Kubernetes 学习
Kubernetes 学习
kubectl manual
Command line tool (kubectl) | Kubernetes
Kubernetes 网络模型
Network:了解K8S的网络通信模型 - 知乎 (zhihu.com)
类比 Dokcer 与 k8s
- 根据网络通信方式,可以这样子类比k8s和docker吗:
- pod 等价于 dockers 的一个network隔离,
- 一个node 等价于 一个docker 宿主机;
- pod 与pod之间跨node 通信,需要借助 overlay 网络吗
在Docker中,容器之间默认是通过Docker的网络隔离机制进行通信的。每个Docker容器都有自己的网络命名空间,使得容器之间的网络互相隔离,每个容器都有自己的IP地址和网络接口。这种网络隔离可以确保容器之间的通信不会相互干扰。
类比到Kubernetes中,可以将Pod看作是Docker容器的集合,每个Pod中可以包含一个或多个容器。Pod提供了一种逻辑上的封装,使得多个容器可以在同一个Pod中协同工作。因此,可以将Pod类比为Docker的一个网络隔离单元。
而Node(节点)可以类比为Docker宿主机,它是运行Kubernetes集群的物理或虚拟机。每个Node上可以运行多个Pod,类似于一个Node上可以运行多个Docker容器。
当Pod与Pod之间跨Node进行通信时,确实需要借助Overlay网络。Overlay网络是Kubernetes中一种常用的网络模型,它通过在底层网络之上创建虚拟网络,使得不同Node上的Pod可以通过Overlay网络进行通信。Overlay网络可以通过各种技术实现,如VXLAN、Flannel、Calico等。
总结起来,可以将Pod看作是Docker的一个网络隔离单元,Node类比为Docker宿主机,而Overlay网络则是Kubernetes中实现Pod与Pod跨Node通信的一种网络模型。
Kubernetes 的网络模型
在学习 Kubernetes 的网络之前,要先简单了解一下 Docker 的网络知识。
Docker里面有 null、host 和 bridge 三种网络模式。这里有一张图,描述了 Docker 里最常用的 bridge 网络模式:
