的查询:当使用索引进行查询时,NULL值可能会对查询结果产生影响。在使用等于(=)操作符进行查询时,如果索引列包含NULL值,那么查询结果将不包括这些NULL值。因此,如果需要包括NULL值在内,可以使用IS NULL或IS NOT NULL操作符进行查询。
- 索引的大小和性能:NULL值在索引中会占用一定的存储空间。对于B+树索引,NULL值会占用额外的空间,因为每个索引键都需要存储NULL标记。对于哈希索引,NULL值不会占用额外的空间。此外,当索引列包含大量NULL值时,可能会导致索引的碎片化,从而影响查询性能。
综上所述,NULL值对索引的影响主要体现在唯一性、查询结果和索引的大小与性能方面。在设计数据库表和索引时,需要根据具体的业务需求和查询场景来考虑是否允许NULL值,并合理选择索引类型和查询方式。
发生索引失效的情况:
- 当我们使用左或者左右模糊匹配的时候,也就是
like %xx或者like %xx%这两种方式都会造成索引失效; - 当我们在查询条件中对索引列做了计算、函数、类型转换操作,这些情况下都会造成索引失效;
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。
执行计划,参数有:
- possible_keys 字段表示可能用到的索引;
- key 字段表示实际用的索引,如果这一项为 NULL,说明没有使用索引;
- key_len 表示索引的长度;
- rows 表示扫描的数据行数。
- type 表示数据扫描类型,我们需要重点看这个。
type 字段就是描述了找到所需数据时使用的扫描方式是什么,常见扫描类型的执行效率从低到高的顺序为:
- All(全表扫描);
- index(全索引扫描);
- range(索引范围扫描);
- ref(非唯一索引扫描);
- eq_ref(唯一索引扫描);
- const(结果只有一条的主键或唯一索引扫描)。
需要说明的是 const 类型和 eq_ref 都使用了主键或唯一索引,不过这两个类型有所区别,const 是与常量进行比较,查询效率会更快,而 eq_ref 通常用于多表联查中。
存储引擎
高可用
主从复制
需要注意的是,MySQL的主从同步还涉及到一些其他的配置和参数设置,如复制过滤规则、复制延迟、主从切换等。具体的配置和流程细节可以参考MySQL的官方文档或相关资料,以及根据具体的需求进行调整和优化。
MySQL的主从同步流程如下:
- 配置主数据库(Master):
- 在主数据库上开启二进制日志功能,将数据变更操作记录到二进制日志(binlog)中。
- 配置一个唯一的服务器ID,用于在主从之间进行标识。
- 配置从数据库(Slave):
- 在从数据库上设置主数据库的连接信息,包括主数据库的IP地址、端口号、用户名和密码等。
- 配置从数据库的服务器ID,确保与主数据库的服务器ID不同。
- 启动主从同步:
- 在从数据库上启动复制进程,连接到主数据库,并请求从主数据库获取二进制日志。
- 主数据库将二进制日志的内容发送给从数据库,从数据库将其保存到自己的中继日志(relay log)中。
- 应用数据变更:
- 从数据库读取中继日志中的二进制日志内容,并将其应用到自己的数据库中,执行相应的数据变更操作。
- 从数据库会记录已经应用的二进制日志位置,以便在断开连接后能够继续同步。
- 持续同步:
- 主数据库持续记录数据变更到二进制日志中,从数据库定期连接主数据库,获取新的二进制日志内容,并应用到自己的数据库中。
在MySQL的主从同步中,涉及到了中继日志(relay log)。中继日志是从数据库中用于保存主数据库的二进制日志内容的日志文件。从数据库在读取主数据库的二进制日志后,将这些变更操作保存到中继日志中,并将其应用到自己的数据库中。中继日志的作用是充当缓冲,使得从数据库可以异步地读取和应用主数据库的二进制日志,提高同步的效率和性能。
需要注意的是,中继日志只在从数据库中存在,主数据库并不使用中继日志。主数据库只负责将二进制日志发送给从数据库,而从数据库则负责将二进制日志保存到中继日志,并应用到自己的数据库中。
以上是MySQL主从同步的基本流程,通过配置和启动复制进程,从数据库可以实时地同步主数据库的数据变更,实现数据的复制和备份。具体的配置和流程细节可以参考MySQL的官方文档或相关资料。
中继日志 - relay log
中继日志是连接mastert(主服务器)和slave(从服务器)的信息,它是复制的核心,I/O线程将来自master的binlog存储到中继日志中,中继日志充当缓冲,这样master不必等待slave执行完成就可以发送下一个binlog。中继日志的作用是用于主从服务器架构中,从服务器通过读取中继日志的内容,来同步主服务器上的操作。中继日志文件的格式与二进制日志文件相同,并且可以使用mysqlbinlog进行读取。
SQL 调优
limit 语句如何优化
limit分页优化_Reiter_Wong的博客-CSDN博客
2.2 子查询的分页方式
随着数据量的增加,页数会越来越多,查看后几页的 SQL 就可能类似:
1 | |
一言以蔽之,就是越往后分页,LIMIT 语句的偏移量就会越大,速度也会明显变慢。
此时,我们可以通过子查询的方式来提高分页效率,大致如下:
1 | |
2.3 JOIN 分页方式
1 | |
Explain
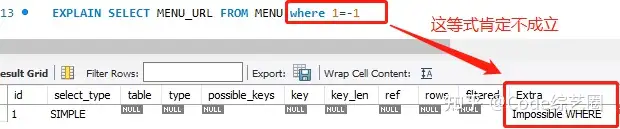
通过上面的逻辑结构,当一个SQL发送到MySQL执行时,需要经过内部优化器进行优化,而使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理SQL的,即SQL的执行计划;根据explain提供的执行计划信息分析SQL语句,然后进行相关优化操作。接下来的示例演示用到五张表:**USER(用户表)、MENU(菜单表)、ROLE(角色表)、USER_ROLE(用户角色关系表)、ROLE_MENU(角色菜单关系表)、ADDR(用户地址表,这里认为和用户一一对应)、FRIEND(朋友表,一对多关系)**,它们的关系这里就不详细说了吧,小伙伴肯定都明白,这是管控菜单权限的五张基础表和两个基础信息表;
演示用的版本是MySql5.5,各版本之间会有不同,所以小伙伴用的版本测试结果不一样的时候,千万别骂我渣哦;其实重要的是查看的思路,整体是大同小异。(求原谅……)
通过explain会输出如下信息,很多小伙伴只关注红框标注部分(即索引),但其实是不够的,接下来就一个一个好好说说。

- id
这个id和咱们平时表结构设计的主键ID不太一样,这里的id代表了每一条SQL语句执行计划中表加载的顺序,分为三种情况:
id相同的时候:这时是从上到下依次执行;
1 | |
执行如下语句,得如下结果:

如上图所示,id一样,从上到下依次执行,所对应表加载顺序为**t->tr->r(这里的表是别名)**;
id不同的时候:当id不同的时,id越大的越先执行;
1 | |
子查询会导致id递增,结果如下:

如上图所示,id递增啦,所对应表的加载顺序为**ur->rm->t(这里的表是别名)**;
id相同和不同同时存在时:id相同的认为是同一组,还是从上往下加载;不一样的情况还是越大越优先执行
1 | |
执行结果如下:

如上图所示,id有一样的,也有不同的,则对应表的加载顺序为USER_ROLE->derived2 (衍生表)->rm->m;衍生表表名后面的2代表的是id,所以可以通过衍生表表名后面的id知道是哪一步产生的,即derived2衍生表是id为2的这一步产生的。
- select_type
select_type 是表示每一步的查询类型,方便分析人员很直接的看到当前步骤执行的是什么查询,有多种类型,见下图:
1> SIMPLE:简单的SELECT查询,不包含子查询或UNION的那种;
1 | |
输出结果如下:

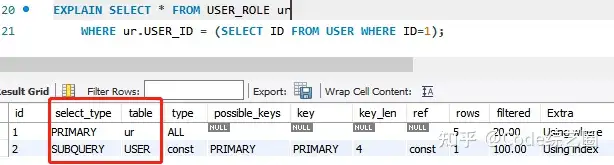
2> PRIMARY:查询语句中包含其他子查询或UNION操作,那最外层的SELECT就被标记为该类型;
如上图所示,查询中包含子查询,最外层查询被标记为PRIMARY;
3> SUBQUERY:在SELECT或WHERE中包含的子查询会被标记为该类型;
见PRIMARY图,当存在子查询时,会将子查询标记为SUBQUERY
4> MATERIALIZED:被物化的子查询,即针对对应的子查询将其物化为一个临时表;
1 | |
测试物化用的是MySQL8.0,和5.*版本有所不同,输出结果如下:

如上图所示,将子查询物化为一个临时表subquery2,这个功能是可以通过设置优化器对应的开关的。
5> DERIVED:在FROM之后的子查询会被标记为该类型,同样会把结果放在一个临时表中;
1 | |
输出结果:

如图所示,FROM后面跟的子查询就被标记为DERIVED,对应步骤产生的衍生表为derived2。高版本好像对其进行了优化,8.0版本这种形式认为是简单查询。
6> UNION:UNION操作中,查询中处于内层的SELECT;
1 | |
输出结果如下:

如上图所示,将第二个SELECT标注为UNION ,即对应加载的表为T2。
7> UNIOIN RESULT:UNION操作的结果,对应的id为空,代表的是一个结果集;
见UNIOIN图,UNIOIN RESULT代表的是UNION之后的结果,对应id为空。
- table
table代表对应步骤加载的是哪张表,中间会出现一些临时表,比如subquery2、derived2等这种,最后的数字代表产生该表对应步骤的id。
- type
代表访问类型,MySQL内部将其分为多类型,常用的类型从好到差的顺序展示如下:
system->const->eq_ef->ref->fulltext->ref_or_null->index_merge->unique_subquery->index_subquery->range->index->ALL;
而在实际开发场景中,比较常见的几种类型如下:const->eq_ref->ref->range->index->ALL(顺序从好到差),通常优化至少在range级别或以上,比如ref算是比较不错的啦;
上面说到的从好到差指的是查询性能。
1>const:表示通过索引一次就找到数据,用于比较primary key或者unique索引,很快就能找到对应的数据;
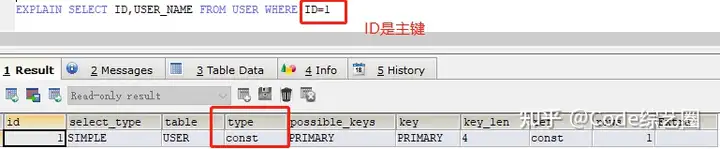
2>eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配,常用于主键或唯一索引扫描;
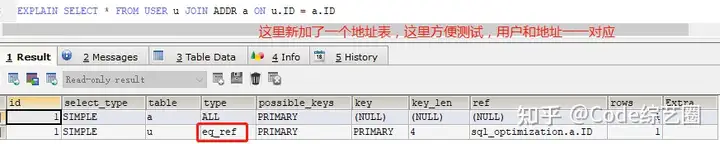
3>ref:非唯一索引扫描,返回匹配的所有行,如建立一个朋友维护表,维护用户对应的朋友,而在用户ID建立非唯一索引;

