《Ashiamd的个人MD笔记》
备注:主要是为了方便后续本地阅读,将@Ashiamd 大佬的笔记复制了一下
视频 + 翻译
课程视频 :学习
课程翻译 : 通过类似于文本的方式学习
《Ashiamd的个人MD笔记》
Notes: docsify-notes- By Ashiamd
Resporitory: Github仓库地址
MIT6.824网课学习笔记-01
【MIT 6.824】学习笔记 1: MapReduce (qq.com) <= 2021版网络大佬的笔记
简介 - MIT6.824 (gitbook.io) <= 知乎大佬的gitbook完整笔记(2020版,我这里看的网课是2021版),推荐也阅读一遍2020版课程的大佬笔记
6.824 <= 课程表
Lecture1 概述(Introduction)
1.1 分布式系统-简述
非正式的定义,这里认为几个只能通过网络发送/接收数据包进行交互的系统,即构成分布式系统。
使用分布式系统的场景/原因:
- 机器资源共享 (sharing)
- 通过并行提高性能 (increase capacity though parallelism)
- 提高服务容错性 (tolerate faults)
- 利用物理隔离的手段提高整体服务安全性 (achieve security via isolation)
1.2 分布式系统-历史发展
- 局域网分布式系统的服务 (1980s)
- 互联网规模的分布式系统,比如DNS(域名服务系统)、email
- 数据中心 (Data center),伴随大型网站而生 (1990s)
- 常见的有网页搜索(爬虫实现,然后需要建立大量倒排索引)
- 商城购物系统(海量商品、订单、用户信息等数据)
- 云计算 (Cloud computing) (2000s)
- 本地运算/本地运行应用,转移到云服务上运算/运行应用
- 如今也是研究和发展的热点话题
1.3 分布式系统-难点
网络分区:
[Network Partition_百度百科 (baidu.com)](https://baike.baidu.com/item/Network Partition/8720737?fr=aladdin)
那么对于一个n个节点组成的网络来说,如果n 个节点可以被分为k个不相交且覆盖的group, 每个group内所有节点全是两两正常连接,而任意两个group之间的任何节点无连接。当k=1 时,网络正常,当k > 1 时,我们称之为network partition。
《RabbitMQ实战指南》整理(七)网络分区 - Jscroop - 博客园 (cnblogs.com)
RabbitMQ集群内两两节点之间会有信息交互,如果某节点出现网络故障或是端口不同,则会使与此节点的交互出现中断,经过超时判定后,会判定网络分区。网络分区的判断与net_ticktime参数息息相关,其默认值为60。集群内部每个节点间会每隔四分之一net_ticktime记一次应答,如果任何数据被写入节点中,则此节点会被认为已经被应答了,如果连续4此没有应答,则会判定此节点已下线,其余节点可以将此节点剥离出当前分区。
对于未配置镜像的集群,网络分区发生之后,队列也会随着宿主节点而分散在各自的分区中。对于消息发送方而言,可以成功发送消息,但是会有路由失败的情况,需要配合mandatory等机制保障消息的可靠性,对于消息消费方而言,可能会出现不可预知的现象,比如已消费消息ack会失效。网络分区发生后,客户端与某分区重新建立通信链路,其分区中如果没有相应的队列进程,则会有异常报出。如果从网络分区中恢复,数据不会丢失,但是客户端会重复消费。
对于已镜像的集群,网络分区的发生会引起消息的丢失,解决办法为消息发送端需要具备Basic.Return的能力,其次在检测到网络分区之后,需要迅速地挂起所有生产者进程,之后连接分区中的每个节点消费分区中所有的队列数据,在消费完之后再处理网络分区,最后从网络分区中恢复之后再恢复生产者进程。整个过程可以最大程度上保证网络分区之后的消息的可靠性。需要注意的是整个过程中会有大量的消息重复,消费客户端需要做好相应的幂等性处理。也可以将所有旧集群资源迁移到新集群来解决这个问题。
许多并发场景 (many concurrent part)
需要处理故障/宕机问题 (must deal with partial failure)
尤其是发生网络分区问题 (network partition)
体现性能优势 (realize the performance benefits)
通常任务并非真正所有步骤都并行执行,需要良好的实现才能达到增加机器数就提高吞吐量的效果。
1.4 课程介绍
实验内容:
- Lab1:实现mapreduce
- Lab2:在存在故障和网络分区的情况下,使用raft协议完成复制
- Lab3:通过实验2,复制一个Key-Value存储的服务
- Lab4:构造分片(sharded)的key-value存储服务
1.5 支持分布式系统的底层基础架构
课程不会花大量时间在分布式的应用程序上,而是着重介绍支撑这些分布式应用程序开发的底层基础架构。常见的有:
- Storage,存储基础架构,比如键值服务器、文件系统等
- Computation,计算框架,用来编排或构件分布式应用程序,比如经典的mapreduce
- Comminication,分布式系统逃不开网络通信问题,比如后续会讨论的RPC(远程过程调用)
需要关注的是RPC提供的语义(同时也是分布式系统和通信关联的部分):
- utmost once:最多一次
- exactly once:恰好一次
- at least once:至少一次
对于分布式系统的底层基础架构,我们通常抽象的目标是做到让使用者觉得和单机操作无意,这是非常难实现的。(也就是隐藏分布式中各类难题的具体实现,对外暴露时争取和普通本地串行函数别无二致。)
1.6 分布式系统的3个重要特性
尾部延迟是什么?如何避免尾部延迟? | 程序员技术之旅 (zhangbj.com) <= 简述概念和产生原因
有
1%的请求耗时高于99%的请求耗时,影响用户体验,甚至拖垮服务。
fault tolerance:容错性
- availability:可用性,一般用p999等指标衡量
- 主要依赖replication复制技术
- recoverability:可恢复性,当机器崩溃或故障时,在重启时恢复正常工作状态
- 主要依赖logging or transaction日志或事务一类的技术
- durable storage,需要将数据写入持久化的存储器,便于后续恢复工作
- availability:可用性,一般用p999等指标衡量
consistency:一致性,即多个服务应该提供一致的服务,客户端请求哪个服务端获取的响应需要一致
关于一致性,有很多不同实现方式:
- 强一致性:多个机器执行的行为,就类似串行执行
- 最终一致性:较为宽松,多个行为执行后,只需要保证最后一个行为的结果在多台服务器都得到相同的表现
performance:分布式系统往往希望能比单机系统要具备更高的性能,但是提高性能本身和提供容错性、一致性是冲突的。
性能一般涉及两个指标:
- throughput 吞吐量:目标是吞吐量与部署的机器数成正比
- latency 低延迟:其中一台机器执行慢就会导致整个请求响应慢,这称为尾部延迟(tail latency)
为了达到强一致性,需要不同机器之间的通信,这可能降低性能
为了实现容错,需要从不同机器上复制数据,还需要将数据写入持久化存储器这一昂贵操作
通常要兼顾以上3个特性很难做到,常见的实现要么牺牲一点一致性换取更高的性能;要么牺牲一点容错性换取更好的性能,不同的实现方式有不同的权衡。
1.7 mapreduce-简述
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。 当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
论文的背景是google的两位数据工程师需要处理爬虫数据,建立倒排索引,用于网页搜索。需要几个小时处理TB级别的数据。传统的代码实现,并发执行任务,如果中间一个线程/线程出错,可能整个任务都需要重新执行,所以还需要考虑容错性设计。
程序员通过编写函数式或无状态的map函数和reduce函数的实现,实现分布式数据的处理。mapreduce内部通过其他机制保证执行过程的容错性、分布式通信等问题,对程序员隐藏这些细节。
map-reduce经典举例即统计字母出现的次数,多个进程各自通过map函数统计获取到的数据片段的字母的出现次数;后续再通过reduce函数,汇总聚合map阶段下每个进程对各自负责的数据片段统计的字母出现次数。一旦执行了shuffle,多个reduce函数可以各自只聚合一种字母的出现总次数,彼此之间不干扰。
开销昂贵的部分即shuffle,map的结果经过shuffle按照一定的顺序整理/排序,然后才分发给不同的reduce处理。这里shuffle的操作理论比map、reduce昂贵。
提问:排序操作是否可以通过map-reduce完成
回答:可以,排序在mapreduce中是讨论最多的应用之一,可以通过mapreduce实现。你可以将输入拆分成不同部分,mapper对这些部分进行排序,输出拆分成r个桶,每个reduce对这r个桶进行排序,最后输出完整的文件。
1.8 mapreduce-执行流程

- Master进程,被称为coordinator协调器,负责orchestrate编排wokers,把map jobs分配给它们
- reduce、map被称为task任务
- coordinator协调器将文件分配给特定的workers,worker对分配到的文件调用map函数
- worker将执行map函数产生的中间结果存储到本地磁盘
- worker的map函数执行完毕后并告知master中间结果存储的位置
- 所有worker的map执行完毕后,coordinator协调器分配worker执行reduce函数
- worker记录分配到的map中间结果,获取数据,按key键sort排序,在每个key、values集合上调用reduce函数
- 每个reduce函数执行时产生结果数据,你可以聚合输出文件获取最终结果
输入文件在全局文件系统中,被称为GFS。Google现在使用的是不同的global file system,但该论文中使用的是GFS。
上面流程最后reduce输出结果会被保存到GFS,而map产生的中间文件不会被保存到GFS中(而是保存到worker运行的本地机器上)。
问题:在远程读取进程中,文件是否会传输到reducer?
回答:是的。map函数产生的中间结果存放在执行map函数的worker机器的磁盘上,而之后解调器分配文件给reducer执行reduce函数时,中间结果数据需要通过网络传输到reducer机器上。这里其实很少有网络通信,因为一个worker在一台机器上,而每台机器同时运行着worker进程和GFS进程。worker运行map产生中间结果存储在本地,而之后协调器给worker分配文件以执行reduce函数时,才需要通过网络获取中间结果数据,最后reduce处理完在写入GFS,写入GFS的动作也往往需要通络传输。
问题:协调器是否负责对数据进行分区,并将数据分发到每个worker或机器上?
回答:不是的。mapreduce运行用户程序,这些输入数据在GFS中。(也就是说协调器告知worker从GFS取哪些数据进行map,后续协调器又告知worker从哪些worker机器上获取中间结果数据进行reduce,最后又统一写入到GFS中)
问题:这里涉及的排序是如何工作的?比如谁负责排序,如何排序?
回答:在中间结果数据传递到reduce函数之前,mapreduce库进行一些排序。比如所有的中间结果键a、b、c到一个worker。比如(a,1) (b,1) (c,1) (a,1) 数据,被排序成(a,1) (a,1) (b,1) (c,1) 后才传递给reduce函数。
问题:很多函数式编程是否可以归结为mapreduce问题?
回答:是的。因为map、reduce函数的概念,在函数式编程语言中非常常见,或者说函数式编程真是map、reduce的灵感来源。
1.9 mapreduce-容错性
当coordinator协调器发现worker失败了,会restart重启对应的task任务,并要求worker重新执行原本分配的map或reduce函数。
如果coordinator协调器分配任务后,其管理的worker机器在一定时间内没有响应,协调器就会假设管理的worker机器崩溃了。这意味着如果存在另一个worker正好空闲,它将被分配崩溃的worker原本该执行的任务。这就是fault tolerance容错的基本方案。
换句话说,如果coordinator没有收到worker反馈task任务完成,那么会coordinator重新分配worker要求执行task(可能分配到同一个worker,重点是task会被重新执行)。这里涉及一个问题,map是否会被执行两次?
或许没反馈task执行done完成的worker是遇到网络分区等问题,并没有宕机,或者协调者不能与worker达成网络通信,但实际上worker仍然在运行map任务,它正在产生中间结果。这里的答案是,同一个map可以被运行两次。
被执行两次是能够接受的(幂等性问题),正是map和reduce属于函数式(functional)的原因之一。如果map/reduce是一个funcitonal program,那么使用相同输入运行时,产生的输出会是相同的(也就是保证幂等)。
类似的,reduce能够运行两次吗?是的,和map出于相同的原因,从容错的角度上看,执行reduce函数和map函数并没有太大区别。需要注意的是,这时候可能有两个reducer同时有相同的输出文件需要写入GFS,它们首先在全局文件系统GFS中产生一个中间文件,然后进行atomic rename原子重命名,将文件重命名为实际的最终名称。因为在GFS中执行的重命名是原子操作,最后哪个reducer胜出并不重要,因为reduce是函数式的,它们最终输出的数据都是一样的。
问题:一台机器应该可以执行多个map任务,如果它分配10个map任务,而在执行第7个map任务时失败了,master得知后,会安排将这7个已完成的map任务分布式地重新执行,可能分散到不同的map机器上,对吗?
回答:是的。虽然我认为通常一台机器只运行一个map函数或一个reduce函数,而不是多个。
问题:在worker完成map任务后,它是否会直接将文件写入其他机器可见的位置,或者只是将文件保存到自己的文件系统中?
回答:map函数总是在本地磁盘产生结果,所以中间结果文件只会在本地文件系统中。
问题:即使一次只做一个map任务,但是如果执行了多次map任务后,如果机器突然崩溃,那么会丢失之前负责的所有map任务所产生的中间结果文件,对吗?
回答:不,中间结果文件放在文件系统中。所以当机器恢复时,中间结果文件还在那里,因为文件数据是被持久化保存的,而不是只会存在于内存中(换句话说,这里依赖了操作系统的文件系统本身的容错性)。并且map或reduce会直接访问包含intermediate results中间结果的机器。
1.10 mapreduce-其他异常场景
协调器会失败吗(Coordinator fail)?
不会。协调器不允许失败。如果协调器真的失败了,整个job(包含具体的多个map、reduce步骤task)需要重新运行。在这篇论文中,没有谈论到协调器失败后他们的应对方式。
(协调器不允许失败)这使得容错性很难做得更高,因为它维护一些工作状态(每个map、reduce函数执行的状态),在论文的库中,协调器不能失败。
后面会谈论一些技术手段,可以实现协调器容错,他们可以这么做却不打算,原因是他们认为比起协调器,运行map函数的上千个机器中崩溃一台的概率更高(也就是收益和成本不成正比,所以暂时没有实现协调器容错的打算)。
执行缓慢的worker(Slow workers)?
比如GFS也在同一台机器上运行占用大量的机器周期或带宽,或硬件本身问题,导致worker执行map/reduce很慢。慢的worker被称为straggler,当剩下几个map/reduce任务没有执行时,协调者会另外分配相同的map/reduce任务到其他闲置worker上运行,达到backup task的效果(因为函数式,map/reduce以相同输入执行最后会产生相同输出,所以执行多少次都不会有问题)。
通过backup task,性能不会受限于最慢的几个worker,因为有更快的worker会领先它们完成task(map或reduce)。这是应对straggler的普遍做法,通过replicate tasks复制任务,获取更快完成task的输出结果,处理了tail latency尾部延迟问题。
Lecture2 远程过程调用和多线程(RPC and Threads)
2.1 选用go语言的原因
这里主要讲为什么这个课程选用Go语言进行编程。
- good support for threads/RPC:对线程和RPC的支持度高
- gc:自带GC,无需考虑垃圾回收问题
- type safe:类型安全
- simple:简单易上手
- compiled:编译型语言,运行时开销更低
2.2 线程Thread of exeution
在Go中,线程成为goroutine,也有人称其为线程的线程(a thread of thread)。每个线程都有自己的PC程序计数器、函数调用栈Stack、一套寄存器Registers。
1 | |
- start/go:启动/运行一个线程
- exit:线程退出,一般从某个函数退出/结束执行后,会自动隐式退出
- stop:停止一个线程,比如向一个没有读者的channel写数据,那么channel阻塞,go可能会运行时暂时停止这个线程
- resume:恢复原本停止的线程重新执行,需要恢复程序计数器(program counter)、栈指针(stack pointer)、寄存器(register)状态,让处理器继续运行该线程。
2.3 为什么需要多线程
- express concurrency:依靠多线程达到并发效果
- I/O concurrency:I/O并发
- multi-core parallelism:多核并行,提高整体吞吐量
- convinience:方便,经常有需要异步执行or定时执行的任务,可以通过线程完成
2.4 多线程的挑战
- race conditions:多线程会引入竞态条件的场景
- avoid sharing:避免共享内存以防止竞态条件场景的产生(Go有一个竞态检测器race detector,能够辅助识别代码中的一些竞态条件场景)
- use locks:让一系列指令变成原子操作
- coordination:同步协调问题,比如一个线程的执行依赖另一个线程的执行结果等
- channels:通道允许同时通信和协调
- condition variables:配合互斥锁使用
- deadlock:死锁问题,比如在go中简单的死锁场景,一个写线程往channel写数据,但是永远没有读线程从channel读数据,那么写线程被永久阻塞,即死锁,go会抓住这种场景,抛出运行时错误runtime error。
2.5 go如何应对多线程挑战
1 | |
- channels:通道
- no-sharing场景:如果线程间不需要共享内存(变量等),一般偏向于使用channels完成线程间的通信
- locks + condition variables:锁和条件变量配套使用
- shared-memory:如果线程间需要共享内存,则采用锁+条件变量的方案。比如键值对key-value服务,需要共享key-value table。
2.6 go多线程代码示例
逃逸分析:
先聊聊Go的「堆栈」,再聊聊Go的「逃逸分析」。 - 知乎 (zhihu.com) <= 简单明了,推荐阅读。还有具体的代码举例分析
相比于把内存分配到堆中,分配到栈中优势更明显。Go语言也是这么做的:Go编译器会尽可能将变量分配到到栈上。但是,当编译器无法证明函数返回的变量有没有被引用时,编译器就必须在堆上分配该变量,以此避免悬挂指针(dangling pointer)的问题。另外,如果局部变量占用内存非常大,也会将其分配在堆上。
编译器通过逃逸分析技术去选择堆或者栈,逃逸分析的基本思想如下:
- 检查变量的生命周期是否是完全可知的,如果通过检查,则在栈上分配
- 否则,就是所谓的逃逸,必须在堆上进行分配
Go语言虽然没有明确说明逃逸分析原则,但是有以下几点准则,是可以参考的。
- 不同于JAVA JVM的运行时逃逸分析,Go的逃逸分析是在编译期完成的:编译期无法确定的参数类型必定放到堆中;
- 如果变量在函数外部存在引用,则必定放在堆中;
- 如果变量占用内存较大时,则优先放到堆中;
- 如果变量在函数外部没有引用,则优先放到栈中;
tcmalloc全称Thread-Caching Malloc,即线程缓存的malloc,实现了高效的多线程内存管理,用于替代系统的内存分配相关的函数(malloc、free,new,new[]等)。
Java逃逸分析 - JaxYoun - 博客园 (cnblogs.com) <= 推荐阅读
在计算机语言编译器优化原理中,逃逸分析是指分析指针动态范围的方法,它同编译器优化原理的指针分析和外形分析相关联。当变量(或者对象)在方法中分配后,其指针有可能被返回或者被全局引用,这样就会被其他方法或者线程所引用,这种现象称作指针(或者引用)的逃逸(Escape)。通俗点讲,如果一个对象的指针被多个方法或者线程引用时,那么我们就称这个对象的指针(或对象)的逃逸(Escape)。
- 方法逃逸:在一个方法体内,定义一个局部变量,而它可能被外部方法引用,比如作为调用参数传递给方法,或作为对象直接返回。或者,可以理解成对象跳出了方法。
- 线程逃逸:这个对象被其他线程访问到,比如赋值给了实例变量,并被其他线程访问到了。对象逃出了当前线程。
如果一个对象不会在方法体内,或线程内发生逃逸(或者说是通过逃逸分析后,认定其未能发生逃逸),就可以做如下优化:
- 栈上分配: 一般情况下,不会逃逸的对象所占空间比较大,如果能使用栈上的空间,那么大量的对象将随方法的结束而销毁,减轻了GC压力
- 同步消除: 如果你定义的类的方法上有同步锁,但在运行时,却只有一个线程在访问,此时逃逸分析后的机器码,会去掉同步锁运行。
- 标量替换: Java虚拟机中的原始数据类型(int,long等数值类型以及reference类型等)都不能再进一步分解,它们可以称为标量。相对的,如果一个数据可以继续分解,那它称为聚合量,Java中最典型的聚合量是对象。如果逃逸分析证明一个对象不会被外部访问,并且这个对象是可分解的,那程序真正执行的时候将可能不创建这个对象,而改为直接创建它的若干个被这个方法使用到的成员变量来代替。拆散后的变量便可以被单独分析与优化,属性被扁平化后可以不用再通过引用指针来建立关系,可以连续紧凑的存储,对各种存储都更友好,执行期间能省去大量由于数据搬运造成性能损耗。同时还可以各自分别在栈帧或寄存器上分配空间,原本的对象就无需整体分配空间了。
深入理解JVM逃逸分析_wh柒八九的博客-CSDN博客 <= 推荐阅读,带有代码示例。
go语言的channel:
Go 语言中的带有缓冲 Channel(Let‘s Go 三十一)_带缓冲的channel_甄齐才的博客-CSDN博客
无缓冲信道 Channel 是无法保存任何值的,该类型信道要求 发送 goroutine 和 接受 goroutine 两者同时准备好,这样才能完成发送与接受的操作。假使 两者 goroutine 未能同时准备好,信道便会先执行 发送 和 接受 的操作, goroutine 会阻塞等待。这种对信道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
带缓冲信道在很多特性上和无缓冲信道是类似的。无缓冲信道可以看作是长度永远为 0 的带缓冲信道。因此根据这个特性,带缓冲信道在下面列举的情况下依然会发生阻塞:
- 带缓冲信道被填满时,尝试再次发送数据时发生阻塞。
- 带缓冲信道为空时,尝试接收数据时发生阻塞。
首先是一个模拟投票选举的go程序。
1 | |
通过执行go run -race vote-count-1.go用go自带的工具检测出竞态条件场景。这里很明显新建的多个goroutine共享了变量count、finished,构成竞态条件场景。
一种解决方法,仅使用锁。涉及修改的代码片段如下:
1 | |
对于下面主线程CPU空转等待其他线程结果的逻辑,可以增加sleep等待,但是坏处是这里该休眠多久并不好把控。
1 | |
另一种解决竞态条件的方法,使用锁和条件变量,代码修改如下:
1 | |
当然,还可以用通道channel实现:
1 | |
问题:看起来上面匿名函数可以访问函数外定义的变量,那么作用域是如何工作的?
回答:如果匿名函数使用的不是函数内声明的变量,那么会指向外部作用于的变量,这里即静态作用域。
追问:上面的go执行的匿名函数启动的线程中,如果把外层for循环的i传递进匿名函数中使用,会发生什么?
回答:如果直接在匿名函数中使用变量i,会在执行到匿名函数中读取i的那一行代码时,读取i的当时值,这很可能不是我们想要的。一般我们希望的是获取创建线程时,for循环中i当时对应的值。所以需要将i作为参数传入匿名函数,如下修改代码:
1 | |
问题:看上去count和finished是主线程的本地变量,它们在主函数退出后应该会被销毁,那此时如果主线程推出后,新建的go线程还在使用这些变量,会怎么样?
回答:这里根据go语言的逃逸分析可知,被共享的变量实际上go会在堆中进行分配,而不是在主线程的栈中,所以可以安全的在多个线程之间共享。(原本讲师回答其实不对,这里修正了下)
问题:channel代码示例中,channel是自带了buffer吗?
回答:是的,通常你往channel写入数据时,如果没有人从channel读取数据,那么channel写者会阻塞。这里用的不是缓存channel。无缓存/缓冲区的channel,需要写者和读者都同时就绪才能通信。讲师表示在实验中用过带缓存/缓冲区的channel,表示不好用,用了很后悔,一般尽量不用,哈哈。
问题:有无办法在不退出主线程的情况下kill其他子线程?
回答:你可以往channel发送一个变量,示意子线程exit。但你必须自己去实现这个流程。
2.7 go爬虫(Crawler)
实现目标:
- I/O concurrency:IO并发性
- fetch once:保证每个url只爬一次
- exploit parallelism:利用并发行特性
这里代码不是重点,可以自己找视频或代码,这里不贴了。
2.8 远程过程调用(RPC)
Go RPC <= 该小节简单讲解了RPC,这里推荐这篇文章。或者可以去了解下gRPC。
RPC(Remote Produce Call)远程过程调用。
RPC系统的目标:
- 使得RPC在编程使用方面和栈上本地过程调用无差异。比如gRPC等实现,看上去Client和Server都像是在调用本地方法,对开发者隐藏了底层的网络通信环节流程
RPC semantics under failures (RPC失败时的语义) :
- at-least-once:至少执行一次
- at-most-once:至多执行一次,即重复请求不再处理
- Exactly-once:正好执行一次,很难做到
Lecture3 谷歌文件系统GFS
GFS是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,并提供容错功能。它可以给大量的用户提供总体性能较高的服务。
本章节主要讨论点:
- storage:存储
- GFS:GFS的设计
- consistency:一致性
3.1 存储Storage设计难点
构建(fault tolerance)可容错的系统,需要可靠的storage存储实现。
通常应用开发保持无状态stateless,而底层存储负责永久保存数据。
- 高性能(high perference)
- shard:需要分片(并发读取)
- data across server:跨多个服务机器存储数据(单机的网卡、CPU等硬件吞吐量限制)
- 多实例/多机器(many servers)
- constant faults:单机故障率低,但是足够多的机器则出现部分故障的概率高,在GFS论文上千台机器规模下,每天总会有3个机器出现失败/故障。因此需要有容错设计
- 容错(fault tolerance)
- replication:通常通过复制数据保证容错性,即当前磁盘数据异常/缺失等情况,尝试从另一个磁盘获取数据
- 复制(replication)
- potential inconsistencies:潜在的数据不一致问题需要考虑
- 强一致性(strong consistency):
- lower performance:一般需要通过一些消息机制保证一致性,这会稍微带来一些性能影响,但一般底层为了保证数据一致性而额外进行的网络通信等操作在整体性能的开销中占比并不会很高。其中可能涉及需要将通信的一些结果写入存储中,这是相对昂贵的操作。
3.2 一致性(consistency)
理想的一致性,即整个分布式系统对外表现时像单个机器一样运作。
**并发性(concurrency)**和**故障/失败(failures)**是两个实现一致性时需要考虑的难点。
并发性问题举例: W1写1,W2写2;R1和R2准备读取数据。W1和W2并发写,在不关心谁先谁后的情况下,考虑一致性,则我们希望R1和R2都读取到1或者都读取到2,R1和R2读取的值应该一致。(可通过分布式锁等机制解决)
故障/失败问题举例:
一般为了容错性,会通过复制的方式解决。而不成熟的复制操作,会导致读者在不做修改的情况下读取到两次不同的数据。比如,我们要求所有写者写数据时,需要往S1和S2都写一份。此时W1和W2并发地分别写1和2到S1、S2,而R1和R2即使在W1和W2都完成写数操作后,再从S1或S2读数时结果可能是1也可能是2(因为没有明确的协议指出这里W1和W2的数据在S1、S2上以什么方式存储,可能1被2覆盖,反之亦然)。
3.3 GFS-简述
GFS旨在保持高性能,且有复制、容错机制,但很难保持一致性。google确实曾使用GFS,虽然后继被新的文件系统Colossus取代。
在论文中可以看到mapper从GFS系统(上千个磁盘)能够以超过10000MB/s的速度读取数据。论文发表时,当时单个磁盘的读取速度大概是30MB/s,一般在几十MB/s左右。
GFS的几个主要特征:
- Big:large data set,巨大的数据集
- Fast:automatic sharding,自动分片到多个磁盘
- Gloal:all apps see same files,所有应用程序从GFS读取数据时看到相同的文件(一致性)
- Fault tolerance:automic,尽可能自动地采取一些容错恢复操作
3.4 GFS-数据读取流程简述

GFS通过Master管理文件系统的元数据等信息,其他Client只能往GFS写入或读取数据。当应用通过GFS Client读取数据时,大致流程如下:
- Client向Master发起读数据请求
- Master查询需要读取的数据对应的目录等信息,汇总文件块访问句柄、这些文件块所在的服务器节点信息给Client(大文件通常被拆分成多个块Chunk存放到不同服务器上,单个Chunk很大, 这里是64MB)
- Client得知需要读取的Chunk的信息后,直接和拥有这些Chunk的服务器网络通信传输Chunks
3.5 GFS-Master简述
这里大致介绍Master负责的工作:
维护文件名到块句柄数组的映射(file name => chunk handles)
这些信息大多数存放在内存中,所以Master可以快速响应客户端Client
维护每个块句柄(chunk handle)的版本(version)
维护块存储服务器列表(list of chunk servers)
- 主服务器(primary)
- Master还需维护每一个主服务器(primary)的租赁时间(lease time)
- 次要服务器(secondaries)
典型配置即将chunk存储到3台服务器上
- 主服务器(primary)
log+check point:通过日志和检查点机制维护文件系统。所有变更操作会先在log中记录,后续才响应Client。这样即使Master崩溃/故障,重启时也能通过log恢复状态。master会定期创建自己状态的检查点,落到持久性存储上,重启/恢复状态时只需重放log中最后一个check point检查点之后的所有操作,所以恢复也很快。
这里需要思考的是,哪些数据需要放到稳定的存储中(比如磁盘)?
比如file name => chunk hanles的映射,平时已经在内存中存储了,还有必要存在稳定的存储中吗?
需要,否则崩溃后恢复时,内存数据丢失,master无法索引某个具体的文件,相当于丢失了文件。
chunk handle 到 存放chunk的服务器列表,这一层映射关系,master需要稳定存储吗?
不需要,master重启时会要求其他存储chunk数据的服务器说明自己维护的chunk handles数据。这里master只需要内存中维护即可。同样的,主服务器(primary)、次要服务器(secondaries)、主服务器(primary)的租赁时间(lease time)也都只需要在内存中即可。
chunk handle的version版本号信息呢,master需要稳定存储吗?
需要。否则master崩溃重启时,master无法区分哪些chunk server存储的chunk最新的。比如可能有服务器存储的chunk version是14,由于网络问题,该服务器还没有拿到最新version 15的数据,master必须能够区分哪些server有最新version的chunk。
问题:Master崩溃重启后,会连接所有的chunk server,找到最大的version?
回答:Master会尝试和所有chunk server通信,尽量获取最新version。当然有可能拥有最新version的chunk server由于网络等原因正好联系不上,此时能联系上的存活最久的chunk server的version会比master存储的version小。
3.6 GFS-文件读取
- Client向Master发请求,要求读取X文件的Y偏移量的数据
- Master回复Client,X文件Y偏移量相关的块句柄、块服务器列表、版本号(chunk handle, list of chunk servers, version)
- Client 缓存cache块服务器列表(list of chunk servers)
- Client从最近的服务器请求chunk数据(reads from closest servers)
- 被Client访问的chunk server检查version,version正确则返回数据
为什么这里Client要缓存list of chunk server信息呢?
因为在这里的设计中,Master只有一台服务器,我们希望尽量减少Client和Server之间的通信次数,客户端缓存可以大大减少Master机器的负载。
为什么Client尽量访问最近的服务器来获取数据(reads from closest servers)?
因为这样在宛如拓扑结构的网络中可以最大限度地减少网络流量(mininize network traffic),提高整体系统的吞吐量。
为什么在Client访问chunk server时,chunk server需要检查verison?
为了尽量避免客户端读到过时数据的情况。
3.7 GFS-文件写入
这里主要关注文件写入中的append操作,因为把记录追加到文件中这个在他们的业务中很常见。在mapreduce中,reducer将处理后的记录数据(计算结果)很快地追加(append)到file中。
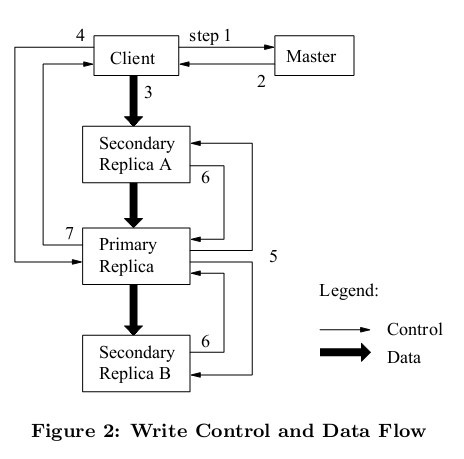
Client向Master发出请求,查询应该往哪里写入filename对应的文件。
Master查询filename到chunk handle映射关系的表,找到需要修改的chunk handle后,再查询chunk handle到chunk server数组映射关系的表,以list of chunk servers(primary、secondaries、version信息)作为Client请求的响应结果
接下去有两种情况,已有primary和没有primary(假设这是系统刚启动后不久,还没有primary)
有primary
继续后续流程
无primary
master在chunk servers中选出一个作为primary,其余的chunk server作为secondaries
。(暂时不考虑选出的细节和步骤)
- master会增加version(每次有新的primary时,都需要考虑时进入了一个new epoch,所以需要维护新的version),然后向primary和secondaries发送新的version,并且会发给primary有效期限的租约lease。这里primary和secondaries需要将version存储到磁盘,否则重启后内存数据丢失,无法让master信服自己拥有最新version的数据(同理Master也是将version存储在磁盘中)。
Client发送数据到想写入的chunk servers(primary和secondaries),有趣的是,这里Client只需访问最近的secondary,而这个被访问的secondary会将数据也转发到列表中的下一个chunk server,此时数据还不会真正被chunk severs存储。(即上图中间黑色粗箭头,secondary收到数据后,马上将数据推送到其他本次需要写的chunk server)
这么做提高了Client的吞吐量,避免Client本身需要消耗大量网络接口资源往primary和多个secondaries都发送数据。
数据传递完毕后,Client向primary发送一个message,表明本次为append操作。
primary此时需要做几件事:
- primary此时会检查version,如果version不匹配,那么Client的操作会被拒绝
- primary检查lease是否还有效,如果自己的lease无效了,则不再接受任何mutation operations(因为租约无效时,外部可能已经存在一个新的primary了)
- 如果version、lease都有效,那么primary会选择一个offset用于写入
- primary将前面接收到的数据写入稳定存储中
primary发送消息到secondaries,表示需要将之前接收的数据写入指定的offset
secondaries写入数据到primary指定的offset中,并回应primary已完成数据写入
primary回应Client,你想append追加的数据已完成写入
当然,存在一些情况导致数据append失败,此时primary本身写入成功,但是后续存在某些/某个secondaries写入失败,此时会向Client返回错误error。Client遇到这种错误后,通常会retry整个流程直到数据成功append,这也就是所谓的最少一次语义(do at-least-once)
需要注意的是,假设append失败,Client再次重试,此时流程中primary指定写入的offset和上一次会是一样的吗?
不,primary会指定一个新的offset。假设primary+2台secondaries,可能上一次p和s1都写成功,仅s2失败。此时retry需要用新的offset,或许p、s1、s2就都写入成功了。这里可以看出来**副本记录是可以重复的(replicates records can be duplicated)**,这和我们常见的操作系统中标准的文件系统不一样。
好在应用程序不需要直接和这种特殊的文件系统交互,而是通过库操作,库的内部实现隐藏了这些细节,用户不会看到曾经失败的副本记录数据。如果你append数据,库会给数据绑定一个id,如果库读取到相同id的数据,会跳过前面的一个。同时库内通过checksums检测数据的变化,同时保证数据不会被篡改。
问题:比起重写每一个副本(replica),直接记住某个副本(replica)失败了不是更好吗?
回答:是的,有很多不同的实现方式。上面流程中假设遇到短暂的网络问题等,也不一定会直接判定会写入失败,可能过一会chunk server会继续写入,并且最后判定为写入成功。
问题:所有的这些服务器都是可信的吗?(换言之,流程中好像没说明一些权限问题)
回答:是的,这很重要,这里不像Linux文件系统,有权限和访问控制写入(permissions and access control writes)一类的东西,服务器完全可信(因为这完全是一个内部系统)。
问题:写入流程中提到需要校验version,是否存在场景就是Client要读取旧version的数据?比如Client自己存储的version就是旧版本,所以读取数据时,拥有旧version的chunk server反而能够响应数据。
回答:假设这里有P(primary),S1(secondary 1),S2(secondary 2)和C(Client),S2由于网络等问题和P、S1断开联系,此时重新选出Primary(假设还是原本的P),version变为11,而S2断联所以还是version10的数据。一个本地cache了version10和list of chunk sevrers的Client正好直接从S2请求读取数据(因为S2最近),而S2的version和Client一致,所以直接读取到S2的数据。
问题:上面这个举例中,为什么version11这个信息不会返回到Client呢?
回答:原因可能是Client设置的cache时间比较长,并且协议中没有要求更新version。
问题:上面举例中,version更新后,不会推送到S2吗?即通知S2应该记录最新的version为11
回答:version版本递增是在master中维护的,version只会在选择新的primary的时候更新。论文中还提到serial number序列号的概念,不过这个和version无关,这个用于表示写入顺序。
问题:primary完成写入前,怎么知道要检查哪一些secondaries(是否完成了写入)?
回答:master告知的。master告诉primary需要更新secondaries,这形成了new replica group for that chunk。
3.8 GFS-一致性(Consistency)
这里一致性问题,可以简单地归结于,当你完成一个append操作后,进行read操作会读取到什么数据?
这里假设一个场景,我们讨论一下可能产生的一致性问题,这里有一个M(maseter),P(primary),S(Secondary):
某时刻起,M得不到和P之间的ping-pong通信的响应,什么时候Master会指向一个新的P?