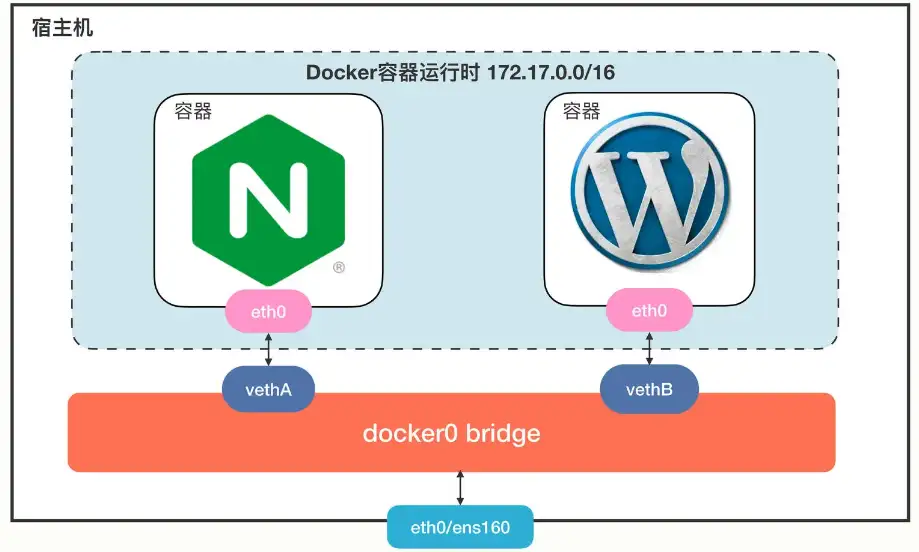
Docker 会创建一个名字叫“docker0”的网桥,默认是私有网段“172.17.0.0/16”。每个容器都会创建一个虚拟网卡对(veth pair),两个虚拟网卡分别“插”在容器和网桥上,这样容器之间就可以互联互通了。
Docker 的网络方案简单有效,但问题是它只局限在单机环境里工作,跨主机通信非常困难(需要做端口映射和网络地址转换)。
针对 Docker 的网络缺陷,Kubernetes 提出了一个自己的网络模型,能够很好地适应集群系统的网络需求,它有下面的这 5 点基本假设:
- • 集群里的每个 Pod 都会有唯一的一个 IP 地址。
- • Pod 里的所有容器共享这个 IP 地址。
- • 集群里的所有 Pod 都属于同一个网段。
- • Pod 直接可以基于 IP 地址直接访问另一个 Pod,不需要做麻烦的网络地址转换(NAT)。
- • 共享namespace : Pod里面的容器共享network namespace (IP and MAC address), 所以这些容器交互可以使用本地回环地址
以下是Kubernetes 整体的网络模型的示意图:
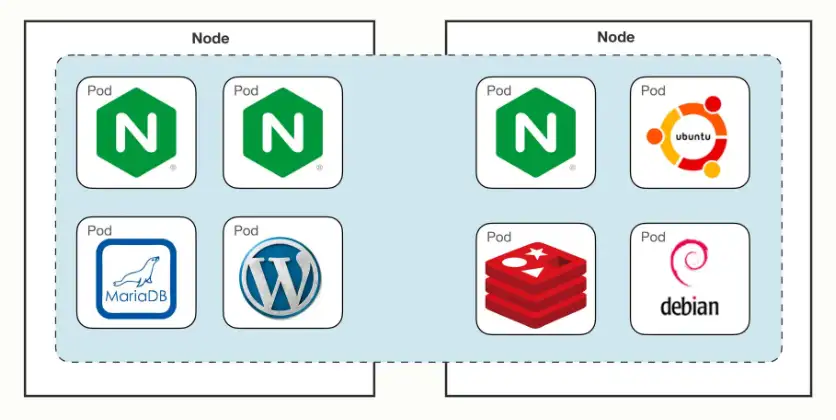
从上图可以看出网络让 Pod 摆脱了主机的硬限制,是一个“平坦”的网络模型,很好理解,通信自然也非常简单。
因为 Pod 都具有独立的 IP 地址,相当于一台虚拟机,而且直连互通,也就可以很容易地实施域名解析、负载均衡、服务发现等工作。
Kubernetes 整体的网络模型细化来看,可以分为container-to-container的网络访问、Pod-to-Pod的网络访问、Service-to-Pod的网络访问。
Container-to-container网络模型
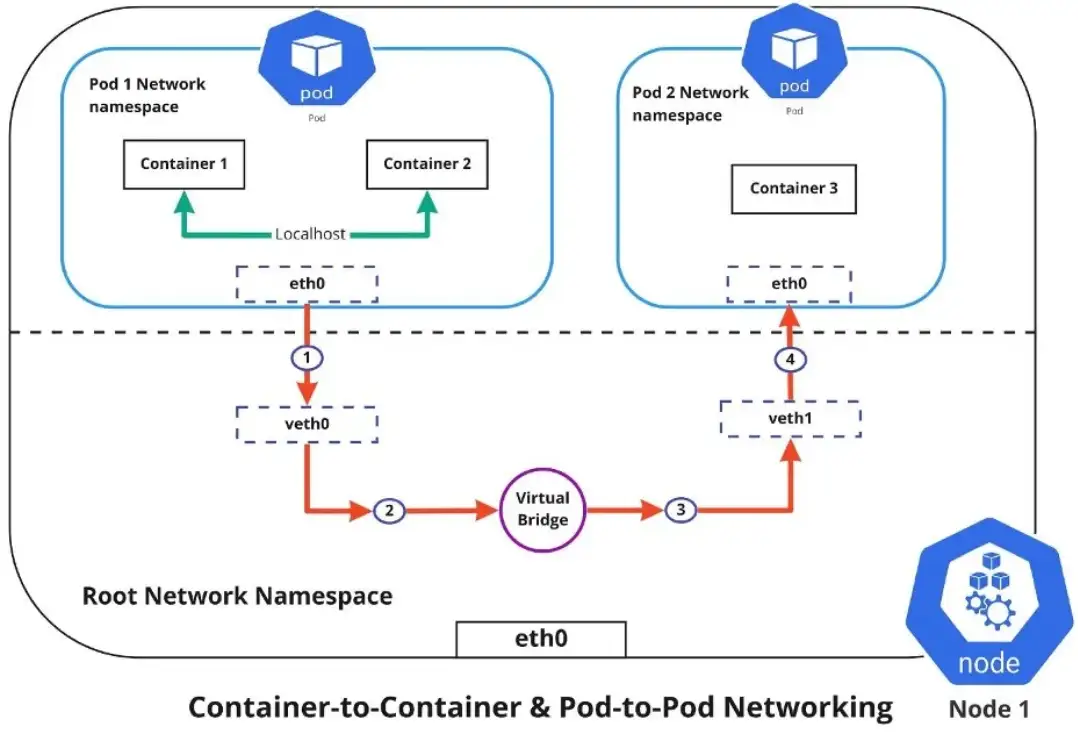
容器到容器的网络是通过 Pod 网络命名空间进行的,network namespace 允许您拥有单独的网络接口和路由表,这些接口和路由表与系统的其余部分隔离并独立运行。
每个 Pod 都有自己的network namespace ,该 Pod 中的容器共享相同的 IP 地址和端口,这些容器之间的所有通信都通过 localhost 进行,因为它们都是同一命名空间的一部分。
