COLA-项目
COLA-项目
COLA 4.0:应用架构的最佳实践_cola4.0_张建飞(Frank)的博客-CSDN博客
主要是项目搭建的架构 :alibaba/COLA: 🥤 COLA: Clean Object-oriented & Layered Architecture (github.com)
《架构》
架构图

1)适配层(Adapter Layer):负责对前端展示(web,wireless,wap)的路由和适配,对于传统B/S系统而言,adapter就相当于MVC中的controller;
2)应用层(Application Layer):主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。层次是开放的,应用层也可以绕过领域层,直接访问基础实施层;
3)领域层(Domain Layer):主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域是应用的核心,不依赖任何其他层次;
4)基础实施层(Infrastructure Layer):主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。此外,领域防腐的重任也落在这里,外部依赖需要通过gateway的转义处理,才能被上面的App层和Domain层使用。
模型

Client 和 防腐层 - RPC
RPC的interface 应该和 service interface差不多,都在client 层定义,然后在 防腐层调用,在 应用层实现
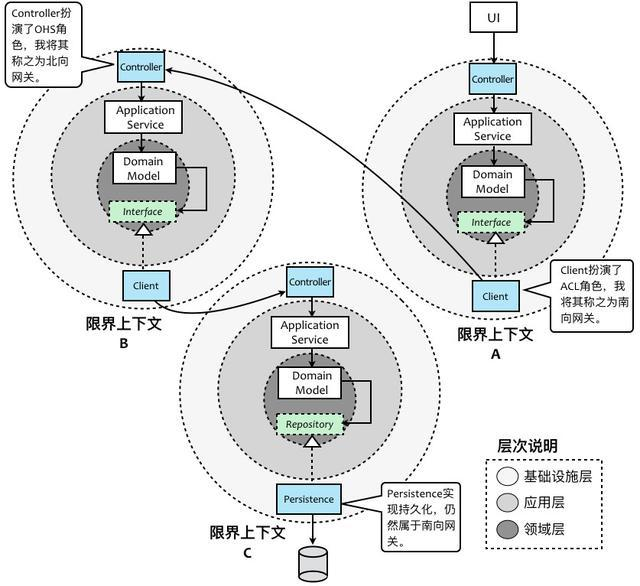
限界上下文 Context A 通过控制器(Controller)为其他上下文暴露 REST 服务,而在 Context A内部呢?则调用的自己的应用层的应用服务(Application Service),然后再调用领域层的领域模型(Domain Model)。
倘若限界上下文 B 需要访问限界上下文A 的rest 服务,由基础设施层的客户端( 如 Feign Client)完成,这个客户端就是上下文映射模式的防腐层ACL。而在 Context B内部呢?实际不会直接调用Feign,则通过放置在领域层的接口(Interface)去完成,接口(Interface)去 调用由基础设施层的客户端( 如 Feign Client),完成真正的访问逻辑实现。
| 层次 | 包名 | 功能 | 必选 | DDD |
|---|---|---|---|---|
| Adapter层 | web | 处理页面请求的Controller | 否 | |
| Adapter层 | wireless | 处理无线端的适配 | 否 | |
| Adapter层 | wap | 处理wap端的适配 | 否 | |