- M比如等待P的lease到期,否则会出现两个P
- 此时可能有些Client还在和这个P交互
假设我们此时选出新P,有两个P同时存在,这种场景被称为脑裂(split-brain),此时会出现很多意料外的情况,比如数据写入顺序混乱等问题,严重的脑裂问题可能会导致系统最后出现两个Master。
这里M知道P的lease期限,在P的lease期限结束之前,不会选出新P,即使M无法和P通信,但其他Client可能还能正常和P通信。
这里扩展一下问题,如何达到更强的一致性(How to get stronger consistency)?
比如这里GFS有时候写入会失败,导致一部分S有数据,一部分S没数据(虽然对外不可见这种失败的数据)。我们或许可以做到要么所有S都成功写入,要么所有S都不写入。
事实上Google还有很多其他的文件系统,有些具有更强的一致性,比如Spanner有更强的一致性,且支持事务,其应用场景和这里不同。我们知道这里GFS是为了运行mapreduce而设计的。
Lecture4 主/备复制(Primary/Backup Replication)
(VM-FT论文解读)容错虚拟机分布式系统的设计 <= 推荐阅读
- failures:复制失败场景和对策
- challenge:实现难点
- 2 appliction:2个典型应用场景的探讨
- 状态转移复制(state transfer replication)
- 复制状态机(replicated state machines)
- case study
- VM FT:VMware fault tolerance
4.1 失败场景(Failures)
常见的复制失败场景分类:
- fail-stop failure:基础设备或计算机组件问题,导致系统暂停工作(stop compute),一般指计算机原本工作正常,由于一些突发的因素暂时工作失败了,比如网线被切断等。
- logic bugs, configuration errors:本身复制的逻辑有问题,或者复制相关的主从配置有异常,这类failure导致的失败,不能靠系统自身自动修复。
- malicious errors:这里我们的设计假设的内部系统中每一部分都是可信的,所以我们无法处理试图伪造协议的恶意攻击者。
- handling stop failure:比如主集群突发地震无法正常服务,我们希望系统能自动切换到使用backup备份集群提供服务。当然如果主从集群都在一个数据中心,那么一旦出现机房被毁问题,大概率整个系统就无法提供服务了。
在后续课程介绍中,我们的讲解/设计,都基于一个前提假设:系统中软件工作正常、没有逻辑/配置错误、没有恶意攻击者。
我们只关注**处理停止失败(handling stop failures)**。
4.2 实现难点(Challenge)
在计算机术语中,故障转移(英语:failover),即当活动的服务或应用意外终止时,快速启用冗余或备用的服务器、系统、硬件或者网络接替它们工作。 故障转移 (failover)与交换转移操作基本相同,只是故障转移通常是自动完成的,没有警告提醒手动完成,而交换转移需要手动进行。
如何判断primary失败?(has primary failed?)
你无法直接区分发生了网络分区问题(network partition)还是实质的机器故障问题(machine failed)
或许只是部分机器访问不到primary,但是客户端还是正常和primary交互中。你必须有一些机制保证不会让系统同时出现两个primary(假设机制中只允许正常情况下有且只有一个primary工作)。
(Split-brain system)脑裂场景
假设机制不完善,可能导致两个网络分区下各自有一个primary,客户端们和不同的primary交互,最后导致整个系统内部状态产生严重的分歧(比如存储的数据、数据的版本等差异巨大)。此时如果重启整个系统,我们就不得不手动处理这些复杂的分歧状态问题(就好似手动处理git merge冲突似的)。
如何让主备保持同步(how to keep the primary/backup in sync)
我们的目标是primary失败时,backup能接手primary的工作,并且从primary停止的地方继续工作。这要求backup总是能拿到primary最新写入的数据,保持最新版本。我们不希望直接向客户端返回错误或者无法响应请求,因为从客户端角度来看,primary和backup无区别,backup就是为容错而生,理应也能正常为自己提供服务。
- 需要保证应用中的所有变更,按照正确顺序被处理(apply changes in order)
- 必须**避免/解决非决定论(avoid non-determinism)**。即相同的变更在primary和backup上应该有一致的表现。
故障转移(failover)
primary出现问题时,我们希望切换到backup提供服务。但是切换之前,我们需要保证primary已经完成了所有正在执行的工作。即我们不希望在primary仍然在响应client时突然切换backup(如果遇到网络分区等问题,会使得故障转移难上加难)。
问题:什么时候需要进行故障转移(failover)?
回答:当primary失败时,我们希望切换到backup提供服务
4.3 主备复制
- **状态转移(state transfer)**:primary正常和client交互,每次响应client之前,先生成记录checkpoint检查点,将checkpoint同步到备份backup,待backup都同步完状态后,primary再响应client。
- **复制状态机(replicated state machine,RSM)**:与状态转移类似,只是这里primary和backup之间同步的不是状态,而是操作。即primary正常和client交互,每次响应client之前,先生成操作记录operations,将operations同步到备份backup,待backup都执行完相同的操作后,primary再响应client。
这两种方案都有被应用,共同的要点在于,primary响应client之前,首先确保和backup同步到相同的状态,然后再响应client。这样当primary故障时,任意backup接管都能有和原primary对齐的状态。
状态转移(state transfer)的缺点在于一个操作可能产生很多状态state,此时同步状态就变得昂贵且复杂。所以市面上的应用一般更乐意采用第二种方案,即复制状态机(replicated state machine,RSM)。
前面介绍的GFS追加append流程(“3.7 GFS-文件写入”),实际上也是primary将append操作通知到其他secondaries,即采用复制状态机(replicated state machine,RSM),而不是将append后的结果状态同步到其他secondaries。
问题:为什么client不需要发送数据到backup备机?
回答:因为这里client发送的请求是具有确定性的操作,只需向primary请求就够了。主备复制机制保证primary能够将具有确定性的操作正确同步到其他backup,即系统内部自动保证了primary和backup之间的一致性,不需要client额外干预。接下来的问题即,怎么确定一个操作是否具有确定性?在复制状态机(replicated state machine,RSM)方案中,即要求所有的操作都是具有确定性的,不允许存在非确定性的操作。
问题:是不是存在着混合的机制,即混用状态转移(state transfer)和复制状态机(replicated state machine,RSM)?
回答:是的。比如有的混合机制在默认情况下以复制状态机(replicated state machine,RSM)方案工作,而当集群内primary或backup故障,为此创建一个新的replica时则采用状态转移(state transfer)转移/复制现有副本的状态。
4.4 复制状态机RSM-复制什么级别的操作
使用复制状态机时,我们需要考虑什么级别的操作需要被复制。有以下几种可能性:
应用程序级别的操作(application-level operations)
比如GFS的文件append或write。如果你在应用程序级别的操作上使用复制状态机,那也意味着你的复制状态机实现内部需要密切关注应用程序的操作细节,比如GFS的append、write操作发生时,复制状态机应该如何处理这些操作。一般而言你需要修改应用程序本身,以执行或作为复制状态机方法的一部分。
机器层面的操作(machine-level operaitons),或者说processor level / coputer level
这里对应的状态state是寄存器的状态、内存的状态,操作operation则是传统的计算机指令。这种级别下,复制状态机无感知应用程序和操作系统,只感知最底层的机器指令。
有一种传统的进行机器级别复制的方式,比如你可以额外购买机器/处理器,这些硬件本身支持复制/备份,但是这么做很昂贵。
这里讨论的论文(VM-FM论文)通过虚拟机(virtual machine, VM)实现。
4.5 通过虚拟化实现复制(VM-FT: exploit virtualization)
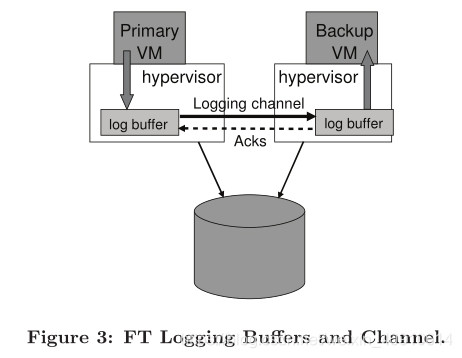
虚拟化复制对应用程序透明,且能够提供很强的一致性。早期的VMware就是以此实现的,尽管现在新版可能有所不同。缺陷就是这篇论文只支持单核,不支持多核(multi-core)。或许后来的FT支持了,但应该不是纯粹通过复制状态机实现的,或许是通过状体转移实现的,这些都只是猜测,毕竟VMware没有透露后续产品的技术细节。
我们先简单概览一下这个系统实现。
首先有一个虚拟机控制器(virtual machine monitor),或者有时也被称为hypervisor,在这论文中,对应的hypervisor即VM-FT。
当发生中断(比如定时器中断)时,作为hypervisor的VM-FT会接收到中断信号,此时它会做两件事:
- 通过日志通道将中断信号发送给备份计算机(sends it over a logging channel to a backup computer)
- 将中断信号传递到实际的虚拟机,比如运行在guest space的Linux。
同理,当client向primary发送网络数据包packet时,primary所在的硬件产生中断,而VM-FT将同样的中断通过logging channel发送给backup computer(也就是另一个VM-FT),然后将中断发送到当前VM-FT上的虚拟机(比如Linux)。另一台backup的VM-FT上运行着和priamry相同的Linux虚拟机,其也会同样收到来自backup的VM-FT的中断信号。primary虚拟机Linux之后往虚拟网卡写数据,产生中断,同样VM-FT也会将中断往backup的VM-FT发送一份。最后就是primary上的Linux虚拟机和backup上的Linux虚拟机都往各自的虚拟网卡发送了数据,但是backup的VM-FT知道自己是backup备机,所以从虚拟网卡接收数据后什么也不会做,只有primary的VM-FT会真正往物理网卡写数据,响应client的请求。
论文中提到,在primary和backup两个VM-FT以外,假设还通过网络和外部一个storage存储保持通讯。外部storage通过一个flag记录primary和backup状态,记录谁是primary等信息。
当primary和backup之间发生网络分区问题,而primary、backup仍可以与这个外部storage通信时,primary和backup互相会认为对方宕机了,都想把自己当作新的primary为外界的client提供服务。此时,原primary和原backup都试图通过test-and-set原子操作在外部storage修改flag记录(比如由0改成1之类的),谁先完成修改修改,谁就被外部storage认定为新的primary;而后来者test-and-set操作会返回1(test-and-set会返回旧值,这里返回1而不是0,表示已经有人领先自己把0改成1了),其得知自己是后来者,会主动放弃称为primary的机会,在论文中提到会选择终结自己(terminate itself)。
看上去这个方案能够避免同时出现两个primary的场景,并且把容错部分转移到了存储服务器中,这些看似都很合理,但事实并非如此。
问题:上面primary和backup的VM-FT争抢地希望通过test-and-set将flag的值从0设置成1,但这个flag是什么时候被设置成0的?
回答: 首先启动一台primary时,我们希望有备份,所以启动了另一个backup。之后我们希望有一个repair计划,保证primary失败后,backup能够接替,避免之后backup也失败后就没有机器能够运行了。而在VMFT中,修复方案由人工执行。当有人接收到报警通知,就马上根据第一个VM image虚拟机镜像创建一个replica,确保它们同步。根据协议,当backup启动完成备份时,flag就被重置为0。(当1个VM-FT向VMotion请求被复制时,正在被复制的VM-FT仍可以正常地向Client提供服务,而新的replica被复制出来时,会将storage中的flag标志设置为0。)
问题:primary和backup之间的logging channel中断会发生什么,又或者client访问server的通道中断了,会发生什么?
回答:如果server被访问的通道都断开了,那么即使primary、backup本身工作正常,可server也不会再对client提供服务,需要等待网络恢复正常,这是一个灾难性的例子。
4.6 差异来源(Divergence sources)
如果前面primary执行的指令都是确定性的,那么primary和backup无疑可以保证拥有相同的状态。但是不可避免的是可能出现一些非确定性的事件,我们需要考虑如何处理。我们的**目标即,将每一条非确定性的指令(non-deterministic instruction)变成确定性指令(deterministic instruction)**。
非确定性的指令(non-deterministic instruction)
比如获取时间的指令,我们不可能保证primary和backup都在同一时间执行,返回值一般来说会不同。
网络包接收/时钟中断(input packets / timer interrupters)
比如网络包输入时导致中断,primary和backup在原本CPU执行流中插入中断处理的位置可能不同。比如primary在第1~2条指令执行的位置插入网络包的中断处理,而backup在第2~3条指令执行的位置插入中断处理,这也有可能导致后续primary和backup的状态不一致。所以我们希望这里数据包产生的中断(或者时钟中断),在primary和backup相同的CPU指令流位置插入执行中断处理,确保不会产生不一致的状态。
多核(multi-core)
并发也是一个导致差异(primary和backup不一致)的潜在因素。而这篇论文的解决方案即不允许多核。比如,在primary上多核的两个线程竞争lock,我们需要保证backup上最后获取到lock的线程和primary的保持一致,这需要很多额外的复杂机制去实现这一点,该论文显然不想处理这个问题。这里讲师也不明确VMware在后来的产品是怎么保证多核机器的复制的,所以后续不讨论multi-core的场景。
论文假设大多数操作指令都是确定性的,只有出现这里谈论的一些非确定性的操作发生时,才需要考虑如何处理primary和backup之间的同步问题。
4.7 VM-FT的中断处理
根据前面的讨论,可以知道中断是一个非确定性的差异来源,我们需要有机制保证primary和backup处理中断后仍保持状态一致。
这里VM-FT是这样处理的,当接受到中断时,VM-FT能知道CPU已经执行了多少指令(比如执行了100条指令),并且计算一个位置(比如100),告知backup之后在指令执行到第100条的时候,执行中断处理程序。大多数处理器(比如x86)支持在执行到第X条指令后停止,然后将控制权返还给操作系统(这里即虚拟机监视器)。
通过上面的流程,VM-FT能保证primary和backup按照相同的指令流顺序执行。当然,这里backup会落后一条message(因为primary总是领先backup执行完需要在logging channel上传递的消息)。
问题:确定性操作,就不需要通过日志通道(logging channel)同步吗?
回答:是的,不需要。因为它们都有一份所有指令的复制,只有非确定性的指令才需要痛殴logging channel同步。
4.8 VM-FT的非确定性指令(non-deterministic instruction)处理
对于非确定性的指令,VM-FT基本上是这样处理的:
在启动Guest space中的Linux之前,先扫描Linux中所有的非确定性指令,确保把它们转为无效指令(invalid instruction)。当Guest space中的Linux执行这些非确定性的指令时,它将控制权通过trap交给hypervisor,此时hypervisor通过导致trap的原因能知道guest在执行非确定的指令,它会模拟这条指令的执行效果,然后记录指令模拟执行后的结果,比如记录到寄存器a0中,值为221。而backup备机上的Linux在后续某个时间点也会执行这条非确定性指令,然后通过trap进入backup的hypervisor,通常backup的hypervisor会等待,直到primary将这条指令模拟执行后的结果同步给自己(backup),然后backup就能和primary在这条非确定性指令执行上拥有一致的结果。
问题:扫描guest space的操作系统拥有的不确定性指令,发生在创建虚拟机时吗?
回答:是的,通常认为是在启动引导虚拟机时(when it boot to the VM)。
问题:如果这里有一条完全确定的指令,那么backup有可能执行比primary快吗?
回答:论文中有一个完整的结论,这里只需要primary和bakcup能有大致相同的执行速度(谁快一点谁慢一点影响不大),通常让primary和backup具有相同的硬件环境来实现这一点。
4.9 VM-FT失败场景处理
这里举例primary故障的场景。
比如primary本来维护一个计数器为10,client请求将其自增到11,但是primary内部自增了计数器到11,但是响应client前正好故障了。如果backup此时接手,其执行完logging channel里要求同步的指令,但是自增到11这个并没有反映到bakcup上。如果client再次请求自增计数器,其会获取到11而不是12。
为了避免出现上诉这种场景,VM-FT指定了一套*输出规则(Output rule)**。 实际上上诉场景并不会发生。**primary在响应client之前,会通过logging channel发送消息给backup,当backup确定接受到消息且之后能执行相同的操作后,会发送ack确认消息给primary。primary收到ack后,确认backup之后能和自己拥有相同的状态(就算backup有延迟慢了一点也没事,反正backup可以通过稳定存储等手段记录这条操作,之后确保执行后未来能和primary达到相同的状态),然后才响应client*。
在任何复制系统(replication system),都能看到类似输出规则(output rule)的机制(比如在raft或者zookeeper论文中)。
4.10 VM-FT性能问题
因为VM-FT的操作都基于机器指令或中断的级别上,所以需要牺牲一定的性能。
论文中统计在primary/backup模式下运行时,性能和平时单机差异不会太大,保持在0.94~0.98的水平。而当网络输入输出流量很高时,性能下降很明显,下降将近30%。这里导致性能下降的原因可能是,primary处理大量数据包时,需要等待backup也处理完毕。
正因为在指令层面(instruction level)使用复制状态机性能下降比较明显,所以现在人们更倾向于在应用层级(application level)使用复制状态机。但是在应用层级使用复制状态机,通常需要像GFS一样修改应用程序。
问题:前面举例client发请求希望primary中维护的计数器自增的操作,看似确定性操作,为什么还需要通过logging channel通知bakcup?
回答:因为client请求是一个网络请求,所以需要通知backup。并且这里primary会确定backup接受到相同的指令操作回复自己ack后,才响应client。
问题:VM-FT系统的目标,是为了帮助提高服务器的性能吗?上诉这些机制看着并不简单且看着会有性能损耗。或者说它是为了帮助分发虚拟机本身?
回答:这一套方案,仅仅是为了让运行在服务器上的应用拥有更强的容错性。虽然在机器指令或中断级别上做复制比起应用级别上性能损耗高,但是这对于应用程序透明,不要求修改应用程序代码。
问题:关于输出规则(Output rule),客户端是否可能看到相同的响应两次?
回答:可能,客户端完全有可能收到两次回复。但是论文中认为这种情况是可容忍的,因为网络本身就可能产生重复的消息,而底层TCP协议可以处理这些重复消息。
问题:如果primary宕机了几分钟,backup重新创建一个replica并通过test-and-set将storage的flag从0设置为1,自己成为新的primary。然后原primary又恢复了,这时候会怎么样?
回答:原primary会被clean,terminate自己。
问题:上面的storage除了flag以外,只需要存储其他东西吗?比如现在有多个backup的话。
回答:论文这里的方案只针对一个backup,如果你有多个backup,那么你还会遇到其他的问题,并且需要更复杂的协议和机制。
问题:处理大量网络数据包时,primary只会等待backup确认第一个数据包吗?
回答:不是,primary每处理一个数据包,都会通过logging channel同步到backup,并且等待backup返回ack。满足了输出规则(output rule)之后,primary才会发出响应。这里它们有一些方法让这个过程尽量快。
问题:关于logging channel,我看论文中提到用UDP。那如果出现故障,某个packet没有被确认,primary是不是直接认为backup失败,然后不会有任何重播?
回答:不是。因为有定时器中断,定时器中断大概每10ms左右触发一次。如果有包接受失败,primary会在心跳中断处理时尝试重发几次给backup,如果等待了可能几秒了还是有问题,那么可能直接stop停止工作。
Lecture5 容错-Raft(Fault Tolerance-Raft) -1
Raft 协议原理详解,10 分钟带你掌握! - 知乎 (zhihu.com) <= 图片很多,推荐阅读
Raft 协议 - 简书 (jianshu.com) <= 有动图,还不错
这章节主要介绍Raft协议,它是分布式复制协议(distributed replication protocol)示例的核心组件之一。
5.1 单点故障(single point of failure)
前面介绍过的复制系统,都存在单点故障问题(single point of failure)。
- mapreduce中的cordinator
- GFS的master
- VM-FT的test-and-set存储服务器storage
而上诉的方案中,采用单机管理而不是采用多实例/多机器的原因,是为了避免**脑裂(split-brain)**问题。
不过大多数情况下,单点故障是可以接受的,因为单机故障率显著比多机出现一台故障的概率低,并且重启单机以恢复工作的成本也相对较低,只需要容忍一小段时间的重启恢复工作。
5.2 脑裂问题(split-brain)
Raft是避免单点故障问题的一种方案,在介绍Raft之前,我们先了解下为什么单机管理可以避免严重的脑裂问题,尽管单机管理会有单点故障问题。
以VM-FT的test-and-set存储服务器storage举例。假设我们复制storage服务器,使其有两个实例机器S1、S2。(即打破单机管理的场景,看看简单的多机管理下有什么问题)
此时C1想要争取称为Primary,于是向S1和S2都发起test-and-set请求。假设因为某种原因,S2没有响应,S1响应,成功将0改成1,此时C1可能直接认为自己成为Primary。
这里S2没有响应可以先简单分析两种可能:
S2失败/宕机了,对所有请求方都无法提供服务
如果是这种情况,那么C1成为Primary不会有任何问题,S2就如同从来不曾存在,任何其他C同样只能访问到S1,他们都会知道自己无法成为Primary,并且整个系统只会存在C1作为Primary。
S2和C1之间产生了网络分区(network partition),仅C1无法访问到S2
这时候如果存在C2也向S1和S2发出请求,此时S1虽然将0改成1会失败,但是S2会成功。如果我们的协议不够严谨,这里C2会认为自己成为了Primary,导致整个系统存在两个Primary。这也就是严重的脑裂问题。
产生这种问题的原因在于,对于请求方,无法简单地判断上诉两种情况,因为对他们来说两种情况的表现都是一样的。
为避免出现脑裂,我们需要先解决网络分区问题。
5.3 大多数原则(majority rule)
诸如Raft一类的协议用于解决单点故障问题,同时也用于解决网络分区问题。这类解决方案的基本思想即:*大多数原则(majority rule)**,**简单理解就是少数服从多数*。
这里的majority指的是整个系统中无论机器的状态如何,只要获取到大于一半的赞成,则认为获取到majority。比如系统中有5台机器,2台宕机了,5台的一半为2.5,但2.5不为有效值,即获取3台机器赞成,认为获取到majority;如果5台中宕机3台,那么没有人能获取到至少3台的赞成,即无法得到majority。
同样以VM-FT的test-and-set存储服务器storage举例,这次storage不是复制出2个实例,而是总共复制出3个实例,S1、S2、S3。
此时C1同时向S1、S2、S3请求test-and-set,其中S1和S2成功将0改成1,S3因为其他问题没有响应,但是我们不关系为什么。这里按照majority rule,只要3个S中有2个给出成功响应,我们就认为C1能够成为Primary。此时就算同时有C2向S1、S2、S3发起请求,就算S3成功了,C2根据majorty rule,3台只成功1台,不能成为Primary。
为什么根据majority rule,这里就不会出现脑裂,因为能确保多个C之间的请求有*重叠部分(overlap)**,这样根据majority rule,多个C最后也能达成一致,**因为只有1个C有可能成为多数的一方,其他C只能成为少数的一方*。
在之后准备介绍的Raft,和这里描述的工作流程基本一致。
- 在majority rule下,尽管发生网络分区,只会一个拥有多数的分区,不会有其他分区具有多数,只有拥有多数的分区能继续工作(比如这里3台被拆成1台、2台的分区,只有和后者成功通信的能继续工作)。
- 而如果极端情况下所有分区都不占多数( 比如这里3台被拆成1台、1台、1台的分区),那么整个系统都不能运行。
上诉3台的场景,只能容忍1台宕机,如果宕机2台,那么任何人都无法达到majorty的情况。这里通过2f+1拓展可容忍宕机的机器数,f表示可容忍宕机的机器数量。2f+1,即使宕机了f台,剩下的f+1>f,仍然可以组成majority完成服务。
例如,当f=2时,表示系统内最多可容忍2台机器处于宕机状态,那么至少需要部署5台服务器(2x2+1=5)。
问题:这里大多数是否包括参与者服务器本身,假设是raft,服务器会考虑自身吗?
回答:是的,通常我们看到的raft,candidate会直接vote自己。而leader处理工作时,也会vote记录自己。
5.4 Raft历史发展
在1980s~1990s,基本不存在诸如majority的协议,所以一直存在单点故障的问题。
而在1990s出现了两种被广泛讨论协议,但是由于当时的应用没有自动化容错的需求,所以基本没有被应用。但近15年来(2000s~2020s)大量商用产品使用到这些协议:
- Paxos
- View-Stamped replication (也被称为VR)
我们将要讨论的是Raft,大概在2014左右有相关的论文,它应用广泛,你可以用它来实现一个完全复制状态机(complete replicated state machine)。
5.5 使用Raft构造复制状态机RSM(replicated state machine)
这里raft就像一个library应用包。假设我们通过raft协议构造了一个由3台机器组成的K/V存储系统。
系统正常工作时,大致流程如下:
- Client向3台机器中作为leader的机器发查询请求
- leader机器将接收到的请求记录到底层raft的顺序log中
- 当前leader的raft将顺序log中尾部新增的log记录通过网络同步到其他2台机器
- 其他两台K/V机器的raft成功追加log记录到自己的顺序log中后,回应leader一个ACK
- leader的raft得知其他机器成功将log存储到各自的storage后,将log操作反映给自己的K/V应用
- K/V应用实际进行K/V查询,并且将结果响应给Client
系统出现异常时,发生如下事件:
- Client向leader请求
- leader向其他2台机器同步log并且获得ACK
- leader准备响应时突然宕机,无法响应Client
- 其他2台机器重新选举出其中1台作为新的leader
- Client请求超时或失败,重新发起请求,系统内部failover故障转移,所以这次Client请求到的是新leader
- 新leader同样记录log并且同步log到另一台机器获取到ACK
- 新leader响应Client
这里可以想到的是,剩下存活的两台机器的log中会有重复请求,而我们需要能够检测(detect)出这些重复请求。
上面就是用Raft实现复制状态机的一种普遍风格/做法。
问题:访问leader的client数量通常是多少?
回答:我想你的疑问是系统只有1个leader的话,那能承受多少请求量。实际上,具体的系统设计还会采用shard将数据分片到多个raft实例上,每个shard可以再有各自的leader,这样就可以平均请求的负载到其他机器上了。
问题:旧leader宕机后,client怎么知道要和新leader通信?
回答:client中有系统中所有服务器的访问列表,这里举例中有3个服务器。当其中一台请求失败时,client会重新随机请求3台中的1台,直到请求成功。
5.6 Raft概述
这里我们重新概述一下Raft流程。首先这里我们用3台Raft机器,其中一台为leader,另外两台为follower。leader和follower都在storage维护着log,所有K/V的put/get操作都会被记录到log中。
- Client请求leader,假设是get请求
- leader将get操作记录到自己的log尾部
- leader将新的log条目发送给其他2个follower
- 此时follower1成功将log条目追加到自己本地的log中,回应leader一个ack
- 此时leader和follower1共2台机器成功追加log,达到majority,于是leader可以进行commit,将操作移交给上层的kv服务。(这里即使宕机了一台,之后重新选举,包含最后操作的服务器将当选成为新的leader,比如原leader或follower1将当选,所以服务能继续正常提供)
- follower2由于网络问题,此时才回应leader一个ack。从follower角度其并不知道leader已经commit了操作,它只知道leader向自己同步了log并且需要回应ack。
- 由于leader进行了commit,leader的上层kv会响应Client对应get请求的查询结果。
如果上面进行的是一个append操作,那么leader的raft记录log到本地后,leader同步log到其他follower后,如果leader进行了commit,follower也需要将log记录反馈给各自上层的k/v服务,使得append这个写操作生效。
问题:如果log从leader同步到其他follower时,leader宕机了,会怎么样?
回答:会重新发生选举,而拥有最新操作log的机器成为新leader后会将追加的log条目传递给其他follower,这样就保证这些机器都拥有最新的log了。
5.7 Raft的log用途
log的原因/用途:
- 重传(retranmission):leader向follower同步消息时,消息可能传递失败,所以需要log记录,方便重传
- 顺序(order):主要原因,我们需要被同步的操作,以相同的顺序出现在所有的replica上
- 持久化(persistence):持久化log数据,才能支持失败重传,重启后日志恢复等机制
- **试探性操作(space tentative)**:比如follower接收到来自leader的log后,并不知道哪些操作被commit了,可能等待一会直到明确操作被commit了才进行后续操作。我们需要一些空间来做这些试探性操作(tentative operations),而log很合适。
**尽管中间有些时间点,可能有些机器的log是落后的。但是当一段时间没有新log产生时,最终这些机器的log会同步到完全相同的状态(logs identical on all servers)**。并且因为这些log是有顺序的,意味着上层的kv服务最终也会达到相同的状态。
5.8 Raft的log格式
在log中有很多个log entry。每个log entry被log index、leader term唯一标识。
每个log entry含有以下信息:
- command(接受到的指令、操作)
- leader term(当前系统中leader的任期期限)
从上面log entry的格式,可以引出两点信息:
- elect leader:我们需要选举出特定任期的leader
- ensue logs become indentical:确保最后所有机器的log能达到一致的状态
问题:没有提交(uncommit)的日志条目(log entries)会被覆盖吗?
回答:是的,可能被覆盖,详情后续会谈。
5.9 Raft选举(election)
假设这里有3台机器,1台leader,2台follower,它们都处于term10。
某一时刻,leader和其他2follower产生了网络分区
2个follower重新进行选举,原因是它们错过了leader的**心跳通信(heartbeats)**,而follower维护的election timer超时了,表明需要重新选举。
当leader没有收到来自client的新消息时,leader也仍会定期发送heartbeat到其他所有followers,告知自己仍是leader。这也算一种append log,但是不会被实际记录到log中。在heartbeat中,leader会携带一些自己log状态的信息,比如当前log应该多长,最后一条log entry应该是什么样的,帮助其他followers同步到最新状态。
假设follower1的election timer超时更早,其将term自增,从term10变成term11,并且发出选举,先自己投自己一票,然后向原leader和follower2请求选票
follower2响应follwer1,投出赞成票,原leader由于网络分区问题没有响应
follower1成为新的leader
client将请求failover故障转移到新的leader上,即follower1,后续请求发送至follower1
也许有人会问,如果leader在follower1成为新leader时,仍然有client请求到leader上,并且leader又重新恢复了和原follower1、原follower2的网络连接了,会不会导致系统出现两个leader,即脑裂问题?
实际上不会出现脑裂(split-brain)问题。如下分析:
- 原leader接收到client的请求,尝试发log给原follwer1和原follower2
- 原follower1(新leader)收到log后,会拒绝追加log到本地log中,并回复原leader新的term11
- 原leader接收到term11后,对比自己的term10会意识到自己不再是leader,接下去要么直接成为follower,要么重新发起选举,但不会继续作为leader提供服务,不导致脑裂
- client此时可能得到失败或拒绝服务等响应,然后重新向新leader(原follower1)发起请求
5.10 Raft-分裂选举问题(split vote)
在Raft中规定每个term只能投票一次,而前面的原leader网络分区后,follower1和follower2可能产生分裂选举(split vote)的问题:
- 由于巧合,follower1和follower2的election timer几乎同一时刻到期,它们都将term由10改成11
- follower1和follower2在term11都vote自己,然后向对方发起获取投票的请求
- follower1和follower2因为都在term11投票过自己了,所以都会拒绝对方的拉票请求,这导致双方都成为不了majority,没有人成为新leader
- 也许有个选举超时时间节点,follower1和follower又继续将term11增加到12,然后重复上诉流程。如果此时没有人为介入操作,上面重复的term增加、vote自己、没人成为leader,超时后又进行新一轮election的过程可能一直重复下去
**为了避免陷入上面的选举死循环,通常election超时时间是随机的(election timeout is randomized)**。
论文中提到,它们设置election timer时,选择150ms到300ms之间的随机值。每次这些follower重制自身的election timeout时,会选择150ms~300ms之间的一个随机数,只有当计时器到点时,才会发起选举eleciton。这样上诉流程中总有一刻follower1或者follower2因为timer领先到点,最终成功vote自己且拉票让对方vote自己,达到majority条件,优胜成为leader。
5.11 Raft-选举超时(election timeout)
选举超时的时间,应该设置成大概多少才合适?
略大于心跳时间(>= few heartbeats)
如果选举超时比心跳还短,那么系统将频繁发起选举,而选举期间系统对外呈现的是阻塞请求,不能正常响应client。因为election时很可能丢失同步的log,一直频繁地更新term,不接受旧leader的log(旧leader的term低于新term,同步log消息会被拒绝)
加入一些随机数(random value)
加入适当范围的随机数,能够避免无限循环下去的分裂选举(split vote)问题。random value越大,越能够减少进行split vote的次数,但random value越大,也意味着对于client来说,整个系统停止提供对外服务的时间越长(对外表现和宕机差不多,反正选举期间无法正常响应client的请求)
尽量短(short enough that down time is short)
因为选举期间,对外client表现上如同宕机一般,无法正常响应请求,所以我们希望eleciton timeout能够尽量短
Raft论文进行了大量实验,以得到250ms~300ms这个在它们系统中的合理值作为eleciton timeout。
5.12 Raft-vote需记录到稳定storage
这里提一个选举中的细节问题。假设还是leader宕机,follower1和follower2中的follower1发起选举。follower1会先vote自己,然后发起拉票请求希望follower2投票自己。
这里follower1应该用一个稳定的storage记录自己的vote历史记录,有人知道为什么吗?原因是避免重复vote。假设follower1在vote自己后宕机一小段时间后恢复,我们需要避免follower1又vote自己一次,不然follower1由于vote过自己两次,直接就可以无视其他follower的投票认为自己成为了leader。
所以,为了保证每个term,每个机器只会进行一次vote行为,以保证最后只会产生一个leader,每个参选者都需要用稳定的storage记录自己的vote行为。
问题:这里需要记录vote之前当前机器自身是follower、leader或者candidate吗?
回答:假设机器宕机后恢复,且仍然在选举,它可以在选举结束后根据vote的结果知道自己是leader还是follower。(注意,vote情况记录在稳定的storage中,所以宕机恢复后也能继续选举流程。大不了就是选举作废,term增加又进行新一轮选举)
5.13 Raft-日志分歧(log diverge)
7.2 选举约束(Election Restriction) - MIT6.824 (gitbook.io)
如果你去看处理RequestVote的代码和Raft论文的图2,当某个节点为候选人投票时,节点应该将候选人的任期号记录在持久化存储中。(换言之,就算当前server的term记录落后于其他server,也可以通过通信知道下一次选举term值应该是多少,比如S1的term为5,但是S2的term为7,S1下次选举时也知道要从term8开始,而不是term6)
这里讨论一下不同raft server中log出现分歧的问题。
一个简单容易想到的场景即S1~S3都在log index 10~11有一致的log记录,而S1作为leader率先在log index12的位置写入log后宕机,之后S2、S3拿不到这个log记录。这个场景比较简单,我们暂不讨论。
一个复杂的场景如下:
- S1在log index10位置有term3的记录,log index11~12暂无记录
- S2在log index10位置有term3的记录,log index11有term3记录,log index12有term4记录
- S3在log index10位置有term3的记录,log index11有term3记录,log index12有term5记录
这里首先需要讨论的是,在raft协议下,有可能出现S2和S3在相同log index12下出现不同term记录的情况吗?
答案是有可能。比如可以有如下推理
- S2作为leader向S1和S3同步term3的log记录,于是S1~S3都在index10有term3记录
- S1某一时刻宕机了,于是没有拿到后续log index11~12的记录
- S2发起选举,term从3改成4,并且成功成为term4的leader
- S2接收到新的请求,记录到log中,所以log index12出现term4记录
- S2同步term4 log到S3之前,宕机
- S3重新发起选举,此时也许S2恢复了,S3随后当选成为term5的leader(因为S2恢复,S3获取2票达到majority条件)
- client向S3请求,S3记录term5的log,于是有log index12出现term5记录
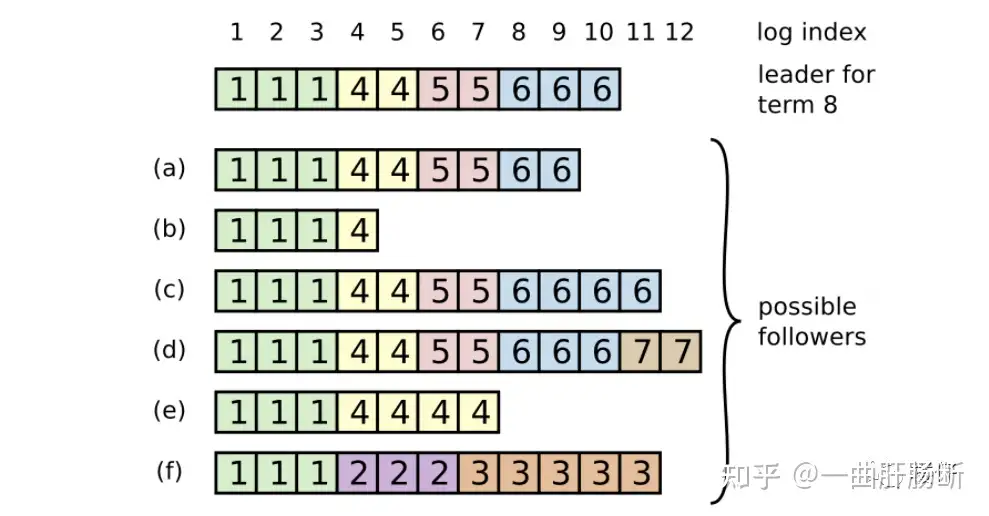
这里进行一个复杂场景的讨论,如果原本系统中有某个server宕机,剩余server中谁会成为leader?