Pod-to-Pod网络模型
在Kubernetes集群中,每个节点都有一个指定的 Pod IP CIDR 范围,这可确保每个 Pod 都能收到集群中其他 Pod 可以看到的唯一 IP 地址。
创建新的Pod 时,IP 地址永远不会重复,无论你将 Pod 部署在集群中的同一节点还是不同节点上。与容器到容器网络不同,Pod 到 Pod 通信是使用真实 IP 进行的,
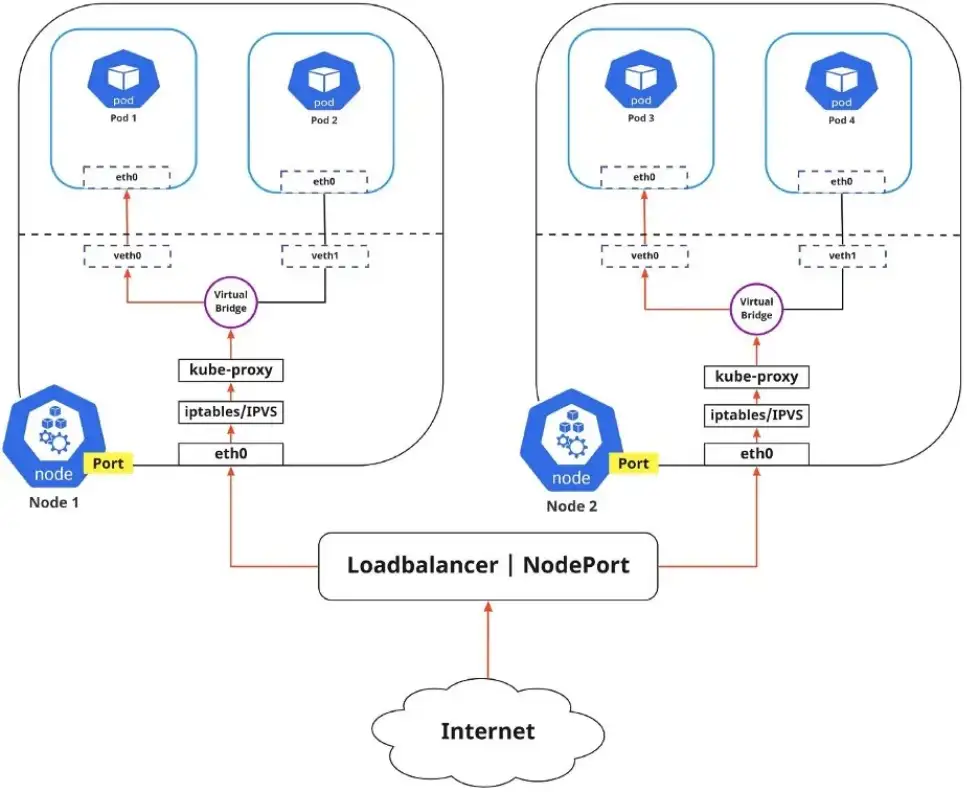
如上图所示,要使 Pod 相互通信,流量必须在 Pod 网络命名空间和根网络命名空间之间流动。这是通过虚拟以太网设备或 veth 对(图中的 veth0 到 Pod 命名空间 1 和 veth1 到 Pod 命名空间 2)连接 Pod 命名空间和根命名空间来实现的。
当数据从 Pod 1 发送到 Pod 2 时,数据流如下:
- \1. Pod 1 流量通过 eth0 流向根网络命名空间的虚拟接口 veth0
- \2. 流量通过 veth0 到达虚拟网桥,虚拟网桥连接到虚拟接口 veth1
- \3. 流量通过虚拟网桥到达 veth1
- \4. 最后,流量通过 veth1 到达 Pod 2 的 eth0 接口
Service-to-Pod网络模型
Pod可能需要根据需求进行扩展或缩减,他动态调整的,如果应用程序崩溃或节点故障,可以再次创建它们。这些事件会导致 Pod 的 IP 地址发生变化,这将使网络成为一个挑战。
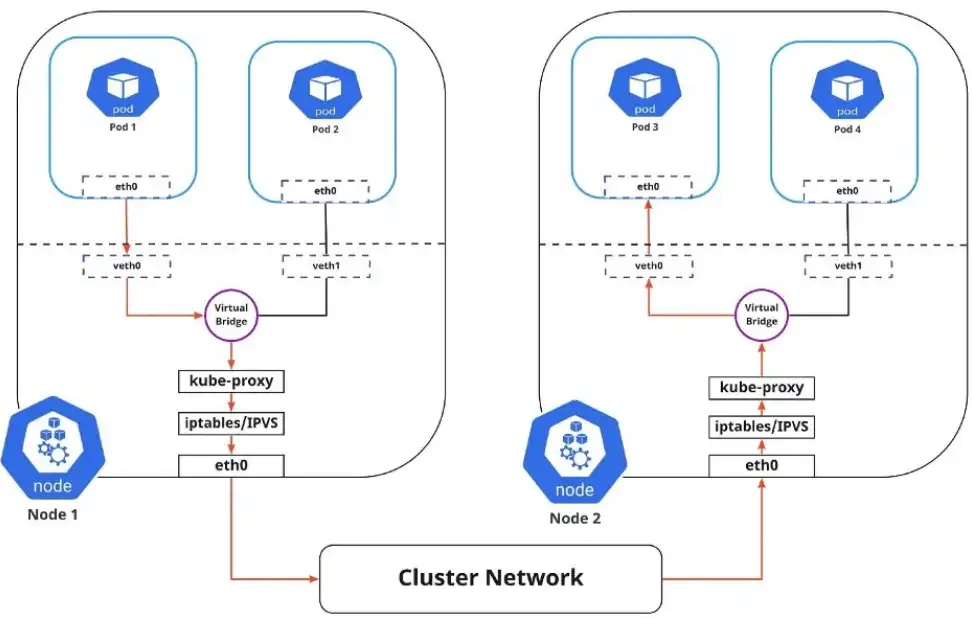
Kubernetes 通过使用 Service 来解决了这个问题:
- \1. 在前端分配一个静态虚拟 IP 地址,以连接与服务service关联的任何后端 Pod
- \2. 将发往此虚拟 IP 的任何流量负载均衡到后端 Pod
- \3. 跟踪 Pod 的 IP 地址,这样即使 Pod IP 地址发生变化,客户端连接到 Pod 也不会有任何问题,因为它们只直接与服务本身的静态虚拟 IP 地址交互
集群内负载均衡具体有两种方式:
IPTABLES:在这种模式下,kube-proxy 会监视 API server中service和endpoint的变化情况 ,对于每个新服务,它都会生成iptables 规则,这些规则捕获到服务的clusterIP 和端口的流量,然后将流量重定向到服务的后端 Pod,Pod 是随机选择的。