| App层 | executor | 处理request,包括command和query | 是 | 应用服务 |
| App层 | consumer | 处理外部message | 否 | 应用服务 |
| App层 | scheduler | 处理定时任务 | 否 | 应用服务 |
| Domain层 | model | 领域模型 | 否 | Domain |
| Domain层 | ability | 领域能力,包括DomainService | 否 | DomainService |
| Domain层 | gateway | 领域网关,解耦利器 | 是 | Gateway |
| Infra层 | gatewayimpl | 网关实现 | 是 | 领域层实现 |
| Infra层 | mapper | ibatis数据库映射 | 否 | |
| Infra层 | config | 配置信息 | 否 | |
| Client SDK | api | 服务对外透出的API | 是 | |
| Client SDK | dto | 服务对外的DTO | 是 | |
备注:WAP(Wireless Application Protocol)无线应用协议是一个开放式标准协议,利用它可以把网络上的信息传送到移动电话或其他无线通讯终端上
Adapter
适配器层
提供对外访问的 Controller,操作Client
Client
用户接口层
- DTO —- 每一个 command 操作,对应一个DTO (Data Transfer Object)
- Client Object
- xxxCmd – command 对应的DTO
- Domain Event 领域事件对应的DTO
- domain event
- service interface – 应用服务接口(APP 应用层实现)
APP
应用层
- 命令查询职责分离 - CQRS(Command Query Responsibility Segregation)
- service implement – 应用服务
- even handler – 事件处理
Domain
领域层
- 领域模型 (定义、操作 领域模型)
- 实体 - entity
- 聚合
- 领域服务
- Gateway interface 提供访问领域模型的接口 (基础设施实现)
- 领域层 与 应用层 的媒介
- 细致化管理
Gateway interface 到作用- (细致化解耦,减少不合理的依赖)
1 | |
infrastructure
基础设施层
- Data Obejct – 操作数据库
- Gateway implement – 实现领域层 提供接口,
- common
- 事件发布
- 异常处理
单个模块(简单)版本:
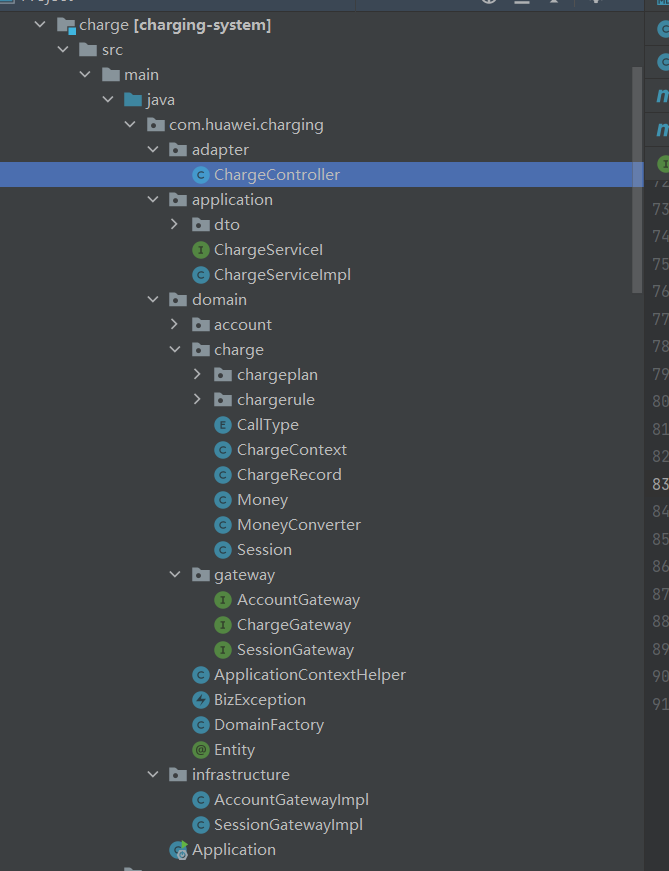
10、代码骨架
用户接口层
用户接口层的核心职能:协议转换和适配、鉴权、参数校验和异常处理。
1 | |
应用层
应用层的核心职能:编排领域服务、事务管理、发布应用事件。
1 | |
领域层
代码组织以聚合为基本单元。
1 | |
基础设施实现层
该层主要提供领域层接口(资源库、防腐层接口)和应用层接口(防腐层接口)的实现。
代码组织基本以聚合为基本单元。对于应用层的防腐层接口,则直接以 application 作为包名组织。
1 | |
—————–《设计》—————–—
设计步骤
背景
限界上下文 - BC
领域服务
领域服务和聚合是领域驱动设计(Domain-Driven Design,简称DDD)中的重要概念。下面是一些设计领域服务和聚合的常见原则和方法:
- 领域服务(Domain Service):
- 领域服务是一种无状态的操作,它封装了一些领域相关的业务逻辑,但不属于任何特定的实体或值对象。
- 领域服务应该具有高内聚性,即它应该关注于一个明确的业务功能或操作。
- 领域服务应该遵循单一职责原则,即每个服务应该只负责一个明确的任务。
- 领域服务可以通过接口或抽象类定义,并由具体的实现类来实现。
- 聚合(Aggregate):
- 聚合是一组相关的领域对象的集合,它们一起形成了一个有边界的整体。
- 聚合应该有一个根实体(Aggregate Root),它是聚合的入口点,负责协调和管理聚合内的其他对象。
- 聚合内的对象应该通过聚合根来访问和操作,外部对象只能通过聚合根来访问聚合内的对象。
- 聚合应该保持一致性和完整性,即聚合内的对象应该满足一定的业务规则和约束。
在设计领域服务和聚合时,可以遵循以下步骤:
- 确定业务需求和业务边界:了解业务需求,确定领域中的业务边界和职责。
- 识别领域对象和关系:识别领域中的实体、值对象和聚合,并确定它们之间的关系和依赖。
- 设计领域服务:根据业务需求,设计领域服务来封装和处理领域相关的业务逻辑。
- 设计聚合:根据业务边界和职责,设计聚合来组织和管理领域对象,并确保聚合的一致性和完整性。
- 实现和测试:根据设计,实现领域服务和聚合,并进行测试和验证。
需要注意的是,设计领域服务和聚合是一个迭代的过程,需要不断地进行反馈和调整。在实践中,可以结合领域驱动设计的其他概念和模式,如实体、值对象、领域事件等,来更好地设计和实现领域服务和聚合。
如果您需要更详细的信息,可以使用以下查询词进行搜索:领域服务和聚合设计。
如果您有任何其他问题,请随时提问。


搜索


—–《COLA 4.0:应用架构的最佳实践》—–
应用架构的本质
什么是架构?十个人可能有十个回答,架构在技术的语境下,就和架构师一样魔幻。我曾经看过一本技术书,用了一章的篇幅讨论架构的定义,最终也没有说明白。