4>range:使用一个索引检索指定范围的行,一般在where语句中会出现between、<、>、in等范围查询;

5>index:全索引扫描,只遍历索引树;

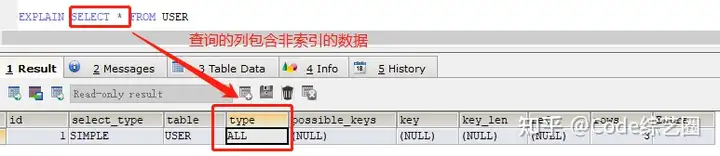
6>ALL:全表扫描,找到匹配行。与index比较,ALL需要扫描磁盘数据,index值需要遍历索引树。
- possible_keys
显示可能被用到的索引,但在实际查询中不一定能用到; 查询涉及到字段,如果存在索引,会被列出,但如果使用的是覆盖索引,只会在key中列出;

- key
实际使用到的索引,如果为NULL代表没有使用到索引;这也是平时小伙伴判断是否用上索引的关键。
- key_len
key_len表示索引使用的字节数,根据这个值可以判断索引的使用情况,特别是在组合索引的时候,判断该索引有多少部分被使用到,非常重要;key_len是根据表定义计算而得。这里测试在USER表中对USER_NAME创建一个非唯一索引,如下:

这里key_len是这么计算的,前提是指定的字符串集是utf8,可变长 且允许为空,计算过程如下:
128(设置的可变长度)*3(utf8占3字节)+1(允许为空标识占一个字节)+2(长度信息占两个字节)=387;
key_len针对不同类型字段的计算规则不一样,这里用USER(用户表)简单计算为例:
| 字段 | Key_len | 说明 | | ————————————- | ————- | ———————————————————— | | ID(int,不为空) | 4 | int为4个字节,不为空 | | USER_NAME(varchar(128),utf8,可为空) | 128*3+1+2=387 | 可变为128,utf8每个占3字节,1个字节标识可控,两个字节标识长度 |
不同类型占用的字节不一样,字符集不一样占用的字节也不一样,允许为空的字段需要1个字节做标识,可变长度的字段需要2个字节标识长度。小伙伴照着这个思路就可以计算其他类型啦。
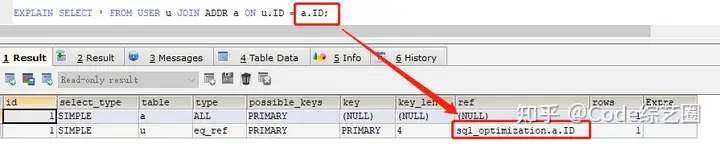
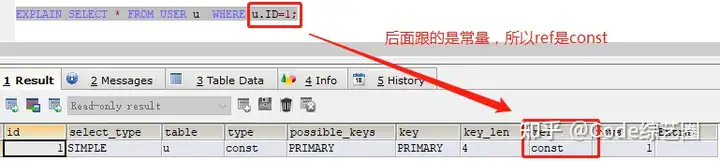
- ref
显示索引的哪些列被引用了,通常是对应字段或const;
- rows
根据表统计信息和索引的使用情况,大概估算出找到所需记录数据所扫描的数据行数;不是所需数据的行数。
- Extra
这个字段里包含一些其他信息,但也是优化SQL的重要参考,通常会出现以下几种信息:
Using index:表示查询语句中用到了覆盖索引,不访问表的数据行,查询效率比较好。
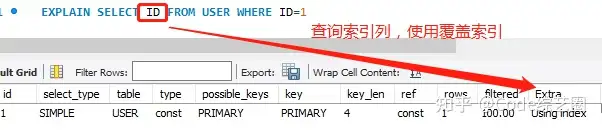
如果用SELECT *进行查询,就不会有Using index,关于索引的介绍下篇好好说说。
Using filesort:代表MySQL会使用一个外部索引对数据进行排序(文件排序),而不是使用表内索引。这种情况在SQL查询需要避免,最好不要在Extra中出现此类型:
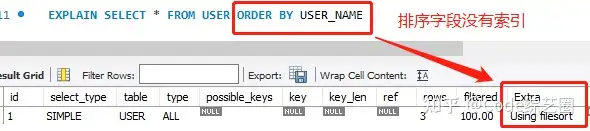
通常会是使用ORDER BY语句导致,上图中使用无索引的字段进行排序会出现,同样如果使用有索引的字段,但用法不对也会出现,比如使用组合索引不规范时。
Using temporary:产生临时表保存中间结果,这种SQL是不允许的,遇见数据量大的场景,基本就跑不动啦;

这种类型常常因为ORDER BY 和 GROUP BY导致,所以在进行数据排序和分组查询时,要注意索引的合理利用。
Using where:使用where过滤数据,小伙伴试一把。
Using join buffer:表示使用到了表连接缓存; 当表数据量大,可能导致buffer过大,查询效率比较低,这种情况注意在表连接字段上正确使用索引。
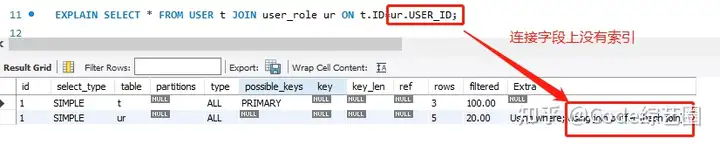
如果表连接查询慢时,在连接字段上加个索引试试,药到病除;
impossible where:代表where后面的条件永远为false,匹配不到数据;
用到的表及数据从Gitgub中获取:https://github.com/zyq025/SQL_Optimize
总结
看完这篇文章之后,小伙伴再去找些SQL看看对应的执行计划,是不是看懂啦,对于优化意义非凡;但是这还不够,接下来还要聊聊索引,聊聊索引失效情况,聊聊除了EXPALIN其他优化方式等,最后日常的开发优化应该都能搞定,远离低效SQL,是不是又有更多时间学习啦。
一个被程序搞丑的帅小伙,关注”Code综艺圈”,跟我一起学~~~
日志
innnodb 独有
InnoDB存储引擎在MySQL中引入了一些特有的日志类型,这些日志对于确保数据的一致性和持久性非常重要。以下是InnoDB特有的日志类型:
- redo log(重做日志):redo log是InnoDB存储引擎的核心日志类型。它记录了对数据页的修改操作,包括插入、更新和删除操作。redo log的目的是在系统崩溃或故障恢复时,通过重放日志中的操作来恢复数据的一致性。
- undo log(撤销日志):undo log是InnoDB存储引擎用于实现事务的回滚和MVCC(多版本并发控制)的关键日志类型。它记录了事务执行过程中对数据的旧值的修改操作,以便在事务回滚或读取旧版本数据时进行恢复。
- doublewrite buffer(双写缓冲):doublewrite buffer是InnoDB存储引擎用于保证数据页写入的原子性和一致性的缓冲区。在将数据页写入磁盘之前,InnoDB会先将数据页的副本写入doublewrite buffer,然后再将数据页写入磁盘。这样可以防止在写入过程中发生部分写入导致的数据损坏。
- change buffer(变更缓冲):change buffer是InnoDB存储引擎用于优化辅助索引的更新操作的缓冲区。当执行插入、更新或删除操作时,InnoDB会将对辅助索引的修改操作记录到change buffer中,而不是立即更新辅助索引。这样可以减少磁盘IO操作,提高写入性能。
这些日志类型是InnoDB存储引擎的关键组成部分,它们共同工作以确保数据的一致性、持久性和并发控制。
如果您对InnoDB存储引擎或其他相关主题有更多问题,请提供更多上下文或具体问题,我将尽力回答。
持久化 - 刷盘
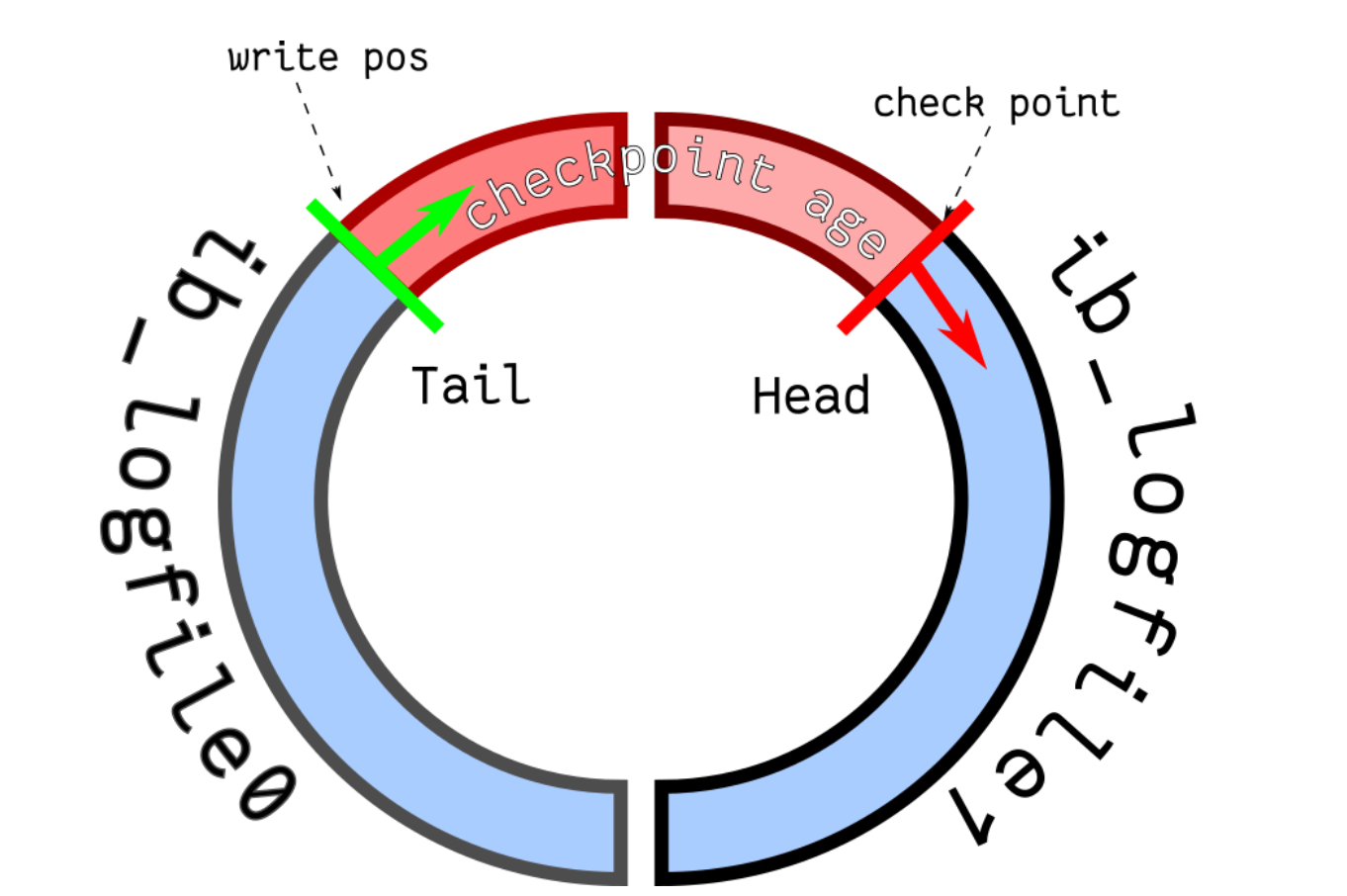
buffer pool 脏页刷盘:
下面几种情况会触发脏页的刷新:
- 当 redo log 日志满了的情况下,会主动触发脏页刷新到磁盘; – write pos – checkpoint
- Buffer Pool 空间不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘; LRU淘汰
- MySQL 认为空闲时,后台线程会定期将适量的脏页刷入到磁盘; 定时
- MySQL 正常关闭之前,会把所有的脏页刷入到磁盘; – 关闭
SQL 执行抖动
在我们开启了慢 SQL 监控后,如果你发现「偶尔」会出现一些用时稍长的 SQL,这可能是因为脏页在刷新到磁盘时可能会给数据库带来性能开销,导致数据库操作抖动。
如果间断出现这种现象,就需要调大 Buffer Pool 空间或 redo log 日志的大小。
redo log 是为了防止 Buffer Pool 中的脏页丢失而设计
redo log 的作用
write posistion
checkpoint
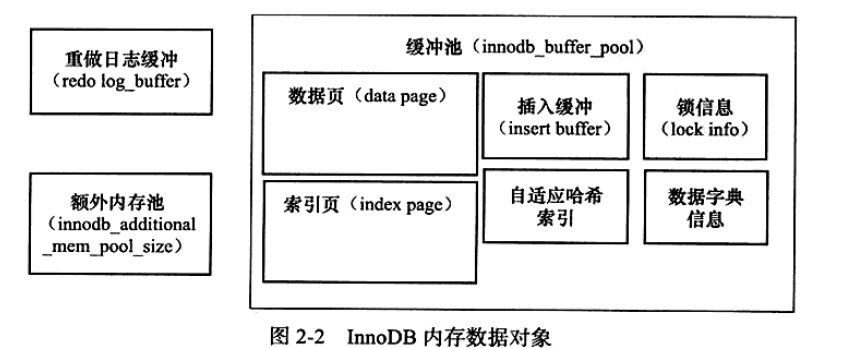
buffer pool 存什么
插入缓冲 == 索引的插入
MySQL的插入缓冲(Insert Buffer)是一种用于提高插入性能的机制。当执行INSERT语句时,MySQL会将新插入的数据先存储在内存中的插入缓冲区,然后再定期将缓冲区中的数据批量写入到磁盘。
插入缓冲的工作原理如下:
- 内存中的插入缓冲区:MySQL会为每个索引维护一个插入缓冲区。当执行INSERT语句时,新插入的数据会先被写入到对应索引的插入缓冲区中,而不是直接写入到磁盘。
- 合并插入缓冲:MySQL会定期触发合并插入缓冲的操作。在合并过程中,MySQL会将插入缓冲区中的数据按照索引顺序进行排序,并将排序后的数据批量写入到磁盘上的索引页中。
插入缓冲的优势在于减少了磁盘的随机写操作,提高了插入性能。通过将多个插入操作合并为批量写入,可以减少磁盘IO的次数,提高数据写入的效率。
需要注意的是,插入缓冲只适用于非聚集索引(Secondary Index),对于聚集索引(Primary Index)的插入操作,数据仍然需要直接写入到磁盘。
2、Redis
常见面试题
单线程模型
初始化
图中的蓝色部分是一个事件循环,是由主线程负责的,可以看到网络 I/O 和命令处理都是单线程。 Redis 初始化的时候,会做下面这几件事情:
- 首先,调用 epoll_create() 创建一个 epoll 对象和调用 socket() 创建一个服务端 socket
- 然后,调用 bind() 绑定端口和调用 listen() 监听该 socket;
- 然后,将调用 epoll_ctl() 将 listen socket 加入到 epoll,同时注册「连接事件」处理函数。
流程:
初始化完后,主线程就进入到一个事件循环函数,主要会做以下事情:
- 首先,先调用处理发送队列函数,看是发送队列里是否有任务,如果有发送任务,则通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。
- 接着,调用 epoll_wait 函数等待事件的到来:
- 如果是连接事件到来,则会调用连接事件处理函数,该函数会做这些事情:调用 accpet 获取已连接的 socket -> 调用 epoll_ctl 将已连接的 socket 加入到 epoll -> 注册「读事件」处理函数;
- 如果是读事件到来,则会调用读事件处理函数,该函数会做这些事情:调用 read 获取客户端发送的数据 -> 解析命令 -> 处理命令 -> 将客户端对象添加到发送队列 -> 将执行结果写到发送缓存区等待发送;
- 如果是写事件到来,则会调用写事件处理函数,该函数会做这些事情:通过 write 函数将客户端发送缓存区里的数据发送出去,如果这一轮数据没有发送完,就会继续注册写事件处理函数,等待 epoll_wait 发现可写后再处理 。