iptabels 模式需要维护大量规则,同时kube-proxy 需要不断刷新规则以确保其准确性。当有大量pod时,数百的规则需要不停刷新,会占用大量主机CPU 资源,甚至在此过程中会使主机卡住。
IPVS:IPVS建立在Netfilter之上,实现了传输层负载均衡。IPVS 使用 Netfilter 的钩子函数,使用哈希表作为底层数据结构,并在内核空间中工作。这意味着 IPVS 模式下的 kube-proxy 比 iptables 模式下的 kube-proxy 以更低的延迟、更高的吞吐量和更好的性能重定向流量。
ipvs 并不需要为宿主机上的每个pod设置iptables 规则,类似功能的实现在内核上进行,这将降低维护规则的成本
IPVS技术与Netfilter一样,都是工作在
内核态,且IPVS是基于Netfilter框架实现的,其可以在数据包到达四层协议栈时对数据包进行处理。
IPVS和IPTABLES都是基于netfilter的,两者差别如下:
- • ipvs 为大型集群提供了更好的可扩展性和性能
- • ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
- • ipvs 支持服务器健康检查和连接重试等功能
如果没有加载并启用ipvs模块,或者没有配置ipvs相关配置,则会被降级成iptables模式。
Internet-to-Service 网络模型
到目前为止,我已经讨论了如何在集群内路由流量,不过,Kubernetes 网络还有另一面,那就是将应用程序暴露给外部网络。
Kubernetes service提供了一种访问一组 Pod 的方法,通常使用标签选择器定义。
这可能是尝试访问群集内其他应用程序的应用程序,也可能允许你向外部世界公开群集中运行的应用程序。Kubernetes Service Types使您能够指定所需的服务类型。
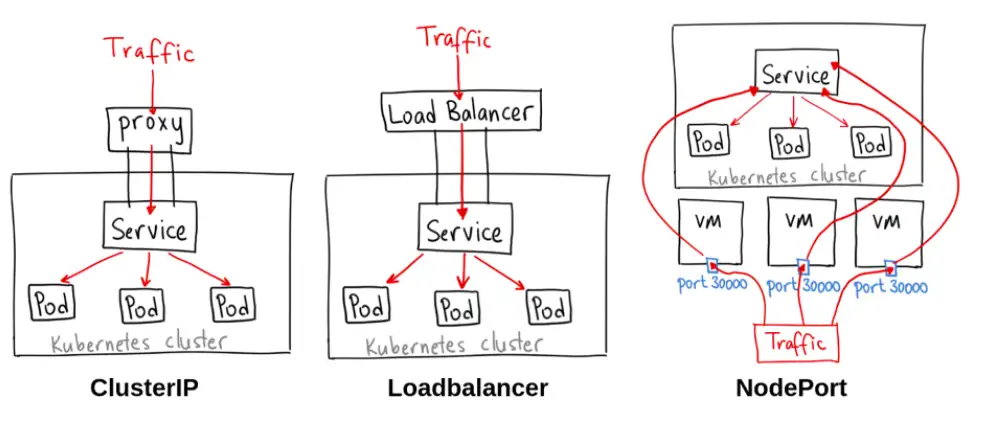
有以下几种ServiceTypes :
- • ClusterIP :这是默认的服务类型。它使服务只能从群集内部访问,并允许群集中的应用程序相互通信,没有外部访问。