实际上,定义架构也没那么难,如下图所示,架构的本质,简单来说,就是要素结构。所谓的要素(Components)是指架构中的主要元素,结构是指要素之间的相互关系(Relationship)。
例如组织架构,其要素是什么?组成组织的要素当然是人,结构呢?结构是人与人之间的关系。因此,组织架构就是关于定义人的职责划分,以及人与人之间协作关系的一种设计方法。
同样,对于应用架构而言,代码是其核心组成要素,结构就是这些代码该如何被组织,也就是要如何处理模块(Module)、组件(Component)、包(Package)和类(Class)之间的关系。简而言之,应用架构就是要解决代码要如何被组织的问题。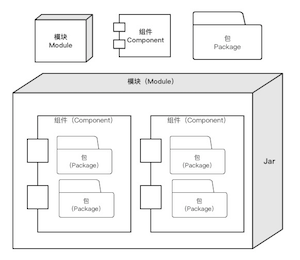
一个没有架构的应用系统,就像一堆随意堆放、杂乱无章的玩具,只有熵值,没有熵减。而一个有良好架构的应用系统,有章法、有结构,一切都显得紧紧有条。
好的组织架构会遵循一定的架构模式,大部分的组织都会按职能和业务来设计自己的架构。如果你反其道而行之,硬要把销售、财务和技术人员放在一个部门,就会显得很奇怪。
同样,好的应用架构,也遵循一些共同模式,不管是六边形架构、洋葱圈架构、整洁架构、还是COLA架构,都提倡以业务为核心,解耦外部依赖,分离业务复杂度和技术复杂度。
应用架构的本质,就是要从繁杂的业务系统中提炼出共性,找到解决业务问题的最佳共同模式,为开发人员提供统一的认知,治理混乱。帮助应用系统“从混乱到有序”,COLA架构就是为此而生,其核心职责就是定义良好的应用结构,提供最佳实践。
COLA 架构
自从COLA诞生以来,已经被使用在很多的业务系统里面,有CRM的业务,有电商的业务,有物流的业务,有外卖业务,有排课系统… COLA作为应用架构,有一定的普适性,是因为业务问题都有一定的共性。例如,典型的业务系统都需要:
- 接收request,响应response;
- 做业务逻辑处理,像校验参数,状态流转,业务计算等等;
- 和外部系统有联动,像数据库,微服务,搜索引擎等;
正是有这样的共性存在,才会有很多普适的架构思想出现,比如分层架构、六边形架构、洋葱圈架构、整洁架构(Clean Architecture)、DDD架构等等。
这些应用架构思想虽然很好,但我们很多同学还是“不讲Co德,明白了很多道理,可还是过不好这一生”。问题就在于缺乏实践和指导。COLA的意义就在于,他不仅是思想,还提供了可落地的实践。应该是为数不多的应用架构层面的开源软件。
分层结构
假如你是一个公司的CTO要管100号人,你怎么管?按照管理学的定义,一个人的管理幅度如果超过10个,管理就会变得很困难。因此,管100号人,你可以把他们分成10个小组,这样你管理10个小组长就好了。