后台线程
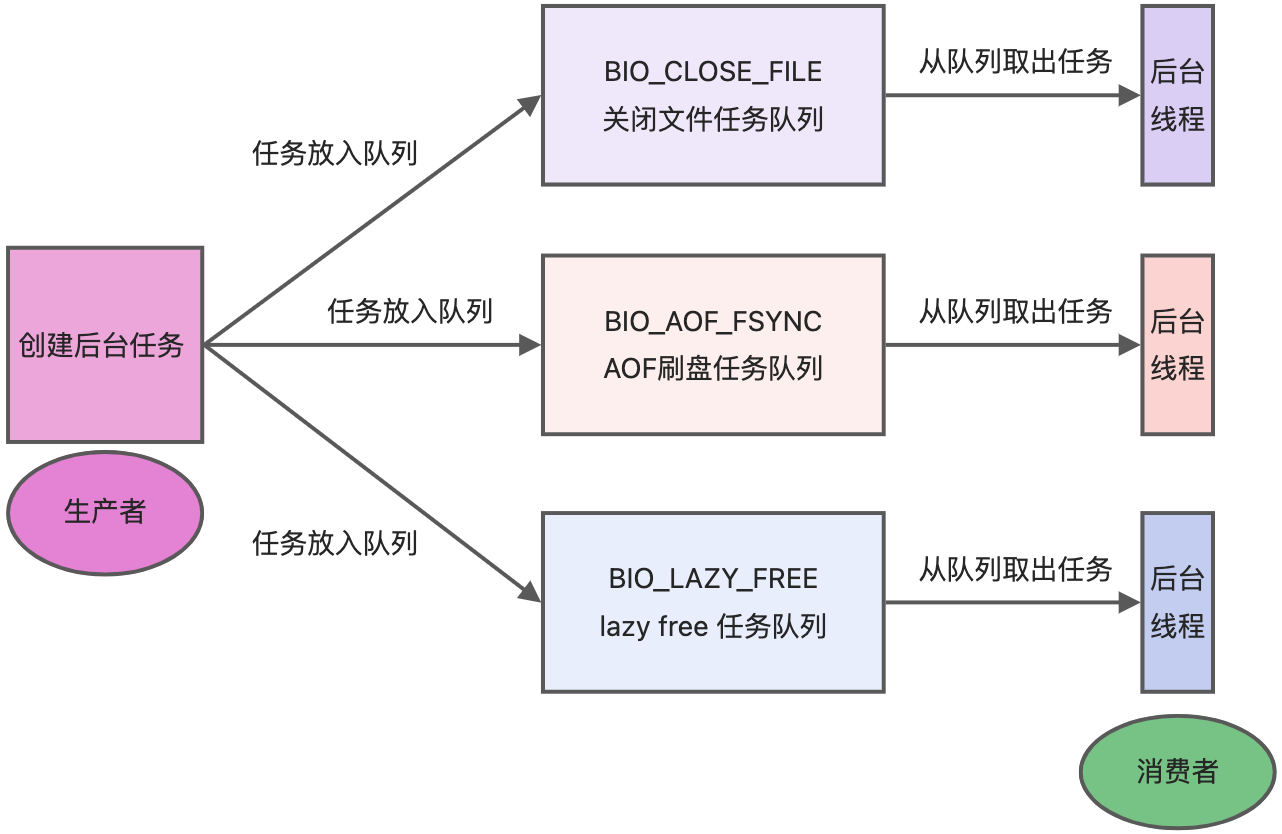
线程总览
因此, Redis 6.0 版本之后,Redis 在启动的时候,默认情况下会额外创建 6 个线程(这里的线程数不包括主线程):
- Redis-server : Redis的主线程,主要负责执行命令;
- bio_close_file、bio_aof_fsync、bio_lazy_free:三个后台线程,分别异步处理关闭文件任务、AOF刷盘任务、释放内存任务;
- io_thd_1、io_thd_2、io_thd_3:三个 I/O 线程,io-threads 默认是 4 ,所以会启动 3(4-1)个 I/O 多线程,用来分担 Redis 网络 I/O 的压力
Redis 6.0 版本支持的 I/O 多线程特性,默认情况下 I/O 多线程只针对发送响应数据(write client socket),并不会以多线程的方式处理读请求(read client socket)。要想开启多线程处理客户端读请求,就需要把 Redis.conf 配置文件中的 io-threads-do-reads 配置项设为 yes。
如何删除大key
- 当我们要删除一个大 key 的时候,不要使用 del 命令删除,因为 del 是在主线程处理的,这样会导致 Redis 主线程卡顿,因此我们应该使用 unlink 命令来异步删除大key。
redis cluster 集群
redis cluster 如何直到 key在那个节点?
MOVED错误
在节点发现key所在的槽不是自己负责处理的时候,就会返回一个MOVED错误:
MOVED
让客户端重定向( redirected)到正确的 Redis 节点。
因为节点本身会存储一份其他节点负责的槽点,所以MOVED很容易实现。