- • LoadBalancer: 此服务类型使用云厂商的负载均衡器在外部公开服务,来自外部负载均衡器的流量将定向到后端 Pod。云厂商决定如何对其进行负载均衡,不涉及公有云的情况无需关注
- • NodePort :这允许外部流量通过在所有节点上打开特定端口来访问服务。然后,发送到此端口的任何流量都将转发到服务,此模式会在所有的k8s node上开放对应的端口。
- • ExternalName :这是k8s中一个特殊的service类型,它不需要指定selector去选择哪些pods实例提供服务,而是使用DNS CNAME机制把自己CNAME映射到你指定的另外一个域名上,想当于可以通过DNS域名,访问另外的服务。
引用stackoverflow的回答,补充解释一下ExternalName service:

总结
本文的主要内容就到此为止了,这里再简单总结一下:
- • Kubernetes 使用的是“IP-per-pod”网络模型,每个 Pod 都会有唯一的 IP 地址,所以简单易管理;
- • 网络的事情万变不离其宗,都是层层剥离就是收包过程,容器网络也是如此,也是通过类似路由器、交换机、网卡的组件完成网络的数据包的传输
K8S网络中更细节的内容 CNI(Container Networking Interface)下次有空再聊~!
—–《Kubernetes的 Ingress》—-
服务网关与流量网关
一、为什么需要服务网关
1、什么是服务网关
传统的单体架构中只需要开放一个服务给客户端调用,但是微服务架构中是将一个系统拆分成多个微服务,如果没有网关,客户端只能在本地记录每个微服务的调用地址,当需要调用的微服务数量很多时,它需要了解每个服务的接口,这个工作量很大。那有了网关之后,能够起到怎样的改善呢?
网关作为系统的唯一流量入口,封装内部系统的架构,所有请求都先经过网关,由网关将请求路由到合适的微服务,所以,使用网关的好处在于:
- 简化客户端的工作。 网关将微服务封装起来后,客户端只需同网关交互,而不必调用各个不同服务;
- 降低函数间的耦合度。 一旦服务接口修改,只需修改网关的路由策略,不必修改每个调用该函数的客户端,从而减少了程序间的耦合性
- 解放开发人员把精力专注于业务逻辑的实现。 由网关统一实现服务路由(灰度与ABTest)、负载均衡、访问控制、流控熔断降级等非业务相关功能,而不需要每个服务 API 实现时都去考虑