所有的复杂系统都会呈现出层级结构,管理如此,软件设计也不例外,你能想象如果网络协议不是四层,而是一层,意味着,你要在应用层去处理链路层的bit数据流会是怎样的情景吗?同样,应用系统处理复杂业务逻辑也应该是分层的,下层对上层屏蔽处理细节,每一层各司其职,分离关注点,而不是一个ServiceImpl解决所有问题。
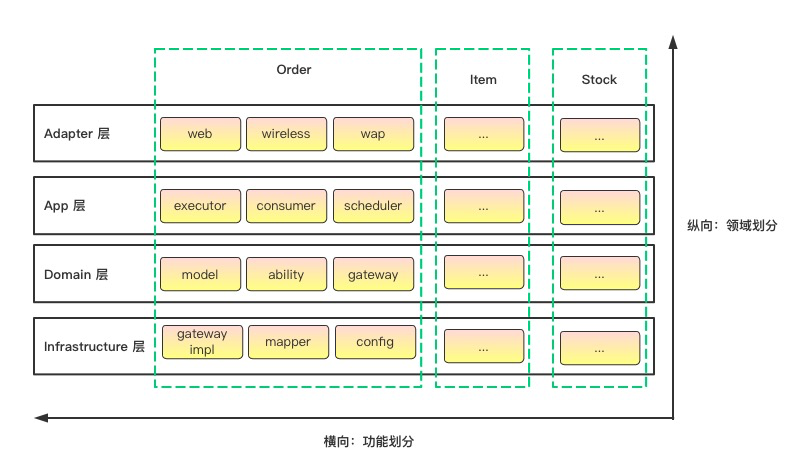
对于一个典型的业务应用系统来说,COLA会做如下层次定义,每一层都有明确的职责定义:
1)适配层(Adapter Layer):负责对前端展示(web,wireless,wap)的路由和适配,对于传统B/S系统而言,adapter就相当于MVC中的controller;
2)应用层(Application Layer):主要负责获取输入,组装上下文,参数校验,调用领域层做业务处理,如果需要的话,发送消息通知等。层次是开放的,应用层也可以绕过领域层,直接访问基础实施层;
3)领域层(Domain Layer):主要是封装了核心业务逻辑,并通过领域服务(Domain Service)和领域对象(Domain Entity)的方法对App层提供业务实体和业务逻辑计算。领域是应用的核心,不依赖任何其他层次;
4)基础实施层(Infrastructure Layer):主要负责技术细节问题的处理,比如数据库的CRUD、搜索引擎、文件系统、分布式服务的RPC等。此外,领域防腐的重任也落在这里,外部依赖需要通过gateway的转义处理,才能被上面的App层和Domain层使用。
包结构
分层是属于大粒度的职责划分,太粗,我们有必要往下再down一层,细化到包结构的粒度,才能更好的指导我们的工作。
还是拿一堆玩具举例子,分层类似于拿来了一个架子,分包类似于在每一层架子上又放置了多个收纳盒。所谓的内聚,就是把功能类似的玩具放在一个盒子里,这样可以让应用结构清晰,极大的降低系统的认知成本和维护成本。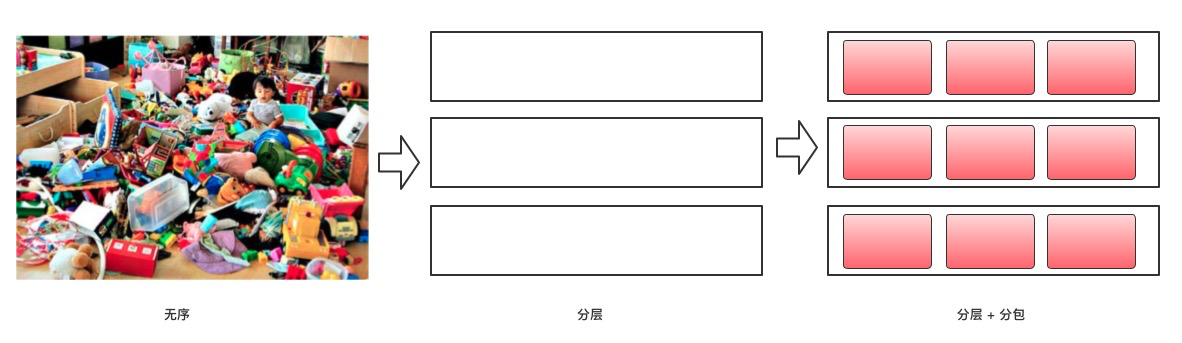
那么,对于一个后端应用来说,应该需要哪些收纳盒呢?这一块的设计真可谓是费了老鼻子劲了,基本上每一次COLA的迭代都会涉及到包结构的调整,迭代到现在,才算基本稳定下来。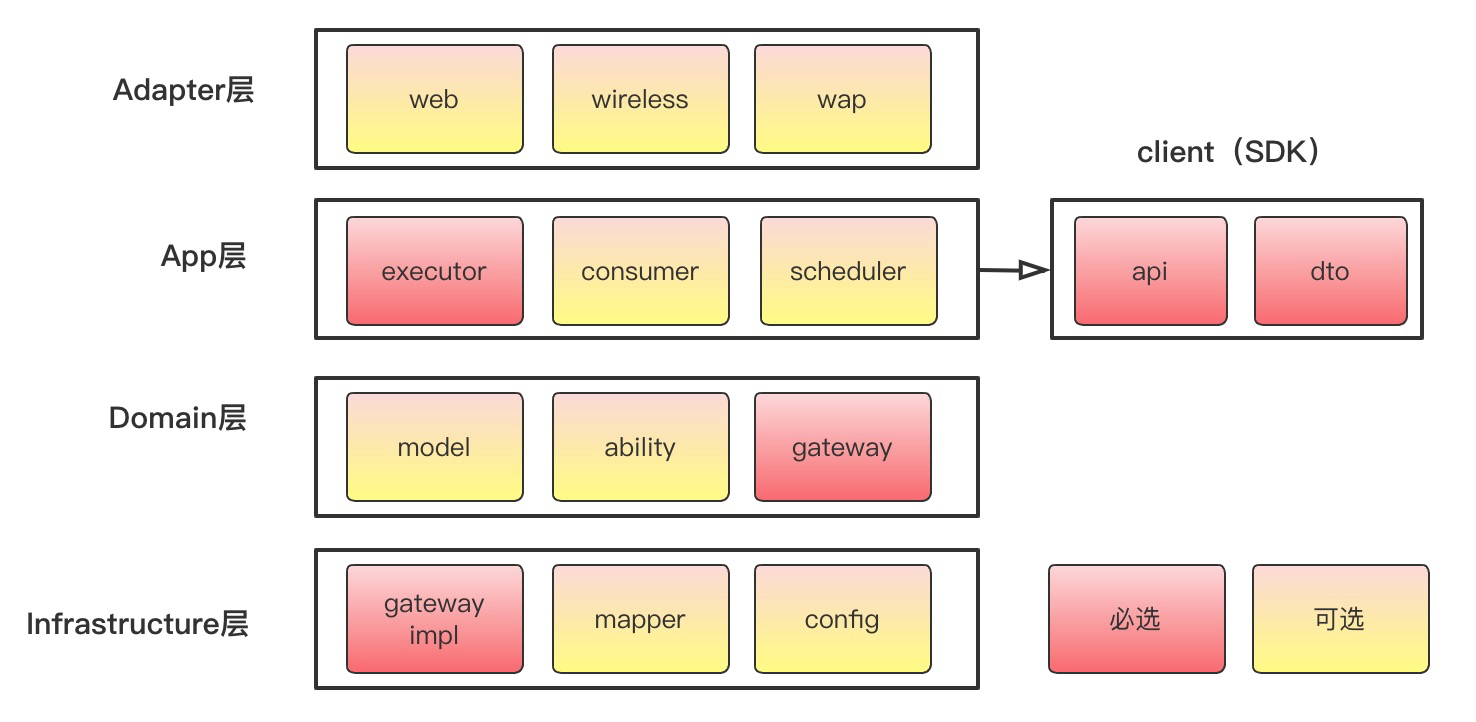
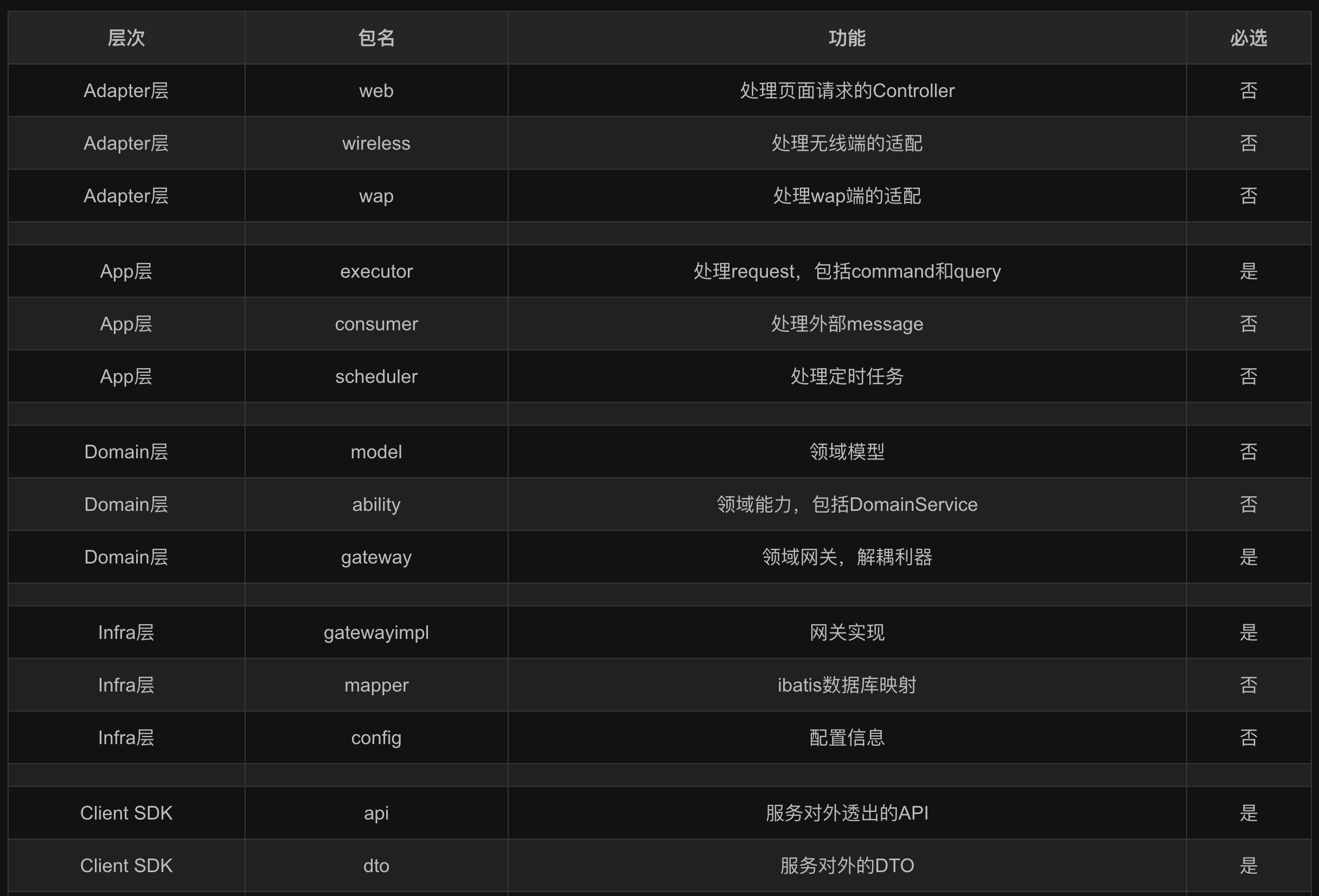
各个包结构的简要功能描述,如下表所示:
| 层次 | 包名 | 功能 | 必选 |
|---|---|---|---|
| Adapter层 | web | 处理页面请求的Controller | 否 |
| Adapter层 | wireless | 处理无线端的适配 | 否 |
| Adapter层 | wap | 处理wap端的适配 | 否 |
| App层 | executor | 处理request,包括command和query | 是 |