ASK 错误 和 MOVED 错误
重新分片
Redis集群的重新分片操作可以将任意数量已经指派给某个节点(源节点)的槽改为指派给另一个节点(目标节点),并且相关槽所属的键值对也会从源节点被移动到目标节点。
重新分片操作可以在线(online)进行,在重新分片的过程中,集群不需要下线,并且源节点和目标节点都可以继续处理命令请求。
ASK错误
在进行重新分片期间,源节点向目标节点迁移一个槽的过程中,可能会出现这样一种情况:属于被迁移槽的一部分键值对保存在源节点里面,而另一部分键值对则保存在目标节点里面。
当客户端向源节点发送一个与数据库键有关的命令,并且命令要处理的数据库键恰好就属于正在被迁移的槽时,怎么处理?
源节点会先在自己的数据库里面查找指定的键,如果找到的话,就直接执行客户端发送的命令。
相反地,如果源节点没能在自己的数据库里面找到指定的键,那么这个键有可能已经被迁移到了目标节点,源节点将向客户端返回一个ASK错误,指引客户端转向正在导入槽的目标节点,并再次发送之前想要执行的命令。
MOVED和ASK的区别
MOVED错误代表槽的负责权已经从一个节点转移到了另一个节点:在客户端收到关于槽i的MOVED错误之后,客户端每次遇到关于槽i的命令请求时,都可以直接将命令请求发送至MOVED错误所指向的节点,因为该节点就是目前负责槽i的节点。
与此相反,ASK错误只是两个节点在迁移槽的过程中使用的一种临时措施:在客户端收到关于槽i的ASK错误之后,客户端只会在接下来的一次命令请求中将关于槽i的命令请求发送至ASK错误所指示的节点,但这种转向不会对客户端今后发送关于槽i的命令请求产生任何影响,客户端仍然会将关于槽i的命令请求发送至目前负责处理槽i的节点,除非ASK错误再次出现。
节点间的内部通信机制
集群中的各个节点通过发送和接收消息(message)来进行通信,采有gossip协议。
gossip协议原理:在一个有界网络中,每个节点都随机地与其他节点通信,经过一番杂乱无章的通信,最终所有节点的状态都会达成一致。每个节点可能知道所有其他节点,也可能仅知道几个邻居节点,只要这些节可以通过网络连通,最终他们的状态都是一致的,很像疫情传播。
优点在于元数据的更新比较分散,不是集中在一个地方,更新请求会陆陆续续,打到所有节点上去更新,有一定的延时,降低了压力;
缺点在于元数据更新有延时可能导致集群的一些操作会有一些滞后。
节点发送的消息主要有以下五种:
- MEET消息:当发送者接到客户端发送的CLUSTER MEET命令时,发送者会向接收者发送MEET消息,请求接收者加入到发送者当前所处的集群里面。
- PING消息:集群里的每个节点默认每隔一秒钟就会从已知节点列表中随机选出五个节点,然后对这五个节点中最长时间没有发送过PING消息的节点发送PING消息,以此来检测被选中的节点是否在线。除此之外,如果节点A最后一次收到节点B发送的PONG消息的时间,距离当前时间已经超过了节点A的cluster-node-timeout选项设置时长的一半,那么节点A也会向节点B发送PING消息,这可以防止节点A因为长时间没有随机选中节点B作为PING消息的发送对象而导致对节点B的信息更新滞后。
- PONG消息:当接收者收到发送者发来的MEET消息或者PING消息时,为了向发送者确认这条MEET消息或者PING消息已到达,接收者会向发送者返回一条PONG消息。另外,一个节点也可以通过向集群广播自己的PONG消息来让集群中的其他节点立即刷新关于这个节点的认识,例如当一次故障转移操作成功执行之后,新的主节点会向集群广播一条PONG消息,以此来让集群中的其他节点立即知道这个节点已经变成了主节点,并且接管了已下线节点负责的槽。
- FAIL消息:当一个主节点A判断另一个主节点B已经进入FAIL状态时,节点A会向集群广播一条关于节点B的FAIL消息,所有收到这条消息的节点都会立即将节点B标记为已下线。
- PUBLISH消息:当节点接收到一个PUBLISH命令时,节点会执行这个命令,并向集群广播一条PUBLISH消息,所有接收到这条PUBLISH消息的节点都会执行相同的PUBLISH命令。
redis cluster 优点
Redis Cluster是Redis的分布式解决方案,具有以下优点:
- 高可用性:Redis Cluster支持主从复制和自动故障转移,当主节点发生故障时,系统可以自动将从节点提升为主节点,保证服务的可用性。
- 数据分片:Redis Cluster将数据分散存储在多个节点上,每个节点负责管理部分数据。通过数据分片,可以将数据负载均衡到多个节点上,提高系统的处理能力和吞吐量。
- 扩展性:Redis Cluster支持动态扩展,可以随着业务需求增加节点数量,从而扩展系统的容量和性能。
- 自动化管理:Redis Cluster提供了自动化的管理功能,包括节点的发现、故障检测和故障转移等。这减少了管理员的工作量,并提高了系统的稳定性。
- 简化客户端实现:Redis Cluster对外提供了统一的接口,客户端无需关心具体的节点和数据分片细节,可以通过集群的入口节点进行访问。
- 数据一致性:Redis Cluster使用哈希槽(hash slot)来管理数据分片,保证相同的键总是存储在同一个节点上,从而保证数据的一致性。
总的来说,Redis Cluster具有高可用性、数据分片、扩展性和自动化管理等优点,适用于需要分布式存储和处理大规模数据的场景。
对比 redis 的主从方案、sentinel 方案、redis cluster方案
Redis提供了三种不同的复制方案:主从复制方案、Sentinel方案和Redis Cluster方案。下面是对它们的比较:
- 主从复制方案:
- 主从复制方案是Redis最基本的复制方案。它通过将一个Redis实例(主节点)的数据复制到多个Redis实例(从节点)来实现数据的冗余和高可用性。
- 主从复制方案适用于读写分离的场景,主节点负责写操作,而从节点负责读操作。从节点通过异步复制的方式复制主节点的数据,可以提高读取性能。
- 主从复制方案的缺点是主节点故障时需要手动进行故障转移,需要人工介入来选举新的主节点。
- Sentinel方案:
- Sentinel方案是Redis提供的一种自动故障转移和监控的解决方案。它通过引入Sentinel节点来监控主节点和从节点的状态,并在主节点故障时自动进行故障转移。
- Sentinel方案可以自动检测主节点的故障,并选举一个新的主节点来接管服务。它还可以监控从节点的状态,并在从节点故障时自动将其替换为新的从节点。
- Sentinel方案提供了高可用性和自动化的故障转移,但在故障转移过程中可能会有一段时间的服务不可用。
- Redis Cluster方案:
- Redis Cluster方案是Redis提供的分布式解决方案,用于在多个节点之间分布数据和负载。
- Redis Cluster将数据分片存储在多个节点上,并使用哈希槽(hash slot)来管理数据的分布。每个节点负责管理一部分哈希槽和相应的数据。
- Redis Cluster方案提供了自动的数据分片和负载均衡,可以水平扩展和提高系统的吞吐量(4G- -》 32G)。它还提供了自动的故障转移和节点的添加/移除功能。
- Redis Cluster方案的缺点是不支持单个键的跨节点事务和复杂的查询操作。
总结:
- 主从复制方案适用于读写分离的场景,但需要手动进行故障转移。
- Sentinel方案提供了自动故障转移和监控的功能,但在故障转移过程中可能会有一段时间的服务不可用。
- Redis Cluster方案适用于分布式场景,提供了自动的数据分片和负载均衡,但不支持跨节点事务和复杂查询操作。
3、计算机网络