下面用(XZ,Y)表示log index XZ的位置有term Y的记录
原leader(已宕机,这里不考虑能恢复的情况),原leader仅比a多一条log记录(10,6)
- a: (1
3, 1); (45, 4); (67, 5); (89, 6) - b: (1~3, 1); (4, 4);
- c: (1
3, 1); (45, 4); (67, 5); (811, 6) - d: (1
3, 1); (45, 4); (67, 5); (810, 6); (11~12, 7) - e: (1
3, 1); (47, 4); - f: (1
3, 1); (46, 2); (7~11, 3);
这里排出b、e、f,因为a~f都不宕机的情况下,b、e、f拥有的term都很小,绝对不可能获取到majority条件的选票数。因为term较大的server会拒绝其他term小的server的拉票请求。
这里有可能作为新leader的candidate只有a、c、d。
下面这些内容,属于我自己的猜想,和这个网课无关
这里a、c、d都可能当选,因为最新的term记录在每个server都会有记录,所以下一次不管谁发起选举,都会从term8开始发起选举(或者说就算一开始不知道,只要和d通信过,其他server就会知道下一次选举的term应该是7之后的8,因为通信完一圈,只有d有目前最大的term值)。只要谁先获取到足够多的选票,谁就有可能成为下一个leader。
但是只有d最后会当选成leader,因为a、c、d除了投票自己后,还会向其他服务器拉票,一旦a、c发现d拥有最大的term之后,都会放弃成为leader,退让成为follower。(因为a、c向d拉票的时候,会被d拒绝,并且d会告知a、c自己拥有更大的term8。这里是term8而不是term7,因为d会先将term改成8,之后vote自己,然后再向其他server拉票,所以a和c向自己拉票的时候会收到d的拒绝和被告知d已经达到term8了。)且这里有个注意点,这里前提是原本leader宕机,而且原本leader记录其实宕机前的部分和d是对齐的。原本leader的所有log都是commited的。d当选leader后,会要求其他的server的log和自己对齐,不一致/有分歧的部分会按照d的log覆盖,保证之后系统中所有的server的log对齐。
问题:上面a~f争抢leader的场景中,为什么d有term7记录,它原本是leader吗?
回答:d至少是term7的leader,否则它不会有term7的log记录。
问题:前面小节提到leader同步log给其他follower后,会进行commit,这里会不会出现leader自己先commit了,结果崩溃了,其他follower还没有commit?
回答:不会。因为leader会等待确认了其他follower能commit了,再执行commit,然后才会告知上层的KV服务对应的client请求消息。
追问:这里有个问题,leader不发送其他消息的话,仅发送同步log消息给其他followers,那又怎么知道其他follower能够commit了?因为leader必须等大多数follower能够commit后才会执行自己的commit。
回答:我们有说过可以执行一些试探性的操作,这里可以有tentative的log传输,来确认其他follower是否能够commit。(我个人猜测,log同步传输后,follower接收到log并写入storage回应ACK。之后leader准备commit之前,又发送tentative试探性消息,而大多数follower收到消息,先将tentative记录到log中表示自己随时可以commit,然后响应ACK。此时大多数follower回应leader可以commit了,尽管follower可能还没有完成commit操作,但是leader可以进行commit了。因为此时尽管followers中出现宕机,其恢复时通过log也会知道自己在commit状态中,需要把收到的log进行commit。)
问题:如果leader追加了很多log,然后崩溃了,那么后续选举出来的新leader,会把旧leader同步过来的log进行commit吗?
回答:可能会,也可能不会。这里场景比较复杂,就算新leader没有做commit,即不响应client也没事。因为KV服务的client会认为服务失败(毕竟election阶段无法对外提供服务),client会重新发起请求,所以新leader会插入一条新的log entry,之后再执行log同步、commit的完整流程。
问题:raft和其他课前提到的算法,有什么可以优化的点吗?比如使用批处理之类的,看起来raft很适合使用批处理,因为leader可以一次再log中放入不止一个log entry。或者说raft在性能角度有什么劣势吗?
回答:首先,raft并没有采用批处理来一次插入积攒的多个log entry,也许是因为这会让协议变得更复杂。也许像你所说,在插入log entry的地方增加批处理能提高性能,但是Raft没这么做,仅此而已。可以认为Raft有很多可以提高性能的潜在手段,但是Raft没有实现它们。(因为这个提问者表示自己在实验中尝试通过批处理的形式插入段时间内积攒的log entry,并且表示暂时没遇到什么问题)。
问题:看上去如果出现log丢失,可能client就无法得到响应,所以Raft是不是只适用于能够允许log丢失的场景或服务?
回答:是的,一般来说需要client能够支持重试机制。并且如果有重复的请求,就如前面提到的,需要Raft的上层服务维护**重复检测表(duplicate detection table)**来保证重复请求不会导致错误的业务结果。
Lecture6 Lab1 Q&A
Lecture7 容错-Raft(Fault Tolerance-Raft) -2
- Log divergence
- Log catch up
- Persistence
- Snapshots
- Linearization
7.1 Raft-leader选举规则
7.2 选举约束(Election Restriction) - MIT6.824 (gitbook.io)
在Raft论文的5.4.1,Raft有一个稍微复杂的选举限制(Election Restriction)。这个限制要求,在处理别节点发来的RequestVote RPC时,需要做一些检查才能投出赞成票。这里的限制是,节点只能向满足下面条件之一的候选人投出赞成票:
- 候选人最后一条Log条目的任期号大于本地最后一条Log条目的任期号;
- 或者,候选人最后一条Log条目的任期号等于本地最后一条Log条目的任期号,且候选人的Log记录长度大于等于本地Log记录的长度
Leader election rule:
- majority:大多数原则,即至少获取整个系统内大于全部机器数量一半的选票(包括自己,且每人只能投一次票,宕机的机器也算在系统机器总数内。如果剩余机器数压根凑不到刚好大于一半的机器数,则没有人能够成功获选)
- at-least-up-to-date:能当选的机器一定是具有最新term的机器
7.2 Raft-日志覆写同步(未优化版本)Log catch up(unoptimized)
- nextIndex:所有raft节点都维护nextIndex乐观的变量用于记录下一个需要填充log entry的log index。这里说乐观,因为当leader当选时,leader会初始化nextIndex值为当前log index值+1,表示认为leader自身的log一定是最新的
- matchIndex:leader为所有raft节点(包括leader自己)维护一个悲观的matchIndex用于记录leader和其他follower从0开始往后最长能匹配上的log index的位置+1,表示leader和某个follower在matchIndex之前的所有log entry都是对齐的。这里说悲观,因为leader当选时,leader会初始化matchIndex值为0,表示认为自身log中没有一条记录和其他follower能匹配上。随着leader和其他follower同步消息时,matchIndex会慢慢增加。leader为每个自己的follower维护matchIndex,因为平时根据majority规则,需要保证log已经同步到足够多的followers上。
假设这里有S1~S3三台服务器组成Raft集群,每个Server的log记录如下,(X, Y)表示在log index X有log entry term=Y的log记录:
- S1:(10, 3)
- S2:(10, 3); (11, 3); (12, 5)
- S3:(10, 3); (11, 3); (12, 4)
这里可以看出来S2是term5的leader。
这里S2通过heartbeats流程顺带发起log catch up,即想要和其他followers同步log entry的整体记录情况,按照majority原则,只需要向除了自身外的一台服务器发送消息即可,这里假设向S3发请求。
- S2向S3,发送heartbeat,携带信息(当前nextIndex指向的term,nextIndex-1的term值,nextIndex-1值),即(空,5,12)
- S3收到后,检查自己的log发现自己log index12为term4,回复S2一条否定消息no,表明自己还存活,但是不能同意S2要求的append操作,因为S3自己发现自己的log落后了。
- S2看到S3的否定回应后,认为S3落后于自己,于是将自己的nextIndex从13改成12
- S2重新发一条请求到S3,这次nextIndex是12,所以携带信息(5, 3, 11)
- S3接收到后,检查自己log index11的位置为3,发现和S2说的一样,于是按照S2的log记录,在自己log index12的位置将term4改成term5,然后回复S2一条确定消息ok
- S2收到来自S3的ok后,认为S3这次通信后log和自己对齐是最新的了
- S2将自己维护的对应S3的matchIndex更新为13,表示log index13之前的log entry,作为leader的S2和作为follower的S3是对齐的
到这里为止,S2能够知道log index12的log entry term5至少在2个server上得到复制(S2和S3),已经满足了majority原则了,所以S2能将消息传递到上层应用了。不幸的是,这不完全是对的。下面会讨论为什么。
这里未优化的版本有个很大的问题,那就是如果Raft集群中出现log落后很多的server,leader需要进行很多次请求才能将其log与自己对齐。
7.3 Raft-日志擦除(Erasing log entries)
commit after the leader has committed one entry in its own term.
| log index | 1 | 2 | 3 |
|---|---|---|---|
| S1 | 1 | 2 | 4 |
| S2 | 1 | 2 | |
| S3 | 1 | 2 | |
| S4 | 1 | ||
| S5 | 1 | 3 |
这里网课描述一个场景,大意就是5台server中,S5在log index2有term3,而某时刻S1在log index3有term4,其他server都还没有log index3的记录。
- 如果S5率先完成log index1~2的提交,那么S5可能先提起log catch up,导致S1~S4的log都被强制和自己对齐。即S1~S5的log变得完全一致(这里S1多出来的log index3记录会被清除),都变成(1, 3),因为log index1的位置S1~S5一致,所以log index2的位置都被覆盖成3即可
- 如果S1筛选完成log index1~3的提交,那么S1~S3的服务器会被覆盖记录成(1,2,4),而S4~S5不变,因为只有S2和S3在log index1~2和S1是对齐的。
7.3 Raft-日志快速覆写同步(Log catch up quikly)
| 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|
| S1 | 4 | 5 | 5 | 5 | 5 |
| S2 | 4 | 6 | 6 | 6 | 6 |
如果通过前面”7.2 Log catch up(unoptimized)”流程,可知道假设S2要向S1同步历史log的记录,那么需要从log index5(nextIndex=6)开始请求,一直请求到log index1(nextIndex=2)的位置后,才能找到S2和S1对齐的第一个位置log index1,然后又以1log index为单位,一直同步到nextIndex=6为止。这显然很浪费网络资源。
这里Log catch up quickly在论文中没有很详细的描述,但是大致流程如下:
- S2假设在term7当选leader,于是nextIndex=6,如之前一样,向S1发送heartbeat时携带log同步信息,(空,6,5),对应(当前nextIndex指向的term,nextIndex-1的term,nextIndex-1值)
- S1收到后,对比自己logIndex5位置为term5。此时S1不再是简单返回no,还顺带回复自己的log信息(即请求中logIndex位置的term值,这个term值最早出现的logIndex位置),这里S1回复(5,2),表示S2heartbeat中说的logIndex5位置自己是term5不对齐,并且term5的值在自己log可追溯到logIndex2
- S2收到回应后,可以直接将nextIndex改成2,并且下次heartbeat携带的信息变成([6,6,6,6], 4, 1),表示nextIndex即往后的数据为[6,6,6,6]
- S1收到heartnbeat后,发现logIndex1是term4是对齐的,于是按照S2说的,将logIndex2开始往后的共4个位置替换成[6,6,6,6]。
7.4 Raft-持久化(Persistence)
7.4 持久化(Persistence) - MIT6.824 (gitbook.io)
持久化currentTerm的原因要更微妙一些,但是实际上还是为了实现一个任期内最多只有一个Leader,我们之前实际上介绍过这里的内容。如果(重启之后)我们不知道任期号是什么,很难确保一个任期内只有一个Leader。
在这里例子中,S1关机了,S2和S3会尝试选举一个新的Leader。它们需要证据证明,正确的任期号是8,而不是6。如果仅仅是S2和S3为彼此投票,它们不知道当前的任期号,它们只能查看自己的Log,它们或许会认为下一个任期是6(因为Log里的上一个任期是5)。如果它们这么做了,那么它们会从任期6开始添加Log。但是接下来,就会有问题了,因为我们有了两个不同的任期6(另一个在S1中)。这就是为什么currentTerm需要被持久化存储的原因,因为它需要用来保存已经被使用过的任期号。
我们这里主要考虑Reboot重启时发生/需要做的事情。
- 策略1:一个Raft节点崩溃重启后,必须重新加入Raft集群。即对于整个Raft集群来说,重启和新加入Raft节点没有太大区别
- 重新加入(re-join),重新加入Raft集群
- 重放日志(replay the log),需要重新执行本地存储的log(我理解上只有未commit的需要重放,当然如果不能区分哪些commit的话,那就是所有现存log需要重放)
- 策略2:快速重启(start from your persistence state),从上一次存储的持久化状态(快照)的位置开始工作,后续可以通过log catch up的机制,赶上leader的log状态
人们更偏向于策略2,快速重启。这就需要搞清楚,需要持久化哪些状态。
Raft持久化以下状态state:
- vote for:投票情况,因为需要保证每轮term每个server只能投票一次
- log:崩溃前的log记录,因为我们需要保证(promise)已发生的(commit)不会被回退。否则崩溃重启后,可能发生一些奇怪的事情,比如client先前的请求又重新生效一次,导致某个K/V被覆盖成旧值之类的。
- current term:崩溃前的当前term值。因为选举(election)需要用到,用于投票和拉票流程,并且需要保证单调递增(monotonic increasing)
问题:什么时候,server决定进行持久化的动作呢?
回答:每当上面提到的需要持久化的变量state发生变化时,都应该进行持久化,写入稳定存储(磁盘),即使这可能是很昂贵的操作。你必须保证在回复client或者leader的请求之前,先将需要持久化的数据写入稳定存储,然后再回复。否则如果先回复,但是持久化之前崩溃了,你相当于丢失了一些无法找回的记录。
7.5 Raft-服务恢复(Service recovery)
类似的,服务重启恢复时有两种策略:
- 日志重放(replay log):理论上将log中的记录全部重放一遍,能得到和之前一致的工作状态。这一般来说是很昂贵的策略,特别是工作数年的服务,从头开始执行一遍log,耗时难以估量。所以一般人们不会考虑策略1。
- **周期性快照(periodic snapshots)**:假设在i的位置创建了快照,那么可以裁剪log,只保留i往后的log。此时重启后可以通过snapshot快照先快速恢复到某个时刻的状态,然后后续可以再通过log catch up或其他手段,将log同步到最新状态。(一般来说周期性的快照不会落后最新版本太多,所以恢复工作要少得多)
这里可以扩展考虑一些场景,比如Raft集群中加入新的follower时,可以让leader将自己的snapshot传递给follower,帮助follower快速同步到近期的状态,尽管可能还是有些落后最新版本,但是根据后续log catch up等机制可以帮助follower随后快速跟进到最新版本log。
使用快照时,需要注意几点:
- 需要拒绝旧版本的快照:有可能收到的snapshot比当前服务状态还老
- 需要保持快照后的log数据:在加载快照时,如果有新log产生,需要保证加载快照后这些新产生的log能够能到保留
问题:看上去好像这破坏了抽象的原则,现在上层应用需要感知Raft的动作?
回答:是的,这里需要上层应用辅助一些Raft的工作,比如告知Raft我已经拥有i之前的快照了,可以对应的删除Raft在i状态之前的log了之类的。
问题:如果follower收到snapshot,这是它日志的前缀,由快照覆盖的log记录将被删除,而其余的会被保留。这种情况下,状态机是否会被覆盖?
回答:前面没有什么问题,这里主要需要关注快照如何和状态机通信。在课程实验中,状态机通过apply channel获取快照,然后做后续需要做的事情(比如根据快照,修改状态机中的变量之类的)。
7.6 使用Raft
重新回顾一下服务使用Raft的大致流程
- 应用程序中集成Raft相关的library包
- 应用程序接收Client请求
- 应用程序调用Raft的start函数/方法
- 下层Raft进行log同步等流程
- Raft通过apply channel向上层应用反应执行完成
- 应用程序响应Client
- 并且前面提过,可能作为leader的Raft所在服务器宕机,所以Client必须维护server列表来切换请求的目标server为新的leader服务器。
- 同时,有时候请求会失败,或者Raft底层失败,导致重复请求,而我们需要有手段辨别重复的请求。通常可以在get、put请求上加上请求id或其他标识来区分每个请求。一般维护这些请求id的服务,被称为clerk。提供服务的应用程序通过clerk维护每个请求对应的id,以及一些集群信息。
7.7 线性一致性/强一致性(Linearizability/strong consistency)
线性一致性(Linearizability),或称原子一致性或严格一致性,指的是程序在执行的历史中在存在可线性化点P的执行模型,这意味着一个操作将在程序的调用和返回之间的某个点P起作用。这里“起作用”的意思是被系统中并发运行的所有其他线程所感知。
在论文中对整个系统提供的服务的正确性称为**线性一致性(Linearizability)**,线性一致性需要保证满足一下三个条件:
整体操作顺序一致(total order of operations)
即使操作实际上并发进行,你仍然可以按照整体顺序对它们进行排序。(即后续可以根据读写操作的返回值,对所有读写操作整理出一个符合逻辑的整体执行顺序)
实时匹配(match real-time)
顺序和真实时间匹配,如果第一个操作在第二个操作开始前就完成,那么在整体顺序中,第一个操作必须排在第二个操作之前(换言之如果这么排序后,整体的执行结果不符合逻辑,那么就不符合”实时匹配”)。
读操作总是返回最后一次写操作的结果(read return results of last write)
问题:这里说的线性一致性,是不是就是人们说的强一致性?
回答:是的。一般直觉就是表现上像单机,而技术文献中准确定义称为线性一致性。
问题:人们为什么决定定义这个property?(指,线性一致性这个概念为啥会被定义出来)
回答:比如你希望多机系统对外表现如同单机一样,线性一致性就是非常直观的定义。数据库世界中有类似的术语,叫做**可串行化(serializability)**。基本上线性一致性和可串行化的唯一区别是,**可串行化不需要实时匹配(match real-time)**。当然,人们对强一致性有不同定义,而我们这里认为线性一致性就是一种强一致性。
问题:可以稍微详细一点介绍clerk吗?
回答:clerk是一个RPC库,它可以帮助记录请求的RPC服务器列表。比如它认为server1是leader,于是Client发请求时,通过clerk会发送到server1,如果server1宕机了,也许clerk根据维护的server列表,会尝试将Client的请求发送到server2,猜测server2是leader。并且clerk会标记每次请求(get、put等),生成请求id,可以帮助server服务检测重复的请求。
问题:论文12页中提到follower擦除旧log,但是不能回滚状态机,是吗?
回答:正如前面日志擦除所说,Raft可以擦除未提交(uncommitted)的log。
问题:server加载snapshot的时候,怎么保证后续还可以接收新的log
回答:可以在加载snapshot之前,先通过COW写时复制的fork创建子进程,子进程加载snapshot,而父进程继续提供服务,例如获取新的log之类的。因为子进程和父进程共享同样的物理内存,所以后续总有办法使得加载完snapshot的子进程获取父进程这段时间内新增的log。
问题:当生成snapshot且因此压缩/删除旧log后,sever维护的log index是从0开始,还是在原本的位置继续往后?
回答:从原本的位置继续往后,不会回退log index索引。
Lecture8 Lab2A_2B Q&A
Lecture9 Zookeeper
高性能(high perference):
- 异步(asynchronous)
- 提供一致性,但非强一致性(consistency)
通用的协调服务(Coordination service)
9.1 Zookeeper复制状态机(replicated state machine)
首先,Zookeeper是一个复制状态机(zookeeper is replicated state machine)。
类似Raft流程,Zookeeper对外服务时:
- Client访问Zookeeper,create一个Znode
- Zookeeper调用ZAB库(类似Raft库),生成操作log,ZAB负责和Zookeeper集群的其他机器完成类似Raft的工作,日志同步、心跳保活等(整体思想和Raft类似,但实现方式不同)
- ZAB保证日志顺序
- 能避免网络分区、脑裂问题
- 同样要求操作都是具有确定性的(换言之不会有非确定性的操作在ZAB之间传递)
- ZAB完成日志同步等工作后,回应Zookeeper
- Zookeeper处理逻辑,响应Client的create请求
在Zookeeper中,维护着由znode组成的tree树结构。
由于ZAB整体思路和Raft类似,这章节不会再重点讨论ZAB,我们主要围绕Zookeeper展开话题
9.2 Zookeeper吞吐量
视频展示一张论文中的图片,大意就是:
- 写请求占比高时,Zookeeper实例机器越多,吞吐量越低(3台21K/s,13台9K/s)
- 读请求占比高时,Zookeeper实例机器越多,吞吐量越高
为什么能有如此高的吞吐,大致原因如下,Zookeeper有以下几种策略/设计:
异步(asynchronous)
操作都是异步的,Client可以一次向Zookeeper提交多个操作。比如Client一次提交多个put(批量操作),但是实际上leader只向持久存储写入一次(而不是写入多次),即Zookeeper批量整合多次写操作,只进行一次磁盘写入操作。
读请求可以由任意server处理(read by any server)
- 这里不需要通过leader完成read操作,任何zookeeper实例节点都可以完成read操作
- 并且其他zookeeper完成read操作时,不需要和leader有任何网络通信
由于”读请求可以由任意server处理(read by any server)”,所以在Zookeeper中,写后读可能读取到旧值。
思考如下场景,有一个3实例组成的Zookeeper集群:
- Client1向Zookeeper的leader进行put写请求(将X从0写成1)
- Zookeeper根据majority原则,只需要自己和另一个Zookeeper实例将log写入稳定存储即可
- 假设leader为Z1,则Z1、Z2完成log写入后,Z1响应Client
- 过了很长一段时间后,另一个Client2再通过get请求向Zookeeper读取X,读取结果为什么?
- 读取X为0,Client2正好读取到Z3,而Z3没有被写入log,所以X还是0
- 读取X为1,Client2正好读取到Z1或Z2,所以X是1
从这里可以看出来,Zookeeper的读写,不是线性一致性(Linearizability)的:
- 因为违背了”7.7 线性一致性/强一致性(Linearizability/strong consistency)”的规则2——**实时匹配(match real-time)**。这里Client向Zookeeper写入数据后的很长一段时间再进行读操作,很明显第一个写操作在第二个读操作开始前就完成,那么读操作需要返回X=1,才能满足”实时匹配(match real-time)”。
- 同时,也违背了规则3——**读操作总是返回最后一次写操作的结果(read return results of last write)**。这里最后一次写操作导致X=1,那么很长时间后进行的读操作,应该读取X=1而不是X=0。
这里如果想保证read能维持线性一致性,简单的做法就是每次read都请求leader。当然你可以用其他方式来保证。
9.3 Zookeeper的一致性规则
8.5 一致保证(Consistency Guarantees) - MIT6.824 (gitbook.io) <= 网络博主的笔记,这里摘抄部分,补充说明
Zookeeper的一致性规则:
写请求是线性一致性的(linearizable writes)
对于所有的客户端发起的写请求,整体是线性一致性的。
同一个客户端的请求按照FIFO顺序被执行(FIFO client order)
这里的意思是,如果一个特定的客户端发送了一个写请求之后是一个读请求或者任意请求,那么首先,所有的写请求会以这个客户端发送的相对顺序,加入到所有客户端的写请求中(满足保证1)。所以,如果一个客户端说,先完成这个写操作,再完成另一个写操作,之后是第三个写操作,那么在最终整体的写请求的序列中,可以看到这个客户端的写请求以相同顺序出现(虽然可能不是相邻的)。所以,对于写请求,最终会以客户端确定的顺序执行。
对于读请求,这里会更加复杂一些。我之前说过,在Zookeeper中读请求不需要经过Leader,只有写请求经过Leader,读请求只会到达某个副本。所以,读请求只能看到那个副本的Log对应的状态。对于读请求,我们应该这么考虑FIFO客户端序列,客户端会以某种顺序读某个数据,之后读第二个数据,之后是第三个数据,对于那个副本上的Log来说,每一个读请求必然要在Log的某个特定的点执行,或者说每个读请求都可以在Log一个特定的点观察到对应的状态。然后,后续的读请求,必须要在不早于当前读请求对应的Log点执行。也就是一个客户端发起了两个读请求,如果第一个读请求在Log中的一个位置执行,那么第二个读请求只允许在第一个读请求对应的位置或者更后的位置执行。第二个读请求不允许看到之前的状态,第二个读请求至少要看到第一个读请求的状态。这是一个极其重要的事实,我们会用它来实现正确的Zookeeper应用程序。
这里特别有意思的是,如果一个客户端正在与一个副本交互,客户端发送了一些读请求给这个副本,之后这个副本故障了,客户端需要将读请求发送给另一个副本。这时,尽管客户端切换到了一个新的副本,FIFO客户端序列仍然有效。所以这意味着,如果你知道在故障前,客户端在一个副本执行了一个读请求并看到了对应于Log中这个点的状态,当客户端切换到了一个新的副本并且发起了另一个读请求,假设之前的读请求在这里执行,那么尽管客户端切换到了一个新的副本,客户端的在新的副本的读请求,必须在Log这个点或者之后的点执行。
这里工作的原理是,每个Log条目都会被Leader打上zxid的标签,这些标签就是Log对应的条目号。任何时候一个副本回复一个客户端的读请求,首先这个读请求是在Log的某个特定点执行的,其次回复里面会带上zxid,对应的就是Log中执行点的前一条Log条目号。客户端会记住最高的zxid,当客户端发出一个请求到一个相同或者不同的副本时,它会在它的请求中带上这个最高的zxid。这样,其他的副本就知道,应该至少在Log中这个点或者之后执行这个读请求。这里有个有趣的场景,如果第二个副本并没有最新的Log,当它从客户端收到一个请求,客户端说,上一次我的读请求在其他副本Log的这个位置执行,那么在获取到对应这个位置的Log之前,这个副本不能响应客户端请求。
更进一步,FIFO客户端请求序列是对同一个客户端的所有读请求,写请求生效。所以,如果我发送一个写请求给Leader,在Leader commit这个请求之前需要消耗一些时间,所以我现在给Leader发了一个写请求,而Leader还没有处理完它,或者commit它。之后,我发送了一个读请求给某个副本。这个读请求需要暂缓一下,以确保FIFO客户端请求序列。读请求需要暂缓,直到这个副本发现之前的写请求已经执行了。这是FIFO客户端请求序列的必然结果,(对于某个特定的客户端)读写请求是线性一致的。最明显的理解这种行为的方式是,如果一个客户端写了一份数据,例如向Leader发送了一个写请求,之后立即读同一份数据,并将读请求发送给了某一个副本,那么客户端需要看到自己刚刚写入的值。如果我写了某个变量为17,那么我之后读这个变量,返回的不是17,这会很奇怪,这表明系统并没有执行我的请求。因为如果执行了的话,写请求应该在读请求之前执行。所以,副本必然有一些有意思的行为来暂缓客户端,比如当客户端发送一个读请求说,我上一次发送给Leader的写请求对应了zxid是多少,这个副本必须等到自己看到对应zxid的写请求再执行读请求。
再次声明,Zookeeper并不提供读的线性一致性(“9.2 Zookeeper吞吐量”有进行过场景分析了)。
Zookeeper并不是遵循线性一致性实现的,它有自己的一致性定义和实现:
线性化写入(Linearize write)
所有的写入操作,必须经过Zookeeper的leader。底层会将生成的log以相同的顺序同步到所有zookeeper节点的log记录中。(即对于写入操作,还是应用复制状态机的方案进行majority的写同步)
先进先出队列维护Client请求(FIFO client order)
尽管请求是异步的,所有的client请求,在zookeeper实例中以FIFO的形式维护。即如果client1先于client2请求,那么client2的处理一定在client1之后,client2的请求能观测到client1的操作结果。
按client请求进行写操作(write in client order)
这是FIFO client order的附带产物,很好理解。因为client请求以FIFO顺序被zookeeper处理,所以写操作也是按照client请求顺序生效。
读操作能观测到同一个client的最后一次写操作(read obverse last write from same client)
如果相同的client执行完写操作后,立即进行读操作,那么至少可以看到自己的写入结果。换言之,如果是其他client在前一个client写后进行读,zookeeper并不保证能读取到前一个client的写结果。
读操作会观察到日志的某些前缀(read will observe some prefix of the log)
这意味着你可以看到旧数据,可能某个follower有指定前缀的log,但是log里面没有最新的值记录,但是follower仍然可以返回读取的结果。因为zookeeper只保证读取可以观察到log的前缀。按照这个特定,读取可以不按照顺序。
不能读取旧前缀的数据(no read from from the past)
这意味着如果你第一次看到了前缀prefix 1,然后你发出读取前缀prefix 1。然后你执行第二次读取,第二次读取必须至少看到prefix 1或者更大的前缀数据(比如prefix 2),但是绝不能看到比precix 1更小的前缀。
9.4 Zookeeper的一致性实现
8.6 同步操作(sync) - MIT6.824 (gitbook.io)
Zookeeper有一个操作类型是sync,它本质上就是一个写请求。假设我知道你最近写了一些数据,并且我想读出你写入的数据,所以现在的场景是,我想读出Zookeeper中最新的数据。这个时候,我可以发送一个sync请求,它的效果相当于一个写请求,所以它最终会出现在所有副本的Log中,尽管我只关心与我交互的副本,因为我需要从那个副本读出数据。接下来,在发送读请求时,我(客户端)告诉副本,在看到我上一次sync请求之前,不要返回我的读请求。
如果这里把sync看成是一个写请求,这里实际上符合了FIFO客户端请求序列,因为读请求必须至少要看到同一个客户端前一个写请求对应的状态。所以,如果我发送了一个sync请求之后,又发送了一个读请求。Zookeeper必须要向我返回至少是我发送的sync请求对应的状态。
不管怎么样,如果我需要读最新的数据,我需要发送一个sync请求,之后再发送读请求。这个读请求可以保证看到sync对应的状态,所以可以合理的认为是最新的。但是同时也要认识到,这是一个代价很高的操作,因为我们现在将一个廉价的读操作转换成了一个耗费Leader时间的sync操作。所以,如果不是必须的,那还是不要这么做。
论文中没有特别详细的说明Zookeeper怎么实现”9.3 Zookeeper的一致性规则”中制定的规则,但是我们可以大致猜测其实现。
- 当客户端想要连接zookeeper服务时,会创建一个session,它使用session信息连接到zookeeper集群,并在整个session期间维护状态state。
- Client创建session后和Zookeeper的leader建立连接,随后发起一个write写请求
- 类似Raft流程,leader生成一个log插入到log记录中,其索引称为zxid。
- leader类似Raft进行log日志同步,将log同步到majority数量的节点(包括自己)
- leader响应Client,同时返回zxid给客户端,客户端会在session中存储这次写入的zxid信息
- Client向zookeeper发起read请求,这个read使用上次写入返回的zxid标记
- 假设被请求的follower正好没有这个zxid对应的log记录,于是它会等待直到收到leader的这条zxid同步log后,才会响应Client
- 此时假设Client又发起write请求,并且最后在leader和follower1产生zxid=1
- 随后Client发起read请求,但携带的zxid=0(假设是最早一次写返回的),并且读取的是follower2
- follower2正好有zxid=0的log记录,尽管它还没有zxid=1的记录,但是它仍会响应client的读zxid=0的请求。**这意味着Zookeeper存在读取旧值的情况(但不允许主动读取旧值)**,这里说不定zxid=1的记录是某个变量的新值,而zxid=0则是旧值(注意,这里如果follower2已经有了zxid=1的记录后,会返回zxid=1的值,而不是返回zxid=0的值,因为不允许返回旧log前缀的数据)。
问题:据我所知,好像一般session具有粘性,即上面读写应该会尽可能发生在同一个zookeeper节点,所以上面流程是可能发生的吗?
回答:这里可以假设曾经发生过一个短暂的网络分区或类似的事情,所以上面的流程是可能发生的。另外zookeeper做了一些负载均衡,但是无论如何,上面流程是可能发生的。
问题:上面写入时说zookeeper会返回zxid,是不是需要已经commit了才会返回zxid?
回答:是的,类似Raft流程,这里需要log被commit后,才会返回zxid。
问题:这里后续的read携带zxid=0,但是系统中已经有节点存在zxid=1的数据了,看上去似乎违背了zookeeper一致性原则中的”不能读取旧前缀的数据(no read from from the past)”的规则?因为看上去client好像在故意请求日志中特定的前缀数据,而且还是读取旧的数据。
回答:实际上,这里zxid含义上表示阻止时间倒流的计数器,作为follower必须至少含有zxid值截止的日志前缀,才能够响应client,而如果你有更高的zxid并不会有问题。这阻止了故意读取旧数据的可能性。
学生提问:也就是说,从Zookeeper读到的数据不能保证是最新的?
Robert教授:完全正确。我认为你说的是,从一个副本读取的或许不是最新的数据,所以Leader或许已经向过半服务器发送了C,并commit了,过半服务器也执行了这个请求。但是这个副本并不在Leader的过半服务器中,所以或许这个副本没有最新的数据。这就是Zookeeper的工作方式,它并不保证我们可以看到最新的数据。Zookeeper可以保证读写有序,但是只针对一个客户端来说。所以,如果我发送了一个写请求,之后我读取相同的数据,Zookeeper系统可以保证读请求可以读到我之前写入的数据。但是,如果你发送了一个写请求,之后我读取相同的数据,并没有保证说我可以看到你写入的数据(这里同一个人表示同一个client)。这就是Zookeeper可以根据副本的数量加速读请求的基础。
学生提问:那么Zookeeper究竟是不是线性一致呢?
Robert教授:我认为Zookeeper不是线性一致的,但是又不是完全的非线性一致。首先,所有客户端发送的请求以一个特定的序列执行,所以,某种意义上来说,所有的写请求是线性一致的。同时,每一个客户端的所有请求或许也可以认为是线性一致的。尽管我不是很确定,Zookeeper的一致性保证的第二条可以理解为,单个客户端的请求是线性一致的。
学生提问:zxid必须要等到写请求执行完成才返回吗?