| App层 | consumer | 处理外部message | 否 |
| App层 | scheduler | 处理定时任务 | 否 |
| Domain层 | model | 领域模型 | 否 |
| Domain层 | ability | 领域能力,包括DomainService | 否 |
| Domain层 | gateway | 领域网关,解耦利器 | 是 |
| Infra层 | gatewayimpl | 网关实现 | 是 |
| Infra层 | mapper | ibatis数据库映射 | 否 |
| Infra层 | config | 配置信息 | 否 |
| Client SDK | api | 服务对外透出的API | 是 |
| Client SDK | dto | 服务对外的DTO | 是 |
你可能会有疑问,为什么Domain的model是可选的?因为COLA是应用架构,不是DDD架构。在工作中,很多同学问我领域模型要怎么设计,我的回答通常是:无有必要勿增实体。领域模型对设计能力要求很高,没把握用好,一个错误的抽象还不如不抽象,宁可不要用,也不要滥用,不要为了DDD而DDD。
问题的关键是要看,新增的模型没有给你带来收益。比如有没有帮助系统解耦,有没有提升业务语义表达能力的提升,有没有提升系统的可维护性和可测性等等。
模型虽然可选,但DDD的思想是一定要去学习和贯彻的,特别是统一语言、边界上下文、防腐层的思想,值得深入学习,仔细体会。实际上,COLA里面的很多设计思想都来自于DDD。其中就包括领域包的设计。
前面的包定义,都是功能维度的定义。为了兼顾领域维度的内聚性,我们有必要对包结构进行一下微调,即顶层包结构应该是按照领域划分,让领域内聚。
也就是说,我们要综合考虑功能和领域两个维度包结构定义。按照领域和功能两个维度分包策略,最后呈现出来的,是如下图所示的顶层包节点是领域名称,领域之下,再按功能划分包结构。
例如,在我们刚刚上线的一个云店铺(cloudstore)项目中,按照COLA的分包策略,我们在每一个module下面首先按照领域做一个顶层划分,然后在领域内,再按照功能进行分包。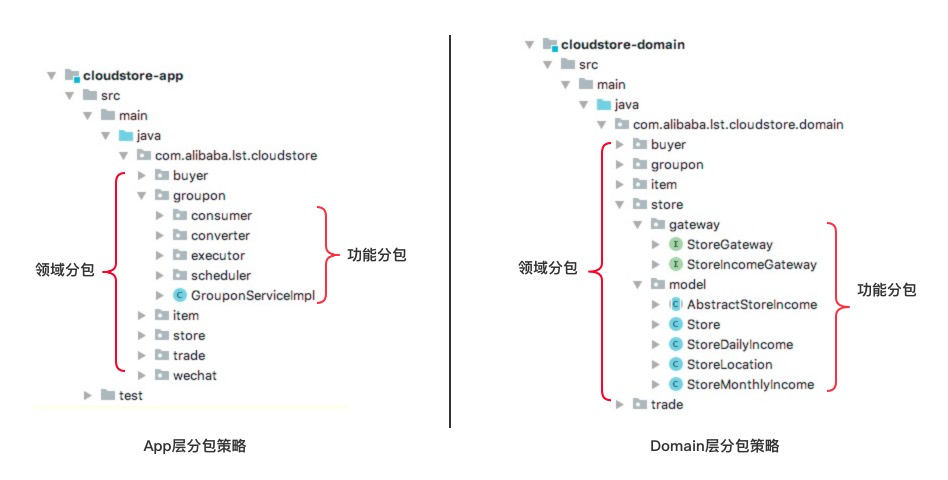
解耦
“高内聚,低耦合”这句话,你工作的越久,就越会觉得其有道理。
所谓耦合就是联系的紧密程度,只要有依赖就会有耦合,不管是进程内的依赖,还是跨进程的RPC依赖,都会产生耦合。依赖不可消除,同样,耦合也不可避免。我们所能做的不是消除耦合,而是把耦合降低到可以接受的程度。在软件设计中,有大量的设计模式,设计原则都是为了解耦这一目的。
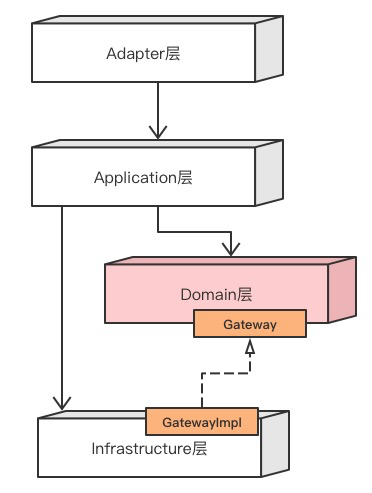
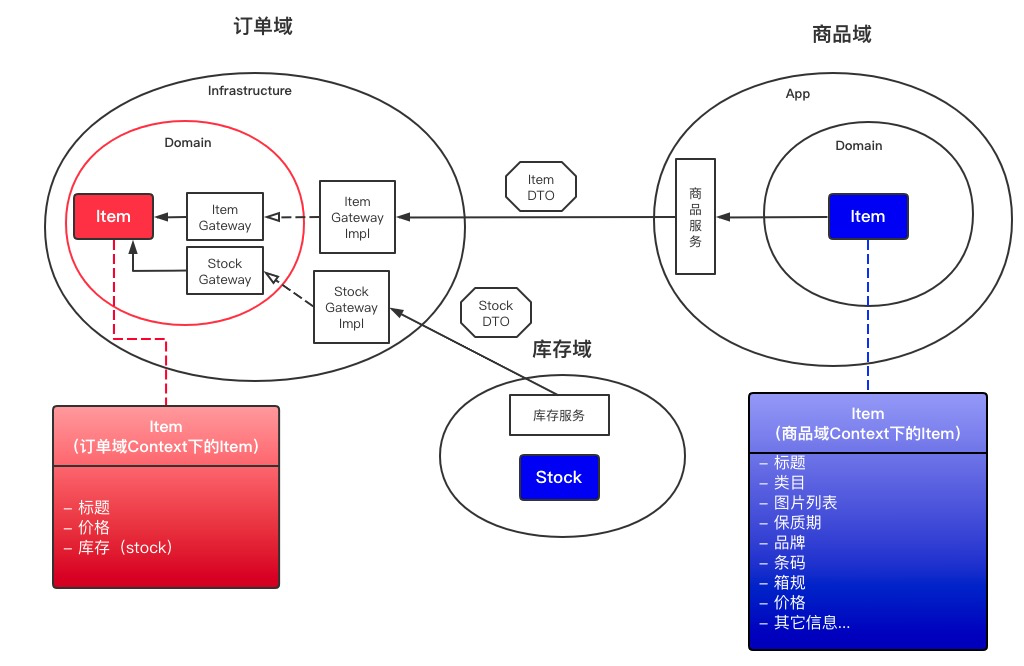