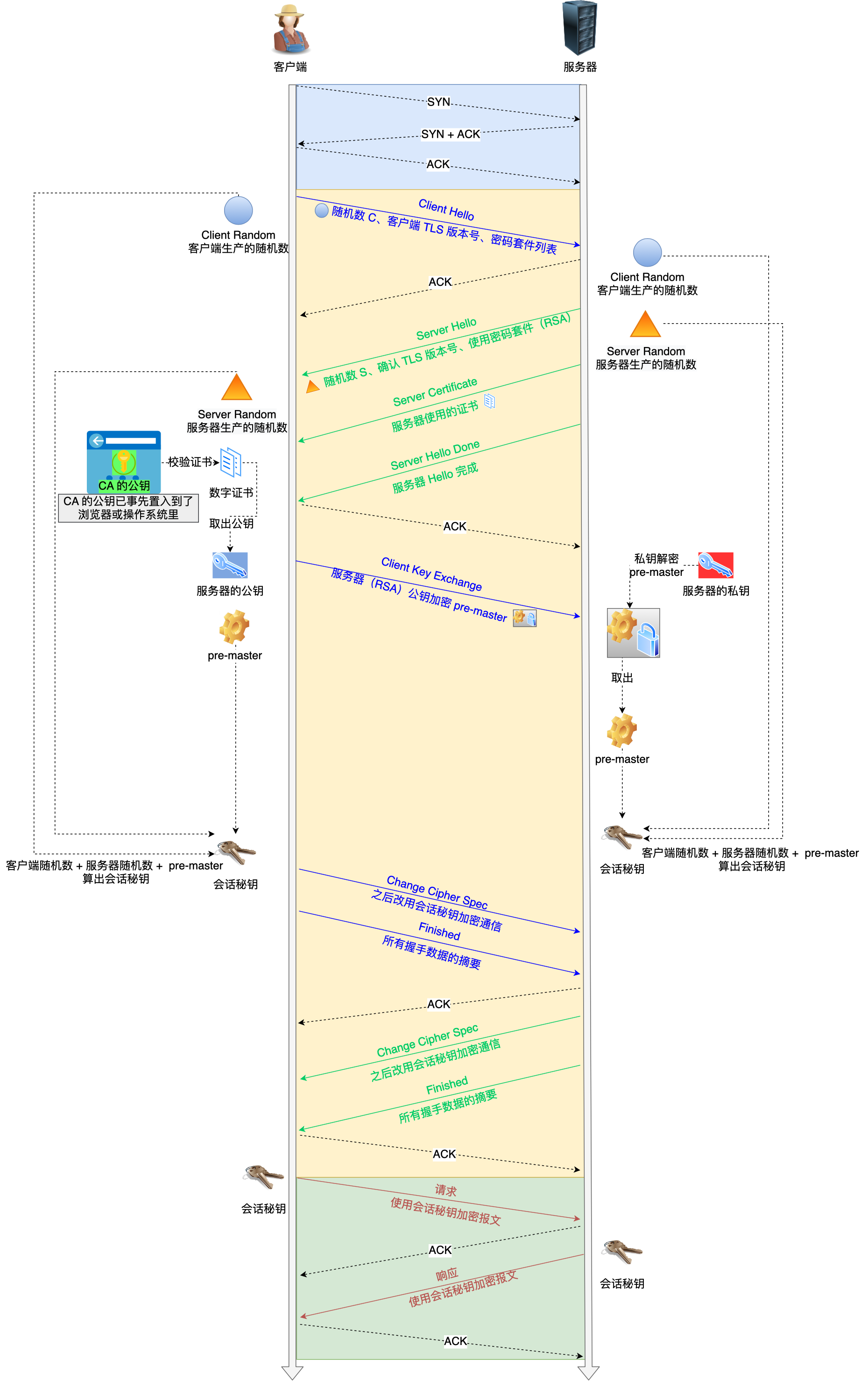
汇总:
太棒了!TCP/IP协议 (图解+秒懂+史上最全)_图解tcpip_退休的汤姆的博客-CSDN博客
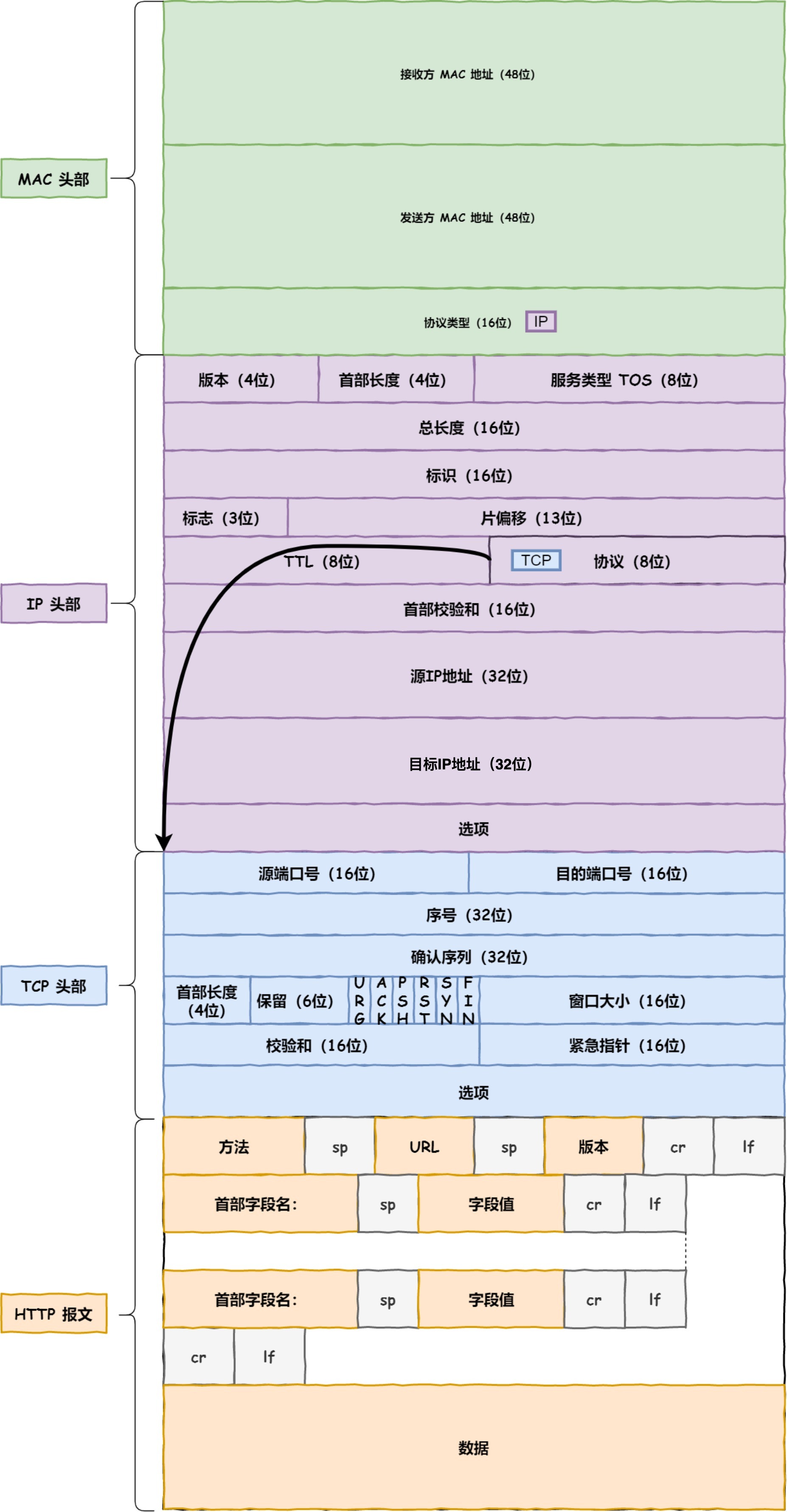
HTTPS
HTTP协议请求 头/体
- ❌ HTTP请求头,请求行,请求体分别存放的是什么?
- 请求头:编码、语言、浏览器版本、请求体的格式、长度,Connection模式,Cookie;
- 请求行:请求方法,请求URL,HTTP的版本;
- 请求体存放请求的内容信息;
请求体(Request Body)、请求行(Request Line)和请求头(Request Headers)是HTTP请求中的三个重要部分,它们承载了请求的相关信息和数据。
- 请求体(Request Body):请求体是HTTP请求中可选的部分,用于传输请求的数据或内容。它通常用于POST、PUT等请求方法,用于向服务器提交数据。
- 请求体可以包含各种格式的数据,如JSON、XML、表单数据等。具体的数据格式由Content-Type请求头指定。
- 请求体的内容可以是用户输入的表单数据、上传的文件、API调用的参数等。
- 请求行(Request Line):请求行是HTTP请求的第一行,包含了请求的方法、URL和协议版本。
- 请求方法(Method)指定了对资源的操作类型,如GET、POST、PUT、DELETE等。
- URL(Uniform Resource Locator)指定了请求的目标资源的地址。
- 协议版本(Protocol Version)指定了使用的HTTP协议版本,如HTTP/1.1。
- 请求头(Request Headers):请求头是HTTP请求中的一组键值对,用于传递附加的请求信息和控制请求的行为。
- 请求头包含了各种标准的和自定义的头部字段,如User-Agent、Content-Type、Authorization等。
- 请求头可以用于传递客户端的身份认证信息、请求的格式要求、缓存控制、语言偏好等。
请求体、请求行和请求头共同构成了HTTP请求的结构,用于向服务器发送请求并传递相关的信息和数据。它们在客户端和服务器之间进行通信,帮助实现请求的准确性、安全性和可靠性。
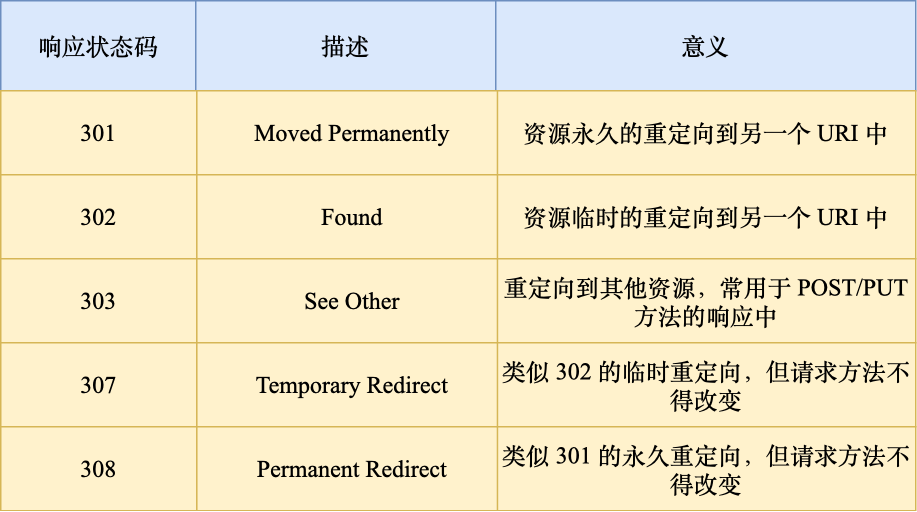
状态码:
✅ 响应状态码12345开头的含义?
1XX:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
2XX:正常响应;
3XX:重定向;
4XX:客户端错误;
5XX:服务端错误;
⭕ 502,504区别,403,404区别?
502:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应,504:作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器。
403:禁止访问该资源,404:访问的资源不存在;
30x
301、302和304是HTTP状态码,用于指示HTTP请求的结果和处理方式。它们的含义如下:
- 301 Moved Permanently(永久重定向):服务器返回301状态码时,表示请求的资源已经被永久移动到了一个新的URL。客户端在接收到301响应后,应该更新其链接到新的URL,并使用新的URL进行后续的请求。搜索引擎也会将旧的URL指向新的URL,以保持搜索结果的准确性。
- 302 Found(临时重定向):服务器返回302状态码时,表示请求的资源暂时被移动到了一个新的URL。客户端在接收到302响应后,应该使用新的URL进行后续的请求。与301不同的是,302状态码表示重定向是临时的,原始URL可能会在将来恢复使用。
- 304 Not Modified(未修改):服务器返回304状态码时,表示客户端发送的请求的资源在服务器上没有发生变化。这通常用于缓存机制,客户端可以使用缓存的副本而无需重新下载资源。服务器在返回304响应时,不会返回实际的资源内容,而是告诉客户端使用缓存的资源。
这些状态码在HTTP请求中起到不同的作用,帮助客户端和服务器进行正确的处理和跳转。例如,当网页被永久移动到新的URL时,服务器可以返回301状态码,告诉客户端更新链接。当需要临时重定向时,可以返回302状态码。而在使用缓存时,服务器可以返回304状态码,减少不必要的数据传输。
Socket 和 IO多路复用
socket模型适用于udp吗,为什么,如果是udp,那么流程是怎么样的。
socket模型不仅适用于UDP(User Datagram Protocol),也适用于TCP(Transmission Control Protocol)。Socket是一种通信机制,它提供了一种编程接口,使得应用程序可以通过网络进行数据传输。
对于UDP,socket模型可以用于实现无连接的通信。UDP是一种无连接的传输协议,它不需要在通信之前建立连接,数据包可以直接发送给目标主机。通过socket模型,应用程序可以创建一个UDP socket,并使用该socket发送和接收UDP数据包。
UDP的通信流程如下:
- 创建UDP socket。
- 绑定socket到本地IP地址和端口号。
- 发送数据:通过socket发送UDP数据包到目标主机的IP地址和端口号。
- 接收数据:通过socket接收来自其他主机发送的UDP数据包。
半连接队列与连接队列是针对socket的吗
关于半连接队列和连接队列,它们是针对TCP连接的概念,与UDP无关。在TCP连接中,存在三次握手的过程,而UDP是无连接的,不需要建立连接,因此没有半连接队列和连接队列的概念。
如果你需要更详细的信息,可以使用以下查询词进行搜索:UDP通信流程、UDP socket编程。
TCP
为什么tcp 是面向字节流
TCP是面向字节流的传输协议,而不是面向报文段的。尽管TCP在传输过程中将数据分割成报文段进行传输,但它对上层应用程序提供的是一个无差别的字节流接口。
TCP将应用程序传输的数据视为一个连续的字节流,没有明确的消息边界。TCP会将这个字节流分割成适当大小的报文段,并在网络中进行传输。报文段包含了TCP头部和数据部分。
TCP的面向字节流的特性有以下几个原因:
- 可靠性:TCP通过序列号和确认机制来保证数据的可靠传输。将数据视为字节流可以更精确地进行序列号的管理和确认机制的实现。
- 流量控制:TCP使用滑动窗口机制来进行流量控制,确保发送方和接收方之间的数据传输速率匹配。通过字节流的方式,可以更精确地控制窗口大小和数据的传输速率。
- 拥塞控制:TCP使用拥塞控制算法来避免网络拥塞。通过字节流的方式,可以更准确地进行拥塞窗口的调整和拥塞信号的传递。
尽管TCP将数据分割成报文段进行传输,但在应用程序层面,它提供了一个无差别的字节流接口,应用程序可以自行解析和处理数据的边界。
如果你需要更详细的信息,可以使用以下查询词进行搜索:TCP面向字节流、TCP报文段。
TCP连接的限制
你知道服务器单机理论最大能连接多少个客户端?
相信你知道 TCP 连接是由四元组唯一确认的,这个四元组就是:本机IP, 本机端口, 对端IP, 对端端口。
服务器作为服务方,通常会在本地固定监听一个端口,等待客户端的连接。因此服务器的本地 IP 和端口是固定的,于是对于服务端 TCP 连接的四元组只有对端 IP 和端口是会变化的,所以最大 TCP 连接数 = 客户端 IP 数×客户端端口数。
对于 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数约为 2 的 48 次方。
这个理论值相当“丰满”,但是服务器肯定承载不了那么大的连接数,主要会受两个方面的限制:
- 文件描述符,Socket 实际上是一个文件,也就会对应一个文件描述符。在 Linux 下,单个进程打开的文件描述符数是有限制的,没有经过修改的值一般都是 1024,不过我们可以通过 ulimit 增大文件描述符的数目;
- 系统内存,每个 TCP 连接在内核中都有对应的数据结构,意味着每个连接都是会占用一定内存的;
4、操作系统
进程管理
进程同步
IO模型
同步 :这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
阻塞: 阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程
异步:而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待
IO多路复用
epoll 事件 与 信号
epoll在进行事件监听时,并没有采用信号的方式。相反,epoll使用了一种基于事件驱动的机制,通过在内核中注册事件,并使用一个文件描述符(epoll文件描述符)来管理这些事件。
具体来说,epoll使用三个函数来实现事件监听:
epoll_create:创建一个epoll文件描述符,用于管理事件。epoll_ctl:用于向epoll文件描述符中添加、修改或删除事件。通过调用epoll_ctl函数,可以将感兴趣的文件描述符和对应的事件注册到epoll文件描述符中。epoll_wait:用于等待事件的发生。调用epoll_wait函数会阻塞当前线程,直到有事件发生或超时。一旦有事件发生,epoll_wait函数会返回就绪的文件描述符和对应的事件。
通过这些函数的组合,epoll可以实现高效的事件监听。相比于传统的select和poll函数,epoll具有以下优点:
- 支持大规模并发:epoll使用红黑树和哈希表的数据结构,可以高效地管理大量的文件描述符和事件。