Robert教授:实际上,我不知道它具体怎么工作,但是这是个合理的假设。当我发送了异步的写请求,系统并没有执行这些请求,但是系统会回复我说,好的,我收到了你的写请求,如果它最后commit了,这将会是对应的zxid。所以这里是一个合理的假设,我实际上不知道这里怎么工作。之后如果客户端执行读请求,就可以告诉一个副本说,这个zxid是我之前发送的一个写请求。
9.5 Zookeeper中watch通知
Zookeeper——Watch机制原理_庄小焱的博客-CSDN博客_zookeeper watch <= 推荐阅读
大体上讲 ZooKeeper 实现的方式是通过客服端和服务端分别创建有观察者的信息列表。客户端调用 getData、exist 等接口时,首先将对应的 Watch 事件放到本地的 ZKWatchManager 中进行管理。服务端在接收到客户端的请求后根据请求类型判断是否含有 Watch 事件,并将对应事件放到 WatchManager 中进行管理。
在事件触发的时候服务端通过节点的路径信息查询相应的 Watch 事件通知给客户端,客户端在接收到通知后,首先查询本地的 ZKWatchManager 获得对应的 Watch 信息处理回调操作。这种设计不但实现了一个分布式环境下的观察者模式,而且通过将客户端和服务端各自处理 Watch 事件所需要的额外信息分别保存在两端,减少彼此通信的内容。大大提升了服务的处理性能。
需要注意的是客户端的 Watcher 机制是一次性的,触发后就会被删除。
zookeeper的watch机制原理解析_java_脚本之家 (jb51.net) <= 推荐阅读,具体的指令操作示例,很好理解
8.7 就绪文件(Ready file/znode) - MIT6.824 (gitbook.io) <= 2021版这里讲得不太清楚,可以看看网络上2020版对于watch的讲解
这里举了一些例子,大概就是在讨论怎么让read读取到最后的write。然后提到zookeeper提供的watch监听指定写事件的变化,zookeeper保证被监听的写事件发生后,会在下一次写操作发生前完成事件通知。
9.6 ZNode API
9.1 Zookeeper API - MIT6.824 (gitbook.io) <= 可以参考这个笔记,里面更详细
回忆一下Zookeeper的特点:
- Zookeeper基于(类似于)Raft框架,所以我们可以认为它是,当然它的确是容错的,它在发生网络分区的时候,也能有正确的行为。
- 当我们在分析各种Zookeeper的应用时,我们也需要记住Zookeeper有一些性能增强,使得读请求可以在任何副本被处理,因此,可能会返回旧数据。
- 另一方面,Zookeeper可以确保一次只处理一个写请求,并且所有的副本都能看到一致的写请求顺序。这样,所有副本的状态才能保证是一致的(写请求会改变状态,一致的写请求顺序可以保证状态一致)。
- 由一个客户端发出的所有读写请求会按照客户端发出的顺序执行。
- 一个特定客户端的连续请求,后来的请求总是能看到相比较于前一个请求相同或者更晚的状态(详见8.5 FIFO客户端序列)。
通常来说会给应用app1创建一个znode节点,然后znode下再挂在一些子节点,上面记录app1的一些属性,比如IP等。
ZNode有三种类型:
- regular:常规节点,它的容错复制了所有的东西
- ephemeral:临时节点,节点会自动消失。比如session消失或Znode有段时间没有传递heartbeat,则Zookeeper认为这个Znode到期,随后自动删除这个Znode节点
- sequential:顺序节点,它的名字和它的version有关,是在特定的znode下创建的,这些子节点在名字中带有序列号,且节点们按照序列号排序(序号递增)。
- create接口,参数为path、data、flags。
create(path, data, flags),这里flags对应上面ZNode的3种类型 - delete接口,参数为path、version。
delete(path, version) - exists接口,参数为path、watch。
exists(path, watch) - getData原语,参数为path、version。
getData(path, version) - setData原语,参数为path、data、version。
setData(path, data, version) - getChildren接口,参数为path、watch。
getChildren(path, watch),可以获取特定znode的子节点
9.7 Zookeeper-小结
- 较弱的一致性(weaker consistency)
- 适合用于当作配置服务(configuration)
- 高性能(high perference)
Lecture10 Patterns and Hints for Concurrency in Go
这个建议直接看视频,讲师主要围绕一些业务场景举例go代码实现和优化技巧。go虽然学过,但并不是我主要用于项目编程的语言,所以这里不打算做太多笔记。
10.1 一些优化go代码的思路
在能简化程序理解的前提下,同一个程序的代码实现,可以考虑将数据状态转变成代码状态(Convert data state into code state when it make programs clearer)
视频中举例的是一个正则表达式的匹配
/"([^"\\]|\\.)*"/,可以用一个看着很复杂的swith-case程序实现(数据状态),但是通过一系列优化后,最后变成只有两个if和一个for语句,并且更容易读懂和理解。优化前的原始代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22state := 0
for {
c := readChar()
switch state {
case 0:
if c != '"' {
return false
}
state = 1
case 1:
if c == '"' {
return true
}
if c == '\\' {
state = 2
} else {
state = 1
}
case 2:
state = 1
}
}优化后的代码(正巧执行也更快,但不是这里讲解的重点,重点是易读性):
1
2
3
4
5
6
7
8
9
10
11
12
13
14func readString(readChar func() rune) bool {
if readChar() != '"' {
return false
}
var c rune
for c != '"' {
c := readChar()
if c == '\\' {
readChar()
}
}
return true
}可通过启动新的goroutine来存储code state代码状态(Use additional goroutines to hold addional code state)
这让我们可以移动程序计数器,将我们不能在原本stack上完成的逻辑,转移到goroutine的栈上去完成。当然创建goroutine需要保证其能够被清除,避免内存泄漏问题。
可通过启动新的goroutine来完成mutex条件变量的工作,如果能简化代码的话(Convert mutexes into goroutines when it makes progrmas clearer)
这里视频通过发布订阅服务器的代码实现举例,大意就是原本的发布订阅相关的方法中,需要用mutex保护临界区map的读写,会有频繁的加锁、解锁流程。而改写代码后,通过新启动一个goroutine维护这个map,原本的线程通过channel与这个goroutine交互,不再需要加锁、解锁流程(这里其实相当于利用channel代替锁的功能,channel本身会阻塞直到读写方都准备好,其实内部也是有锁,只是不需要开发者再显示声明锁)。
10.2 设计模式1: 发布订阅服务器(Publish/subscribe server)
10.3 设计模式2: 工作调度器(Worker scheduler)
10.4 设计模式3: 复制服务的客户端(Replicated service client)
10.5 设计模式4: 协议选择器(protocol multiplexer)
Lecture11 链式复制(Chain Replication)
11.1 Zookeeper锁
一开始提到一种粗糙的zookeeper锁实现方式,利用zookeeper的write具有线性一致性的规则,可以靠Zookeeper提供的原语实现Lock和Unlock。
粗糙的Lock实现中,大致逻辑即:
- 尝试创建一个临时znode节点(ephemeral),如果存在则返回(表示获取到锁)
- 如果znode节点已存在exist,则阻塞wait等待(这里通过watch监听znode变更事件),直到znode消失/被删除后,重新发起create一个znode请求(尝试获取锁)
- 获取锁后,解锁只需要delete之前创建的临时znode即可。
这里就算client请求Lock后突然崩溃,Zookeeper也会检查请求Lock的client是否存活,如果client崩溃,则zookeeper服务端会删除这个client的记录,取消Lock动作。
看上去这个Lock没什么问题,能保证多个client请求Lock时也只有一个能获取Lock。问题是会造成羊群效应,即1000个client请求,只有1个成功,剩下999个等待,下次lock释放后,又只有1个成功,998个失败后等待,尽管每次只有1个client能获取锁,却伴随大量的Lock请求,是个灾难。
一个更优的Lock实现伪代码(论文中的伪代码)如下:
1 | |
可以看到这里没有retry重试加锁的请求操作(前面的粗糙实现中,所有未成功获取锁的客户端都将重试获取),相反的,所有的客户端排成一条线,按序获取锁。
1行的
SEQUENTIAL意味着锁文件被创建时,第一个将是”lock-0”,下一个是”lock-1”,以此类推…。这里n获取到对应的序列号,比如第一个锁文件返回n=0按照前面举例1000个client最后会创建”lock-0”~”lock-999”这1000个锁文件。
3行,如果当前n已经是创建的znode中锁文件序号最小的,则返回,表示获取锁成功
4行,表示当前n不是当前最小的锁序号,于是获取n的前一个序号,比如n=10,则p=9
5行,这里对p序号对应的锁文件加上watch,表示前一个client通过Unlock删除锁文件后,下一个也就是当前自己这个client就会监听到事件,然后重新goto代码2行走一遍逻辑,此时n会是最小的锁序号,所以当前client获取到lock,然后返回
这种锁也被称为**标签锁(ticket locks)**。
需要注意的是,这里zookeeper的锁(下面简称为zlock),和go里面的lock不一样。
一旦zookeeper确认zlock的持有者failed了(比如通过session的心跳机制等),我们会看到一些中间状态(intermediate state)。持有zlock的client崩溃后,zookeeper会撤销client原本持有的zlock锁。而由于锁被撤销了,会导致临界区的访问出现一些中间状态(因为不再受锁保护了),而log可以保证临界区访问的正确性。
zlock一般应用场景:
- **选举(leader election)**:从一堆client中选举一个leader。并且如果有必要,可以让leader清理中间状态(临界区的一些状态值,比如把state清0之类的)。
- **软锁(“soft” lock)**:通常执行map只需要一个mapper,可以通过软锁保证mapreduce的worker中一次只有一个mapper接受某个特定的map任务。当然,这里mapeer如果failed,锁就会被释放,然后其他mapper可以尝试获取锁,重新执行这个mapper任务。而对于mapreduce程序来说,重复执行(执行两次)是可接受的,因为函数式编程,相同输入下运行几次都应该有相同的输出结果。
问题:前面粗糙版本的Zookeeper锁实现中,zookeeper是怎么确定client已经failed,从而释放ephemerial锁?比如通常只是出现短暂的网络分区。
回答:因为client和zookeeper交互时会创建session,zookeeper需要和client在session中互相发送心跳,如果zookeeper一段时间没有收到client的心跳,那么它认为client掉线,并关闭session。session关闭后,即使client想在原session上发送消息,也行不通。而这个session期间被创建的ephermeral文件在session关闭后会被删除。假设client因为网络分区联系不上,如果超过zookeeper容忍的心跳检测阈值,那么zookeeper会关闭session,client必须重新创建一个session。
问题:在zlock中,如果持有锁的server宕机,那么zlock会被撤销。但是不是没宕机,也一样会被撤销,因为zlock有一个标记是”EPHEMERAL”。
回答:是的。只有EPHEMERAL文件才会发生这种情况(锁被撤销,因为client不管什么原因导致的session被关闭后,session周期内存活的EPHEMERAL锁文件自然会被删除)。
追问:那么我们能不能通过不传递EPHEMERAL,来模拟go锁?
回答:你可以这么做,但是一旦宕机后就没有其他cleint能够释放这个锁文件了,会导致死锁。因为能释放这个lock文件的client宕机了,并且去掉EPHEMERAL后,锁文件永久存在,其他client排队永远无法获取锁,而且也没法释放不属于自己的锁文件来解围(这时就需要人工介入删除指定的lock文件了)。这就是为什么zlock需要EPHEMERAL,保证只在session内存活,避免死锁问题。
追问:client宕机后,其他client真的不能删除这个lock文件吗?理论上只要想的话,其他client可以通过自己编写的delete来删除lock文件吧?
回答:这是一个共识问题(consensus problem),你当然可以通过delete任意删除别人的lock。但是这么做的话,lock本身就没有太大意义了,因为lock本身就是为了保护临界区访问,但是你破坏了规则,任何人可以随意删除其他人的锁。
问题:可以再解释一下”soft” lock软锁吗?
回答:软锁意味着一个操作可以发生两次。正常情况下,一个map被mapper施行成功后,会释放zlock,一切正常。但是mapper中途失败后,由于session断开,zookeeper撤销这个zlock,其他mapper会获取锁,接替原本的mapper执行map任务,也就是说map会被执行两次。但是这里是可接受的,因为mapreduce是函数式编程,相同输入运行几次都得有相同的输出。
问题:在leader选举的zlock使用举例中,这里可以暴露的中间状态(intermediate state)是指什么?
回答:纯粹的leader election不会有中间状态,但是通常leader会创建配置文件,就像zookeeper那样,使用ready trick。(提问者补充表示懂了,所以leader把文件整个创建好,然后原子地进行convert并且rename。讲师表示没错)。
问题:能解释一下zookeeper的ready trick指的是什么吗?
回答:讲师表示事件不多,课后问再回答,并表示上次说过了。(这里ready file应该指的是watch机制讲解的时候提的用例,即client监听ready file的变更事件,然后作出一些动作)可以参考更详细的关于ready file举例的网络笔记 => 8.7 就绪文件(Ready file/znode) - MIT6.824 (gitbook.io)
11.2 两种构造RSM(复制状态机)的方案
这里简单提一下两种构造复制状态机(RSM, replicated state machine)的方案
Run all options through Raft/Paxos:通过Raft/Paxos或其他共识算法,完成所有的操作
事实证明,这种通过Raft/Paxos这类共识算法运行所有操作的方式,在实际应用中并不常见。这并不完全是一种标准的方法(指用于实现复制状态机)。后续会介绍一些其他的设计来实现这一点,比如Spanner。
*Configuration service + P/B replication(primary backup replication)**:**更常见的是通过一个配置服务器*(比如zookeeper服务),配置服务器内部可能使用Paxos、Raft、ZAB或其他共识算法框架,配置服务器扮演者coordinator或master的角色(比如GFS的master)。**这里配置服务器除了采用共识算法实现外,还可以运行主备复制(P/B replicaiton)**。
- 比如GFS虽然只有一个master,但是chunk服务器却有primary和一堆backups,它们有一个用于主备复制的协议。
- 而VM-FT中,配置服务器是test-and-set的storage服务器,其决定谁是primary,另一方则是backup,primary和back之间通过channel或其他形式同步log等数据,尽管略有延迟。
相比第一个方案,第二种方案更常见和通用。
采用配置服务器+主备复制的特点:
- 复制服务在状态state维护的成本较低,一般需要维护的数据量很少
- 主备复制则主要负责大量的数据复制工作
而直接用共识算法实现复制状态机,往往意味着需要直接在提供服务的server之间来回进行大量的数据复制,检查点的state数据同步等工作,一般实现会更复杂。
问题:方案1比起方案2有什么好处吗?
回答:你不需要同时使用它们两个,只需要选择一种。方案1中,你每运行操作,Raft就为你进行同步,所有的东西都集成在单一的组件中(包括主备同步等操作);而在方案2中,我们拆分出2个组件,一个配置服务中可以包括Raft,而同时我们有主备方案,这分工更加清晰。
问题:那方案2有什么优势吗?如果通过leader达成共识,leader永远不会失败,对吧。
回答:方案2的优势,在随后准备介绍的链式复制中会看到。有一个单独的进程负责配置部分的工作,你不必担心你的主备复制方案。对比的话,GFS的master指定某几个server组成一个特定的replica group。而这里主备协议不用考虑这个问题。
11.3 链式复制-概述
MIT 6.824 - Chain Replication for Supporting High Throughput and Availability - 知乎 (zhihu.com)
链式复制,就是上面提到的方案2的主备复制方案(P/B replication)。
在论文中,**链式复制(Chian replicaiton)假设系统中存在一个配置服务(Configuration service)作为master,然后链式复制本身有一些属性(properties)**:
- 读操作/查询操作(read operation / query operation)只涉及一个服务器(reads ops involve 1 server)
- 具有简单的恢复方案(simple recovery plan)
- 线性一致性(linearizability)
整体来说,这是一个很成熟的设计,已经应用到诸多系统中。
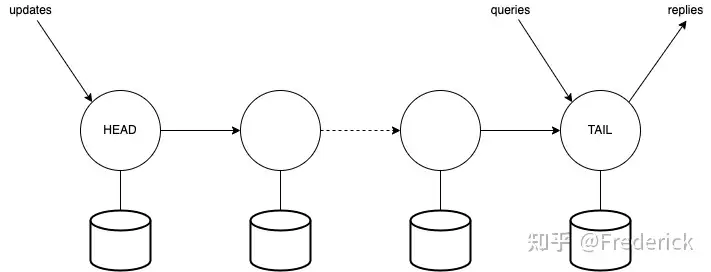
在链式复制系统中,首先有一个配置服务(configuration service)记录链式连接的节点信息。
- client向系统发起write请求,write写请求总是会发送到链中的head节点服务器
- head节点生成log等,通过storage稳定存储更新相关state状态,然后传递操作到下一个节点
- 下一个节点同样更新自己storage中的state状态,然后向下一个节点传递操作
- 直到最后一个tail尾节点,修改storage中的状态后,向client回应确认信息。
如果你需要更高的可用性(容错性),你可以增加链中的节点数量。
这里tail尾节点就是提交点(commit point),因为后续读取总是从tail尾节点获取。任何client发起读请求,都会请求tail节点,而tail节点会立即响应。
写请求总是发送到head节点
head修改storage中的state后,向下传递操作,直到tail节点。中间的节点总是更新state,然后向下传递操作。最后由tail节点响应client。
读请求总是发送到tail节点
tail节点直接响应client读请求。
可以看到的是,这里读写工作负载至少分布在两台服务器上。对于更多的读操作,只需要一台服务器支持,且能够快速回应,这使得我们有很多优化空间(后续介绍)。
而这里称tail尾节点为提交点(commit point),因为写入发生在尾部的节点,只有在那里写操作可以被读者看见,这也提供了线性一致性(因为所有写操作都需要经过head到最后tail节点才会生效,且实际应答读和写请求的只有tail节点,只要系统没有崩溃的情况下,client进行写后读操作,一定会观察到最后一次或最近一次写入的结果,但不会读到旧数据)。
假设写请求不需要等到tail回应,而是head直接回应,那会破坏线性一致性吗?假设head收到写请求后,同样向链表往后的节点同步操作信息,但是又马上响应Client,那么之后Client读tail节点可能获取不到刚写入的数据,很明显违背了线性一致性。
11.4 链式复制-崩溃(Crash)
有趣的是,链式复制的失败场景是有限的,共3种crash场景:
- 头节点故障(head fail)
- 中间节点故障(one of the intermediate server fail)
- 尾节点故障(tail fail)
这里假设有S1、S2、S3构成链式复制的3台服务器,其中S1作为head,S3作为tail。简单分析一下系统如何应对3种crash:
头节点故障(处理最简单)
假设client请求head时,head崩溃了。那么这里S1未向下同步的log记录可以丢弃,因为还没有真正commit。此时,配置服务器得知S1宕机后,会通知S2、S3,宣布S2称为新的head,而S1被抛弃。之后client请求失败后会重试,请求新的head,S2节点。
中间节点故障(处理相对复杂)
类似的,S2故障后,某一时刻配置服务器通知S1和S3需要组成新的链。并且由于S3可能还没有和S1同步到最新状态(因为有些同步log可能还在S2没有下发,或者本身S2也没有完全同步到S1的l信息),所以还需要额外进行同步流程,将S3同步到和S1一致的状态。
尾节点故障(处理相对简单)
S3故障后,配置服务器通知S1、S2组成新链,其中S2成为新的tail。client可以从配置服务器知道S2是新tail。其他的流程基本没变动。
可以看出来**头节点故障(head fail)**和**尾节点故障(tail fail)处理相对简单,而中间节点故障(one of the intermediate server fail)**相对复杂一点。
重要的是,链式复制的失败处理比起Raft要明显简单得多。简单的原因有二:
- 整个系统以简单的链表维护
- 配置相关的工作交给了专门的配置服务
11.5 链式复制-新增副本(add replica)
正如论文所述,在tail添加新replica最简单,大致流程如下:
- 假设原tail节点S2下新增S3节点,此时client依旧和原tail节点S2交互
- S2会持续将同步信息传递给S3,并且记录哪些log已经同步到S3
- 某时刻S3和S2同步完成,S3通过配置服务告知S2,自己可以成为新的tail
- 配置服务设置S3为新tail
- 后续client改成请求tail节点获取读写响应(client可以通过配置服务知道谁是head、tail)
11.6 链式复制和Raft在主备复制的比较
光从主备复制的角度出发,比较一下链式复制CR(Chain Replication)和Raft。
CR比起Raft的优势:
CR拆分请求RPC负载到head和tail
前面说过CR的head负责接收write请求,而tail节点负责响应wrtie请求和接收并响应read请求。不必像Raft还需要通过leader完成write、read请求
head头节点仅发送update一次
不同于Raft的leader需要向其他所有followers都发送update,CR的head节点只需要向链中的下一个节点发送update。
读操作只涉及tail节点(read ops involve only tail)
尽管Raft做了read优化,follower就算要处理read请求,还是得向其他leader、followers发送同步log,确定自己是否能够响应read(因为follower可能正好没有最新的数据)。而CR中,只需要tail负责read请求,并且tail一定能同步到最新的write数据(因为write的commit point就是tail节点)。
简单的崩溃恢复机制(simple crash recovery)
与Raft相比,CR的崩溃处理更简单。
CR比起Raft的劣势:
一个节点故障就需要重新配置(one failure requires reconfiguration)
因为写入操作需要同步到整个链,写入操作无法确认链中每台机器是否都执行,所以一有fail,就需要重新配置,这意味着中间会有一小段时间的停机。而Raft中只需要majority满足write持久化,就可以继续工作。
11.7 链式复制-并行读优化拓展(Extension for read parallelism)
由于链式复制中,只需要tail响应read请求,这里可以做一些优化的工作,进一步提高read吞吐量。
**基本思路是进行拆分(split)对象,论文中称之为volume,将对象拆分到多个链中(splits object across many chain)**。
例如,现在有3个节点S1~S3,我们可以构造3个Chain链:
- Chain1:S1、S2、S3 (tail)
- Chain2:S2、S3、S1 (tail)
- Chian3:S3、S1、S2 (tail)
这里可以通过配置服务进行一些数据分片shard操作。如果数据被均匀write到Chain1~Chain3,那么读操作可以并行地命中不同的shards,均匀分布下,读吞吐量(read throughput)会线性增加,理想情况下这里能得到3倍的吞吐量。
拆分(split)的好处:
- 得到扩展(scale),read吞吐量提高(shard越多,chain越多,read吞吐量理论上越高)
- 保持线性一致性(linearizability)
问题:在拆分split的场景下,client怎么决定从哪个chain中读取数据?
回答:论文中没有详细说明,或许client可以通过配置服务器得知read请求对应哪个shard,再找出shard对应的chain,然后告知client该请求哪个chain的tail节点。
11.8 链式复制-小结
9.7 链复制的配置管理器(Configuration Manager) - MIT6.824 (gitbook.io) <= 摘抄我觉得有意义的问答内容:
学生提问:为什么存储具体数据的时候用Chain Replication,而不是Raft?
Robert教授:这是一个非常合理的问题。其实数据用什么存并不重要。因为就算我们这里用了Raft,我们还是需要一个组件在产生冲突的时候来做决策。比如说数据如何在我们数百个复制系统中进行划分。如果我需要一个大的系统,我需要对数据进行分片,需要有个组件来决定数据是如何分配到不同的分区。随着时间推移,这里的划分可能会变化,因为硬件可能会有增减,数据可能会变多等等。Configuration Manager会决定以A或者B开头的key在第一个分区,以C或者D开头的key在第二个分区。至于在每一个分区,我们该使用什么样的复制方法,Chain Replication,Paxos,还是Raft,不同的人有不同的选择,有些人会使用Paxos,比如说Spanner,我们之后也会介绍。在这里,不使用Paxos或者Raft,是因为Chain Replication更加的高效,因为它减轻了Leader的负担,这或许是一个非常关键的问题。某些场合可能更适合用Raft或者Paxos,因为它们不用等待一个慢的副本。而当有一个慢的副本时,Chain Replication会有性能的问题,因为每一个写请求需要经过每一个副本,只要有一个副本变慢了,就会使得所有的写请求处理变慢。这个可能非常严重,比如说你有1000个服务器,因为某人正在安装软件或者其他的原因,任意时间都有几个服务器响应比较慢。每个写请求都受限于当前最慢的服务器,这个影响还是挺大的。然而对于Raft,如果有一个副本响应速度较慢,Leader只需要等待过半服务器,而不用等待所有的副本。最终,所有的副本都能追上Leader的进度。所以,Raft在抵御短暂的慢响应方面表现的更好。一些基于Paxos的系统,也比较擅长处理副本相距较远的情况。对于Raft和Paxos,你只需要过半服务器确认,所以不用等待一个远距离数据中心的副本确认你的操作。这些原因也使得人们倾向于使用类似于Raft和Paxos这样的选举系统,而不是Chain Replication。这里的选择取决于系统的负担和系统要实现的目标。不管怎样,配合一个外部的权威机构这种架构,我不确定是不是万能的,但的确是非常的通用。
学生提问:如果Configuration Manger认为两个服务器都活着,但是两个服务器之间的网络实际中断了会怎样?
Robert教授:对于没有网络故障的环境,总是可以假设计算机可以通过网络互通。对于出现网络故障的环境,可能是某人踢到了网线,一些路由器被错误配置了或者任何疯狂的事情都可能发生。所以,因为错误的配置你可能陷入到这样一个情况中,Chain Replication中的部分节点可以与Configuration Manager通信,并且Configuration Manager认为它们是活着的,但是它们彼此之间不能互相通信。这是这种架构所不能处理的情况。如果你希望你的系统能抵御这样的故障。你的Configuration Manager需要更加小心的设计,它需要选出不仅是它能通信的服务器,同时这些服务器之间也能相互通信。在实际中,任意两个节点都有可能网络不通。
前面提到构造复制状态机,有两种方式:
- 传统的只通过Raft/Paxos/ZAB等共识算法实现
- 通过配置服务(通过Raft/Paxos/ZAB等共识算法实现)+主备复制实现(这里我们使用链式复制chain replicaiton)
可以看到这里方案2更吸引人:
- 你能够获取可拓展的读性能(链式复制配合配置服务split几个chain,可以通过shard均匀读请求,提高读吞吐)
- 由于配置服务和主备系统独立,所以如果你有更优秀的共识算法实现的同步机制(synchronization),你更新配置服务的成本更小
因此,人们更偏向于在实际应用中使用方案2。当然也不排除有使用方案1实现复制状态机的,比如你只需要简单的put/get等操作的话。后续会介绍的Spanner就是采用Paxos完成(方案1)。
问题:你前面提到Raft使用时,所有的read需要通过majority的同意,我不懂为什么?因为leader不是有所有的committed entries吗?
回答:你问的是另一种策略实现。最原始的,如果你的read都只经过leader处理,并且保证leader总有最新数据,那么leader可以直接处理read。而另一种策略,你希望follower能处理read,那它必须通过majority来确认自己是否拥有最新的数据,否则应该等待同步到最新的数据后,才响应client的read请求,以确保线性一致性。
问题:我想知道前面”11.5 链式复制-新增副本(add replica)”增加tail时,S3什么时候能成为新的tail,有没有可能S2一直是tail,S3一直没同步完原tail(S2)的数据?
回答:论文中有提到一些切换tail的细节,大概可以这么说,S2可以用snapshot快照之类的手段先将目前所有的同步信息都传递给S3,也许S2同步snapshot给S3时,log到100,当S3同步完时,S2又接收了101~110。此时S3可以告诉S2,剩下的101~110你同步给我后,不要当tail了。之后S3通过配置服务告知client自己是新tail,同时告知client自己还有101~110要处理,会等处理完同步信息后再响应client(所以这里会有短暂延迟/阻塞)。
问题:有没有可能,这里扩展可以采用别的数据结构,例如tree,而不是链表?
回答:读取tree叶子节点,听着可能破坏线性一致性。因为client请求的叶子节点,很可能还没有同步到最新write后的数据。也许你想的方案比我的想象要复杂,树的深度或者链的深度,是由失败时间决定的。如果你通常运行3~5台服务器就满足高可用性的要求了,那你可以比如只选用4台,可能崩溃恢复和日常write会引入一些延迟(这里我没怎么懂后面回答的啥东西,感觉大意就是如果构成系统的机器数本身很少,那链表的深度和树的深度差距不会太大,换言之就是tree结构的性能基于深度可能比链表小,但是这里机器数量本身不多的话,树和链表的读写性能差别也不大)。
问题:我好奇split拆分多个链后怎么保持强一致性?这里S1、S2、S3都可以作为tail被进行读取。
回答:你可以获取不同的分片shard或对象object以获取强一致性,这是分配给chain的。因为分片了,所以你写/读某个对象,它一定是对应具体某一个chain,所以能保证chain的强一致性。
追问:拆分chain后,在所有的对象上,我们都有强一致性吗?
回答:不,我认为这可能需要更多的机制。比如client读取不同shard的对象1和对象2,你需要额外的机制保证整体顺序和线性一致性。(虽然单个shard对应的chain读写能够保证线性一致性,但整体的需要额外机制。否则比如对象2的写或读在业务上依赖对象1的写或读操作,这里不同chain之间并不能严格保证执行的顺序。)
问题:当CR(Chian Replication)发生网络分区而不是崩溃,那会发生什么?比如S2可能还存活,但是和配置服务器或者其他什么的存在网络分区。
回答:假设所有配置都有编号,此时如果编号不匹配,那么S3不会接受来自S2的命令。
问题:有没有可能S3崩溃后,存在Client以为S3还是tail,仍然读取S3?
回答:所以论文中提到Client要使用代理Proxy。(即Client可以先通过Proxy访问配置服务,得知最新的tail是什么,然后再请求具体的tial。就算tail崩溃了,下次重试时,Proxy也知道该让Client请求新的tail)
问题:重复上面全局所有对象的线性一致性的问题,是不是需要诸如分布式事务一类的机制保证?因为我们希望的是数据a和数据b两个不同shard的数据读写具有线性一致性。(毕竟涉及多个不同对象的操作,我也感觉就是需要分布式事务机制)
回答:是的,就是需要分布式事务,这个大话题后面会说。
问题:前面zlock提到和go锁不一样,zlock在fail的时候会被看到中间状态是什么意思?
回答:因为fail后,zookeeper因为session断开了,会删除EPHEMERAL锁文件,这会导致临界区数据可能被处理/加工到一半就不再被保护(这些就是中间状态),因为zookeeper操作的都是被持久化的文件,所以这些中间状态是可见的。但是你可以通过leader选举后,增加清理这些中间状态的步骤(因为这里说zlock通常可以用于leader election)。而如果获取go锁的goroutine发生fail(崩溃),表示整个go进程都崩溃了,所以当然没有办法读到中间状态。
Lecture12 缓存一致性(Cache Consistency)-Frangipani
这篇论文发表于1997,研究的背景是网络文件系统,整体目标是在一组用户之间共享文件,但Frangipani本身并没有被大量应用。下面列举本章节的重点:
- 缓存一致性协议(cache coherence)
- 分布式锁(distributed locking)
- 分布式崩溃恢复(distributed crash recovery)
12.1 传统的网络文件系统(Network FS)
传统的网络文件系统,对外提供open、create等文件操作函数,服务端内部实现复杂,而client端除了函数调用和缓存以外,基本不做其他工作。
12.2 Frangipani-简述
Frangipani中没有专门的file server角色,每个client本身就作为file server,因为client本身运行file server code。
这里所有的client共享一个虚拟磁盘(virtual disk),这个虚拟磁盘内部使用Petal实现,由数个机器构成,机器复制磁盘块(disk blocks),内部通过Paxos共识算法保证操作按正确顺序应用等。
虚拟磁盘对外的接口是read块(read block)或write块(write block),看上去就像普通的磁盘。
在Frangipani这种设计下,复杂的设计更多在于client。你可以通过增加工作站(workstation)数量来拓展文件系统。通过增加client数量,每个client都可以在自己的文件系统上运行,许多繁重的计算都可以在client机器上完成,根本不涉及任何文件系统服务器。而传统的网络文件系统的性能瓶颈往往出现在文件服务器。
12.3 Frangipani-使用场景和设计目标
Frangipani的使用背景,一堆重度计算机使用者的研究者/学者,偶尔有需要分享的文件需要传递。因为所有参与者都是可信的,所以安全性对于这个文件系统不是很重要。
需求的文件分享形式有2种:
- user-to-user:client到client之间
- user-to- workstation:client到文件服务器
以此,催生出几个设计目标:
- caching:缓存,不是所有数据都保留在Petal(Frangipani文件服务器部分被称为Petal)中。**client采用回写式缓存(write back-cache)取代直写式(write-through)**。即操作发生在client本地的cache中,未来某时刻被传输到Petal。
- strong consistency:强一致性。即希望client1写file1时,其他client2或者workstation能够看到file1的变动。
- perference:高性能。
对比GFS,GFS并不提供POSIX或Unix兼容性,而Frangipani可以运行Unix标准的应用程序,应用的行为方式和没有分布式系统一样(如果单一文件系统)。
问题:为什么说client上运行server code可以增强scalability可拓展性?而不是向传统网络文件系统一样,server code只在file server上存在,而client只负责调用file server的接口。
回答:传统的网络文件系统中,所有的计算都是针对文件系统本身,而文件系统只在文件服务器上。在Frangipani中,所有文件系统操作发生在workstation工作站上(client上运行的server code),我们可以运行多个client(工作站)来扩展工作负载。
12.4 Frangipani-实现难点(challenge)
假设WS1工作站1执行read f的操作,之后通过本地cache对f通过vi进行操作。这时需要考虑几个可能发生的场景如何处理:
WS2 cat f
工作站2查看f文件,这时需要通过**缓存一致性(cache conference)**确保工作站2能看到正确的内容。
WS1创建d/f,WS2创建d/g
需要保证WS1创建d目录下的f文件,以及WS2创建d目录下的g文件时,双方不会因为创建目录导致对方的文件被覆盖或消失等问题。这里需要**原子性(atomicity)**保证操作之间不会互相影响。
WS1 crash during FS op
工作站1进行复杂的文件操作时发生崩溃crash。需要**崩溃恢复(crash recovery)**机制。
12.5 Frangipani-缓存一致性(cache coherence/consistency)
11.4 缓存一致性(Cache Coherence) - MIT6.824 (gitbook.io) <= 摘抄一些内容,作为补充说明
每个工作站用完了锁之后,不是立即向锁服务器释放锁,而是将锁的状态标记为Idle就是一种优化。
另一个主要的优化是,Frangipani有共享的读锁(Shared Read Lock)和排他的写锁(Exclusive Write Lock)。如果有大量的工作站需要读取文件,但是没有人会修改这个文件,它们都可以同时持有对这个文件的读锁。如果某个工作站需要修改这个已经被大量工作站缓存的文件时,那么它首先需要Revoke所有工作站的读锁,这样所有的工作站都会放弃自己对于该文件的缓存,只有在那时,这个工作站才可以修改文件。因为没有人持有了这个文件的缓存,所以就算文件被修改了,也没有人会读到旧的数据。
这就是以锁为核心的缓存一致性。
学生提问:如果没有其他工作站读取文件,那缓存中的数据就永远不写入后端存储了吗?
Robert教授:这是一个好问题。实际上,在我刚刚描述的机制中是有风险的,如果我在我的工作站修改了一个文件,但是没有人读取它,这时,这个文件修改后的版本的唯一拷贝只存在于我的工作站的缓存或者RAM上。这些文件里面可能有一些非常珍贵的信息,如果我的工作站崩溃了,并且我们不做任何特殊的操作,数据的唯一拷贝会丢失。所以为了阻止这种情况,不管怎么样,工作站每隔30秒会将所有修改了的缓存写回到Petal中。所以,如果我的工作站突然崩溃了,我或许会丢失过去30秒的数据,但是不会丢更多,这实际上是模仿Linux或者Unix文件系统的普通工作模式。在一个分布式文件系统中,很多操作都是在模仿Unix风格的文件系统,这样使用者才不会觉得Frangipani的行为异常,因为它基本上与用户在使用的文件系统一样。
Frangipani主要通过lock锁机制实现缓存一致性。
| file inode | owner |
|---|---|
| f | ws1 |
| g | ws1 |
| h | ws2 |
锁服务器(lock server)维护一张表table,里面维护每个file对应的inode编号,以及锁的owner拥有者对应哪个工作站。这里lock server本身是一个分布式服务,可以想象成类似zookeeepr,其提供加锁/解锁接口,且服务具有容错性。
| file inode | State |
|---|---|
| f | busy |
| g | idle |
同时,工作站自身也需要维护一张table,table维护lock对应的状态,比如f文件锁对应的状态为busy,g文件锁对应的状态为idle,表示g这一时刻没有被修改。这里idle状态的锁被称为**粘性锁(sticky lock)**。
由于ws1占有g对应的sticky lock,之后如果再次使用文件g,不必与Petal通信或重新加载cache之类的,因为sticky lock由自己占用,说明这段时间内没有其他工作站获取锁。
通过上述的两种锁,配合rule规则,即可实现缓存一致性:
- 缓存文件之前,需要先获取锁(to cache file, first acquire lock)
在论文中描述的lock锁是排他的读写锁,后续的课程为了优化,会假设不需要锁的排他性质,多个工作站可以在只读模式下拥有文件缓存。
12.6 Frangipani-协议(protocol)
这里场景举例,假设有WS1(工作站/client1)、LS(锁服务器)、WS2(工作站/client2)。
在WS和LS之间通信,会使用4种消息:
- 请求锁,requesting a lock
- 授予锁,granting a lock
- 撤销锁,revoking a lock
- 释放锁,releasing a lock
下面大致描述一下工作流程:
- WS1向LS请求锁(requesting a lock),要求访问文件f
- LS查询自己维护的file inode => owner表,发现f没有被任何WS上锁
- LS在table中记录f对应的owner为WS1,响应WS1授予锁(granting a lock)
- WS1在本地table中修改f文件对应的状态为busy,写操作执行完后,将f文件的锁状态改成idle。这里lock有租约期限,WS1需要定期向LS续约。
- WS2想问访问f,向LS发送请求锁(requesting a lock)
- LS看table,发现f对应的owner为WS1,于是向WS1发送撤销锁(revoking a lock)
- WS1确定已经不对文件修改后,向Petal同步自己对f的修改数据
- WS1完成对f的修改同步后,向LS发送释放锁(releasing a lock),同时删除自己本地对f锁的记录
- LS发现WS1释放锁后,重新修改table中f的owner为WS2
- LS向WS发送授予锁(granting a lock)
因为工作站访问Petal的文件需要获取锁,并且释放锁之前会将文件修改同步到Petal,所以保证了缓存一致性(cache coherence),即后续对相同文件进行访问的工作站一定能看到最新的修改内容。
问题:我们需要写入Petal,当释放读和写锁时,为什么我们需要在释放读锁时写入Petal?
回答:让我们忽略读写,只关注排他(即这里要求不管是读还是写,都要获取排他锁)。
问题:这看上去效率很低,如果两个工作站都一直操作同一个文件的话。
回答:是的,如果两个工作站一直在处理相同的文件,就会导致文件在工作站的缓存和Petal之间来回跳动。不过这里应用场景中,大多数研究者都在处理私人文件,所以它们同时处理一个共享文件的概率很低。就好像git,你平时在本地操作,偶尔才会和远程进行同步。
问题:如果WS1占有f锁为busy时,WS2向LS请求f的lock会发生什么?
回答:WS2会等待直到WS1完成修改并释放锁。
12.7 Frangipani-原子性(atomicity)
11.5 原子性(Atomicity) - MIT6.824 (gitbook.io) <= 摘抄部分内容,作为补充说明
为了让操作具备原子性,Frangipani持有了所有的锁。对于锁来说,这里有一件有意思的事情,Frangipani使用锁实现了两个几乎相反的目标。
- 对于缓存一致性,Frangipani使用锁来确保写操作的结果对于任何读操作都是立即可见的,所以对于缓存一致性,这里使用锁来确保写操作可以被看见。
- 但是对于原子性来说,锁确保了人们在操作完成之前看不到任何写操作,因为在所有的写操作完成之前,工作站持有所有的锁。
Frangipani使用同样的锁机制来实现原子文件系统操作。
假设WS1在目录d下创建f目录,那么根据论文所描述,会获取目录d的锁,然后获取文件f的inode锁,大致伪代码如下:
1 | |
这里通过锁,保证对本地Unix文件系统内部涉及的inode等操作进行保护,达到原子操作文件的目的。
当进行操作时,WS1将lock状态改成busy,操作完成后,如果没有后续写,则改状态为idle。此时如果LS要求撤销锁(revoking a lock),WS1可以将文件同步到Petal,之后安全地释放锁(releasing a lock)。
问题:论文中提到目录和inode都需要锁,所以WS1在释放锁(releasing a lock)之前,需要先释放2种文件锁?