在DDD中有一个很棒的解耦设计思想——防腐层(Anti-Corruption),简单说,就是应用不要直接依赖外域的信息,要把外域的信息转换成自己领域上下文(Context)的实体再去使用,从而实现本域和外部依赖的解耦。
在COLA中,我们把AC这个概念进行了泛化,将数据库、搜索引擎等数据存储都列为外部依赖的范畴。利用依赖倒置,统一使用gateway来实现业务领域和外部依赖的解耦。
其实现方式如下图所示,主要是在Domain层定义Gateway接口,然后在Infrastructure提供Gateway接口的实现。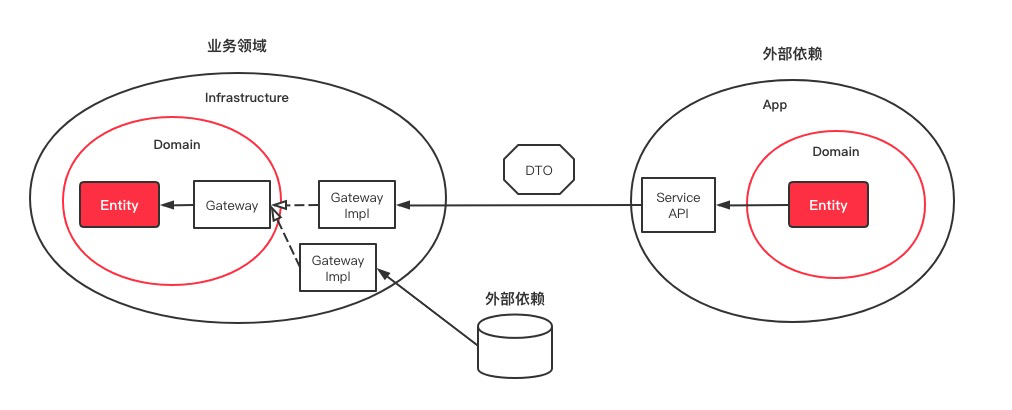
举个例子,假如有一个电商系统,对于下单这个操作,它需要联动订单服务、商品服务、库存服务、营销服务等多个系统才能完成。
那么在订单域,该如何获取商品和库存信息呢?最直接的方式,无外乎就是RPC调用商品和库存服务,拿到DTO直接使用就完了。
然而,商品域吐出的是一个大而全的DTO(可能包含几十个字段),而在下单这个阶段,订单所需要的可能只是其中几个字段而已。更合适的做法,应该是在订单域中,使用gateway对商品域和库存域的依赖进行解耦。
这样做有两个好处,一个是降低了对外域信息依赖的耦合;另一个是通过上下文映射(Context mapping),确保本领域边界上下文(Bounded context)下领域知识的完整性,实现了统一语言(Ubiquitous language)。
COLA Archetype
以上就是COLA架构的核心内容了。然而这么多module,这么多package,如果要手动去创建的话,是非常繁琐和费时的。为了能够快速创建满足COLA架构的应用,我创建了两个Maven Archetype。
- 一个是用来创建纯后端服务的archetype:cola-archetype-service。
- 一个是用来创建adapter和后端服务一体的web应用archetype:cola-archetype-web。
另外,你也可以使用阿里云的应用生成器去生成一个COLA应用,只是那边的版本没有同步更新,可能会老旧一点。
COLA组件
使用过老版本COLA的同学,应该知道,COLA除了架构之外,还提供了一些框架级别的功能,比如拦截器功能,扩展点功能等。
之前,这种框架功能和架构混淆在一起,会让人以为使用COLA,就必须要使用这些功能。实际上二者是可以分开使用的,也就是说,你可以单纯的使用COLA架构,而不使用任何COLA组件提供的功能也是完全没问题的。
当然,我还是强烈推荐你可以有选择的使用这些COLA组件,毕竟这些组件都是我们在实际工作中的总结沉淀,其复用性和价值是被反复验证过的。
为了方便管理,以及更清晰的把架构和框架区分开来。在此次COLA 4.0的升级中,我把这些功能组件全部收拢到了cola-components下面。到目前为止,我们已经沉淀了以下组件:
| 组件名称 | 功能 | 版本 | 依赖 |