- 零拷贝:epoll可以使用
EPOLLET模式,实现零拷贝的数据传输,提高性能。 - 只返回就绪的事件:epoll_wait函数只返回就绪的文件描述符和对应的事件,避免了遍历整个文件描述符集合的开销。
需要注意的是,epoll是Linux特有的机制,在其他操作系统上可能有不同的实现方式。
如果需要更详细的信息,可以使用以下查询词进行搜索:epoll工作原理、epoll事件驱动。
使用了 epoll 需要轮询吗
使用epoll的IO多路复用不需要轮询。相比于传统的select和poll函数,epoll采用了事件驱动的方式,通过在内核中注册事件,并使用epoll文件描述符来管理这些事件。当有事件发生时,epoll会主动通知应用程序,并返回就绪的文件描述符和对应的事件。
在使用epoll时,应用程序只需要调用一次epoll_wait函数来等待事件的发生。epoll_wait函数会阻塞当前线程,直到有事件发生或超时。一旦有事件发生,epoll_wait函数会返回就绪的文件描述符和对应的事件。
相比于传统的轮询方式,epoll的事件驱动机制可以提高系统的响应性和效率。应用程序只需要处理发生的事件,而不需要进行轮询整个文件描述符集合。
因此,使用epoll的IO多路复用不需要轮询,而是通过事件驱动的方式来处理就绪的事件。
如果你需要更详细的信息,可以使用以下查询词进行搜索:epoll工作原理、epoll事件驱动。
孤儿进程 与 僵尸进程
(1)父子进程
子进程通过父进程创建,子进程的结束和父进程的运行是一个异步过程,即父进程永远无法预测子进程什么时候结束。
当子进程退出的时候,内核会释放子进程所有资源,包括打开的文件,占用的内存等。但是依然会保留部分信息(进程id,退出状态,运行时间),直到父进程通过wait/waitpid来调用获取子进程状态信息后才释放
(2)孤儿进程
一个父进程退出,而它的一个或多个子进程还在运行,那么那些子进程将成为孤儿进程,孤儿进程将被init进程(1号进程)托管,由init进程负责完成状态收集工作
(3)僵尸进程
子进程通过父进程创建,子进程退出,父进程没有调用wait/waitpid获取子进程状态,则子进程的进程描述符依然保存在系统中,形成僵尸进程
子进程结束后,父进程没来及调用wait/waitpid,会进入僵尸进程,如果父进程及时调用,子进程会从僵尸进程退出,但这个过程中也会经过僵尸进程
如果父进程在子进程结束之前退出,则子进程由init接管。init将会以父进程身份对僵尸状态的子进程进行处理
产生危害:资源泄漏(一种是pcb所占内存资源一直无法被回收,一种是一个用户所能创建的进程数量是有限制的,没有可用的进程号将导致系统不能产生新的进程)
解决方案:
处理:退出父进程
(1)内部fork两次,子进程变成孤儿进程,父进程由init进程担任实现托管
(2)外部通过kill指令消灭产生僵尸子进程的进程,使其变成孤儿进程,init托管
避免:进程等待,信号处理函数wait接收子进程退出时向父进程发送的SIGCHILD信号
版权声明:本文为CSDN博主「HT . WANG」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36131611/article/details/118608842
内存管理
分段与分页的优缺点
分段和分页是两种不同的内存管理方式,它们各自有不同的好处。
分段的好处:
- 灵活的内存管理:分段将进程的地址空间划分为多个段,每个段可以具有不同的大小和属性。这样可以更灵活地满足不同程序的内存需求,提供更好的内存管理和保护机制。
- 共享和保护:多个进程可以共享同一个段,从而节省内存空间。同时,通过设置段的保护属性,可以实现对不同段的访问权限控制,提高系统的安全性。
- 减少内存碎片:由于段的大小是固定的,当一个段不再使用时,可以将整个段回收,而不会产生内部碎片。这样可以提高内存利用率。
分页的好处:
- 简化的内存管理:分页将内存划分为固定大小的页,简化了内存管理的复杂性。每个页的大小相同,可以更方便地进行内存分配和回收。
- 灵活的地址映射:分页通过页表进行地址映射,可以将虚拟地址空间映射到物理内存的任意位置。这样可以实现虚拟内存的概念,使得进程可以使用比物理内存更大的地址空间。
- 内存保护和隔离:通过设置页表的权限位,可以实现对不同页的访问权限控制,提高系统的安全性。同时,不同进程的页表可以相互隔离,保护各个进程的内存空间。
总结来说,分段和分页都有各自的优势。分段提供了灵活的内存管理和共享保护机制,适用于不同大小和属性的内存需求。而分页提供了简化的内存管理和灵活的地址映射,适用于实现虚拟内存和内存保护隔离。
段页式 对比 多级页表 的优点
段页式内存管理是一种将内存划分为固定大小的段和页的内存管理方式。相比于多级页表,段页式内存管理有以下几个优势:
- 灵活的地址空间划分:段页式内存管理可以将进程的地址空间划分为多个段,每个段可以具有不同的大小和属性。这样可以更灵活地满足不同程序的内存需求,提供更好的内存管理和保护机制。
- 共享和保护:段页式内存管理可以实现段的共享和保护。多个进程可以共享同一个段,从而节省内存空间。同时,通过设置段的保护属性,可以实现对不同段的访问权限控制,提高系统的安全性。
- 减少内存碎片:段页式内存管理可以减少内存碎片的产生。由于段的大小是固定的,当一个段不再使用时,可以将整个段回收,而不会产生内部碎片。这样可以提高内存利用率。
- 快速地址转换:段页式内存管理可以通过段表和页表进行地址转换,从而快速定位到物理内存中的具体位置。相比于多级页表,段页式内存管理的地址转换过程更加简单和高效。
尽管段页式内存管理有上述优势,但也存在一些缺点。例如,段页式内存管理需要维护段表和页表,增加了内存管理的复杂性。同时,由于段的大小是固定的,可能会导致内部碎片的浪费。
5、云原生
docker
DockerFile
纯干货!Docker Dockerfile指令大全 - 知乎 (zhihu.com)
Nginx
Nginx 平滑升级-腾讯云开发者社区-腾讯云 (tencent.com)
RESTful
面试官:说说你对 RESTful 的理解? - 知乎 (zhihu.com)
6、ES
当然,以下是一些常用的Elasticsearch操作和功能的完整列表,以及官方文档的参考地址:
查询操作:
- match:根据指定字段的匹配查询
- term:根据指定字段的精确值查询
- range:根据指定字段的范围查询
- bool:组合多个查询条件
参考地址:查询操作官方文档
聚合操作:
- terms:根据指定字段进行分组统计
- range:根据指定字段的范围进行分组统计
- date_histogram:根据日期字段进行时间间隔分组统计
参考地址:聚合操作官方文档
过滤操作:
- term:根据指定字段的精确值进行过滤
- range:根据指定字段的范围进行过滤
- bool:组合多个过滤条件
参考地址:过滤操作官方文档
排序操作:
- sort:根据指定字段进行排序
- _score:根据文档的相关性评分进行排序
参考地址:排序操作官方文档
以上只是一些常见的操作和功能,Elasticsearch还提供了更多的功能和操作,如分页、高亮、聚合计算等。您可以在Elasticsearch的官方文档中找到更详细的信息。
官方文档地址:Elasticsearch官方文档
如果您需要更具体的操作和示例,建议参考官方文档或在开发社区中寻求帮助。
n、分布式
分布式共识算法 与 应用
ETCD和Zookeeper区别
ETCD和Zookeeper是两种常用的分布式一致性协调服务,它们有以下几个区别:
- 数据模型:ETCD是一个分布式键值存储系统,类似于分布式的字典或哈希表,可以存储键值对。而Zookeeper则是一个分布式的层次命名空间,类似于分布式的文件系统,可以存储和管理层次结构的数据。
- 一致性算法:ETCD使用的是Raft一致性算法,它保证了强一致性和高可用性。Zookeeper使用的是ZAB(Zookeeper Atomic Broadcast)协议,它也能提供强一致性和高可用性。
- 功能特性:ETCD主要用于分布式系统中的服务发现、配置管理和分布式锁等场景。它提供了简单的API和触发器,支持事务操作和监听机制。Zookeeper则更加注重于分布式协调和同步,提供了更丰富的特性,如分布式队列、分布式锁、分布式协调等。
- 生态系统:ETCD是Kubernetes的核心组件之一,用于存储集群的元数据和配置信息。它也被广泛应用于其他分布式系统中。Zookeeper则在分布式系统领域有着广泛的应用,被用于Hadoop、Kafka等项目中。
物理存储-LSM、SST 、B+
LSM(Log-Structured Merge)和列存储是两种常见的存储结构,而B+树存储和SST(Sorted String Table)存储是在LSM和列存储中常用的索引结构。下面我将详细介绍这几种存储结构的特性、适用场景、优点、缺点以及它们之间的对比。
LSM(Log-Structured Merge)存储结构:
- 特性:LSM是一种基于日志结构的存储引擎,将数据写入顺序日志文件(Log)中,然后通过合并(Merge)操作将数据写入到内存和磁盘中的索引结构中。
- 适用场景:适用于写入密集的工作负载,如日志记录、时间序列数据等。
- 优点:高写入性能、支持高并发写入、适用于大规模数据集。
- 缺点:读取性能相对较低、占用更多的磁盘空间、合并操作可能导致写放大。
- 对比:相对于B+树存储,LSM存储具有更高的写入性能,但读取性能较低。
列存储:
- 特性:列存储将数据按列存储在磁盘上,而不是按行存储。每个列都有自己的存储文件,可以独立地进行压缩和编码。
- 适用场景:适用于分析型查询,如数据仓库、OLAP等。