回答:是的。论文中有提到实现中需要用不同种类的锁,它们对每个inode都有一个锁,包括目录的inode、文件的inode。事实上目录和文件没什么不同,只不过有特定的format格式。所以创建f,我们需要先分配和获取目录d的锁,然后分配获取到inode f的锁,所以持有两把锁。一旦出现获取多把锁的场景,就可能陷入死锁。如果一个工作站以不同的顺序分配锁,你可能陷入死锁。所以Frangipani遵循规则,所有的锁都以特定的方式排序,以固定的顺序获取锁,我想锁时按照inode编号排序的。
12.8 Frangipani-崩溃恢复(crash recovery)
11.6 Frangipani Log - MIT6.824 (gitbook.io) <= 摘抄部分内容,作为补充说明
有关Frangipani的Log系统有意思的事情是,工作站的Log存储在Petal,而不是本地磁盘中。几乎在所有使用了Log的系统中,Log与运行了事务的计算机紧紧关联在一起,并且几乎总是保存在本地磁盘中。但是出于优化系统设计的目的,Frangipani的工作站将自己的Log保存在作为共享存储的Petal中。每个工作站都拥有自己的半私有的Log,但是却存在Petal存储服务器中。这样的话,如果工作站崩溃了,它的Log可以被其他工作站从Petal中获取到。所以Log存在于Petal中。
这里其实就是,每个工作站的独立的Log,存放在公共的共享存储中,这是一种非常有意思,并且反常的设计。
这里有一件事情需要注意,Log只包含了对于元数据的修改,比如说文件系统中的目录、inode、bitmap的分配。Log本身不会包含需要写入文件的数据,所以它并不包含用户的数据,它只包含了故障之后可以用来恢复文件系统结构的必要信息。
为了能够让操作尽快的完成,最初的时候,Frangipani工作站的Log只会存在工作站的内存中,并尽可能晚的写到Petal中。这是因为,向Petal写任何数据,包括Log,都需要花费较长的时间,所以我们要尽可能避免向Petal写入Log条目,就像我们要尽可能避免向Petal写入缓存数据一样。
所以,这里的完整的过程是。当工作站从锁服务器收到了一个Revoke消息,要自己释放某个锁,它需要执行好几个步骤。
- 首先,工作站需要将内存中还没有写入到Petal的Log条目写入到Petal中。
- 之后,再将被Revoke的Lock所保护的数据写入到Petal。
- 最后,向锁服务器发送Release消息。
更新Petal中的state,需要遵循**预写式日志(write-ahead logging)**协议。可以说Petal就是为预写式日志(write-ahead logging)协议设计的。
在Petal的实现中,每台机器的磁盘由两部分组成:
- **日志log(**磁盘中有一特定区域用于log)
- 文件系统(磁盘中其余块用于文件系统)
当更新Petal的state状态时,经过以下流程:
更新日志(log update)
工作站进行实际文件操作前,记录log
安装更新(install the update)
工作站log记录完毕后,就可以实际安装更新,即更新文件系统中的文件,进行文件写操作等
每台Frangipani服务器都有log日志,log中的log entry拥有序列号(sequence number)。**log entry中存放更新数组(array of updates)**,用于描述文件系统操作,包含以下内容:
需要更新的块号(block number that needs to be updated), block#
在我们的示例中,对应inode编号
版本号(version number), version#
块编号对应的新字节数据(new bytes)
例如create f,在数组中会有两个条目,一个描述对inode块的更新,一个描述对目录数据块的更新。
当复制发生时(即LS向WS发送revoke撤销锁后,WS需要将文件变更同步到Petal),经过以下流程:
- log发送到Petal
- 发送更新块到Petal (send the updated blocks to Petal)
- 释放锁(release lock)
实际上,文件数据(file data)写入不会通过日志,而是直接传递给Petal。通过日志的更新是元数据(meta data)更改。元数据的含义是关于file文件的信息,比如inode、目录等,这些会通过log。应用级数据,实际构成文件的文件块直接写入到Petal,而不需要通过log。
因为文件数据没有记录到log中,这意味着如果你需要原子地写某个文件,你需要自己以某种方式保证,而大多数Unix文件都是这么设计的,在Frangipani角度不能破坏Unix原来的文件系统设计。
对于需要原子写文件的场景,通常人们通过先将所有数据写入一个临时文件,然后做一个原子重命名(atomic rename),使得临时文件编程最终需要的文件。同理,如果Frangipani需要原子写文件,也会采用这种方式。
通常人们只希望文件系统的元信息能够通过log存储,而不是连带文件数据一起存储。假设你写2GB的文件,存入log之后进行同步会极大影响性能。但是表示文件系统内部结构的元信息,比如inode、目录等需要保证在Petal上也有一致的表现,所以需要记录到log中。
问题:这里怎么保证文件操作是原子的,第一步首先要更新log?
回答:论文中有提到几种方式,每个log记录都有一个校验和(checksum),用校验和确保log的完整性。
12.9 Frangipani-崩溃场景分析
11.7 故障恢复(Crash Recovery) - MIT6.824 (gitbook.io) <= 摘抄部分内容,作为补充说明
Frangipani出于一些原因对锁使用了租约,当租约到期了,锁服务器会认定工作站已经崩溃了,之后它会初始化恢复过程。实际上,锁服务器会通知另一个还活着的工作站说:看,工作站1看起来崩溃了,请读取它的Log,重新执行它最近的操作并确保这些操作完成了,在你完成之后通知我。在收到这里的通知之后,锁服务器才会释放锁。这就是为什么日志存放在Petal是至关重要的,因为一个其他的工作站可能会要读取这个工作站在Petal中的日志。
但是幸运的是,执行恢复的工作站可以直接从Petal读取数据而不用关心锁。这里的原因是,执行恢复的工作站想要重新执行Log条目,并且有可能修改与目录d关联的数据,它就是需要读取Petal中目前存放的目录数据。接下来只有两种可能,要么故障了的工作站WS1释放了锁,要么没有。如果没有的话,那么没有其他人不可以拥有目录的锁,执行恢复的工作站可以放心的读取目录数据,没有问题。如果释放了锁,那么在它释放锁之前,它必然将有关目录的数据写回到了Petal。这意味着,Petal中存储的版本号,至少会和故障工作站的Log条目中的版本号一样大,因此,之后恢复软件对比Log条目的版本号和Petal中存储的版本号,它就可以发现Log条目中的版本号并没有大于存储数据的版本号,那么这条Log条目就会被忽略。所以这种情况下,执行恢复的工作站可以不持有锁直接读取块数据,但是它最终不会更新数据。因为如果锁被释放了,那么Petal中存储的数据版本号会足够高,表明在工作站故障之前,Log条目已经应用到了Petal。所以这里不需要关心锁的问题。
接下来分析一下不同崩溃场景下,Frangipani如何处理:
写log前就崩溃(before writing log)
数据丢失
log写到Petal后崩溃(crash after writing log to Petal)
假设写log到Petal后WS1崩溃,此时WS1占有log,如果WS2想要获取同一个文件inode的lock,LS会等待WS1的lock租约过期后,要求剩余的WS的recovery demon读取WS1的log,并应用log中记录的操作。等待demon工作完成后,LS重新分配锁,即授予WS2锁。(这里术语demon,通常指一项服务or服务器or服务器进程,通常用于处理一些额外工作,而不是提供主要的服务)
写log到Petal的过程中崩溃(crash during writing the log to Petal)
文件中包括前缀,如果写log中崩溃,那么文件的校验和检验就不会通过,recovery demon会停止在检验和不通过的记录之前。
问题:确认一下,这里写log后崩溃,不能保证用户写的文件数据,对吧?
回答:是的,log系统只用于保证内部文件系统数据结构一致。
12.10 Frangipani-日志和版本
这里讨论下一个场景,假设有WS1~WS3,整体操作时序如下:
- WS1在log中记录
delete ('d/f'),删除d目录下的f文件 - WS2在log中记录
create('d/f') - WS1崩溃
- WS3观察到WS1崩溃,为WS1启动一个recovery demon,执行WS1的log记录
delete('d/f')
原本WS2能在Petal中创建d目录下的f文件,但是WS3却有可能因为恢复执行WS1的log的缘故,将f文件删除。这里Frangipani通过日志版本号避免了这个问题。
实际上,上面的操作,可以详细成如下:
- WS1在log中记录
delete ('d/f'),删除d目录下的f文件。log的版本号假设为10 - WS2在log中记录
create('d/f'),log的版本号为11(因为锁保证了log的版本号是完全有序的) - WS1崩溃
- WS3观察到WS1崩溃,为WS1启动一个recovery demon,准备执行WS1的log记录
delete('d/f'),但是发现Petal中已应用的log对应的version版本号为11,高于log或inode的version,准备重放的log的version为10,小于等于11,所以demon会放弃重放这个log。
问题:version版本号总是绑定到正在编辑的inode上吗?
回答:是的。比如文件有一个version。前面”12.8 Frangipani-崩溃恢复(crash recovery)”提到的更新列表中,每一项会记录更新的块编号、version、更新的数据。
12.11 Frangipani-小结
Frangipani虽然实际应用不广泛,但是其应用到的一些思想/设计,直接学习。
- 缓存一致性协议(cache coherence)
- 分布式锁(distributed locking)
- 分布式恢复(distributed recovery)
后续章节即将讨论的分布式事务,也会用到这些设计思想。
问题:这里的缓存一致性,不是在两个地方有一个文件缓存,对吧?
回答:是的。
问题:你说每一条记录都是原子操作的,但是每条记录也有一些更新,对吧?
回答:论文描述比较含糊,磁盘可以保证单个扇区(512字节)的操作是原子的,可以利用这一点实现。或者使用log的校验和,读扇区时重新计算校验和,对比存储中的校验和是否一致,如果没错,那就是完整的一个记录。
Lecture13 分布式事务(Distributed Transaction)
- 两阶段锁(2-phase locking, 2PL)
- 两阶段提交(2-phase commit, 2PC)
出现分布式事务的一个原因是,人们需要跨机器的原子操作(cross-machine atomic ops)。
13.1 事务-原语简述
这里举例应用事务时的程序编写,假设有T1和T2两个正在进行的事务,我们只需要通过指定的事务原语编程程序,就能保证逻辑被原子地执行,而无需感知事务内部实现使用什么锁等机制。
- begin:声明一个事务的开始
- commit:提交事务,commit成功被执行后,begin~commit之间的逻辑被原子地执行
- abort:取消事务,begin~abort之间的逻辑将被撤销,即产生的影响会消除(比如put修改的值被改回去之类的)。除了人为在逻辑里使用abort,事务本身遇到死锁等情况时也会自动调用abort。
13.2 事务-关键属性ACID
12.1 分布式事务初探(Distributed Transaction) - MIT6.824 (gitbook.io) <= 摘抄部分内容,作为补充说明
我们说可串行化是指,并行的执行一些事物得到的结果,与按照某种串行的顺序来执行这些事务,可以得到相同的结果。实际的执行过程或许会有大量的并行处理,但是这里要求得到的结果与按照某种顺序一次一个事务的串行执行结果是一样的。所以,如果你要检查一个并发事务执行是否是可串行化的,你查看结果,并看看是否可以找到对于同一些事务,存在一次只执行一个事务的顺序,按照这个顺序执行可以生成相同的结果。
- A,atomicity:原子性。在执行中发生崩溃,事务内的所有写入要么都是有效/可见的,要么都是无效/不可见的。原子性和崩溃恢复有关。
- C,consistency:一致性。一致性通常与数据库有关,数据库具有内部变量,比如参照完整性(referential integrity)就是其中之一,而事务应该保持这种(内部)一致性。
- I,Isolation:隔离性。两个运行的事务,不该观察到彼此的中间结果,即事务只有内部所有逻辑执行完后,产生的影响/结果才能被其他事务观测到。
- D,durability:持久性。表示事务提交后,结果写入稳定存储,如果系统崩溃后恢复,已提交的事务的结果/影响需要是可见的/存在的。
下面主要讨论A(atomicity)和I(Isolation)。
13.3 事务-隔离性(Isolation)
正确执行多个事务或并发事务,在数据库文献中经典的定义或标准,称为**可串行化(serializability)**。
可串行化,即T1和T2事务就算并发运行,那么也可以按照串行执行进行排序,即要么T1之后T2,要么T2之后T1,且串行顺序产生的结果需要和并发执行一致。
可串行化和前面章节提到的线性一致性很类似。在线性一致性中,如果T2在T1结束后开始,那么T2在整体顺序中必须出现在T1之后;而可串行化中无此要求,即使T2开始时间晚于T1的结束时间,系统仍然允许对T1和T2重排序使得T2在T1之前。所以可串行化在执行顺序的要求上比可线性化要求弱一些。
尽管如此,可串行化仍是一种很方便的编程思想,它禁止了很多有问题的情况(problem cases)的发生。
被禁止的场景举例1:
| T1 | T2 |
|---|---|
| get(X) | |
| Transfer(X,Y) 对X、Y进行修改 | |
| get(Y) |
这里场景举例1很明显不符合可串行化,可串行化会禁止这种执行顺序的发生。(这里T1的修改操作要么在T2事务之前,要么在T2事务之后,但是不能让T1在T2执行时同时对T2产生可见的影响。)
被禁止的场景举例2:
| T1 | T2 |
|---|---|
| put(X) | |
| get(X) | |
| get(Y) | |
| put(Y) |
这里同样是可串行化不允许的,应该要么先执行T1然后T2,要么先T2再T1。
13.4 事务-并发控制(Concurrency Control)
有两种方向的方法可以实现可串行化要求的禁止,即避免不符合可串行化的场景发生,称为**并发控制(Concurrency Control)**。
- 悲观(pessimistic):悲观的实现方案,引入锁。当事务运行/开始时,需要锁来维护可串行化,只有确保能够串行化执行后才会释放锁。
- 乐观(optimistic):乐观的实现方案,无锁。当你到达提交点(commit point)时,系统确认之前的一系列操作是否符合可串行化的要求,如果符合则正常执行。如果不符合,则被abort。这里可能会引入一些重试机制。
这里暂时不会讨论乐观的实现,后续关于FaRM论文的章节,会看到一个乐观的分布式事务系统实现。这里重点讨论悲观的实现。
在文献中,两种方案可以这么理解:
- 悲观实现方案:你需要先获取许可,然后才能执行操作
- 乐观实现方案:相反,你只管执行操作,如果最后结果是错的(不符合可串行化),随后道歉即可(撤销操作)
13.5 事务-可串行化实现之两阶段锁(2PL)
尽管可串行化是数据库的黄金标准,但实际数据库提供了多种程度的隔离性,程序员可能会选择较弱的隔离性以获取更高的并发度。作为课程介绍,我们按照可串行化的标准进行隔离性实现的讨论。
这里我们聊聊可串行化的常见实现方案——两阶段锁(2-phase locking, 2PL)。
在两阶段锁(2PL)中,每个记录都有锁(lock per record),其有两条需要遵循的规则:
- 在开始事务之前,需要lock。(T acquire lock before using)
- 事务拥有锁之后,只能在commit或abort时释放锁。(T holds until commit or abort)
按照2PC,T1和T2事务的场景列举如下:
在T1事务获取记录X的锁后,T2阻塞直到T1进行commit后释放记录X的锁,T2事务才能继续进行
| T1 | T2 |
|---|---|
| Lock X record | Lock X record (wait until T1 release lock) |
| Lock Y record | …. (other things) |
| commit (release Lock X, Lock Y) | Lock X success and do other things |
2PL是对简单锁(严格锁)的改进。
- 简单锁(simple locking)或严格锁(strict locking),在事务开始前,你获取整个事务所需的所有锁,持有这些锁直到提交点进行commit或者abort,然后释放所有锁。
- 2PL的锁更细粒度一点,不需要在事务开始前直接获取所有锁,相反的,在事务运行时动态增量的获取锁,支持某些严格锁(简单锁)不允许的并发模式。
一般而言,使用2PL要比使用简单锁(严格锁)有更高的并发度。比如事务中读取的某个变量极小概率会是true,而变量为true时,才会执行后序事务逻辑,那么这里不需要在事务开始前就加锁,可以等读到变量时再加锁。
13.6 事务-2PL规则分析
“13.5 事务-可串行化实现之两阶段锁(2PL)”中,2PL的规则中第一条(在开始事务之前,需要lock)很好理解,第二条(事务拥有锁之后,只能在commit或abort时释放锁)似乎有点模糊,这里举例进行说明。
场景1(获取锁后,在记录操作完直接释放锁)
很明显这里T1和T2不符合可串行化,这和没有加锁时并没有什么太大区别。
| T1 | T2 |
|---|---|
| Lock X, put(X), release Lock X | |
| Lock X, get(X), release Lock X | |
| Lock Y, get(Y), release Lock Y | |
| Lock Y, put(Y), release Lock Y |
所以,按照2PL的第二条规则(事务拥有锁之后,只能在commit或abort时释放锁),事务需要到commit point时才能释放锁,确保不会有事务的中间结果被其他事务看见。
13.7 事务-2PL死锁分析
在提交点才释放锁,很容易联想死锁的场景,如下:
| T1 | T2 |
|---|---|
| Lock X, put(X) | |
| Lock Y, get(Y) | |
| wait Lock X, get(X) | |
| wait Lock Y, put(Y) |
很明显T1和T2互相等待对方的Lock,进入死锁。
不过好在事务系统提供了abort操作。如果事务系统可以检测到死锁(deadlock),那么可以对T1或T2事务任意一个执行abort操作,使其中一个事务能正常获取lock完成事务,并中止另一个事务。而客户端client或应用程序可以自己决定如何处理事务被abort的情况,比如事务重试或放弃执行等等,但至少避免了死锁。
可以看出来2PL也会进入死锁的场景,但至少提供了abort操作,能够解决死锁问题,而不是永远停在死锁场景中。
问题:事务系统如何检测到死锁?
回答:人们用两种方法来检测,尽管不够可靠。一种是基于超时(timeout)的,比如几个事务执行了许久看似没有新进展,则中止其中一个。另一种更系统的方法是构造一个**等待图(wait-for graph)**,如果发现等待图中出现环,则说明有死锁(比如上面T1等待T2的Lock Y,T2等待T1的Lock X,T1和T2成环)。
问题:检测到死锁后,中止其中一个事务会发生什么?
回答:假设中止了T2,事务系统会安排T2没有result或者其result是可见的,此时abort强制释放T2占有的Lock Y,T1之后可获得Lock Y完成事务,而发起T2的客户端会知道T2被系统中止,一般情况下你可以选择重新发起T2。
问题:是否可以在提交点之前释放锁?
回答:视情况而定,如果你只使用我们目前在描述的独占锁(exclusive locking),那么释放锁的时间点和提交点(commit point)或中止点(abort point)一致;如果你使用读写锁,锁允许区分读锁和写锁,那在某些限制的前提下可以提前释放读锁。
13.8 崩溃处理-两阶段提交(2PC)概述
两阶段提交(2-phase commit, 2PC)和崩溃恢复有关。
事务系统(transactiion system)中接收事务的机器称为**协调器(coordinator)**,协调器负责通过事务系统运行事务。
下面通过示例先简单介绍下2PC:
通常协调者以试探的方式协调分布式事务。下面所有的操作,都需要预写日志,即(WAL, write-ahead log),先写日志,在做实际操作,确保崩溃恢复时能重现log完成已commit的操作,以及舍弃或恢复未commit的操作。
协调者只在参与式事务的服务器都同意执行事务后才会进行commit提交。
| 时序 | coordinator(协调器) | A服务器拥有X记录 | B服务器拥有Y记录 |
|---|---|---|---|
| 1 | 新建事务(tid),告知A执行put(X), 告知B执行put(Y) | ||
| 2 | Lock X, put(X), log X(日志记录)。这里暂时没有实际操作数据库,只是log记录 | log Y(日志记录), Lock Y, log Y(日志记录),这里暂时没有实际操作数据库,只是log记录 | |
| 3 | 对A、B发起prepare询问请求,询问A和B是否正常log了事物需要的操作 | ||
| 4 | A查看自己的状态,发现持有X的锁,并且log了需要执行的put操作,回应prepare请求YES | B查看自己的状态,发现持有Y的锁,并且log了需要执行的put操作,回应prepare请求YES | |
| 5 | 收到A和B的prepare响应YES后,得知A和B可以准备提交事务了,向A和B发起commit(tid)请求 | ||
| 6 | A看本地log,发现tid对应的事务可以提交了,于是install日志,即执行日志中记录的put(X)操作,然后释放X的锁,对commit请求响应OK | B看本地log,发现tid对应的事务可以提交了,于是install日志,即执行日志中记录的put(Y)操作,然后释放Y的锁,对commit请求响应OK | |
| 7 | 收到A和B的OK,知道A和B都成功执行完事务了 |
- 假设时序4准备执行事务时,A或者B由于死锁或者log空间不足等原因无法执行事务操作,那么A或者B会对prepare请求回应NO,拒绝执行事务。
- 此时协调者在时序5的位置发现有人不同意执行事务,于是改成向A和B发送abort请求,要求停止执行事务。
- 在时序6的位置,A和B接收到abort请求后,会根据log里的记录,对tid事务操作进行回滚。回滚完毕后,A和B回应OK
- 在时序7的位置,协调者收到A和B的OK后,得知A和B都回滚tid事务成功了。
问题:有没有可能B在收到来自协调者的prepare请求后,回应Yes,但是又决定中止事务执行?
回答:不可能。如果你promise承诺要提交,那就必须准备提交,即等到commit请求来之后进行提交。这里一旦prepare回应了Yes后就不能再中止事务了。
问题:有没有可能prepare时回应Yes,结果后面发现死锁了,又中止事务?
回答:你会在回应prepare之前发现死锁,所以不可能发生回应了prepare后才发现死锁的问题。
13.9 崩溃处理-2PC崩溃分析
场景1:事务参与者在回应prepare后崩溃
按照”13.8 崩溃处理-两阶段提交(2PC)概述”举例的场景,如果在时序5的位置,B发生了崩溃,那之后我们需要做什么?即B对prepare响应OK,但是随后机器崩溃了。
首先,B已经对prepare回应OK了,所以这里B恢复后不能反悔,必须继续执行事务。这里B恢复后,仍持有数据Y的锁,并且检查log中记录的状态(比如需要把一些状态值加载到内存之类的),然后后续就和没发生崩溃一样走原本的流程了。
显然,两阶段提交2PC是有些昂贵的流程,我们不仅需要发送多个回合的信息,而且事务的参与者还必须将一些操作记录到稳定存储中。
场景2:协调者在发送commit(tid)请求后崩溃
假设协调者在时序5的位置,向A和B发送commit请求后崩溃,需要怎么确保整个流程顺利执行?
类似事务参与者,协调者在发送commit(pid)请求之前,需要记录log,崩溃后根据log继续执行事务流程。这里假设协调者崩溃前,A回应了OK,但是B回应协调者之前,协调者崩溃了。那么B必须等待协调者恢复后,再回应协调者OK,而不能私自中止事务。
这种情况下,B很不幸必须一直等待,这里其他事务如果要占用Y数据的锁就会失败,因为B需要等待协调者恢复后,能响应协调者时再释放锁。
场景3:A一直没有回应协调者prepare请求
假设A因为某些原因,在时序4的位置一直没有回应prepare,那么协调者会以超时等机制,在时序5的位置告知B执行abort来中止事务。后序A又和协调者联系上时,协调者会告诉A,tid这个事务已经中止了。这意味着B收到abort后可以释放Y数据的锁,然后后续尝试其他涉及Y数据的事务之类的。
问题:假设B持有Y的锁,直到把Y操作放入日志,以及最后install日志,执行实际对Y数据的操作后,然后才会释放锁是吗?
回答:是的。
问题:这里的锁是分布式的,Y数据只存在于服务器B上,或许我们不需要对Y数据加锁?
回答:A维护它所有分片的锁,B同理。而不同用户/事务可能访问同一个数据,所以需要锁。
13.10 崩溃处理-2PC容错分析
从上面”13.9 崩溃处理-2PC崩溃分析”举例的场景2可以知道,如果协调者崩溃了,会导致其他服务器无法继续执行事务,导致锁一直占用。所以我们希望通过一些手段加强协调者的容错性。
通过Raft共识算法使协调者具有容错性(use Raft to make C available)
比如运用Raft/Paxos等共识算法部署多台协调者,这样容许其中几台故障后也能继续提供服务。同样的,也可以使用Raft让事务参与者有更高的可用性。
问题:Raft是不是类似2PC?
回答:最大的区别就是Raft基于majority原则;而2PC要求所有机器都有一致的回应。并且在Raft中,所有服务器做相同的事情,用于实现RSM复制状态机;而2PC中所有参与者操作不同的数据。同时,Raft用于实现高可用性,而2PC用于实现跨机器的原子操作。即使某些方面Raft和2PC的实现类似,但两个协议针对的问题不同。
问题:2PL,看着也是关于原子操作的,但是看着好像是单台服务器的,而不是跨服务器的?然后2PC则是跨服务器的。
回答:是的,实际上如果你在一台多核机器上实现事务系统,你必须对事务中涉及的记录加锁,而2PL在这种场景下是非常好的协议。而2PC才是真正关于分布式系统的。
问题:2PL可能是2PC流程中的一部分吗?
回答:我不太理解你的问题,但我认为2PL和2PC解决的是两种不同问题。也许你想说的是前面示例中A和B服务器对X和Y数据加锁用的是不是2PL两阶段锁。实际上这里可以是2PL,也可以是简单锁(严格锁),但是对于2PC流程来说不重要,因为2PC解决的是分布式事务整体的协调问题。
问题:2PC是专门用于分片数据的吗?
回答:不完全是。最初2PC应对的场景是,比如你有不同的机构,它们需要协商同意某一些事情,比如你在旅游订单上,下单了机票,然后又下单了酒店房间预定,最后想提交整个旅游订单,这需要机场服务网站和酒店服务网站都同意后,这个订单才能生效,即事务才能提交。实际上,这里需要互不信任的机场服务、酒店服务互相感知,互相依赖,如果一个服务宕机了,另一个服务就无法处理这个订单,所以2PC有点负面名声。而2PC最初就是为了解决这类问题,但是人们对于这个问题并不希望采用2PC来解决。然而,在拥有数据中心的环境中,该单一机构内数据库是分片的,2PC则作为典型应用而广泛流行。
问题:为什么B在接受到prepare请求后,需要持久化?当它恢复后,如果收到来自协调者的commit请求,它就不能假设自己已经准备好了吗?
回答:也许B在崩溃前打算abort,所以B需要记住自己做了什么。这里有个变体,即你可以总是假设后续要commit,然后做一些优化方案,这里还没有谈到对应的协议。2PC有很多变体实现。
Lecture14 Spanner
Spanner是谷歌公司研发的、可扩展的、多版本、全球分布式、同步复制数据库。它支持外部一致性的分布式事务。本文描述了Spanner的架构、特性、不同设计决策的背后机理和一个新的时间API,这个API可以暴露时钟的不确定性。这个API及其实现,对于支持外部一致性和许多强大特性而言,是非常重要的,这些强大特性包括:非阻塞的读、不采用锁机制的只读事务、原子模式变更。
Spanner是2012年的论文,但目前Spanner系统还是在投入使用中。
Wide-area transation:支持广域的事务,即跨越多个国家/地区的分布式事务
read-write trasaction using 2-phase commit, Paxos:读写事务使用两阶段提交实现,协议的参与者都是Paxos组(2PL+2PC+Paxos)
Read-only transaction:只读事务可以在任意数据中心运行,
大约比读写事务快10倍
(Spanner针对只读事务做优化)
- snapshot isolation:使用快照隔离技术,使得只读事务能更快
- synchronized clocks:实现依赖同步时钟,这些时钟基本是完全同步的,事务方案必须处理不同机器的一些时间漂移或错误容限(具体的实现称为TrueTime API)
Wide-used:Spanner是一项云服务,你可以作为Google的客户使用。比如Gmail的部分功能可能有依赖Spanner。
14.1 Spanner-系统结构概述(Organization)
假设有A~C这3台服务器,其中a~m的数据shard分片在A~C都有一份,并且相同的shard分片数据在一个Paxos组中。同理A~C都有一份n~z的数据shard分片,对于n~z的分片,又在另一个Paxos组中。
- multiple shards,parallelism:Spanner对数据分片,换取更高的并行度。如果事务涉及不同的分片,事务之间互不依赖,可并行处理。
- Paxos per shard:每个shard分片都有对应的Paxos组,用于replication复制。保证速度慢的机器不会对系统整体性能产生太大影响,因为根据majority原则,只需要大多数服务器响应,服务就能正常运行;同时也增加容错性,容许部分服务器宕机。
- data center fault tolerance(数据中心容错能力)
- through slowness(绕过慢机器,借助majority原则)
- Replica close to clients:Replica通常部署在靠近client用户群体(这里client主要指公司内部的后端服务,因为Spanner整体而言是对内的基础架构服务)的地理位置。目标是能让client智能地访问最近的Replica。通常只读事务可以由本地Replica执行,而不需要与其他数据中心进行任何通信。
14.2 Spanner-实现难点(Challenge)
Read of local replica yield lastet write:从本地Relica读取,但要求看到最新的写入
事实上,Spanner追求的是比线性强一致性更强的性质。(zookeeper也允许读任何节点,但是并不保证能读到其他client的最新写入,只保证读取当前session下最新的写入,即弱一致性)
Support transactions across shards:支持跨分片的事务
read-only txns and read-write txns must be serializable:只读事务和读写事务必须串行化
实际上,这比可串行化要强一些。
实际上,对于读写事务(read-write tx),Spanner使用2PL和2PC。
14.3 Spanner-读写事务(read-write txns)
这里先在不考虑时间戳的情况下讨论读写事务。因为时间戳在读写事务中不是很重要,时间戳主要用于只读事务(因为需要保证只读事务读到最新写数据),它们需要对读写事务进行一些调整,以支持只读事务。
时间戳在某种程度上也能漂移到读写事务(drifting to read-write transaction),但是本质上,读写事务是直接的2PL和2PC。
Spanner读写事务的注意点(可以把Paxos看成Raft的替代物):
- 在执行只读事务时,直接读数据分片Paxos组的leader(即事务如果目前还只有read操作,还没有write操作时,不需要事务协调者参与)
- 当事务涉及写操作后,当前事务需要经过事务协调者Paxos组leader,其协调和数据分片Paxos组leader之间的写操作
- lock table仅在Paxos组的leader中存放记录,不在Paxos组内复制(因为不需要复制锁表,加快了读操作)
- 只读事务下分片Paxos组的leader在事务过程中宕机,则事务中止,需要重新开始(因为锁信息丢失了,只有分片Paxos组leader记录锁信息)
- 事务中后续涉及写操作,升级为读写事务,prepare阶段前崩溃,锁信息会丢失(因为还只在分片Paxos组的leader的锁表记录中),prepare阶段后,某些记录被加锁的状态会通过log同步到Paxos组其他成员,锁记录不会丢失。
- 2PC的事务协调者也是Paxos组,增强容错性(降低事务协调者宕机后,导致参与者必须等待协调者恢复后才能commit事务的事故概率)
下面通过示例讲解:
| Client | 事务协调者(Paxos组) | Sa(A数据分片Paxos组) | Sb(B数据分片Paxos组) |
|---|---|---|---|
| 事务tid,向Sa的Paxos组leader发起数据分片A的读请求,向Sb的Paxos组leader发起数据分片B的读请求 | |||
| Sa根据2PL,leader对X加锁,Owner是Client | Sb根据2PL,leader对Y加锁,Owner是Client | ||
| Client向事务协调者发起X=X-1,Y=Y+1的操作 | |||
| 收到X和Y更新的操作,通过2PC流程,分别发送X更新操作和Y更新操作到分片A和分片B的Paxos组leader | |||
| 根据2PC流程,leader发现X已经有锁,将读锁升级为写锁,根据WAL进行事务操作的log | 根据2PC流程,leader发现Y已经有锁,将读锁升级为写锁,根据WAL进行事务操作的log | ||
| 发起prepare请求,确认Sa和Sb是否可以准备事务提交,同样需要Paxos组log、复制 | |||
| 检查已拥有锁,log记录事务状态和2PC状态,lock持有状态等信息,以及在Paxos组内同步log,确认整个Paxos组可以准备提交,leader回应OK | 检查已拥有锁,log记录事务状态和2PC状态,lock持有状态等信息,以及在Paxos组内同步log,确认整个Paxos组可以准备提交,leader回应OK | ||
| 发起commit(tid)请求,要求提交事务,同样需要Paxos组log、复制 | |||
| Paxos组实际install log,执行log记录的事务操作,leader释放锁,leaer回应OK | Paxos组实际install log,执行log记录的事务操作,leader释放锁,leader回应OK |
整体上看,和之前”13.8 崩溃处理-两阶段提交(2PC)概述”介绍的2PL+2PC流程相似,最大的区别就是事物协调者(coordinator)和参与者(participant)都是Paxos组。
问题:每个分片是否都复制了锁表?
回答:分片不是直接复制lock table,它复制的是2PC的prepare阶段中对于数据分片持有锁的state状态(it’s replicating the lock that’s holding when it does the prepare.)
问题:如果当前一些事务的锁,还没有到达prepare阶段,它们会丢失吗?
回答:它们会丢失,然后事务会中止。然后(分片Paxos组的leader)告知协调者,我的锁丢失了,不能继续执行事务
14.4 Spanner-只读事务(read-only tnxs)概述
只读事务,事务中只有读操作。论文提到只读事务基本上比读写事务快10倍,读写事务在数百毫秒的量级,而只读事务在5~10毫秒的量级。
- Fast, Read from local shards:通过只从本地分片读取数据,实现低延迟(无需额外和其他分片通信,实现一致性/串行化是个难点)
- no locks:不需要锁(读写事务需要锁,会互相阻塞;而只读事务不会阻塞读写事务)
- no 2PC:不需要两阶段提交(同时意味着不需要广域wide-area通信)
14.5 Spanner-只读事务正确性(Correctness)定义
这里的正确性(Correctness)意味着两点:
事务是可串行化的(serializable)
即几个读写事务和只读事务在一起运行时,能够按照结果对事务得到一个排序。只读事务要么读取到某个读写事务的所有写入结果,要么其写入结果一个都看不到,但必须保证只读事务不能看到读写事务的中间结果。
外部一致性(external consistency)
如果事务T2在T1提交之后开始,那么T2必须看到T1的结果。
**这里外部一致性可以理解为,在可串行化基础上再加上实时性的要求。实际上外部一致性贴近于线性一致性(linearizability)**。
补充说明:线性一致性要求如果操作2在操作1结束后才开始,那么操作2必须排在操作1之后。详情见“7.7 线性一致性/强一致性(Linearizability/strong consistency)”
对比**事务的外部一致性(external consistency)**和**线性一致性(linearizability)**:
| 事务的外部一致性(external consistency) | 线性一致性(linearizability) | |
|---|---|---|
| 描述的属性级别 | 事务级别(事务1,事务2) | 操作级别(操作1,操作2) |
| 对外一致性表现 | 强一致性 | 强一致性 |
14.6 Spanner-只读事务错误实现示例
bad实现:always read lastet committed value,总是读最后提交的数据。
| 事务 | 时间戳10 | 时间戳20 | 时间戳30 |
|---|---|---|---|
| T1 | set X=1, Y =1, Commit | ||
| T2 | Set X=2, Y=2, Commit | ||
| T3 | Read X (now X=1) | Read Y (now Y=2), Commit |
显然,如果总是读最后提交的数据,是不正确的,T3观察到了来自不同事务的写入,而不是得到一致的结果。(不符合可串行化,理论上T3要么X和Y都读取到1,要么都读取到2,要么都读取到X和Y的原始值假设为0)。
14.7 Spanner-只读事务正确性之快照隔离(Snapshot Isolation)
“14.6 Spanner-只读事务错误实现示例”描述了只读事务错误的正确性实现方式。
**Spanner采用快照隔离(Snapshot Isolation)方案实现只读事务的正确性(Correctness)**。
快照隔离是一个标准的数据库概念,主要是针对本地数据库,而非广域(wide-area)的,后续会对广域方面的内容再做介绍。
快照隔离具备以下特征:
为事务分配时间戳(Assign TS to TX)
- 读写事务:在开始提交时分配时间戳(R/W:commit)
- 只读事务:在事务开始时分配时间戳(R/O:start)
按照时间戳顺序执行所有的事务(Execute in TX order)
每个副本保存多个键的值和对应的时间戳(Each replica stores data with a timestamp)
例如在一个replica中,可以说请给我时间戳10的x的值,或者给我时间戳20的x的值。**有时这被称为多版本数据库(multi-version database)或多版本存储(multi-version storage)**。对于每次更新,保存数据项的一个版本,这样你可以回滚(so you can go back in time)。
| 事务(开始的时间戳) | 时间戳10 | 时间戳20 | 时间戳30 |
|---|---|---|---|
| T1 (10) | set X=1, Y =1, Commit | ||
| T2 (20) | Set X=2, Y=2, Commit | ||
| T3 (15) | Read X (X=1) | Read Y (Y=1), Commit |
这里T3需要读取时间戳15之前的最新提交值,这里时间戳15之前的最新值,只有T1事务提交的写结果,所以T3读取的X和Y都是1。因为所有的事务按照全局时间戳执行,所以保证了我们想要的线性一致性或串行化。
这里需要知道的是,每个replica给数据维护了version表,可以猜想结构大致如下:
| 数据(假设X和Y在同一个replica中) | 版本(假设用时间戳表示) | 值 |
|---|---|---|
| X | @10 | 1 |
| X | @20 | 2 |
| Y | @10 | 1 |
| Y | @20 | 2 |
所以当读请求到达replica时,replica可以根据事务请求的时间戳,查询维护的数据记录表,决定该返回什么版本的数据。
这里Spanner还依赖”safe time”机制,保证读操作从本地replica读数据时,能读取到事务时间戳之前的最新commit数据。
- Paxos按照时间戳顺序发送所有的写入操作(Paxos sends write in timestamp order)
- 读取X数据的T时间戳版本数据之前,需等待T时间戳之后的任意数据写入(Before Read X @15, wait for Write > @15)
- 这里等待写入,同时还需要等待在2PC中已经prepare但是还没有commit的事务(Also wait for TX that have prepared but not committed)
问题:当我们读取X时,X本身处于一些shard分片上,被复制到Paxos组中,假设3台机器复制X,当你读取X时,我们希望只读事务特别快,而我们只从本地replica读取,它不一定是leader,那么如果保证不会读到旧数据?