但是 API 网关也存在不足之处,在微服务这种去中心化的架构中,网关又成了一个中心点或瓶颈点,它增加了一个我们必须开发、部署和维护的高可用组件。正是由于这个原因,在网关设计时必须考虑即使 API 网关宕机也不要影响到服务的调用和运行,所以需要对网关的响应结果有数据缓存能力,通过返回缓存数据或默认数据屏蔽后端服务的失败。
在服务的调用方式上面,网关也有一定的要求,API 网关最好是支持 I/O 异步、同步非阻塞的,如果服务是同步阻塞调用,可以理解为微服务模块之间是没有彻底解耦的,即如果A依赖B提供的API,如果B提供的服务不可用将直接影响到A不可用,除非同步服务调用在API网关层或客户端做了相应的缓存。
因此为了彻底解耦,在微服务调用上更建议选择异步方式进行。而对于 API 网关需要通过底层多个细粒度的 API 组合的场景,推荐采用响应式编程模型进行而不是传统的异步回调方法组合代码,其原因除了采用回调方式导致的代码混乱外,还有就是对于 API 组合本身可能存在并行或先后调用,对于采用回调方式往往很难控制。
2、服务网关的基本功能
3、流量网关与服务网关的区别
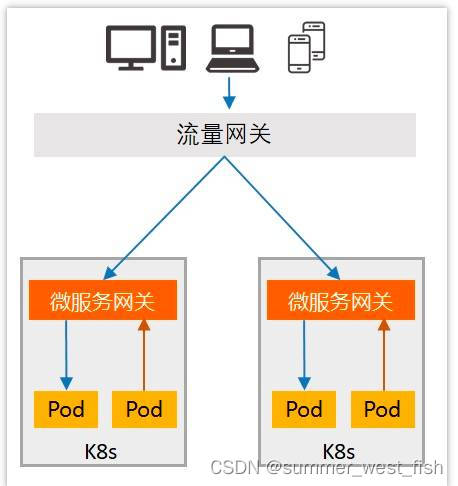
流量网关和服务网关在系统整体架构中所处的位置如上图所示,流量网关(如Nignx)是指提供全局性的、与后端业务应用无关的策略,例如 HTTPS证书卸载、Web防火墙、全局流量监控等。
而微服务网关(如Spring Cloud Gateway)是指与业务紧耦合的、提供单个业务域级别的策略,如服务治理、身份认证等。****也就是说,流量网关负责南北向流量调度及安全防护,微服务网关负责东西向流量调度及服务治理。
二、服务网关的部署
1、主流网关的对比与选型
- Kong 网关 :Kong 的性能非常好,非常适合做流量网关,但是对于复杂系统不建议业务网关用 Kong,主要是工程性方面的考虑
- Zuul1.x 网关 :Zuul 1.0 的落地经验丰富,但是性能差、基于同步阻塞IO,适合中小架构,不适合并发流量高的场景,因为容易产生线程耗尽,导致请求被拒绝的情况
- gateway 网关 :功能强大丰富,性能好,官方基准测试 RPS (每秒请求数)是Zuul的1.6倍,能与 SpringCloud 生态很好兼容,单从流式编程+支持异步上也足以让开发者选择它了。