- 优点:高压缩率、高查询性能、适用于大规模数据集、支持高并发查询。
- 缺点:写入性能相对较低、不适合频繁更新的工作负载。
- 对比:相对于传统的行存储,列存储具有更高的查询性能和压缩率,但写入性能较低。
B+树存储结构:
- 特性:B+树是一种平衡的多路搜索树,用于在磁盘上组织和管理数据。它具有层级结构,每个节点可以存储多个键值对。
- 适用场景:适用于随机读写的工作负载,如数据库系统。
- 优点:高查询性能、支持范围查询、适用于小规模和中等规模数据集。
- 缺点:写入性能相对较低、不适合大规模数据集。
- 对比:相对于LSM存储和列存储,B+树存储具有更高的读取性能,但写入性能较低。
4.SST(Sorted String Table)存储结构(续):
- 优点:高读取性能、支持范围查询、适用于键值存储引擎、压缩率较高、支持快速的键查找。
- 缺点:写入性能相对较低、不适合频繁更新的工作负载、合并操作可能导致写放大。
- 对比:相对于LSM存储和B+树存储,SST存储具有更高的读取性能和压缩率,但写入性能较低。
综合对比:
- LSM存储适用于写入密集的工作负载,具有高写入性能,但读取性能较低。
- 列存储适用于分析型查询,具有高压缩率和查询性能,但写入性能较低。
- B+树存储适用于随机读写的工作负载,具有高查询性能,但写入性能较低。
- SST存储适用于键值存储引擎,具有高读取性能和压缩率,但写入性能较低。
—————看看大佬怎么说——————
绿盟一面+二面
一面25min
1.面向对象的五大特性?
2.mysql慢查询?如何检查和优化?
开启慢查询日志(slow_query_log =1 配置文件)
设置阈值:long_query_time
分析日志:mysqldumpslow
优化:从sql语句、表结构 出发
MySQL慢查询是指执行时间较长的SQL语句,可能会对数据库性能产生负面影响。为了检查和优化MySQL慢查询,可以按照以下步骤进行操作:
- 开启慢查询日志:在MySQL配置文件中(通常是my.cnf或my.ini),将
slow_query_log设置为1,启用慢查询日志。可以通过设置slow_query_log_file指定慢查询日志文件的路径。 - 设置慢查询阈值:通过设置
long_query_time参数,指定执行时间超过该阈值的SQL语句将被记录到慢查询日志中。可以根据实际情况调整阈值,通常建议设置为0.1秒或更高。 - 重启MySQL服务:在修改完配置文件后,需要重启MySQL服务使配置生效。
- 分析慢查询日志:使用工具(如mysqldumpslow、pt-query-digest等)分析慢查询日志,找出执行时间较长的SQL语句和频繁出现的查询模式。
- 优化慢查询:根据分析结果,对慢查询进行优化。以下是一些常见的优化方法:
- 添加索引:通过为频繁查询的列添加索引,可以加快查询速度。
- 优化查询语句:检查慢查询中的SQL语句,优化查询语句的结构和逻辑,避免不必要的查询和重复操作。
- 优化数据库结构:根据查询需求和数据特点,调整数据库表结构,避免冗余和不必要的关联查询。
- 使用缓存:对于一些频繁查询但不经常变化的数据,可以使用缓存技术(如Redis)来提高查询性能。
- 测试和监控:对优化后的查询进行测试,确保性能得到改善。同时,可以使用MySQL的性能监控工具(如Explain、Performance Schema等)来实时监控数据库的性能指标,及时发现和解决潜在的性能问题。
3.最左匹配原则?索引失效的场景?
4.了解那些linux指令?如何查看java进程?
5.java如何实现线程安全?
。。。就记得这些
二面30min
1.深挖项目
2 tcp和udp的区别?
3.状态码301 302 304是什么?
4.https?ssl握手过程?
5.tcp四次挥手的过程?
- 开启慢查询日志:在MySQL配置文件中(通常是my.cnf或my.ini),将
作者:欧内的手
链接:https://www.nowcoder.com/discuss/402533418146312192?sourceSSR=search
来源:牛客网
绿盟java base武汉 一面 二面 三面 已意向
平时老是看牛友的面经,今天回馈一波牛友
9.7一面 50min
1,实验室项目(后面主挖参与的部分,很细致)
2,计算机网络模型和各层的常见协议的介绍
3,lock和synchronized的区别
4,final ,fxx,fxx的区别
- final是修饰符:用于修饰类(不可继承)、方法(不可重写)、变量(不可修改)、属性()
- finalize是方法,示例被第一次回收的时候执行,用于实例的复活
- finally 配合try 使用,用于try 代码段的资源关闭等后续操作
5,关于sql的优化的看法,sql注入
- 优化看法:尽量避免使用xx,尽量使用xx
- 对需要排序的字段放入索引,因为索引建立是有序的
- 尽量避免子查询,使用连接join
- 对于limit,应该先 分页的(偏移量)第一条数据id,然后进行 分页
- 尽量使用索引,利用索引下推、索引覆盖减少回表次数、
- 根据字段特性进行索引建立,比如 身份证使用前缀索引
6,尽可能详细的讲解tcp三次握手和四次挥手
7,六大设计原则以及相关的体验
8,常见的设计模式以及在哪见过或者自己写过。
9,什么时候会发生回表
10,java并发编程的体会,(讲讲juc和jvm锁)
11,分布式锁怎能实现的
12,实践项目主要负责的地方和体会感受
13,幂等性问题
14,对于的认知(防 🔥 墙)
不太了解,就结束了。还以为要凉凉。
9.22二面 20min
1,实验室项目,细节和流程(很细致)
2,如何排查网络问题
3,个人的学习方式
4,1-3年的职业规划
当天晚上收到测评
10.10三面 20min
1,网络安全方面的问题
2,输入一个网址,发生了什么
- HTTP
- DNS
浏览器会先看自身有没有对这个域名的缓存,如果有,就直接返回,如果没有,就去问操作系统,操作系统也会去看自己的缓存,如果有,就直接返回,如果没有,再去 hosts 文件看,也没有,才会去问「本地 DNS 服务器」。 - TCP / IP
- IP
- MAC
- 先查询 ARP 缓存,如果其中已经保存了对方的 MAC 地址,就不需要发送 ARP 查询,直接使用 ARP 缓存中的地址。
- 而当 ARP 缓存中不存在对方 MAC 地址时,则发送 ARP 广播查询。
- MAC 头部的作用就是将包送达路由器,其中的接收方 MAC 地址就是路由器端口的 MAC 地址。因此,当包到达路由器之后,MAC 头部的任务就完成了,于是 MAC 头部就会被丢弃。
3,接着2,问 响应缓慢的原因分析
4,谈谈如何开发一项目,用软件工程角度
5,期望的公司是怎么样的,是哪里人
6,对于未来相关行业的局势的看法
由于聊的比较久,没有反问环节
10.14收到录用意向书
作者:快乐的猕猴桃反对画饼
链接:https://www.nowcoder.com/discuss/402586023933341696?sourceSSR=search
来源:牛客网
24 届 Java 后端秋招面经分享
秋招面经,回馈一下牛友。
切记,项目、实习一定需要总结,背诵下来,项目里有挑战的事情、前因后果、遇到的难点,实习的收获、个人的成长等,这些问题都是高频题,如果提前总结的话,面试的时候可以侃侃而谈,一般面试官问这些问题的时候,我一般就直接讲个 10 分钟,这样面试就过去 1/4 了。
一些原理的介绍,前往不要讲一两句就结束了,能多深入多深入,多发散多发散,多水点面试时长,最好讲到面试官打断你,这样面试绝大部分时间都是被你掌控的。
算法也是,即使你会,也要拖一会,一般拖到个 45min 左右就不会给你出第二个算法题了,这也算一个小技巧?
八股按照 JVM、Java、Mysql、Redis、计网、OS 的优先级(个人根据面试提问频率总结)着重复习。
不知道什么情况,感觉秋招问的比暑期简单一点?可能是实习和项目经历丰富,大部分面试有个二三十分钟都是介绍这个。
08-15 快手一面 45min
- 自我介绍。
- 为什么想来快手。
- 介绍一下阿里的实习经历。
- 介绍一下字节的实习经历。
- 介绍下项目经历。
- 介绍一下 Synchronize 机制。
- 最好是要深入到 Cpp monitor 对象。
- 顺带介绍了 wait 和 notify 的实现原理。
- 你刚刚提到 wait 和 notify,AQS 是否有类似的实现?
- 介绍 AQS 的条件队列。
- 算法题:带过期时间的 LRU 缓存。
- 反问。
隔了两天收到二面邀请。
08-17 阿里滔天一面 35min
- 自我介绍。
- 实习经历介绍。
- 实习的时候做的最有成就的一件事?
- 体现了你的什么价值?
- 还能做的更好吗?
- 挑一个你最熟悉的项目介绍一下。
- 介绍一下数据库插入的全流程。
- 你刚刚提到索引,介绍一下索引是如何工作的。
- B+ 树相当于 B 树的优点在哪里?
- 你提到 lsm 树和列存储,在实际工作中有使用吗?介绍下使用场景。
- 在阿里实习的成长。
- 介绍一下 JVM 的垃圾收集机制。
- 为什么新生代需要三个空间,优点在哪?
- 介绍一下 G1 垃圾收集器。
- 介绍下类加载机制。
- 反问。
当天收到二面邀请。
8-18 阿里滔天二面 80min
老板面,感觉更多的是压力与思想上的拷打。
- 自我介绍。
- 字节实习经历介绍。
- 字节实习经历拷打。
- 你认为你和别人的优势在哪?
- 为什么要来面我门部分?
- 看你之前都是做底层产品偏多,我们大多数业务,你觉得你是否能够适应下来?
- 阿里实习经历介绍。
- 做这件事的内在驱动是什么?
- 是你主动去做的吗?