回答:正如你所说,可能读取的local replica正好没有比如@10版本的数据。Spanner通过”Safe time”方案解决这个问题。即Paxos或Raft也按照时间戳顺序发送所有写入(Paxos sends writes in timestamp order),你可以考虑总顺序是一个计数,但它实际是一个时间戳,由于时间戳形成了全局顺序,时间戳的全局顺序足够对所有写入进行排序。并且,对于读取有一个额外的规则,在读取时间戳15的X之前,replica必须等待时间戳大于15的写入。一旦看到时间戳15之后的写入,它就知道在时间戳15之前不会再有别的写入,所以安全地在时间戳15执行读取,并且知道该返回什么值。这对服务而言,相当于读取可能必须稍微延迟一点,直到下一次写入。当然对于写入频繁的服务器而言,这里读操作需要的等待时间很短。****真正的情况会更复杂一些,需要等待,并且要等待已准备好提交但未提交的事务。例如某个事务可能在时间戳14已经prepare了,但是还没有commit写入到键值存储。所以我们需要保证任何在我们读取时间戳前准备好(prepared)的事务,必须在我们返回读取值之前提交(commit)。
追问:不同分片是不是也需要这样考虑,我们是否单独考虑不同的分片shard?
回答:读取只命中本地的分片shard,本地的replica。
追问:这里的正确性保证,适用于跨分片的场景吗?
回答:是的,适用于事务级别。如果只读取本地replica,我们仍然需要确保事务的一致性。通过遵循这些规则实现该目标。
14.8 Spanner-时钟偏移(Clock drift)问题
Spanner的实现和时间戳强相关,要求不同机器的时钟必须准确。不同的参与者在时间戳顺序上需要达成一致。在系统中的任何地方,时间戳都必须是相同的。
**实际上,时钟和时间戳只对只读事务非常重要(matters only for R/O txns)**。
这里对时间戳不准确的场景进行分析:
时间戳偏大(TS too large)
比如只读事务T3在实际时间戳15执行,机器却认为在时间戳18执行,那么只读事务需要等待等待更长时间,即更大的时间戳之后的write出现后,才能得到read数据。所以时间戳偏大,只是单纯影响性能。
时间戳偏小(TS too small)
比如只读事务T3在实际时间戳15执行,机器的时钟错误导致认为T3在时间戳9执行,那么T3看不到T1(假设在时间戳10完成commit)的写入,这**打破了外部一致性(external consistency)**。
问题:假设T3机器的时钟有问题,在时间戳15时,给只读事务T3分配时间戳9。但是现实时间戳为15,这时候T3只读事务,读取本地replica,本地replica是不是可能从其他机器同步到了现实时间戳10的数据?
回答:是的,因为现实时间戳是15。但是由于T3机器时钟认为时间戳是9,所以不会给T3事务返回时间戳10的数据,而是会寻找时间戳9之前的最新已提交的数据。
14.9 Spanner-时钟同步(Clock Synchronization)
网络时间协议,英文名称:Network Time Protocol(NTP)是用来使计算机时间同步化的一种协议,它可以使计算机对其服务器或时钟源(如石英钟,GPS等等)做同步化,它可以提供高精准度的时间校正(LAN上与标准间差小于1毫秒,WAN上几十毫秒),且可介由加密确认的方式来防止恶毒的协议攻击。NTP的目的是在无序的Internet环境中提供精确和健壮的时间服务。
术语网络时间协议(NTP)适用于运行在计算机上的和客户端/服务器程序和协议,程序由作为NTP客户端、服务器端或两者的用户编写,在基本条件下,NTP客户端发出时间请求,与时间服务器交换时间,这个交换的结果是,客户端能计算出时间的延迟,它的弥补值,并调整与服务器时间同步。通常情况下,在设置的初始,在5至10分钟有内6次交换。 一旦同步后,每10分钟与服务器时间进行一次同步,通常要求单一信息交换。冗余服务器和不同的网络路径用于保证可靠性的精确度,除了客户端/服务器商的同步以外,NTP还支持同等计算机的广播同步。NTP在设计上是高度容错和可升级的。
使用原子钟(atomic clocks)
Spanner在机器上使用原子钟,以获取更精准的时间
与全球时间同步(synchronize with global time)
Spanner让时钟和全球时间同步,确保所有机器的时钟在全球时间上一致。使用GPS全球定位系统广播时间,作为同步不同原子钟的一种方式,然后保持它们同步运行。
论文中没有太多谈论真实时间系统如何工作,但看上去他们每个数据中心可能有少量或至少一个原子钟。比如时间服务器常规地与不同数据中心的不同time master通过GPS系统进行时间同步。
但就结论而言,Spanner依靠这些手段使得位于不同服务器上的时钟非常接近,论文中提到不同机器上时钟时间误差只有几微秒到几毫秒之间的量级。所以当访问操作系统获取当前时间时,可能与实际时间只相差几微秒/毫秒。
尽管进行了时钟同步,但仍存在一个误差范围。True Time会返回最佳估计值,即当前的绝对时间或真实时间是什么,加上机器的误差范围。
问题:论文中没有深入讲解同步时钟,通过GPS同步不同机器的时钟时,不应该考虑信息传递的时间吗?
回答:是的,前面没有特地说明,但他们同步时间时,可能通过时间库跟踪开始时间以进行估计平均延迟或正常延迟是多少,用来纠正时间以获取尽量精确的时间。他们协议也支持离散值,比如突然网络问题导致时间戳延迟许多,则你不该接收本次的时间同步值。同时时钟的时间振荡器要是出现问题,那么后续时间也不准确了。再次声明,论文并没有详细说明怎么进行时钟同步,但他们貌似是用了类似NTP的技术来处理这里的问题。
14.10 Spanner-时钟偏移解决方案TrueTime
6.824:Spanner详解 - 知乎 (zhihu.com) <= 推荐阅读。这里摘抄部分内容,作为补充说明,因为21版的视频这部分讲得有点模糊
Start Rule:为事务分配时间戳就是返回的TT区间中的latest time来赋值,用
TT.now().latest赋值,这确保事务被赋值的时间戳是比真实的时间要大一些。对于只读型事务而言,时间戳应该在开始的时候就赋予;对于读写型事务而言,时间戳应该在提交的时候再赋予。Commit Wait Rule:这个规则只针对于读写型事务,由于事务被分配的时间戳为TT区间中的latest,实际是要大于真实时间的,后续则需要等待真实时间大于这个时间戳后才能提交该读写型事务。这确保了读写型事务被提交的那个时间的数值是比被分配的时间戳要大。
服务器仅需循环调用TT.now()获取真实时间的情况,当获取的TT区间的earliest time都大于这个时间戳了,表明真实时间必然已经大于这个时间戳了。
我们需要解决的情况是,只读型事务要是被分配了相对于真实时间较小的时间戳,会导致只读型事务读取不到最新提交的数据。而只读型事务被分配相对于真实时间较大的时间戳的情况,只是需要多等待一会后续的write,但能读取新版本的数据。因此,我们需要避免只读型事务被分配较小的时间戳。而Start Time Rule保证只读事务的版本时间戳永远比实际时间戳大一点。
关于Spanner中的TrueTime和Linearizability - 墨天轮 (modb.pro) <= 推荐阅读,也是对TrueTime机制做补充。文章里面有具体的推算逻辑
Spanner通过TrueTime机制+Commit Wait机制,确保External consistency。
Spanner的TureTime API设计非常巧妙, 保证了绝对时间一定是落在TT。now()返回的区间之中。 基于这个保证, 使得分布在全球的spanserver分配的timestamp都是基于同一参考系, 具有可比性。 进而让Spanner能够感知分布式系统中的事件的先后顺序, 保证了External Consistency。
但是TureTime API要求对误差的测量具有非常高的要求, 如果实际误差 > 预计的误差, 那么绝对时间很可能就飘到了区间之外, 后续的操作都无法保证宣称的External Consistency。另外, Spanener的大部分响应时间与误差的大小是正相关的。
自Spanner在OSDI12发表论文后, Spanner一直在努力减少误差, 并提高测量误差的技术,但是并没有透露更多细节。
解决时钟偏移(Clock drift)的方案,即不使用真实时间的时间戳,或者不仅仅是使用纯粹的时间戳,而是使用时间间隔。
**每个当前时间now的返回值,不是单独值,而是一个时间区间[earliest, lastest]**。
这里有些关于时间的规则,需要修正:
当前时间规则(start rule: now.lastest):当前时间,取时间区间的lastest值
- 读写事务:在开始提交时分配当前时间
now.lastest作为时间戳(R/W:commit) - 只读事务:在事务开始时分配当前时间
now.lastest作为时间戳(R/O:start)
- 读写事务:在开始提交时分配当前时间
提交等待规则(Commit wait rule)
我们会在事务中推迟(delay)提交。如果(读写)事务在start commit时获得某个时间戳,延迟提交直到时间刚比
now.earliest大的时刻。
场景举例:
| 事务(实际开始时间) | 实际时间戳9 | 实际时间戳10 | 实际时间戳12 |
|---|---|---|---|
| T1 (7) | set X=1, Commit (这里先不关心T1的细节,假设实际时间戳为9时完成提交) | ||
| T2 (8) | Set X=2, 在实际时间戳9时获取当前时间,返回时间区间假设[8, 10],那么需要延迟等待到时间戳10时提交Commit | ||
| T3 (11) | Read X (X=2), Commit |
- 这里先不考虑T1读写事务的细节,这里假设T1在实际时间戳9完成提交。
- 而T2在实际时间戳8时开始读写事务,假设在实际时间戳9时获取当前时间,返回时间戳区间
[8,10],于是需要等到时间戳10时执行Commit。 - T3为只读事务,假设在实际时间戳9时获取当前时间,返回时间戳区间
[8,11],于是等到实际时间戳11时执行Read操作,于是读到最新的X数据为2(能看到T2的提交结果),符合外部一致性(External Consistency)。
14.11 Spanner-小结
为什么很多数据库自称受spanner启发,难道他们也有TrueTime API? - 知乎 (zhihu.com) <= 不错的讨论文章,推荐阅读
- 读写事务(R/W tx)是全局有序的(可串行化+外部一致性),因为使用2PL+2PC
- 只读事务(R/O tx)只读本地replica,通过快照隔离(snapshot isolation)确保读正确性
- 快照隔离,保证可串行化
- 按时间戳顺序执行只读操作,保证外部一致性
- 时间依赖完全同步的时钟,当前时间now采用时间间隔/区间表示
[earliest, lastest]
- 时间依赖完全同步的时钟,当前时间now采用时间间隔/区间表示
通过以上技术/手段,只读事务非常快,而读写事务平均100ms。读写事务慢的原因是跨国家/地区进行分布式事务。
问题:前面”14.3 Spanner-读写事务(read-write txns)”介绍中,一开始读写事务只执行读操作的时候,不需要和TC(事务协调者)通信是吗?
回答:是的,一开始的只读操作,只需要和Paxos的leader进行交互。后续的写操作执行时,才需要和事务协调者交互。
问题:论文中4.2.3部分,事务模式章节的部分,他们讨论的预测提交的时间。
回答:这部分这个课没有讲述。模式更改(schema-change)意味着向表中添加列或者删除表中的列等,改变了数据库的布局。模式更改通常代价高昂,他们确保做到原子,在未来某个时间点运行。所以这里模式更改时使用的时间戳超越了当前时间。而这时候系统中的事务还能继续,我想是因为这些食物都是用版本内存(version memory),他们创建版本内存直到遥远的未来。所以这里模式更改不会影响任何当前在运行的事务。正式提交模式迁移部分(commit the schema migration part)时,事务还是按时间前进的,规则是任何正在运行的事务都必须停止,直到迁移事务完成(migration transaction was completed)。因为迁移事务时间戳是新值。因为有版本内存,所以可以把迁移事务推迟到后面再进行。
Lecture15 乐观并发控制-FaRM(Optimistic Concurrency Control)
FaRM论文笔记 - 知乎 (zhihu.com) <= 网络大佬的笔记
15.1 FaRM-概述
非易失性存储器技术是在关闭计算机或者突然性、意外性关闭计算机的时候数据不会丢失的技术。非易失性存储器技术得到了快速发展,非易失性存储器主要分为块寻址和字节寻址两类。
如何实现内核旁路(Kernel bypass)?_夏天的技术博客的博客-CSDN博客_内核旁路 <= 原文列举出了很多流行的内核旁路技术
关于 Linux 内核网络性能的局限早已不是什么新鲜事了。在过去的几年中,人们多次尝试解决这个问题。最常用的技术包括创建特别的 API,来帮助高速环境下的硬件去接收数据包。不幸的是,这些技术总是在变动,至今没有出现一个被广泛采用的技术。
RDMA(Remote Direct Memory Access)技术全称远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的。RDMA通过网络把资料直接传入计算机的存储区,将数据从一个系统快速移动到远程系统存储器中,而不对操作系统造成任何影响,这样就不需要用到多少计算机的处理功能。它消除了外部存储器复制和上下文切换的开销,因而能解放内存带宽和CPU周期用于改进应用系统性能。
FaRM这是一篇2015年的研究论文,研究的主题是探索一些想法和技术来获取高性能的事务。FaRM在TATP基准上,使用90台机器,获取1.4亿个事务/秒。作为对比,Spanner能处理10~100个事务/秒。当然,两者是完全不同的系统,Spanner是全球范围内进行同步复制的事务系统,而FaRM的一切都在同一个数据中心内运行。
FaRM提供了严格的可串行化,类似于Spanner提供的外部一致性。FaRM整体目标是获取高性能。
FaRM为了获取高性能,采取如下手段/策略:
- 单数据中心(One data center):系统只部署在单个数据中心内
- 数据分片(shard):如果不同事务访问不同分片,那么互不影响,可完全并行。
- 非易失性DRAM(non-volatile DRAM):采用非易失性DRAM硬件,避免不得不写入稳定存储设备时的写入性能瓶颈。所以在他们的设计中,你不必写入关键路径到固态硬盘或磁盘。这消除了存储访问成本,接着需要解决CPU瓶颈和网络瓶颈。
- 内核旁路技术(kernel bypass):这避免了操作系统与网卡交互。
- 远程直接数据存取(RDMA):他们使用具有RDMA特殊功能的网卡,这允许网卡从远程服务器读取内存,而不必中断远程服务器。这为我们提供了对远程服务器或远程内存的低延迟网络访问。
- 乐观并发控制(OOC, Optimistic Concurrency Control):为了充分利用以上这些提速手段,他们采用乐观并发控制。对比前面经常谈论的悲观并发控制方案其需要在事务中访问对象时获得锁,确保到达提交点时拥有所有访问对象的锁,然后再进行提交;而使用乐观并发控制不需要锁,尤其在FaRM中,不需要在读事务中获取锁,当你进行commit时,你需要验证读取最近的对象,是则提交,不是则中止且可能伴随重试。FaRM使用乐观并发控制的原因,主要是被RDMA的使用所需动的。
FaRM命名来源:
- R远程remote
- M内存memory
- Fa快速Fast
Spanner目前仍是活跃使用中的系统,而FaRM是微软研究的产品。
15.2 FaRM-系统布局概述
UPS即不间断电源(Uninterruptible Power Supply),是一种含有储能装置的不间断电源。主要用于给部分对电源稳定性要求较高的设备,提供不间断的电源。
- 高速网络:数据中心中,90台机器通过高速数据中心网络连接,内部是一个交换网络。
- 数据分片:得不到不同机器上。根据分片的级别,被称为区域(region),region大小2GB。region分布在内存DRAM中,而不是在磁盘上。所以数据库的所有数据集必须和部署的机器的DRAM相适应。如果数据集大于所有机器的内存总量,则必须配置更多的机器和DRAM。
- 主备复制:如果宕机DRAM数据会丢失,所以他们也有主备复制(P/B replication)方案。这里通过配置管理器(configuration manager, CM)配合zookeeper,维护region到primary、backups机器的映射。
- 不间断电源:由于整个系统部署在单个数据中心,数据中心断电就会导致所有DRAM丢失数据,所以DRAM配置在有不间断电源(UPS)的机器上。如果发生断电,DRAM通过UPS即使将数据存储到SSD上,或者只是刷新内存中的内容(region、transaction、log等),之后恢复电源再从SSD加载DRAM存储的内容。这里仅在故障恢复时使用SSD。
在区域region中有一些对象object,可以把region想象成一个2GB的字节对象数组。
对象拥有唯一的标识符oid,由区域编号和区域内的访问偏移量构成
<region #, offset>对象有元数据信息,对象头部包含一个64bit的数字,底63bit表示版本号,顶1bit表示锁。这个头部元信息在乐观并发控制中起重要作用
15.3 FaRM-API简述
txbegin:启动事务
read(oid):读取指定oid的对象
write(oid, o):以指定的o对象更新对应oid的对象
txcommit:事务提交
当然,说不定有些情况还需要事务中止,但乐观并发控制,这里会采取重试事务。
FaRM会使用类似2PC的协议来执行原子操作跨region的对象。
问题:地址oid,是在机器本身的地址吗?
回答:是的,是对象所在的region的偏移量。region可以通过修改配置管理器里的映射而被移动,所以oid是一个region number+偏移量offset。
问题:创建全局地址空间背后的设计选择或设计思想是什么?
回答:即为了把所有数据存储到内存中,目标是在内存数据库上运行事务。
追问:所以它们共享一个全局地址空间?
回答:地址空间是按机器的,每个机器都有自己的地址空间,从0到某个数值。而对象的oid是全局编号或全局名称。
15.4 FaRM-内核旁路(Kernel-bypass)
DPDK介绍_growing_up_的博客-CSDN博客 <= 图文并茂,推荐阅读
DPDK是INTEL公司开发的一款高性能的网络驱动组件,旨在为数据面应用程序提供一个简单方便的,完整的,快速的数据包处理解决方案,主要技术有用户态、轮询取代中断、零拷贝、网卡RSS、访存DirectIO等。
FaRM除了故障恢复时需要SSD临时存储数据,否则其他工作时间采用DRAM读写数据,保证读写性能。解决数据存储设备瓶颈问题后,他们关注的是CPU瓶颈,所以采用内核旁路技术绕过CPU来处理网络数据。
FaRM作为用户程序运行在Windows操作系统服务器上。通常操作系统OS内的内核驱动程序(driver)读写网卡(network interface card, NIC)的寄存器来完成网络数据交互。而应用程序与网卡交互时,则需要进行内核系统调用,涉及到网络栈,相关的开销十分昂贵,而FaRM想要避免这类开销。
FaRM采用内核旁路记录,对网卡的发送/接收队列排序,这些队列被直接映射或进入应用程序的地址空间。先不考虑内核旁路实现细节,这里可以认为用户应用程序FaRM可以直接读写网卡数据,而不需要涉及操作系统。
在FaRM的内核旁路实现中,不采用中断机制来感知网卡数据,而是用一个用户级别的线程主动轮询网卡中的接收队列,查看是否有包可用,FaRM在应用程序线程和轮询网卡线程之间来回切换。
不少人可能听说过DPDK,这是一个利用内核旁路的开发工具包,是一个合理的标准,在诸多操作系统上可以使用。
15.5 FaRM-远程直接数据存取(RDMA)
RDMA是Remote Direct Memory Access的缩写,意思是远程直接数据存取,就是为了解决网络传输中服务器端数据处理的延迟而产生的。
除了内核旁路直接处理网卡数据外,FaRM还使用远程直接数据存储(RDMA)。RDMA需要网卡支持。
RDMA的大致使用介绍,即两台FaRM机器通过电缆(cable)连接,机器1可以将RDMA包通过内核旁路直接放入发送队列,机器1网卡接收到RDMA包后,将其发送到目标网卡(假设为机器2网卡),机器2网卡发现接收到RDMA包,解析与RDMA包一起的指令,这些指令可能描述的是读取特定内存位置或写入特定内存位置。例如,机器2网卡查看RDMA的指令,从机器2内存中读取某个位置的值,然后将其直接送回源头(机器1网卡)。
RDMA有趣的一点是,网卡能够直接操作内存,而不需要依赖中断或服务器的其他帮助,不产生中断,也不需要处理器上运行任何代码。相反,网卡具有固件执行这些指令,加载存储在内存中的值,请求内存地址直接进入响应包(response packet),并发回数据包。而接受端会在接收队列中获取RDMA的结果。
这里描述的RDMA流程对应的版本,论文中称为**单边RDMA(ont-sided RDMA)**,这通常指的是读取操作。
FaRM也是用RDMA进行写入,真正实现RPC,论文中称之为**写RDMA (write RDMA)**。和读取流程基本一致,除了发送方可以放入RDMA包,并说明这是一个写操作,将以下字节写入特定地址。
在论文中有两处使用到写RDMA:
- **日志(log)**:包括事务的提交记录等,源头可以通过写RDMA来append日志记录。每个发送方和接收方都有一个队列和一个日志,所以发送者可以管理和感知日志的开头和结尾是什么。
- **RPC消息队列(message queue)**:消息队列也是每对一个(one per pair),用于实现RPC。你如果想进行远程过程调用,客户端发送方生成write RDMA包,将数据信息写入RPC消息队列。而目标侧/RPC接收方有一个线程用于轮询(所有)消息队列,看到消息则进行处理,然后可以再使用 write RDMA进行响应。使用RDMA实现RPC比标准的RPC性能好(标准的RPC没有使用RDMA,需要经过传统的网络协议栈等流程)。
整体而言,RDMA是一种很棒的用于提高网络数据处理性能的技术,在过去十年来被各方普遍使用。在FaRM中,单边RDMA耗时约为5微秒,这比写入本地内存慢不了多少,非常快。
问题:可以重复一下网卡是如何工作的吗?
回答:客户端只有一个专门读取特定内存位置的线程,表示数据包是否已经到达。当网卡接收到包,将其放入接收队列中,作为接收队列中设置的一侧,标志位变为1,应用程序知道那里有一个包。
追问:是不是一个特殊的线程轮询?
回答:是的,系统中有特定的线程专门轮询队列。
问题:网卡是否与系统合作,正常工作,就像普通网卡一样?
回答:这不是普通网卡,这个网卡同时支持内核旁路(kernel-bypass)和远程直接内存访问(RDMA)。通常,网卡为了支持内核旁路,意味着它必须有多个接收和发送队列。它只项应用程序提供一对发送或接收队列。当然,你不能让计算机上每个进程都有一个发送和接收队列。这里通常是16个或32个队列,把其中一些放到特定的操作系统上,允许一些应用程序拥有发送接收队列。这也意味着有对RDMA的支持,并使它正常工作。所以它(FaRM)需要一个相当复杂的网卡,尽管如今这是一个合理的标准(即这类网卡现在很常见了)。
问题:这里是否存在任何验证步骤,为了确保你只在允许RDMA访问的内存区域进行写入?
回答:有的。当你设置RDMA时,为了做单边RDMA(one-sided RDMA)或写入RDMA(write RDMA),你首先必须进行连接设置(connection setup),在发送者和接收者之间存在协商步骤来设置,就好像TCP channel,虽然RDMA不采用TCP。但是RDMA建立了面向连接的可靠、有序的通道,所以安全检查和访问控制检查,是在设置时进行的。
追问:需要对每个机器都进行RDMA配置吗?
回答:是的。
追问:如果每个机器都需要手动进行RDMA配置,那么加入更多机器称为大集群,配置操作是昂贵的,对吧?
回答:是的,你会有n^2个RDMA连接需要配置。
问题:上面说的write RDMA的应用场景之一,日志log,也是存储在内存中,并且是和对象object存在不同位置?
回答:是的。你可以认为FaRM机器上的内存布局,即一部分用于区域(Region)存储对象(object)数据,一部分用于存放log,一部分用于存放RPC消息队列。
问题:为了让网卡支持从内存直接访问,这里不涉及网卡外的其他软件,甚至不需要通知应用或操作系统,不应该在硬件层面进行一些协调,或者至少从处理器支持这个特性?
回答:是的,网卡可以原子地读写缓存行。为了支持这点,有一个接口在内存系统和网卡之间,必须在操作系统仔细设置,当RDMA连接设置完成时。
问题:队列只用于读RDMA,而写入直接到接收者的内存?
回答:在 write RDMA中,可能会有确认响应,所以如果发送方发送 write RDMA,它可以等待来自接收方网卡的确认响应(acknowledgement),表示执行了写入RDMA。
15.6 FaRM-使用RDMA实现事务(transaction using RDMA)
前面提到的内核旁路(kernel-bypass),远程直接数据存取(RDMA)都是很棒的技术,但都算是业界内已存在的技术标准。而FaRM解决的真正挑战在于使用RDMA实现事务,即通过write RDMA和one-sided RDMA进行事务。
之前介绍过的事务协议、两阶段提交(2PC)等,都需要服务端(server-side)参与,意味着需要在服务器上运行代码。
而RDMA本身没有提供在服务器上运行代码的能力,所以需要论文的作者需要额外的协议实现2PC和事务,不使用或减少服务端参与。
15.7 FaRM-乐观并发控制(OOC, Optimistic concurrency control)
FaRM论文笔记 - 知乎 (zhihu.com) <= 图片出处
FaRM,用以实现事务的high-level strategy即**乐观并发控制(OOC, Optimistic concurrency control)**。
而真正值得关注的是FaRM对读取操作的处理,其无锁读取对象,当然这里需要依赖object的头部信息版本号判断数据版本。
如果读操作需要锁,就意味着需要中断服务器,服务器被中断后就需要中一些额外工作,这可能会阻止客户端直到锁可用才返回对象。使用锁的方案不是很适合RDMA。
FaRM只读事务基本流程:
- 事务无锁地读对象object,并记录数据的version版本号
- 提交前增加校验步骤(validation step)
- 如果发现版本号冲突,则中止abort事务
- 如果版本号没有冲突,意味着没有其他事务修改对象
- commit提交事务
一般情况下,如果提交前的校验步骤发现了版本冲突而中止事务,客户端随后会再次运行整个事务。这种乐观并发控制实现,读取操作可以完全利用RDMA,读取操作不需要服务器上的任何状态变化。
乐观并发控制与悲观并发控制相反,总是假设操作允许被执行,如果发现冲突(不允许的情况),则只需中止。而悲观并发控制需要获取锁和请求批准执行操作。
上图中C是事务协调者应用程序,应用程序运行在相同的机器上,其运行在90台机器的系统中其中一台,这里忽略机器数量,后续都假设在同一台机器上运行,方便课程讲解。P1~P3为3个分片的primary,每个都有对应的备份B1~B3。其中P1和P2的数据被读取和修改,而P3的数据仅被读取。上面虚线表示read RDMA(one-sided RDMA),实线表示write RDMA,点线表示网卡硬件的ACK确认响应。这里希望实现严格的可串行化。
**读写事务的流程分为两个阶段:执行阶段(execution phase),提交阶段(commit phase)**。
按照上图流程,假设已经完成了执行阶段,事务协调者读取数据、version版本号存储到内存,然后在提交点打算提交事务,事务后续要么提交成功要么中止,如果被中止,那原因就是有其他事务同时运行,并且修改了其中一个对象。
其中提交阶段(commit phase)又细分成5个步骤:LOCK、VALIDATE、COMMIT BACKUP、COMMIT PRIMARY、TRUNCATE。
加锁(LOCK)
获取所有正在写入的对象的锁,上图中可以看到有2个对象正在被写入。在这个图例中,write RDMA依赖primary的lock entry。primary拥有一个log日志记录锁的使用情况,写object时,追加log entry,其组成包括:被修改的object的原版本version、对象object的oid、对象object的新值new value。
上图P1和P2的数据被写,所以lock entry通过write RDMA追加到P1和P2的日志,P1和P2各自通过test-and-set完成object加锁操作,然后write RDMA信息附加到事务协调者TC的消息队列中,告知TC成功获取P1和P2的某些数据对象的锁。
如果P1和P2尝试加锁时已经有其他事务加锁了, 那么这里test-and-set失败,log里会记录加锁失败,并通过write RDMA附加消息到TC的消息队列,告知获取锁失败。这种情况下,TC会中止当前事务。
加锁只会发生在提交阶段,所以执行阶段写数据也不需要加锁,但是如果提交阶段加锁失败,意味着有其他事务修改了当前事务写的object,所以需要中止事务(如果继续执行,当前事务就违反了串行化)。
某种程度上,LOCK之后,VALIDATE之前,是写事务的串行化点(the serialization point for write transaction)。在这个点上,事务获取到所有执行阶段写的object的锁,其他事务都不能修改相关的object。
验证(VALIDATE)
校验步骤只使用了单边RDMA(one-sided RDMA),不需要真正的服务器参与。读操作不需要LOCK,但是需要VALIDATE步骤,校验version版本是否冲突(即是否被其他事务修改了),如果没有冲突则继续,有冲突则中止事务。
对于每个已读取但未修改的对象(示例中对应P3的数据),事物协调者TC请求从primary读取object对应的64bit元信息的底部63bit版本号。TC收到Read RDMA响应后,如果发现object的lock bit为1或者version发生变化,意味着其他并发事务尝试修改object,则中止事务,否则正常进行事务。
事务按照版本号的顺序提交,以此获取严格的可串行化,因为当前事务提交后,后续启动的任何事务都有更高的版本号。
**这里VALIDATE之后,COMMIT BACKUP之前,可认为就是事务的提交点(commit point)**,这里我们已经对所有被写的object获取锁,也校验了只读object的version。
提交备份节点(COMMIT BACKUP)
为了容错性,提交点后,TC先将被写的object的变更记录通过write RDMA同步到backup备份的日志log(而由于写操作发生在primary,primary已经有相关的object修改记录了,TC不需要向primary也同步一遍object变更记录)。log中记录的信息和primary在LOCK阶段记录的锁信息类似,包括:object的version number、oid、new value。
之后backup响应write RDMA,告知TC自身的log记录完毕。这时候TC知道之前交互的primary和现在交互的backup都已经拥有了被write的object的变更log记录。
提交主节点(COMMIT PRIMARY)
TC通过write RDMA附加事务commit tid信息到primary的日志log中,之后primary网卡确认写入RDMA,进行响应。(这里不需要任何中断,没有服务器参与,前面说过RDMA使网卡可以直接将数据发送到内存指定位置。只有网卡参与操作。)
此时TC得知tid事务真正执行完毕了。
截断(TRUNCATE)
tid事务执行完毕后,日志需要进行清理、缩短和截断等工作,这里TC通知被写数据object所在的primary和backup进行日志截断等清理工作。
截断(TRUNCATE)是耗时较长的步骤。而在我们看来提交主节点(COMMIT PRIMARY)后,截断(TRUNCATE)之前,就是事务结束的时间点。
问题:这里提交阶段(commit phase)的锁是怎么获取的,通过zookeeper吗?
回答:不是,另一套锁才会使用到zookeeper,那是为了进行配置管理,比如region number到primary和backup之间的映射。这里用的是内存锁,由primary自己维护。region中的object头部信息64ibt中,顶部的1bit用于表示锁lock,底部63bit表示版本version。
追问:这里lock是内存锁,那primary停机怎么办,backup是否和prmary持有相同的锁?
回答:如果primary停机,这里事务会中止。关于容错性,后面在详细讨论。
问题:版本号是针对每个object的,对吧?
回答:是的,每个对象。
问题:为什么对象已经被锁了之后,当前想加锁的事务直接中止,而不是选择阻塞等待锁被释放?
回答:因为对象被锁说明对象有新值,这里事务读取不到最新的值(因为读取操作在执行阶段已经执行完了,而加锁在后续的提交阶段中执行),所以事务必须中止。
追问:懂了,因为锁意味着当前对象下一次会发生改变。
回答:是的,但他们在写完对象后才会要求加锁。协调者给予某个版本号修改对象,提交了一些写入。假设写入最新的版本号,这个时刻,提交开始,然后你试图获取锁,结果发现另一个事务已经获取锁了。这意味着此时存在别的事务已经修改我们刚操作的对象了。而这时候如果继续事务,会违反串行化,所以中止事务。
问题:上图中,Primary或Backup机器的网卡是直接和TC的网卡交互?
回答:是的。回到前面RDMA的介绍中,TC的write RDMA发送到Primary或Backup的网卡,然后接收方网卡发现是RDMA包,解析后按照RDMA包的要求将数据放到指定内存位置,这里会将数据放到内存的log中,然后Primary或Backup网卡操作完毕后,发送确认响应给TC的网卡,TC会在网卡的接收队列中看到确认响应消息。
问题:所以写入RDMA只是写入日志?
回答:write RDMA用于两种情况,对应消息队列和日志追加。
问题:所以,当我们说已经执行了写入RDMA时,只是指它被附加到log中,并不一定由应用程序实际执行?
回答:是的。例如bakcup在log中收到来自TC的write RDMA附加的object变更信息后,应用会读取log记录,执行对应object的更新。
问题:每个对象的lock bit,由于所有数据都在内存中,object的64bit元信息,我想可以放入一个单一的内存地址,但假设处理器将内存地址提取到寄存器中,多核机器的不同内核读取相同地址,都将它们从0变成1,是否假设有一些来自硬件的支持?
回答:是的。LOCK阶段primary在log中收到来自TC的write RDMA,要求primary对object加锁,primary通过test-and-set加锁,然后回应。正因为object的元信息大小只有64bit,所以test-and-set指令是能够保证原子加锁的。就算是多核机器同时执行test-and-set,也只有一个core会成功,另一个会失败。
问题:这里VALIDATE之后,COMMIT BACKUP之前,当前事务到达事务的提交点(commit point)后,另外一个完全独立的并发事务,是否可能只写入P3进行交错?
回答:不能,因为如果写入P3,意味着在提交阶段会获取P3的锁,此时会检查P3的对象的锁bit和版本version。这里讲师说先保留这个问题,后面讲课再说类似场景。(我个人理解是可以交错的,因为当前事务对P3只是读取操作,并没有修改version,也没有对P3加锁)
问题:如果在执行阶段后,它试图获取一个锁,然后在那之后崩溃了,锁已经被获取,之后其他人无法获取。这之后怎么处理?
回答:这里锁只在内存中,所以Primary崩溃后,锁信息就丢失了。后续会讲的恢复协议中,协议这里会中止事务。
问题:这里事务协调者TC是客户端,就像应用程序一样,而客户端所有步骤,比如lock… (被打断)
回答:是的,你可以认为应用程序在论文中系统的90台机器上运行,运行这个事务,然后写P1、P2,读P3。
问题:所以Primary不直接和Backup通信吗?
回答:primary不直接和bakcup通信。除了在恢复协议期间,有各种各样的通信发生,但这里事务流程没有体现。
问题:这里事务协调者TC使用zookeeper的配置?
回答:是的。这里课程内没有讨论太多细节,但是由zookeeper和connection manager决定我们运行的当前配置,配置包括region的区域划分,region和主/备份之间的映射等等内容。在任何失败发生时,有一个完整的重新配置进程并恢复。
15.8 FaRM-严格的串行化(strict serializability)
严格的可串行化要求,如果当前事务在某个事务提交之后才开始,当前事务也要在那个事务之后提交,这通过协议的版本号保证。
- 如果T2在事务T1提交之后才开始,那么T2必须能观察到T1的结果。
- 如果T2在T1提交之前开始,那么T2和T1是并发事务,T1和T2可以观察到彼此,其顺序没有关系(T1和T2谁先执行都可接受)。(如果是读相同的数据,没有写操作,则互不冲突;如果存在写数据,则会有锁冲突,其中一方会中止事务,另一个成功)
这里按照下面举例的事务进行串行化讨论,假设T1和T2并发事务执行如下逻辑:
1 | |
这里T1和T2并发执行后,oid对应的对象o的值,可能是0~2任意一个值:0表示一个发生冲突所以中止,另一个失败/崩溃,或者两个都失败/崩溃;1表示一个成功,另一个冲突或失败;2表示两个都成功。
假设T1和T2都几乎在同一时间执行完Read操作,后续在提交阶段T1先获取锁(o被修改,需要锁),那此时T2可能获取到锁吗?
- 如果T1还没有提交,那此时T2会加锁失败,然后事务中止;
- 如果T1很快完成了提交使得T2这里获取到锁,那么后续在VALIDATE时,会发现o的数据version变动,也会中止事务。
所以,假设T1和T2都不发生崩溃,那么T1和T2一个成功后,另一个中止事务后会尝试重新进行事务。
问题:他们使用这个整个硬件结构,是否适用于悲观并发控制?
回答:理论上可行,因为这里通过RDMA实现的RPC性能更高。而前面的事务流程图中,可以看到P3只读操作,只需要单边RDMA,没有什么写入,性能很好(执行阶段一次单边RDMA,提交阶段的校验步骤又一次单边RDMA,然后没有后续步骤了)。但是这里RDMA必须配合乐观并发控制才能让只读事务提速。
问题:网卡读取内存的部分,安全吗?
回答:实际这里有操作系统和网卡之间的一系列设置,所以操作系统也不会允许网卡写入任意位置。
问题:关于性能的问题,得益于单边RDMA,读取操作很快,但如果有大量的写入,比如大量数据冲突?
回答:如果有冲突,那么只有一个事务能正常运行。如果事务操作的都是不同对象,那整体性能会高。
问题:FaRM这种设计(乐观并发控制)的主要应用场景是什么?
回答:有很多关于悲观和乐观并发控制的研究,比如TPC-C和TATP没有太多的冲突。可能是由不同的用户或不同的客户端提交的,它们接触/使用不同的表。
问题:如果有多个客户端在同一个对象上执行事务,它们想要执行write RDMA,写入到Primary或Backup的log,有没有可能发生冲突?比如其中一个会重写另一个日志之类的。
回答:不,写log说明有写操作,这里会获取锁。
问题:事务基于什么基准提供可串行化?是时间还是别的什么。
回答:版本号version。这里没有类似Spanner的TrueTime之类的机制,但版本号本身起到了类似时间的作用。
问题:如果两个事务获得了相同的版本号,那么只有先达到提交点的那个才会…(打断)
回答:是的。只有其中一个会成功,另一个会失败。
问题:如果在每一对机器之间都建立了消息队列,比如多个消息队列的消息都给primary,你怎么知道读取这些消息的顺序,而不会乱读它们的顺序?