- Zuul 2.x :性能与 gateway 差不多,基于非阻塞的,支持长连接,但 SpringCloud 没有集成 zuul2 的计划,并且 Netflix 相关组件都宣布进入维护期,前景未知。
综上,gateway 网关更加适合 SpringCloud 项目,而从发展趋势上看,gateway 替代 zuul 也是必然的。
——《Linux 命名空间》——
Linux的命名空间(Namespace)是一种内核特性,用于实现进程之间的隔离。命名空间可以将一组系统资源封装在一个抽象的环境中,使得在不同的命名空间中运行的进程看起来像在独立的系统中运行一样。
Linux提供了以下几种命名空间:
PID命名空间(PID Namespace):隔离进程ID,使得每个命名空间中的进程拥有独立的进程ID空间。
Mount命名空间(Mount Namespace):隔离文件系统挂载点,使得每个命名空间中的进程拥有独立的文件系统视图。
UTS命名空间(UTS Namespace):隔离主机名和域名,使得每个命名空间中的进程拥有独立的主机名和域名。
IPC命名空间(IPC Namespace):隔离System V IPC和POSIX消息队列,使得每个命名空间中的进程拥有独立的进程间通信机制。
Network命名空间(Network Namespace):隔离网络设备、IP地址、路由表、网络命名空间中的进程拥有独立的网络栈。
User命名空间(User Namespace):隔离用户和用户组ID,使得每个命名空间中的进程拥有独立的用户和用户组。
命名空间的工作原理是通过Linux内核提供的clone()系统调用来创建新的命名空间。在创建新的命名空间时,可以选择性地指定要隔离的资源。隔离后,每个命名空间中的进程只能访问和操作自己所属的命名空间中的资源,而无法访问其他命名空间中的资源。
命名空间的分配是由Linux内核进行管理的。每个命名空间都有一个唯一的标识符,称为命名空间ID。命名空间ID是在命名空间创建时由内核分配的,并且在整个系统中是唯一的。
命名空间的应用场景非常广泛。它可以用于容器技术(如Docker)中,实现容器之间的隔离;也可以用于虚拟化技术中,实现虚拟机之间的隔离;还可以用于构建安全的沙箱环境,限制进程的权限和资源访问等。
如果您对命名空间的更详细信息感兴趣,建议参考Linux内核文档或者相关的技术资料。
1 | |