- 成果是怎么衡量的?
- 这个成果达到预期了吗?
- 如何判断成果是否达到预期了?
- 还有别的办法吗?调研过吗?
- 你认为是技术重要还是业务重要?
- 你更喜欢做技术?可是我们这大部分都是业务?
- 这里我踩坑了,对方是业务部门一定要说自己喜欢业务,扯一扯技术赋能业务之类的黑话。
- 业务落地能力和性能调优能力是不一样的,你怎么样评估你的业务落地能力?
- 你做一个需求之前会考虑哪些?
- 介绍下项目中的数据库表设计思路。
- 一个业务想要做好,需要哪些品质?
- 反问。
- 本来范围也就 60 几分钟,然后面试官回答着又扯到业务和技术上去了,又拉扯了十几分钟。
29 号笔试完成后约 HR 面。
8-19 快手二面 30min
最没有体验感的一次面试,全是写题,既然全是写题,为什么不搞个笔试?面试的意义何在?而且我不清楚快手为什么要周日面?
- 自我介绍。
- 算法题:k 个一组反转链表。
- 算法题:多个有序数组排序。
- 智力题:两个人拿 100 个石头,最后一个拿完的胜利,每人一次只能拿 1~5 个,必胜策略。
- 面的时候没想出来,面完了也懒得去搜。
- 概率题:两个人都有可能在 6~7 点到达公园,到达后,最多会停留 15min,问,相遇的概率。
- 反问。
中途流程灰了,然后 9 月 11 号莫名其妙又发三面邀请,流程又亮起来了,拒。
8-23 滴滴一面 40min
- 自我介绍。
- 挑一个项目介绍一下。
- 介绍一下 JVM 内存区域。
- 这题我直接说了十分钟,被喊停的。
- 介绍一下 Java 常见集合。
- 介绍一下 TCP。
- 这里也说了差不多十分钟
- 算法题:顺时针打印螺旋矩阵。
- 反问。
上午 12 点面完,中午 12 点 45 然我去二面,绷不住了,当时正在午休,没看见消息,这奇葩的设定。
后来看到消息,想了想直接放弃了,对滴滴兴趣也不大,然后 2 点 15 接到了一个电话,当时在开会没接,2 点 30 又打电话来,问我为啥鸽他们,然后让我立即上线。
二面聊了 20 来分钟把….. 当天感谢信。
8-22 字节一面 45min
- 自我介绍
- 字节实习经历介绍。
- 你提到 Redis Moved 错误,能介绍一下吗?
- Redis 集群模式的优缺点?
- 挑一个项目介绍一下。
- 怎么做查询优化的?
- 用直方桶维护的话,岂不是每一次插入删除都要维护每个字段?
- 怎么优化呢?
- B+ 树 crabbing 协议介绍。
- 淘宝店铺中的热销榜单如何设计?
- 先考虑热销商品,访问量大,用 Redis 减少压力。
- 立马提出用 Redis 有序列表数据结构。
- 由于商品火热,因此实时维护 zset 不太合理,压力过大。
- 可以先记 pv log,流式产品解析 pv log,存特征表。
- 定时任务批量处理,更新 Redis 列表,刷新缓存。
- 流处理和批处理哪个好?使用场景。
- MapReduce 介绍一下?
- 介绍一下 MIT6.824 实验。
- 算法题:三数之和。
25 号收到二面邀请。
8-29 字节二面 40min
- 自我介绍。
- 为什么不选择保研。
- 平时怎么学习的。
- 字节实习介绍。
- 每次面试都要介绍实习…..
- 一般我一介绍就是 10 分钟起步。
- 阿里实习介绍。
- 你是怎么去评估做这件事的价值。
- 能否给我讲一下你这个产品的核心价值。
- 看上去你做的这些事并不是特别有价值?价值体现在哪?
- 如果阿里和这边同时给你发 offer,你会怎么选择。
- 平时有哪些爱好。
- 算法题:最小栈。
9 月 1 号收到三面邀请。
9-3 小红书一面 40min
- 自我介绍。
- 实习经历介绍。
- 项目经历介绍。
- 介绍一下 Synchronize 机制。
- 介绍一下 Java8 到 Java21 的新特性。
- 介绍一下 Java19 新特性虚拟线程。
- 介绍一下 Java 中协程的实现原理。
- 平时通过哪些途径学习。
- 介绍下 Java 常用集合。
- 介绍下限流的几种实现方案。
- Redis 滑动窗口、滚动窗口限流。
- Sentinel 分布式限流解决方案,基于窗口。
- 受控限流,令牌环。
- 漏洞算法。
- 代码设计题:实现 Redis 滑动窗口限流。
5min 后收到二面通知。
9-3 小红书二面 30min
- 自我介绍。
- 实习经历介绍。
- 在阿里的成长。
- 数据库 DTS 怎么实现的,断点续传怎么实现的。
- Redis 常用数据结构介绍下。
- 哨兵机制介绍下。
- 算法题:消消乐。(给定一个数组,连续的相同的数字会被消除)
9 月 12 收到 HR 面,拒。
9-4 阿里滔天 HR 面 50min
- 自我介绍。
- 为什么选择来我们这。
- 在学校是否有参加过一些比赛、社团。
- 为什么不保研。
- 介绍下在阿里的实习经验。
- 你认为,你实习的三家公司里,那家公司你体验最好?
- 这三家公司里,你收获了什么。
- 在阿里实习时,有遇到什么困难吗?怎么解决的。
- 有用到哪些先进的技术。
- 你认为你和别人的 gap 在哪?
- 期望薪资是多少。
- 别的同学也很优秀,你认为你的优势是?
- 当你遇到困难时,怎么去解决的?
- 反问。
聊天时得知,今年滔天 90% 校招 offer 都是 p4,物是人非啊。
9 月 7 号 OfferCall,由于给 P4,拒。
9-4 字节三面 50min
- 自我介绍。
- 大一到现在,学习的路线介绍一下。
- 阿里挑一件事讲一下。
- 字节环境部署流程提速 40% 怎么得出的。
- 在外面有看哪些机会?我不希望到时候你接了意向然后又拒掉他,如果同时发 offer 会来我们这吗?
- 为什么想来我们部门。
- 选择 offer 的会考虑哪些因素。
- 这里踩坑了,我说部门业务是否核心是我的一个考虑因素,应该要说业务前景而不业务是否核心。
- 那如果我把你分配到一个不核心的业务去,你会怎么办?不干了吗?
- 我答了还要考虑氛围、技术沉淀等因素,面试官直接问,也就是如果这些都不好,你会不干吗?
- 当时懵逼了,应该要立即答有信息把业务从不核心干到核心的,奈何我太嫩了,没答上来,然后面试官就下一个话题了。
- 既然考虑业务是否核心,为什么不在阿里内部跳呢?
- 这个也答不来。。。我扯了很多,还提到 “脉脉上说 xxxx” 之类的。
- 你为什么还会看脉脉这种戾气很重的 app。
- 其实这里面试官想要的答案是我自己思考出来的,没有受别人影响的答案。
- 如何判断一个业务是否核心?你是怎么认为我们产品很核心呢?
- 喜欢 C 端还是 B 端?
- 为什么喜欢 C 端?
- 让你选择部门,你会怎么选择?
- 你觉得你相对别人的优势在哪?
- 反问。
这里的评价是技术能力 OK,业务理解力偏差。感觉 sp 没戏了。
隔天约 HR 面。
9-5 美团一面 60min
- 自我介绍。
- 介绍一下阿里实习经历。
- 介绍一下 Redis 基本数据类型。
- 为什么用 skip list 不用红黑树?
- 主要是范围遍历,其他都是假的。
- 介绍一下数据库索引工作原理。
- 深入讲了一下。
- 缓存池原理。
- 索引的 redo log 和 undo log。
- 索引的查询。
- 索引上的 next key lock。
- 数据库的隔离级别。
- 介绍下 https 原理。
- 介绍下 tcp 三次握手的流程。
- 向这种问题也是能深入的,同步异步、socket、半连接队列、tcp 泛洪、epoll 通知。
- 其实这些知识点大家都会,就是没法联想,很多知识都是能串起来的,一定要联想其他知识点去回答(能多拉扯点时间,面试官还会认为你回答的有深度)。
- 介绍下四次挥手的过程。
- 智力题:毒药。
- 算法题:最长上升子序列。
- 算法题:鸡蛋掉落。
隔天二面邀请。
9-6 字节 HR 面 20min
- 自我介绍。
- 介绍下在三家公司的经历。
- 给你带来了哪些成长。
- 外面有哪些 offer。
- 看你项目经历也挺丰富的,你认为还有哪些可以提升的地方。
- 在学校怎么学习的。
- 更喜欢做底层业务,还是上层业务。
- 技术和业务之间的关系。
- 能来实习吗?
- 反问。
一周后意向。
9-7 美团二面 50min
- 自我介绍。
- 介绍一下字节实习经历。
- 介绍一下阿里实习经历。
- 当时的解决方案有产出文档吗?
- 这里我说阿里的实习生没有文档权限。
- 然后和面试官聊了了一会天。
- 看你对 netty 应该比较熟悉,介绍一下 netty 的优缺点。
- 为什么想来我们部门。
- 场景题:在一个搜广推的项目里,如果发现自前半个月以来,调用耗时由 500ms -> 700ms,请你分析一下可能的原因。
- 这个就看临场发挥了,主要从 IO 限制,上下游对接、缓存命中、流量高峰等因素考虑。
- 智力题:一个圆桌,和对手轮流放硬币,问必胜策略。
- 算法题:最长有效括号。
隔天三面邀请。
9-11 美团三面 35min
- 自我介绍。
- 挑一个项目介绍一下。
- 介绍你在阿里的工作。
- 介绍一下上下游链路。
- 这里就是要看你是否关注了团队内其他产品以及是否理解团队的整体链路。
- 要说到面试官弄明白整体链路。
- 为什么要来我们部门。
- 你认为你的优势在哪里?
- 如果同时给你 offer,选择哪里?
- 你认为程序员必不可缺的品质是什么?
- 你认为 4 天工作制在中国行得通吗?
- 如何看待我们部门的发展前景。
- 反问。
当天约 HR 面。
9-12 美团 HR 面 30min
大部分都是聊部门发展,这里就不暴露部门了,略了。
隔天早晨意向。
作者:Happysnaker
链接:https://www.nowcoder.com/discuss/532303076607197184
来源:牛客网