回答:你以相同的顺序读取同一来源的所有消息。因为它们在接收方的同一个队列里。如果一个来源就对应一个队列,那多个机器同时写入不同的队列,你没法知道顺序是什么。
问题:论文中提到了无锁读取,也提到提供了本地线索(locality hints),使程序员能够将同一组机器上的相关对象相互关联。我不理解后段句什么意思,能解释下吗?
回答:我想你指的是,如果你的对象在各种不同的区域(regions),然后你必须和很多不同的primary交互。如果你总是接触同一个集群的对象,这是较好的情况,如果所有对象集群都在同一个primary上,那你只需要联系一个primary,而不是多个。
问题:所以FaRM不是很适合长事务?
回答:是的,你担心长事务会更容易导致冲突。
问题:假设有一个事务T1先写入分片1,分片2,然后读取分片3,此时T2在T1完成提交之前,读取分片3然后写分片3,并且比T1先执行了提交阶段的步骤,会发生什么?
回答:你说的这个场景,假设T1的version是0,T2的version是1,那么T2能成功提交,而T1会中止,因为T1晚进入校验阶段,会发现自己version落后了。
追问:我想知道的是,如果T1在执行完VALIDATE后,准备执行COMMIT BACKUP之前,T2完成了提交,那T1会怎么处理?
回答:这个等下节课举例的时候再进行说明。
问题:可串行化使我们能够对事务重新排序,或许前一个问题T1和T2,我们可以对其重新排序,避免问题描述的场景发生?
回答:这里FaRM采用的是严格的可串行化,不会对事务重排序。严格的可串行化要求,如果事务在某个提交之后开始,事务也要在那个事务之后提交,这通过协议的版本号保证。
15.9 FaRM-严格串行化的正确性
这里举一个经典用例,常用来测试协议是否提供可串行化。当然用例本身不能用于证明可串行化,但它是关键的例子之一。
T1和T2两个事务的逻辑伪代码如下:
1 | |
这是一个很好的可串行化测试,要么T1在T2之后进行,要么T2在T1之后进行,这里要么x=1要么y=1,但永远不该出现x和y都为1(违背了可串行化)。
这里对FaRM用同样的场景,划分时间线来看看T1和T2并发执行会发生什么。
| 事务 | 时序1 | 时序2 | 时序3 |
|---|---|---|---|
| T1 | Read x(version0), Read y(version0) | 假设T1先进入提交阶段,Lock Y(因为Y发生写操作),Valiadate X(version还是0) | |
| T2 | Read y(version0), Read x(version0) | T2后进入提交阶段,Lock X(因为X发生写操作),Validate Y(version还是0,但是Y的64bit元信息的顶1bit 锁位是1,已经有锁),Y校验不通过,事务中止 |
这里假设T1先进入提交阶段,Lock步骤会对Y加锁。假设T2后进入提交阶段,那么在Validate时,会发现Y被加锁,所以T2中止事务。至少在这个例子里,如果FaRM放任T1和T2都能提交,那么将获得X和Y都变成1,不符合可串行化;但实际上FaRM在这里会中止T2事务。
问题:对于事务来说,如果只是读操作,可以无锁操作?
回答:是的,前面”15.8 FaRM-严格的串行化(strict serializability)”的事务图流程可以看出来,事务只读P3数据时,只有在执行阶段度数据时执行一次单边RDMA,以及在提交阶段的VALIDATE步骤执行一次单边RDMA,但没有涉及锁操作,没有任何写入,没有任何记录附加。也正是因为如此,FaRM在只读事务上能获得高性能。在只读事务中,不需要执行提交阶段的LOCK步骤。
问题:为什么只读事务,还需要在提交阶段执行VALIDATE步骤,不是只读取值吗,为什么还需要验证版本?
回答:因为可能另一个事务修改了当前只读事务读取的对象,而修改对象的事务提交后,当前只读事务需要能观察到最后的写入。
追问:但是如果它们同时发生(写事务和只读事务),我们可以以任何一种方式对它们进行重排序。
回答:是的。
追问:所以在我看来,只读事务的第二次涉及RDMA的校验VALIDATE步骤,你第一次读取它,第二次看到版本应该是相同的,在我看来第二次验证似乎没有必要。(我感觉他疑问就是,按照前面说的严格串行化,如果T2在T1提交之前开始,那么T1和T2是并发事务,顺序不重要。所以只读事务和写事务如果并发运行,就没必要要求只读事务一定要读取并发的写事务的新version数据,反正读事务可以排在前面,进而不需要验证version)
回答:你可能是对的,我之前没仔细想过这个问题。如果是只读事务(也就是说没有任何写操作),那么验证肯定是不必要的。但是当有混合事务(事务内既有写操作,也有读操作)时,你需要验证VALIDATE步骤。(我个人想了下,这里只读事务的VALIDATE是不能省略的,不然可能出现:只读事务开始前,X和Y版本都是0,但是只读事务开始时,读取到X的version0数据,而Y读取由于延迟,读取到version1的数据。假设另一个并发事务同时写X和Y,version最后都变成1,但是只读事务却读到两个不同版本的数据。不符合可串行化。按照可串行化规则,如果T1和T2并发,我们可以对T1和T2任意重排序,那么T1要么在T2之后,要么T1在T2之前,所以只读事务中X和Y要么都读取到version1,要么都读取到version0,才是正确的。)
问题:按照上面说的,如果事务完全只有读操作,你在只读事务中希望原子地读取两个对象,在读取第一个对象之后,有另一个事务修改了另一个对象…(打断)(我猜想这个老哥疑问点,比如是 if X = 0 and Y = 0这类的只读事务逻辑,可能只读事务只做这两个读取,然后后续代码需要依照这个条件做其他事情)
回答:这里回答比较含糊,基本可以认为没有回答。(我个人认为,这个老哥的疑问是对的,这里只读事务不能删除VALIDATE步骤)
15.10 FaRM-容错(Fault tolerance)
这里不深入讨论FaRM的容错机制,主要谈论FaRM容错实现中遇到的挑战。
事务协调者通知应用程序后发生崩溃(TC crashes after telling application):事务必须被持久化,因为我们已经通知应用程序事务已提交,所以我们不能丢失事务已完成的所有写入。
假设在COMMIT PRIMARY之后崩溃,那么我们已经commit提交事务了,后续我们有足够的信息能恢复整个系统,确保已完成的写入能够持久化。
这里最坏的情况是B2崩溃了,即提交阶段的COMMIT BACKUP步骤执行时,B2丢失了被修改的object的记录,primary可能还没有提交记录,因为它在我们看到一个primary的确认后崩溃了,所以我们假设P1有提交记录,当然backup有B1的提交记录,所以这在恢复时有足够的信息。事务已经提交,有tid事务commit记录,我们有备份中的所有信息(锁、描述写事务的提交记录),所以恢复阶段我们有足够的信息来确认事务是否已经实际提交。对于新的TC,恢复进程来决定这个事务已经提交,应该持久化。
(吐槽:这里容错,我个人觉得视频基本没讲清楚,草草就过了,估计是因为FaRM实在占用太多课程时间了。)
15.11 FaRM-小结
- Fast:高性能,尤其是只读事务无锁
- Assume few conflict:系统假设冲突少,所以采用乐观并发控制实现事务。也因为使用了单边RDMA,不需要任何服务器参与,使用乐观并发控制实现契合度更高。(论文中通过一些基准测试,表明系统本身冲突的场景很少)
- Data must fit memory:数据必须存储在内存中,这意味着如果你有一个非常大的数据库,你需要增加机器或内存。如果数据集就是太大,内存存储不下,那你应该使用传统的数据库系统,采用持久存储进行读写。
- Replication is only within datacenter:复制只在单个数据中心内进行。与前面讨论的Spanner截然相反,Spanner针对的是跨国家/地区/数据中心的同步事务,同步复制。
- Require fancy hardware:系统需要依赖特定类型的硬件,主要包括两个:UPS,使数据中心在安全故障中存活下来;RDMA网卡,获取高性能。
到这里为止,已经讨论完分布式系统中最具挑战性的部分,即构造容错存储系统。这节课往后的内容,会讨论与存储系统无关的其他知识。
MIT6.824网课学习笔记-02
【MIT 6.824】学习笔记 1: MapReduce (qq.com) <= 2021版网络大佬的笔记
简介 - MIT6.824 (gitbook.io) <= 知乎大佬的gitbook完整笔记(2020版,我这里看的网课是2021版),推荐也阅读一遍2020版课程的大佬笔记
6.824 <= 课程表
Lecture16 BigData-Spark
MIT 6.824:spark - 知乎 (zhihu.com) <= 网络博主的笔记
16.1 Spark-简述
某种程度上,Spark是Hadoop的继任者(毕竟都是批处理框架),通常用于科学计算。Spark很适合需要执行多轮mapreduce的场景,因为Spark将中间结果保存在内存中。
这篇论文中定义的RDD已经过时了,RDD被**数据帧(dataframes)**取代。但是数据帧(dataframes)可认为是特定列的RDD(RDD with explicit columns),RDD的所有好的设计思想同样适用于数据帧(dataframes)。这节课只讨论RDD,并将其等同于数据帧。
- In-memory computaion:Spark针对内存进行计算
16.2 Spark-RDD执行模型(execution model)
Spark中的Transformations和Actions介绍_sisi.li8的博客-CSDN博客_spark actions transformations <= 有详细的算子清单描述
- 所有的
transformation都是采用的懒策略,如果只是将transformation提交是不会执行计算的,计算只有在action被提交的时候才被触发。action操作:action是得到一个值,或者一个结果(直接将RDD cache到内存中)Spark:Stage介绍_简单随风的博客-CSDN博客_spark stage <= stage划分讲解,图文并茂
spark——宽/窄依赖 - 知乎 (zhihu.com) <= 图文并茂,推荐阅读
spark中, 某些操作会导致RDD中的数据在分区之间进行重新分区。新的分区被创建出来,同时有些分区被分解或合并。所有基于重分区操作而需要移动的数据被成为shuffle。在编写spark作业时,由于此时的计算并不是在同一个executor的内存中完成,而是通过网络在多个executor之间交换数据,因此shuffle操作可能导致严重的性能滞后。shuffle越多,作业执行过程中的stage也越多,这样会影响性能。之后的计划中将会学习spark的调优,所以shuffle过程将会在后面的学习中进行补充。
spark driver会基于两方面的因素来确定stage。这是通过定义RDD的两种依赖类型来完成的,窄依赖和宽依赖。
spark持久化操作 persist(),cache()_donger__chen的博客-CSDN博客_spark persist
spark对同一个RDD执行多次算法的默认原理:每次对一个RDD执行一个算子操作时,都会重新从源头处计算一遍。如果某一部分的数据在程序中需要反复使用,这样会增加时间的消耗。
为了改善这个问题,spark提供了一个数据持久化的操作,我们可通过persist()或cache()将需要反复使用的数据加载在内存或硬盘当中,以备后用。
了解RDD编程模型的最好方式就是先了解一些简单用例:
1 | |
- 这里创建一个RDD对象lines,该RDD存储在HDFS中,例如第100万条记录在HDFS分区1上,第200万条数据在分区2。这个RDD lines代表了这组分区。运行这行时,什么都不会发生,即论文所说的**惰性计算(lazy computations)**,实际计算在后续才进行。
- 创建第二个RDD对象errors,接收对只读对象lines过滤仅保留开头”ERROR”的数据行。这里同样没有进行计算,只是预先创一个一个**数据流(dataflow)**,或者论文中所说的**计算迭代图(iterative graph of the computation)**。后续如果完整到某个action操作时,整个逻辑流水线式执行,即先创建lines,后过滤lines的数据获取errors,再进行后续的其他RDD操作。
- 指定RDD对象errors在内存中保存,以便后续计算使用
- 过滤errors中的数据,只保留带有”MySQL”字眼的记录,使用
count()这个action操作统计数量(实际导致计算) - 过滤errors中的数据,只保留带有”HDFS”字眼的记录
- 用
\t切割字符串后保留第3个匹配的切割后字符串部分 - 最后
collect()该action操作,汇总结果(实际导致计算)
可以看出来这里和Mapreduce有很大不同。在mapreduce中,每次运算完后数据回到文件中,下一轮计算需要重新从文件中读取数据;而这里Spark使用persist方法避免从磁盘重新读取数据。
RDD的API支持两类方法:Transformations和Actions,Actions才是实际导致计算发生的操作。
- Transformations:负责将RDD转换成别的RDD,**每个RDD都是只读(read-only)或者不可变的(immutable)**。所以你不能修改RDD,只能从现有的RDD生成新的RDD。
- Actions:实际执行计算。只有执行了Actions后,前面的Transformations涉及的文件操作等逻辑才会实际被执行。
假设是使用命令行用Scala编写Spark,那么在4和7执行的时候,用户交互的命令行界面才会返回,因为执行的count()和collect()都是action操作,会实际触发Spark进行计算。action操作对应的时间点,Spark会collect许多worker,向它们发送jobs,或者通知调度器(scheduler)需要执行job。
问题:当错误文件从P1(HDFS分区1)中提取出来时,然后另一个错误文件从P2中提取出来,我理解上这是并行发生的?
回答:是的,就像mapreduce中有很多worker,worker在每个分区上工作,调度者scheduler会发送job给每个worker,而job是和数据分区关联的task。worker获取一个task后运行。所以你可以在分区之间获得并行性。你也会得到流水线中各个阶段之间的并行性。
问题:lineage和事务日志(the log of transactions)有什么不同,是否只是操作粒度不同(the granularity of the operations)?
回答:目前我们看到的日志是严格线性的(strictly linear),lineage也是线性的,但稍后会看到的使用fork的例子,其中一个阶段依赖于多个不同的RDD,这在日志中不具有代表性。它们有一些相似之处,比如你从开始状态开始,所有的操作都是具有确定性的,最后你会得到某种确定性的结束状态,就这点上它们是相似的。
问题:这个filter的例子中,它只需在每个分区上应用filter,但有时,比如我看到transformation也包含join或sort。
回答:是的,join和sort更复杂,后序介绍。
问题:第三行persist是不是我们开始进行计算的时候?
回答:不,这里还没有任何东西会被计算出来,前三行仍然只是在描述Spark程序需要执行的操作。
问题:前面的代码中,如果不调用errors.persist,会发生什么?
回答:如果不调用errors.persist,那么后续发生的第二次计算,即(序号7. action,collect),Spark需要先重新计算errors(我理解上,指的是需要重新构造lines对象RDD,然后过滤得到errors。即如果没有保存RDD到内存,那么当前RDD进行完一次action计算后,下一次如果代码中用同一个RDD想进行下一个action计算,就需要重新从源头构造当前的RDD)
问题:对于不调用persist的分区,在mapreduce的情况中,我们把它们存储在中间文件中,但我们仍然将它们存储在本地文件系统中。Spark这里处理数据时,是会产生中间文件存储在磁盘中吗,还是将整个数据流处理保存在内存中?
回答:默认情况下,整个流都在内存中,但有一个例外,稍后会详细讨论。代码序号3.这里persist使用另一个flag,应该是reliable。然而集合存储在HDFS,这个称为checkpoint(代码序号2.)。
问题:对于分区,这里代码序号2.对应的HDFS,说有多个分区,这个是Spark临时为每个worker进行的分区划分HDFS数据?
回答:代码序号1.对应的lines这个RDD产生于HDFS。这里说的分区,是HDFS文件直接直接定义的(也就是说原始的HDFS中的文件本来就分区好了,不是后面SPark临时分区的)。但是你也可以执行repetition重新分区的transformation,一般是stage这样做,后续会提到。比如使用hash partition技巧,你还可以定义自己的分区程序,提供一个分区程序对象或抽象。
追问:所以这里代码里HDFS文件分区,之前就已经由HDFS处理了,但如果你后续想Spark再自定义patition流程,也可以再来一次。
回答:是的。
16.3 Spark-worker窄依赖容错
和mapreduce处理容错的方式基本一致,Spark中的某个worker崩溃时,需要重新执行stage。
这里只讨论Spark的worker崩溃的情况。Spark的worker崩溃,意味着丢失内存中的数据,或者说丢失RDD的partition数据,而后续的RDD计算部分可能依赖于丢失的partition。所以,这里需要重新读取(reread)或重新计算(re-compute)这个partition分区。调度器(scheduler)某时刻发现没有得到worker的应答,然后重新运行对应partition的stage。
和mapreduce函数式编程一样,视频中列举的transformations算子,都是函数式的。它们将RDD作为输入,产生另一个RDD作为输出,是完全确定性的(completely deterministic)。所以这里如果发现一个worker崩溃了,scheduler重新安排某个worker生成同样的partition即可。
问题:所以就是因为函数式API实现,所以Spark能保证partion重计算后不变?
回答:是的。
16.4 Spark-worker宽依赖容错
如”16.3 Spark-worker窄依赖容错”所述,Spark的窄依赖容错,和mapreduce的容错处理基本一致。相对更为棘手的是宽依赖的容错处理。
假设有个Spark在指令流中,child-RDD-1的数据来源自parent-RDD-1~parent-RDD-3的结果,假设是由于进行了join等操作,而child-RDD-1往下执行产生child-RDD-2。此时如果产生chid-RDD-2的worker崩溃,为了恢复这个RDD,就需要往源头追溯,重新计算,最后会追溯到需要parent-RDD-1~parent-RDD-3并行进行重新计算。显然,如果还是按照窄依赖的方式进行容错恢复,性能损耗严重。
对于宽依赖容错恢复,解决方案是设置检查点或持久化RDD。
比如在parent-RDD-1~parent-RDD-3取checkpoint检查点存储的partition快照RDD,而不是重新进行并发计算。之后只需要重新计算child-RDD-1~child-RDD-2即可。
问题:如果使用了一般的persist函数,但是论文也提到了一个RELIABLE flag。想知道,使用persist函数和使用RELIABLE flag有什么区别?
回答:persist函数,意味着你将RDD保存到内存,后续action计算可以重复使用(默认是一个action触发后,后续其他action使用到同样的RDD用于触发计算时,需要重新计算一遍这个被依赖的RDD,而persist会保存这个RDD在内存中免去重新计算);checkpoint或者RELIABLE flag意味着,你将整个RDD的副本写入HDFS,而HDFS是持久或稳定的文件存储系统。
问题:有没有一种方法可以告诉Spark不再持久化某些东西,因为如果你持久化了RDD,而且你做了大量的计算,但是后面的计算不在使用那个RDD,你可能会把它永远留在内存中。
回答:Spark使用了一个通用的策略,如果真的没有空间了,它们可能会将一些RDD放到HDFS或者删除它们,论文对具体的计划有些含糊。当然,当计算结束,用户退出或停止driver,那我想那些RDD肯定从内存中消失了。
16.5 Spark-迭代计算PageRank
[google pagerank_百度百科 (baidu.com)](https://baike.baidu.com/item/google pagerank/2465380?fromtitle=pagerank&fromid=111004&fr=aladdin)
PageRank,网页排名,又称网页级别、Google左侧排名或佩奇排名,是一种由根据网页之间相互的超链接计算的技术,而作为网页排名的要素之一,以Google公司创办人拉里·佩奇(Larry Page)之姓来命名。
PageRank通过网络浩瀚的超链接关系来确定一个页面的等级。Google把从A页面到B页面的链接解释为A页面给B页面投票,Google根据投票来源(甚至来源的来源,即链接到A页面的页面)和投票目标的等级来决定新的等级。简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
PageRank算法详解 - 知乎 (zhihu.com) <= 推荐阅读
在实际应用中许多数据都以图(graph)的形式存在,比如,互联网、社交网络都可以看作是一个图。图数据上的机器学习具有理论与应用上的重要意义。 PageRank 算 法是图的链接分析(link analysis)的代表性算法,属于图数据上的无监督学习方法。
PageRank算法最初作为互联网网页重要度的计算方法,1996 年由Page和Brin提出,并用于谷歌搜索引擎的网页排序。事实上,PageRank 可以定义在任意有向图上,后来被应用到社会影响力分析、文本摘要等多个问题。
PageRank是一个对网页赋予权重或重要性的算法,(权重)取决于指向网页的超链接的数量。
这里代码用例通过Spark实现PageRank算法,如果最后补充ranks.collect(),那么计算就会实际在机器集群上进行:
1 | |
这里有2个RDD,其中links表示图的连接/边(the connection of the graphs),即URL之间的指向关系;而ranks表示每个url的排名。(这里省略代码讲解的记录,想仔细分析的可以看原视频)
这里links通过persist()常驻内存,所以下面ranks在for循环中迭代使用links,不需要重新计算links,直接从内存中读同一份RDD对象links即可。
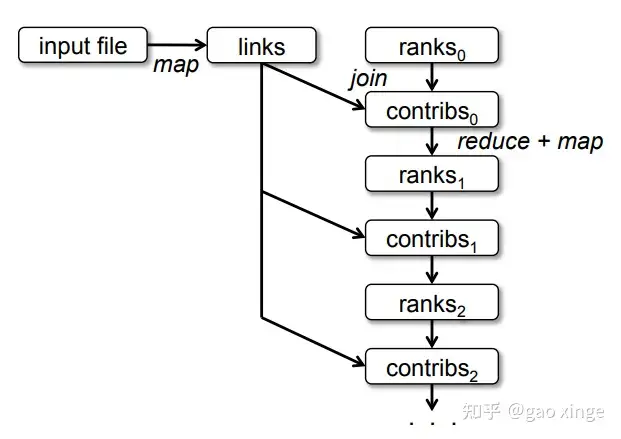
随着ranks中迭代次数的不断增加,每一次循环(图中的contribs)都是一个stage,当调度器计算新的stage时会将transformation的一部分附加到lineage graph中。代码中,links被保存到内存,下面ranks中每一次循环都会重复使用links。图中links和ranks在每次循环中做join,构成一个stage,这里涉及网络分区通信,论文中提到一些优化手段,可以指定分区RDD,使用hash分区,意味着links和ranks文件,这两个RDD将以相同的方式分区,它们是按key或hash key进行partition的。论文中提到这里可以通过hash key分区,使得具有相同hash key的数据partition落到同一个机器上,这样即使join直观上是宽依赖,但是可以像窄依赖一样执行。比如对于U1,对应分区P1,你只需要查看links的P1和ranks的P1,而hash key以相同的方式散列到同一台机器上。scheduler或程序员可以指定这些散列分区,调度器看到join使用相同的散列分区,因此就不需要做宽依赖,不需要像mapreduce那样做一个完整的barrier,而是优化成窄依赖执行。
这里如果一个worker崩溃,你可能需要重新执行许多循环或一次迭代,所以这里可以设置比如每10次迭代生成一个checkpoint,避免重新整个完整的计算。
问题:所以我们不是每次都需要重新计算links或其他东西,比如我们不持久化的话?
回答:这里唯一持久化的只有links,这里常驻内存,而ranks1、ranks2等都是新的RDD,但你偶尔可能像持久化它们,保存到HDFS中。这样如果你遇到故障,就不需要循环迭代从0开始计算所有东西。
问题:不同的contribs,可以并行计算吗?
回答:在不同的分区上,所以是可以并行计算的。
16.6 Spark-小结
- RDD by functional transformation:RDD是函数式转换创建的
- group togethr in sort of lineage graph:他们以谱系图的形式聚集在一起
- reuse:允许重复使用
- clever optimization:允许调度器进行一些优化组织
- more expressive than MR:表现力比mapreduce更强
- in memory:大多数数据在内存中,读写性能好
问题:我想论文中提到了自动检查点(automatic checkpoints),使用关于每次计算所需时间的数据,我不太理解是什么意思。但是,他们将针对什么进行优化?
回答:可以创建一个完整的检查点,这是一种优化。创建检查点是昂贵的,需要时间。但在重新执行时,如果机器出现故障,也要花很多时间。比如,如果你从来不做检查点,那么你要从头开始计算。但如果你定期创建检查点,你不需要重新计算。但如果你频繁创建检查点,你可能把所有时间都花费在了创建检查点上。所以这里有一个优化问题。
问题:所以可能计算检查点,需要非常大的计算?
回答:是的,或者在PageRank的情况中,也许每10次迭代做一次checkpoint。当然如果检查点很小,你可以创建checkpoint稍微频繁点。但在PageRank中checkpoint很大, 每个网页都有一行或一条记录。
问题:关于driver的问题,driver是不是在客户端?
回答:是的。
问题:如果driver崩溃,我们会丢弃整个图,因为这是个应用程序?
回答:是的,但我也不知道具体会发生什么,因为调度器有容错。也许你可以重新连接,但我不太清楚。
问题:关于为什么dependency optimization的问题。你提到他们会进行hash patitioning,这是怎么回事?
回答:这个和Spark无关,是数据库数据常见的分区概念。即假设对dataset1和dataset2使用hash partion,之后相同hash key的links和ranks数据会分布到同一个机器上,而此时对links和ranks进行join,就不需要机器进行网络通信,直接在机器本地进行处理即可。即多个机器处理多个分区,但是每个分区内links和ranks的join只需要本地进行,不需要和其他机器网络通信。
问题:什么时候是宽依赖,什么时候是窄依赖?
回答:明确的父RDD和子RDD是一对一那就是窄依赖;如果是1父RDD对N个子RDD,就是宽依赖。
问题:worker和stage?
回答:每个worker在parition上运行一个stage。所有stage在不同的worker上并行运行。pipeline中每个stage是批处理(batch)。
Lecture17 缓存一致性-Memcached缓存系统
MIT6.824 Facebook的Memcache - 知乎 (zhihu.com) <= 网络博主的笔记
一致性是指同一时刻的请求,在缓存中的数据是否与数据库中的数据相同的。
- 强一致性:数据库更新操作与缓存更新操作是原子性的,缓存与数据库的数据在任何时刻都是一致的,这是最难实现的一致性。
- 弱一致性:当数据更新后,缓存中的数据可能是更新前的值,也可能是更新后的值,因为这种更新是异步的。
- 最终一致性:一种特殊的弱一致性,在一定时间后,数据会达到一致的状态。最终一致性是弱一致性的理想状态,也是分布式系统的数据一致性解决方案上比较推崇的。
这是一篇2013年来自Facebook的论文,memcached在网站开发中很常用。这篇论文不目的不是介绍构建系统的新思想/新概念/新方式,更多的是构建系统的实践经验的总结。
在这种情况下,可以支持10亿/s的请求量。从论文中可以学到3个lesson:
- 高性能:只使用市面上现有的组件构建系统,但是整体性能很高。
- 性能和一致性之间的取舍:设计主要受性能驱动,但同时想要得到某种程度的一致性。这里Facebook的应用不需要真正的线性一致性,比如新闻的消息延迟了一会后才更新并不影响业务。
- 经验法则:cautionaru tables,论文中列举了一些警示项。
17.1 网站演变
- 单服务端,单DB
- 多服务端,单DB
- 多服务端,多DB(分片或其他手段,使DB处理环节也有并行性。这里可能涉及分布式事务,需要2PL+2PC)
- 多服务端,多DB,添加缓存
到了4. 添加缓存时,系统新增了缓存层(cache layer),每个单独的缓存服务器被称为memcached daemon,整个缓存集群称为memcache。
这里的主要挑战包括:
- 如何保持数据库和缓存之间的一致性
- 如何保证数据库不会过载
17.2 最终一致性(eventual consistency)
Facebook这里不追求强一致性/线性一致性,他们追求的是:
- 顺序写入(write ordering):写入按照某种一致的整体顺序应用,你不会在时间问题上感到奇怪,这些由数据库完成,对于memcache层不是大问题
- 可接受读旧数据(reads are behind is ok):读取短暂落后也没关系。
- 例外就是客户端进行写后读,即写后要求读到刚更新的数据。(clients read their own writes)
zookeeper也是不同session不保证读到其他session的最新写入,但是同一个session内写后读能读到最新数据。
17.3 缓存失效方案(cache invalidation)
Facebook的基本方案即,**缓存失效方案(cache invalidation plan)**。
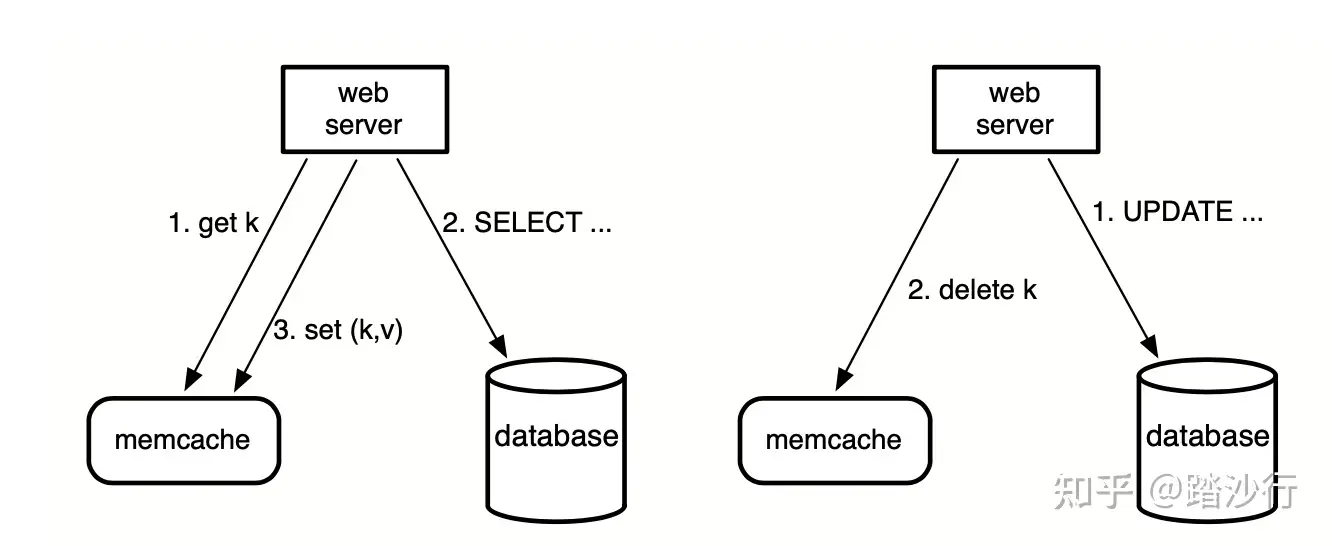
FE前端将数据写入MySQL,此时squeal监听MySQL的事务日志,发现有一个key被修改,向缓存发送失效消息,缓存将会删除指定key的value缓存。此时另一个FE发起read,缓存不命中,然后从MySQL读数据,之后将数据加入缓存。
问题:为什么不在删除缓存后,立即更新缓存呢?
回答:那就是所谓的更新方案(update scheme),原则上也是可行的,但实现会更麻烦点,这里缓存、数据库、客户端之间会需要一些cooperation。比如client1和client2发请求,原本client1发送的x=1应该更早生效,client2发送的x=2应该后生效作为新值,但由于网络问题,导致client2请求先被处理,如果用更新方案,缓存x=2,后续client1请求被处理后,缓存x=1,这里缓存中的x会一直都是旧值。当然,你可以通过修改MySQL内部一些流程,比如要求按序处理client1和client2的请求等等。但是这里系统希望能直接用现成的组件搭建,而不是再进行复杂的修改,所以论文中选择的是失效方案。
17.4 系统优化
Facebook为了容灾,在两个地区部署了数据中心:
只有primary数据中心接收数据的写入,backup数据中心只读
就算是backup数据中心发生了写入请求,也会请求primary数据中心
primary数据中心的数据变化,通过squeal进程监听并同步到backup数据中心
这里primary和backup之间存在一定延迟,不过系统不追求强一致性,所以可以接受。
系统获取高性能的手段(按序逐渐增加优化手段):
- 分区或分片 (partition or shard data)
- 大容量 (capacity):一般对数据分区后,每个分区可以容纳大量数据
- 并行度 (parallism):分区后,不同分区数据读取可以并行
- 复制数据 (replicate data)
- 热键友好 (hot key):可以使相同键扩展到不同的memcached服务器(两个数据中心),缓解单点热键问题
- 需扩容 (capacity):复制数据本身需要另外的硬件资源,但本身没有扩大存储的数据的容量
- 构造集群(cluster)
- 热键友好 (hot key):同一个数据中心内,再将单缓存服务扩展成缓存集群服务,热键由单实例存储复制到集群内多实例
- 减少连接 (reduce connection):避免了incast congestion问题,集群内实例均摊了前端的缓存数据请求TCP连接
- 网络压力 (reduce network pressure):很难建立具有双向带宽的网络,这里流量均摊到集群内的实例,整体网络压力承载量大
如果系统中有冷键,其将被存储在多个regions,基本上什么都不做。所以Facebook还有一个额外的pool,称为region pool,应用程序可以决定保存不是很受欢迎的键到regional pool,它们不会在时间上跨所有集群复制,你可以考虑region pool在多个集群之间共享,用于不太受欢迎的键存储。
问题:这里如果backup发起写请求,会写到primary,但是这里backup缓存失效后,因为同步需要时间,backup可能还是会缓存到旧数据?
回答:是的,后面会说怎么处理这个问题。
17.5 保护数据库(protecting db)
什么是惊群,如何有效避免惊群? - 知乎 (zhihu.com)
惊群效应(thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(或者线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群效应。
假设所有的memcache都失效了,db就算分片了也不能够扛下10亿/s的查询请求。
新建集群 (new cluster)
假设新建了一个cluster,预想分担系统50%流量,但是new cluster的memcache还没有数据,如果50%读请求都进入new cluster,会导致流量都直接击中底层db,导致db崩溃。所以这里创建new cluster时,会填充new cluster的memcache,待预热完缓存数据后,再实际切50%流量到new cluster。
惊群问题 (thundering herd problem)
某个热键被更新后,缓存失效,多个前端请求同一个热键,得到null后都请求db查询数据,增大了数据库瞬时压力。这里Facebook采用租约(lease)解决这个问题,即热键失效时,某个前端获得lease,负责更新该缓存,而其他前端则retry请求缓存,而不是直接查询db。(这里lease用于解决性能问题,后续会提到同样也解决一致性问题)
缓存崩溃 (memcache server failed)
如果不做处理,缓存崩溃后,会有大量请求直接发送到db,增加db压力。这里系统设置了gutter pool,用于临时处理memcache崩溃的场景。当memcache崩溃后,改成查询gutter pool,若还是没有,就查询数据库然后将数据放到gutter pool中(同样起到缓存作用,但gutter pool只是容错应急用的,非常态使用)。
17.6 缓存读写竞争(race)
避免缓存旧值(avoid stale set problem)
Client1执行
get(key),Client2执行delete(key),Client1执行put(key)。由于有lease机制,这里C1执行get时获取lease,而C2执行delete时会使得C1的lease失效(因为更新了db,所以C2需要让key缓存失效),后面C1的put会失效(被拒绝)。利用lease机制,避免了”17.5 保护数据库(protecting db)”提到的惊群问题,也避免了这里旧值填充的问题。冷集群预热时缓存其他集群旧值(cold cluster)
C1更新db值,执行
delete(key),C2从cold cluster读数据未命中,从另一个cluster缓存取数据,并执行put(key)。这里C2设置的缓存还是旧值。这里Facebook通过two-second hold-off,推迟两秒机制解决该问题,其规定从cold cluser删除key值后,2s内不能对那个key做任何put操作。所以这里举例的C2执行的put操作会被拒绝。这种问题只会出现在集群预热阶段,即集群新建后暂时没有数据,会从其他运行中的集群取数据(可能由于primary和backup之间同步延迟问题,导致取到旧缓存值)。因为这问题只出现在预热阶段,所以他们认为2s够用了,这也足够让其他写入传播/同步到cold database。backup写后读不到值(primary/backup)
C1在backup执行写操作,数据会写到primary的DB,随后backup的缓存失效(执行
delete(key)),此时C1直接get(key)取到空值,因为primary的数据修改通过squeal同步到backup的缓存需要时间。这里Facebook通过remote marker解决该问题。当C1执行delete(key)后,标记key为”remote”,后续马上执行get(key)时,发现key的”remote”标记,于是从远程的primary的缓存读取值,而不是从本地读取。完成get(key)后,再移除key的”remote”标记。
问题:即使没有lease invalidation机制,我们仍然会遵从弱一致性,你会获得在过去某个时间发生的顺序写入。但至少这能确保观察到自己的写入,对吗?
回答:lease还能确保你不会回到过去(读旧数据)。
17.7 小结
- 缓存的重要性(caching is vital):正确的使用缓存,使得论文中的系统能够承载10亿/s的请求
- 分区和分片(partition and shard):分区和分片,提高整体存储量和并行度
- 复制(replicaiton):均摊热键访问成本
- 缓存和DB的一致性处理:利于lease、two-second hold off、remote marker等特殊技术手段,保证系统的弱一致性,主要是防止出现长期缓存旧值的问题。
问题:远程标记(remote marker),他们怎么知道这是一个相关的data race。或者他们怎么决定什么时候需要使用远程标记?
回答:论文中没有明确说明,但猜测是为了保证最终一致性(eventual consistency)中的写后读能读取到刚才的最新写入。
问题:他们对get请求使用UDP,对其他请求使用TCP,这是一种业界普遍的做法吗?