|---|---|---|---|
| cola-component-dto | 定义了DTO格式,包括分页 | 1.0.0 | 无 |
| cola-component-exception | 定义了异常格式, 主要有BizException和SysException | 1.0.0 | 无 |
| cola-component-statemachine | 状态机组件 | 1.0.0 | 无 |
| cola-component-domain-starter | Spring托管的领域实体组件 | 1.0.0 | 无 |
| cola-component-catchlog-starter | 异常处理和日志组件 | 1.0.0 | exception ,dto组件 |
| cola-component-extension-starter | 扩展点组件 | 1.0.0 | 无 |
| cola-component-test-container | 测试容器组件 | 1.0.0 | 无 |
这些组件是一个良好的开端,我相信,在未来会有更多有用的组件加入。当然,作为一个开源项目,如果你有好的组件idea,欢迎你随时为这个组件库添砖加瓦。
COLA 4.0
总结一下,在本次COLA升级中,我们进一步明确了架构和框架功能的定义。升级之后,如下图所示,COLA会被分成COLA架构和COLA组件两个部分:
- COLA架构:关注应用架构的定义和构建,提升应用质量。
- COLA组件:提供应用开发所需要的可复用组件,提升研发效率。
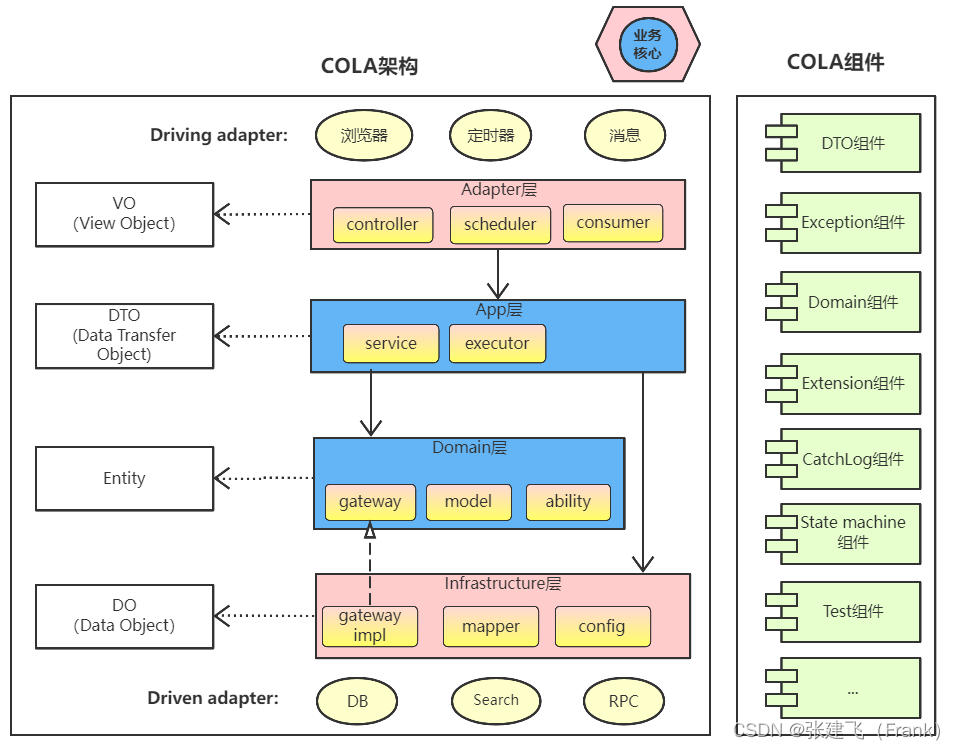
COLA 开源地址: https://github.com/alibaba/COLA
你可以按照以下步骤去使用COLA:
** 第一步:安装 cola archetype **
下载cola-archetypes下的源码到本地,然后本地运行mvn install安装。
** 第二步:安装 cola components **
下载cola-components下的源码到本地,然后本地运行mvn install安装。
** 第三步:创建应用 **
执行以下命令:
1 | |
命令执行成功的话,会看到如下的应用代码结构: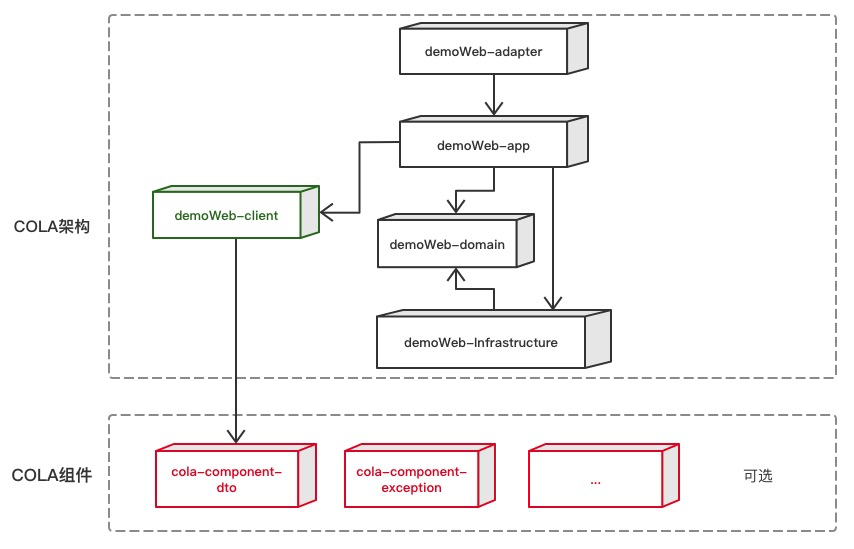
** 第四步:运行应用 **
首先在demoWeb目录下运行mvn install(如果不想运行测试,可以加上-DskipTests参数)。然后进入start目录,执行mvn spring-boot:run。
运行成功的话,可以看到SpringBoot启动成功的界面。
生成的应用中,已经实现了一个简单的Rest请求,可以在浏览器中输入 http://localhost:8080/helloworld 进行测试。