回答:一般人们更喜欢用TCP,但TCP开销更大。有些人喜欢在UDP上使用他们自己的类似可靠传输协议的技术,比如QUIC等。
Lecture18 fork一致性-SUNDR
18.1 SUNDR简述
拜占庭将军问题(Byzantine failures),是由莱斯利·兰伯特提出的点对点通信中的基本问题。含义是在存在消息丢失的不可靠信道上试图通过消息传递的方式达到一致性是不可能的。
分布式系统入门 | 拜占庭将军问题 - Alan-Yin - 博客园 (cnblogs.com) <= 详细的文章,推荐阅读
拜占庭故障(也叫做交互一致性,源一致性,错误雪崩,拜占庭协议问题,拜占庭将领问题和拜占庭故障)是一个计算机系统的状态,特别是「分布式计算」系统中,其中的组件可能会故障,并且在组件故障时可能发生故障信息。
项目开始时,并不清楚总共需要多少台计算机才能保证 n 台故障计算机的阴谋不会“阻挠”正确运行的计算机达成共识。Shostak 表明至少需要
3 n+ 1,并设计了一个两轮3 n+ 1消息传递协议,该协议适用于 n = 1。他的同事 Marshall Pease 将算法推广到任何 n > 0,证明3 n+ 1是充分必要的。这些结果,连同Leslie Lamport后来使用数字签名证明 3n 的充分性,发表在开创性的论文—— 《Reaching Agreement in the Presence of Faults》(在存在故障的情况下达成共识)。
该章节主要讨论的主题为**去中心化的系统(decentralized system)**。
去中心化,即没有单一的权威机构(single authority)来控制这个系统。前面介绍的系统,或多或少所有的机器和服务在某种程度上合作(cooperate),且在单一机构处于或任何单一autority的控制下。
去中心化的系统更难建立,因为你可能不得不解释**拜占庭失败(byzantine failures)**。在过去的课程中,介绍的分布式协议,都是默认认为每个参与者都遵守协议规则,但在拜占庭问题和拜占庭参与者之间,情况就不一样了,可能有参与者恶意捏造虚假数据进行传输。这类话题,位于分布式系统(distributed system)和安全性(security)的交汇点(intersection)上。后面即将介绍的论文,主要就和密码学或安全理念有关,比如签名(signing)和哈希(hashing)。
可能有人好奇,SUNDR有被普遍使用吗?实际上没有任何系统直接实现SUNDR,或者直接基于SUNDR。但是,SUNDR提出了一些强大的技术或设计思想,特别是signed log,尽管是概念设计。同样的想法出现在很多其他去中心化的系统中。从git到比特币(Bitcoin),或其他类型的**加密帐本(cryptographic ledger)**,都能看到类似的设计思想。有一个系统直接收到SUNDR的影响,即Keybase,其被Zoom收购。
18.2 SUNDR论文背景
论文动机,是为了设置网络文件系统(network file system)。回想之前读过的Frangipani论文,其主题也是实现一致的网络文件系统。不同的是,SUNDR这里认为网络文件系统可以是拜占庭式的,攻击者可能通过某些手段得以操控网络文件系统。
SUNDR实际上不是在文件服务器上维护整个文件系统,文件系统尽可能简单,类似Frangipani论文中的Pedal,它几乎就像一个块设备,而客户端真正实现了文件系统。所以在SUNDR中,不是client向serevr发送、创建文件,而是从block服务器发送数据块和读取数据块。
SUNDR就整体文件操作流程,和Frangipani论文类似,文件系统在client,server负责硬件磁盘块(blocks)资源管理。两者最大的在于,Frangipani的文件系统Pedal和所有client之间是完全信任的,而SUNDR中client不受信任,文件系统本身也不可信。
这篇论文主要集中在一些安全属性的讨论,重点是**完整性属性(integrity properties)**。与保密性(confidentiality)相反,保密性关于保护数据避免泄漏;而完整性只是为了确保系统结构是正确的,检测数据非法修改行为,无论数据本身是否公开。
比如,2003年Debian Linux遭受过恶意开发者在代码嵌入trapdoor的问题,而Debian Linux被部署到众多服务器上使用。当时Debian Linux为了处理该问题,开发冻结了几天,试图找出源代码库中哪些部分仍然是正确的,以及哪些部分被攻击者修改了。这类攻击会周期性地发生,Ubuntu在2018年或2019年也有出现类似的问题。
18.3 安全场景举例
zoobar是一个虚拟银行类型的应用程序,系统的注册用户可以互相转移zoobar(充当货币的作用)。
- A:某有权限修改
auth.py的程序员,主要负责权限校验开发 - B:某有权限修改
bank.py的程序员,主要负责银行交易等行为的开发 - C:某拷贝git项目,部署zoobar代码,后续由于代码有后门等原因被攻击的大冤种
这里明显存在安全隐患:
- 某个程序员S偷偷修改
auth.py,导致C部署项目后,项目内缺失身份认证的一些关键步骤,存在安全漏洞。 - 某程序员S针对C修改了
bank.py,删除了里面关于身份校验的逻辑,导致银行业务内不在进行身份认证等校验。因为银行业务流程本身没有改动,所以相对难察觉。
接下来谈谈一些常见的处理手段,来尝试避免上面的安全隐患。
修改文件后,对文件使用非对称加密,即public key加密。这样程序员S无法获取到程序员A的私钥,无法完成程序代码auth.py的修改,因为S没有密钥,签名自己的代码修改后上传会被代码托管服务器拒绝。但这里S仍有方法攻击,比如发送程序员A以前修改过的auth.py文件,这个文件以前由A签名,所以能成功上传,也许旧代码存在安全漏洞。另外,S可以声明删除auth.py文件,C无法知道这是否正常,这可能需要对系统所有文件做一个捆绑,以某种方式决定文件系统最新版本是什么,来避免这个问题。
18.4 SUNDR设计思想
从前面的18.3 安全场景举例,可想到网络文件系统存在很多攻击的方式,并且对应的修复方法并不容易或很难只通过某一种手段完全规避攻击。而SUNDR论文就是为了试图解决这类问题。
SUNDR论文提到了一个设计思想,即**对操作的日志签名(signed log of operations)**,尽管论文本身没有直接实现这个大的想法。可以理解为操作日志的增强版本,在日志条目有签名的情况下,涵盖了条目及之前的条目。
我们在前面的所有**分布式系统(distributed systems)**和**故障恢复协议(recovery protocols)**中看到,日志是一个非常强大的设计思想,经常用于保证系统的正确性,同样也适用于拜占庭背景下的系统正确性保障。
这里假象一个log结构如下,假设写操作为mod,读操作为fetch:
| mod auth.py signed A | mod bank.py signed B | fetch auth.py signed C | Fetch bank.py signed C |
|---|---|---|---|
这里每次读或写操作都进行log记录,并且每次操作完后,需要对当前操作记录log以及之前的log进行签名。即signed B这里签名的log包括当前B对bank.py的mod操作,也包含之前A对auth.py的mod操作。这样当client C接收到B的log时,就不可能丢失A的日志条目,因为一旦丢失,签名就对应不上。通过这种机制,服务器现在更难有选择地删除日志条目。
此时如果有一个用户下载项目代码,其参与维护,经过以下流程:
- 校验签名(check signatures):项目中所有的操作log都有签名,只要对不上,就知道项目有其他恶意开发者篡改代码。
- *检查最后一个日志条目(check its own last entry)**:**这是为了保证客户端不会被服务器回滚,所以服务器总是检查最后一个条目,确保最新的log修改条目没有被恶意攻击者回滚*。比如A新增了一个mod操作log,但S通过某些手段回滚log记录,使A的修改在log中不存在。
- 构造文件系统(construct FS):它知道文件系统系统没有被回滚到旧版本,所以可以应用所有现存的修改,基本上就是在client上构建文件系统树
- 新增操作log条目并签名(add entry log + sign):对项目进行修改,在操作log中新增条目,并对其进行签名(和前面说的一样,需要对当前log条目以及之前的log条目进行签名)
- 上传操作log到文件系统服务器(upload log to FS):本地记录log后,向服务器上传log。
这个协议在现实中是未完成的,但提供了一些设计概念,让我们思考最终怎么成功在拜占庭服务器的上下文中实现安全。
18.5 SUNDR为什么记录fetch
可能有人会有疑问,修改操作记录log中很正常,为什么fetch读取操作也要记录到log中?
假设fetch操作不需要记录到log中,那么前面”18.4 SUNDR设计思想”的log可以看作如下:
| mod auth.py signed A | mod bank.py signed B | ||
|---|---|---|---|
C一开始从服务器获取前面的log(比如到A的操作log为止),校验无问题后,安装auth.py;后面B的操作log也发送过来,C发现B对bank.py进行了修改,校验log后无异常,于是安装bank.py。问题在于这里A和B之间的修改可能对应的系统版本不一致。比如auth.py对应系统版本1,bank.py对应系统版本2,两者同时运行会有一些异常。
而如果log需要记录fetch,那么故事变更如下:
- C fetch
auth.py,服务器发送过来prefix,即A和B的操作记录 - C add fetch to log,upload log,C获取log后,添加fetch操作记录,上传log到服务器
- C fetch
bank.py,服务器发送过来prefix,包括A和B操作,以及C刚才的fetch操作记录。此时如果log中没有刚才新增的fetch操作,C就会拒绝该日志
(这里稍微有点懵,感觉大意就是如果没有把fetch加入log的话,那么当前client只会一味地接受新log,新log产生的影响可能对上次读log得到的数据有影响;而如果把fetch加入log,那么client就能感知到新log插入的位置在自己fetch之前还是之后,避免新log对已读出的数据有影响却无感知的问题。)
问题:当前例子中是什么阻止服务器将fetch放在日志的正确位置?
回答:每个日志条目都包含之前的所有条目(指签名),服务器不能在fetch A和B之前的prefix之后修改切片。
问题:假设它只想发送A的修改,它知道A的修改和之前所有内容的hash,然后它可以把fetch C插入到那里,因为它知道,这是一个hash。
回答:是的,然后他们就不能发送B的修改。因为B的修改直接在A之后,所以它也不能切分A和B。
18.6 fork一致性
目前看到的是,服务器不能真正操作日志,它只能发送prefixes或hide parts,他可以将前缀发送给client,但它自身不能修改log。所以log被时刻修改时,不同客户端可能看到不同版本的log。这就是fork一致性的含义。
fork一致性场景举例,下面描述A、B、S三方的log记录:
| server S | a | ||
|---|---|---|---|
| client A | a | b | c |
| client B | a | d | e |
A和B从S fetch log后,自己在本地修改,后续并发地upload log到S。这里可以看出来A和B都拥有同样的a日志前缀记录,但是后面各自的本地log不一样,S接收到A和B的log后,作为服务端不能擅自修改log,所以根据fork一致性,会同时保留A和B的两条log修改链路,而不是直接合并到原有log上。
18.7 如何检测fork
这篇论文提到了两个检测fork的方案:
- 带外通信(out-of-band communication):如果A和B互相访问,询问对方最后一条记录是什么,得到不同的答案,他们就意识到双方造成了log分叉。如果没有分叉,一方的log应该是另一方的前缀。所以客户端可以定期交换最新的日志条目,确保不产生log分叉。
- **三方受信时间戳机器(timestamp box)**:引入某种受信任的机器,比如时间戳机器。它将时间戳添加到log中,每个客户端知道它是一个文件。在文件系统中,包含当前时间,时间戳机器每隔几秒钟就更新一次文件,客户端读取该文件。他们知道每隔几秒钟会有一次新修改。这里timestamp box相当于就是fork
第二种方案也就是SUNDR论文中提出的。Bitcoin比特币就采用类似方案二的方式,以某种方式达成读取共识,决定哪个fork能继续执行。
18.8 用户粒度文件系统快照(i-handle)和版本向量(version vector)
为处理fork一致性问题(即让用户在不同fork上做取舍,决定使用哪个fork),SUNDR采用用户文件系统快照和版本向量(版本向量包含快照i-handle和用户修改计数)。
服务器维护log,而其他人维护snapshot快照。实际上SUNDR所做的,不是字面上创建快照,而是维护着文件系统的快照视图,并针对每个用户。文件系统按照用户进行分片,每个用户都有属于自己的视图快照。这里有一些协议确保不同的快照和不同的用户是一致的。
SUNDR中,有一种叫做用户i-handle的东西,用户i-handle唯一标识文件系统中的快照。i-handle对应一个i-table的加密hash表,其记录系统中所有inode的hash值。当某个文件被修改时,对应的inode节点hash值会更新,往上追溯,i-table、i-handle都会更新。这提供给用户一个完整的文件系统快照。
而为了处理用户之间的一致性,SUNDR提出了**版本向量(version vector)**的概念。每个版本向量对应一个用户的i-handle,比如A在修改auth.py后有一个i-handle,同时版本向量维护所有用户的当前i-handle的修改计数。比如对于A的i-handle有记录{A:1; B:0; C:0}表示只有A修改了A自身的i-handle一次,其他人没进行过修改。
用户对于整个文件系统的快照i-handle,以及每个用户(包括当前用户)对当前i-handle的修改次数,作为一个版本向量(version vector)整体进行签名。
1 | |
18.9 小结
梅克尔树(Merkle trees)是区块链的基本组成部分。虽说从理论上来讲,没有梅克尔树的区块链当然也是可能的,只需创建直接包含每一笔交易的巨大区块头(block header)就可以实现,但这样做无疑会带来可扩展性方面的挑战,从长远发展来看,可能最后将只有那些最强大的计算机,才可以运行这些无需受信的区块链。 正是因为有了梅克尔树,以太坊节点才可以建立运行在所有的计算机、笔记本、智能手机,甚至是那些由Slock.it生产的物联网设备之上。
- 拜占庭参与者问题(Byzantine participant):拜占庭参与者问题,需要在去中心化系统中处理。因为没有单一的机构作为信任的来源/担保。
- 签名式日志(signed log):签名式日志,是对付恶意服务器的一个强大工具,后续的课程会讨论这类日志如何在比特币中使用。特别是fork一致性,fork是如何被创建的,在比特币案例中是如何解决的。
这些就是去中心化系统主要讨论的知识点/技术点。
问题:SUNDR使用B+树还是什么数据结构?Merkle tree和这些数据结构有什么区别
回答:SUNDR使用Merkle,因为提出这个结构的人就是这个名字,所以称这种树结构为Merkle tree。
问题:验证签名时,如果log有100个条目,需要计算100次hash吗?
回答:通常只计算一次,也就是最后一个新增的条目。虽然理论上每个log entry的签名需要重新计算,但实际应用中,一般用户本地也会保存之前的log的hash值,只需要计算后面新增的hash值进行比对就好了。(提问者吐槽这样效率低,但是就是这么做)
问题:所以hash就像一条Merkle chain?
回答:是的。同样的想法。
问题:如果改变文件系统中某几个block,是所有block的hash都需要重新计算吗?然后再追溯到inode、i-table、i-handle?
回答:只需要计算被修改的几个block的hash,然后往前追溯相关的inode(block对应的inode)、i-table(对应的几个inode)、i-handle(对应的i-table)需要重新计算。论文有提到一种优化可以让这一过程计算更快,但hash通常很快,而签名才是成本更高的操作。
问题:我们使用版本向量来确保系统不会返回/回滚到旧状态,那为什么系统不直接返回旧状态和旧版本向量,如果它保留第二份复制的话?
回答:版本向量只有fork一致性,SUNDR fork一致性,没有保证更多其他别的。
问题:fork一致性,需要用到时间戳吗?
回答:fork一致性,我的意思是,服务器可以在任何时间点fork日志,为他们可以将日志合并回一起提供一致的视图。(如何合并决策权还是在client端,sevrer端只是负责存储各种fork情况的log发展分支)
问题:所以这里我们能做到的最好的情况就是保持fork一致性,它允许fork,但我们可以检查出fork。
回答:是的。
追问:这里我们能检测到fork,那么能得到比fork一致性更强的东西吗?
回答:我们可以选择一个fork并继续。
追问:但是SUNDR没有办法做到这一点。
回答:是的。(我理解上就是SUNDR的server不直接决定哪个fork能继续,而是交给client自己决定用哪个fork继续,sevrer只负责存储多个用户版本向量,换言之server保存多个fork,但不对外声明哪个fork是所谓的正统/主干)
问题:SUNDR现在提出了一些(检测fork的)方法吗?
回答:检测fork的方法,提出时间戳机器来检测fork。
问题:时间戳机器只是一个附加条目的服务器?
回答:是的,并且是可信的,不在对手的控制下。
Lecture19 p2p比特币(peer-to-peer bitcoin)
谈论比特币的一个很大原因在于,其完成了实现难度高的**拜占庭参与者达成共识(consensus with byzantine paticipants)**。
人们可以随意加入或退出,其中有些人是恶意的,并且在事务发生的顺序上达成了共识,这是一个很有挑战性的实现,尤其是比特币还和金钱相关。
和SUNDR类似,比特币也有**签名的操作日志(signed log of operations)**,比特币也能处理fork (handle fork)。
比特币是一个真正开放的系统,可以容忍拜占庭参与者,并达成共识。
19.1 实现的难点
担心出现完全的伪造(concern outright forgery)
人们试图凭空捏造交易,并输入日志中,试图误导其他参与者。从根本上,签名操作使伪造变得困难。这里假设密码系统不易被攻破,所以很多核心流程经密码学加密处理后,认为是可靠的。
双重花费(double spending)
假设你手头有一些比特币,一个拜占庭参与者试图花费同一个比特币两次。通过查询所有交易的公共账本或公共日志,判断是否存在这种情况,并就日志的以往交易记录达成共识,避免重复消费同一个比特币能成功。
偷窃(theft)
论文中讨论不多,即有人偷窃了别人的私钥,因此可以冒充身份花钱或使用比特币。因为人们将自己的钱包和签名密钥存储在计算机上,这使得黑客有机会破解并窃取他们财产。(这里不会花太多时间介绍这个,这里主要集中讨论分布式系统方面的知识)
19.2 交易简述
这里简化交易的记录,即一个交易记录主要包含以下数据:
- 转账的目标用户的公钥(public key),dst
- 之前交易的hash值(hash(prev))
- 比特币的前持有者的私钥签名(signature),src
- 金额,更多的dst、src…(这里出于简化交易流程的描述,不对其他数据做描述)
一条记录表示比特币经过src的同意,从src转移到dst。交易也是经过编码(encoded)的,而不是纯粹的记录,这里忽略这些细节。
- T6:pub(x), ….
- T7:pub(y), hash(T6), sig(x) // 这里表示x因为某些原因向y转账
- T8:pub(z), hash(T7), sig(y) // 假设y想要在咖啡店买咖啡,于是向z比特币支付费用
这里假设y的密钥只有y知道,否则任何人可以顶替y进行签名,即使用y钱包的钱进行消费。
这里z可以对交易记录进行校验,有效则完成实质的交易。
19.3 双重花费(double spending)
区块链中双重支付/ 双重花费/ 双花是什么? - 区块链文库 (5m88.com)
双重支付是一个故意的分叉,是指具有大量计算能力的节点发送一个交易请求并购买资产,在收到资产后又做出另外一个交易将相同量的币发给自己。攻击者通过创造一个分叉区块,将原始交易及伪造交易放在该区块上并基于该分叉上开始挖矿。如果攻击者有超过50%的计算能力,双重花费最终可以在保证在任何区块深度上成功;如果低于50%则有部分可能性成功。
考虑一下双重花费问题(double spending)。
这里假设前面举例中,y对同一笔比特币生成2次交易记录(y creates two txn records)。假设Z和Q都是拿铁店,Y试图同时产生两笔交易。
- T8:pub(Z), hash(T7), sig(y) // Y => Z
- T8’:pub(Q), hash(T7), sig(y) // Y => Q
如果Z和Q都认同了交易记录,那么Y将收获两份拿铁,但是只实际支付了一份拿铁的费用。
处理方法即,检查所有之前存储的日志。交易记录在log中按序存储,假设如下:
…. T6,T7,T8,T8’
这时Q检查到T7为止,发现交易都还是正常的,但是到T8时,发现原本Y打算转给Q的比特币实际已经被消费,于是拒绝T8’交易。但现在问题在于,我们怎么确保系统中所有参与者都同意这个日志?
所有交易都在同一位置,包含相同的内容、相同的hash,相同的签名,所以我们可以验证交易,这就是共识问题涉及的场景。人们有时也把现在所述的这种验证方法称为**中本聪共识(the Nakamoto consensus protocol)**。
19.4 共识问题思考
日志顺序和fork思考:
假设有一个受信的服务器S,其他客户端C1、C2、C3向S发送交易记录T5、T6、T7….。最后由S对这些交易记录进行排序。很显然,在比特币的场景下,服务器S不可信,所以这种方案不可靠。
如果用之前SUNDR的思路,则可以让Client生成log,Server只负责追加log,那么同样会遇到fork的问题,即可能出现两个分支:
- T5,T6,T7,T8
- T5,T6,T7,T8’
按照SUNDR的思路,server产生fork后,由client自行达成共识选择fork。这里假设Z走fork1,Q走fork2,两者校验log都会认为Y的交易是合法的(即没有检测出来双重花费)。显然,直接这么设计不合理。
网络中日志顺序思考:
假设Client往网络中其他多个服务器都发送log,那么怎么确定最后每个服务器在追加log的顺序上达成共识?可以想到之前Raft等共识算法处理方式即majority大多数原则,只要所有服务器中大多数(超过一半)都认为log应该是某个顺序排列的,那么这种序列作为主流传播。
然而,在比特币这种去中心化的系统中,系统节点在任何时候都可能加入或离开,并且系统中没有维护所有参与者的列表,所以也无法得知系统在什么情况达到majority大多数。majority解决共识问题的方案不适用于比特币这类去中心化的开发分布式系统,只适用于Raft这类在设置中封闭的系统。
19.5 加密货币的共识算法PoW和PoS简述
与要求证明人执行一定量的计算工作不同,权益证明要求证明人提供一定数量加密货币的所有权即可。权益证明机制的运作方式是,当创造一个新区块时,矿工需要创建一个“币权”交易,交易会按照预先设定的比例把一些币发送给矿工本身。权益证明机制根据每个节点拥有代币的比例和时间,依据算法等比例地降低节点的挖矿难度,从而加快了寻找随机数的速度。这种共识机制可以缩短达成共识所需的时间,但本质上仍然需要网络中的节点进行挖矿运算。因此,PoS机制并没有从根本上解决PoW机制难以应用于商业领域的问题。
POS一并解决了POW浪费能源和算力集中两个痛点,理论上还能缩短了共识时间,但同时也丢弃了POW的某些优势,因此更容易分叉,一笔交易需要等待更多确认才能确保安全,而POS最大的问题是其安全性和容错性还没有得到严格的数学论证。
Proof of Stake 是什么? - 知乎 (zhihu.com)
权益证明(PoS)是一种公共区块链的共识算法类别,它依赖于验证者在网络中的经济利益 。 在基于工作证明(PoW)的公共区块链(比如比特币和当前实施的以太坊)中,算法奖励解决密码难题的参与者,以验证交易并创建新的区块(即采矿)。 在基于PoS的公共区块链(例如以太坊即将推出的Casper实现)中,一组验证者轮流在下一个区块提出投票并投票,每个验证人投票的权重取决于其存款的大小(即股权)。 PoS的显着优势包括安全性,集中化风险降低和能源效率 。
区块链共识算法Proof-of-Stake (PoS权益证明) 常见问题解答 (1)_济源IT小伙一枚的博客-CSDN博客_proof-of-stake
其关键的想法在于,**工作量证明(proof-of-work, PoW)**。基本规则即,一个机器节点需要经过大量的计算才能扩展日志(extend the log),通过PoW胜出的节点决定下一个log entry。
为什么PoW是有效的?因为很难冒充winner。扩展日志时需要解决的问题,实际上需要一台计算机进行一个月的计算。(因为矿工通过挖矿能获取比特币,所以不需要担心没人挖矿,即增加了其他人双重花费的难度)
而PoW的缺点也很明显,那就是浪费资源(energy waste)。
由于PoW浪费资源严重,后续出现了其他加密货币或其他设计,基于其他想法,比如基于**权益证明(proof-of-stake)**。
在PoS中,假设你拥有3%的货币,那么你可以决定3%的日志条目,哪个可以被追加。PoS不需要解决PoW中的计算密集型难题。PoS也获得业界关注,其中**以太坊(Ethereum)**是使用PoS的代表之一。
问题:冒充PoW中的winner有多难,假设我们有服务器A和B,A想要log附加e1,B想追加e2。而A解决难题并发布解决方案,然后B认可A的解决方案。B不能直接用自己的签名重新发布解决方案,是因为e2的难题(puzzle)和e1的难题不一样是吗?
回答:是的,难题不同,后续会介绍更多细节。但是这足以决定在哪个fork上,比特币会接受fork,就像SUNDR一样,比特币通过某种方法决定选择哪个fork。
问题:网络分区(network partitioin)问题。假设能做到在广大互联网级别的网络分区,那就不能证实某人确实双重花费(double spend)。比如这个人在两个网络分区里进行花费。假设这里网络分区时间持久很长。
回答:比特币基本上每10min产生一次交易日志。如果你想小心地避免double spend,那么你通常会等待更多的日志entry,比如5~6个,所以基本是经过了1个小时,在真正决定接受(某些新产生的fork)之前,仍在正确的fork上。
19.6 区块链(block-chain)
区块链,就是一个又一个区块组成的链条。每一个区块中保存了一定的信息,它们按照各自产生的时间顺序连接成链条。这个链条被保存在所有的服务器中,只要整个系统中有一台服务器可以工作,整条区块链就是安全的。这些服务器在区块链系统中被称为节点,它们为整个区块链系统提供存储空间和算力支持。如果要修改区块链中的信息,必须征得半数以上节点的同意并修改所有节点中的信息,而这些节点通常掌握在不同的主体手中,因此篡改区块链中的信息是一件极其困难的事。相比于传统的网络,区块链具有两大核心特点:一是数据难以篡改、二是去中心化。基于这两个特点,区块链所记录的信息更加真实可靠,可以帮助解决人们互不信任的问题。
PoW需要花费大量能量,完成操作的一种方式是,以块(block)为单位对组(group)进行交易处理,PoW以一个block为基础。
其工作方式中,我们不会直接创建blocks,但会通过进行很多交易(transactions)来创建很多blocks,形成**区块链(block-chain)**。
每个block区块的数据,这里简单描述以下几个:
- 链中前一个block的hash值唯一标识符
- 交易记录txns
- nonce(难题中发挥关键作用)
- 时间戳timestamp
一个block一般是1MB级别大小。游戏规则即收集交易的节点,然后解决难题,一旦有人解决难题,他就会把这个block发送给网路中每一个人。每个人都可以检查节点是否真正解决了难题,如果检查通过,那么他们会接受这个block作为chain中的下一个区块。
当winner到达下一个block,该区块即是winner的工作量证明(PoW),通常计算PoW的一方被称为矿工(miners)。矿工(miner)必须计算这个新block的hash,使其包含n个前置零(H(B) has N leading zero),矿工可以通过改变nonce做到这点。所以miner对nonce进行随机猜测,计算hash并检查前置0的个数,前置零的数量越大,那么这个块越容易被接受。很明显前置零的数量要求N越大,计算难度越大,N可以随着时间推移而改变,以调整难度。
- 对于比特币系统而言,矿工工作是必要存在的,目标是让每个矿工平均进行一个月的CPU计算。
- 目标希望第一个解决难题的人,需要计算约10分钟。
无论哪个miner最先完成了难题,在整个网络中传播该block,这么做大概需要10min。10min的原因是,网络中传播1MB的block需要一点时间,而且需要有足够的时间将区块提供给许多节点,以避免fork。
问题:所以需要一些leading zeros,hash需要被节点接受,它是每个节点单独设置的数字吗?
回答:不,这是protocol的难题,一个agreed puzzle,关于N的共识。
追问:那么这个N说会时间推移而改变,进而变动难题解决的难度。这里变量N是这么通过网络传播的?有一个中央服务器计算出N并发送到其他地方吗?
回答:不,后续会介绍。block中的时间戳是一个提示点。如果一个块之间的时间变得太短,那么难度就上升了。当然,这里时间戳是使用hash进行验证的,所有这些东西都在blockchain中,每个人看到相同的blockchain。所以他们将计算时间戳之间的相同差值,并在难度方面作出同样的调整。这是一种很酷的设计,日志中有很多东西,如果其中一些是具有确定性的,你可以对日志的内容计算任何确定性函数。
追问:所以这里对于N有确定性的函数能够计算。那我如果尝试发送少于N个前置0的hash记录block,然后网络中的节点都会把我赶出来?
回答:是的,因为你没有真正的解决方案。
问题:有什么办法能阻止攻击者不断向网络发送错误的解决方案吗?
回答:是的,拒绝服务攻击(denial of service attack, DOS),幸运的是检查解决方案非常容易,所以拒绝一个不正确的解决方案不需要多少时间。
问题:如何确定时间戳?比如每个block都设置自己的时间戳。
回答:是的,winner,成功开采的矿工在block中设置timestamp时间戳。
追问:如果他们故意将时间戳设置成比所用时间更长的时间,或许后面计算难度就会因此下降?(因为N计算难度受block之间时间戳差值影响,如果差值小说明当前计算难度不够高,进而会导致N上升,即计算难度上升)
回答:它不能说谎说过头,他们有10min的时间(应该指的是计算难度一般都是10min左右能出下一个block),我不知道时间戳具体怎么检查的,但应该是有办法检查的。
19.7 块和交易(block + txns)
假设B5已经被miner i计算出来,B5前一个位置是B4。此时miner i得知一些交易,进行难题计算中,而新来的交易被存放到内存缓冲区中,已备用于生成后续的block。假设miner i幸运的完成这些交易的计算,得到B6,并广播网络声明B6为B5的下一个log entry。miner i构造B6时,会选择B6包含的交易是哪一些,而其他本地接收到但未解决难题的交易用于后续的block计算。假设有别的矿工用剩余的交易计算出B7,那么miner i会在B6后记录B7,然后删除本地缓存中B7已经结束的所有交易,继续处理剩下的且不在B7内的交易。
这就是high level上对于每个block之间如何交互的大致介绍。
问题:随着交易的到来,试着计算区块的nonce,这会给你N个leading zeros,然后新的交易会进来….
回答:不,这些新的交易不会是当前block的一部分,他们被放在一边,用于下一个区块的计算。
追问:不能把这些新来的交易加入当前block吗?
回答:这会改变hash值。
追问:就算让block容纳更多的交易导致hash值改变了,不也还可以继续调整nonce吗?
回答:但你还需要考虑block大小限制,不能超过协议规定的某个预定义常量。当然还有其他别的限制使得一个block不能无限制地一直追加容纳的交易记录。整体来说就是你计算一个hash,得到一个新block,或者接收到别人计算的新block,然后尝试再继续计算下一个(需要去除已经被新block容纳的交易,用剩余的交易继续计算)。
问题:有没有可能有些矿工因为算力不够一直输,导致从来没获利?
回答:是的,当然。如果我用自己的笔记本挖矿,我很肯定只会亏电费。
问题:交易池(transaction pool)是本地的吗?
回答:是的,每个节点都维护一个交易池(transaction pool)。当它们从网络中其他节点接收交易时,他们使用交易池使下一个区块失败。这里包含各种各样的规则来决定如何选择交易,但不是课程重点。
问题:如果要append,你需要把你的transaction告诉每个人?
回答:是的,或者你告诉一群节点(a bunch of peers),它们会继续把交易传播给其他网络节点。
问题:据我所知,当一名矿工挖矿成功或核实一笔交易时,都会得到奖励。
回答:是的。
追问:他们做了核实,但涉及到时间戳时,它们也可以选择撒谎,假设你有两个verifers,并且它们在同一个block上工作,而且它们几乎同时完成核实,但其中一个撒谎了,它们把时间戳做得稍微更早了一点…
回答:难度并不是在每个block改变,它会定期更改,在一定数量的区块被计算出来之后。后续每个人都能看到这些时间戳是什么,我想一般在经历某个数量的block之后,难度会进行调整。在这个点上,你已经同意了过去所有的block,所有人都达成一致,这也包括block上的时间戳值。
问题:共识问题,我想这能运作归结于几乎每个节点都运行中相同的代码,或至少非常精确地遵守规则。如果我的代码有bug,会发生什么?也许我的bug代码在一堆不同的节点上运作着,这是不是抛出了一致性的概念。
回答:是的,只要大多数节点运行正确的代码,系统就能正常工作。但如果代码有后门,那你就会遇到问题。比如Linux如果有后门,你也会有问题。
问题:所以每个节点都运行相同代码?
回答:有几个不同的比特币版本,但它们中有一个主要的核心,类似Linux项目,它有维护者,代码审核以及其他类似的事情。而大多数钱包和大多数节点,都会运行其中一个标准化版本。
19.8 分叉和最长链(forks and longest chain)
区块链系统中,任何节点都有可能扩展log或者chain,因此会产生分叉(forks)。
比如B5=>B6=>B7,可能正好几乎同时有人解决难题,得到另一个fork,B5=>B6=>B7’。而B7内含有Y->Z的交易,B7’含有Y->Q的交易,必须以某种形式确定后续只使用某一个fork,否则Y出现双重花费(同一个比特币消费两次)。
产生fork的原因一般有:
- 存在至少两个miner几乎同时解决难题,并发布block(find nonce at same time)
- 网络延迟导致block传播缓慢(slow network)
在遇到fork时,当前节点对fork保留,不做处理。当forks中一个分支出现新的block,比其他fork长时,**节点会切换到最长的fork(peer switches to longest fork)**。最终所有节点都会选择最长的fork,在最长链上达成一致,并且沿着最长的链继续采矿。
最长链是如何降低双重花费(double spending)的可能性的,这里先回顾一下双重花费的两种情况:
- Y同时发送Y->Z和Y->Q两笔交易给peers,显然通过log校验,Y->Q会被拒绝
- Y发送Y->Z和Y->Q到不同的peers,此时可能产生forks,但是通过最长链原则,只有一笔交易能生效
论文假设攻击者算力比好人的整体算力低。当Y试图双重花费时,除了Y->Z该交易所属的block生成,Z需要等待该block后再产生5~6个block,此时Z就可以认为当前fork是最长链,线下认同这笔交易。(此时就算有Y->Q这个fork,也可以认为不可能比Y->Z所在的chain长。一般一个fork领先5~6个block后,就基本不可能被另一个frok赶超了)
问题:产生fork的第二个原因,比如网速慢,你能不能检测到。如果矿工包含的时间戳,当他们找到解决方案时?
回答:你可能存疑什么是下一个正确的chain,但这将在之后的区块得到确认,而你使用的未来的区块确实最长的链是什么。
问题:是谁分发这些难题(puzzle)的?
回答:没有必要分配难题,难题是预先确定的。你必须通过block计算出一个hash,且有足够的前置零。所以没有难题被分发的过程,唯一被分发的东西可能是解题的难度N。正如前面所说,这种情况通过时间以一种确定性的方式调整难度N。
问题:所有这些发生的交易,然后通过gossip协议或别的什么,交易被分发给所有节点,然后达成一致,比如哪些交易被打包成一个block。所有人都对block达成了一致。
回答:不,矿工收到交易,由矿工来决定哪些交易该放在block中,然后它开始计算,如果它win了,那block中就含有它指定的那些交易。还有其他复杂的规则限制,但是矿工一定程度上可以决定block中含有哪些交易。而且有一定的激励制度让矿工们愿意做正确的事情。
19.9 矿工激励(miner incentive)
正如我们在“比特币-采矿”一章中所看到的,在任何给定时间段内,矿工可能会被许多交易淹没。系统中预先定义了一个块的最大大小,因此必须在该块中仅包含一定数量的事务。
区块中的交易数量取决于预定义的区块大小和每个区块的平均长度。这里的一个重要提示是,发件人不应在其消息中包含太多信息,以使其简短,从而激励矿工在其他冗长的消息之前接受它。
通常,发件人还会根据一定数量的比特币增加交易费,以激励矿工尽早将其包括在他的区块中。
构建区块链的另一个结果是它的规模。在一段时间内,整个区块链可能变得太大,以至于节点无法将其存储在其磁盘上。这可以通过使用下面描述的Merkle树来解决。
到目前为止,我们看到难题是工作量证明(PoW)的思想核心,也是真正达成共识的核心。但是这需要矿工们做相当多的工作,他们必须使用高性能的计算机计算hash,平均下来每个矿工约需要进行一个月的计算工作。
矿工愿意进行计算工作,是因为有矿工激励机制:
有一些比特币保留在池(pool)中,用于奖励矿工(主要奖励)
比如第一批比特币交易被创建时,矿工从池子里拿到奖励。区块中的交易对矿工来说就是奖励。矿工可以在block中第一个插槽插入交易,把钱从pool转到自己身上。随着时间推移,奖励的比特币数额会降低。几年前是12.5比特币,一段时间后编程6.25。每21万个区块,奖励数额减半,直到它遇到了最后正好能接受的比特币分母,然后就会停下来。
交易本身需要支付奖励费用(次要奖励)
为了挖一个区块,每一笔交易都需要支付一点费用,而矿工收取区块中所有交易的费用,用这些费用奖励矿工自身。所以实际上矿工的收入不仅是pool中瓜分的6.25比特币,还有伴随着交易而来的费用。这是次要的奖励。
比特币发展至今,已经可以看作是矿工之间的军备竞赛,因此产生一些新事物:
矿工池(miner pool)
矿工们彼此合作,并互相分享收入。如果你的pool中有很多很多节点,人们可以分享采矿带来的收入,因为他们(矿工)作为一个pool运作的,从概率上讲,他们更有可能win。
特殊硬件(special hardware)
一些公司发行特殊版本的硬件,它们很擅长计算hash,就是专门为miner pools量身打造的。
高速链路(speed links)
他们(矿工团体)有到许多节点的高速链路,所以如果他们找到了一个区块,他们可以先把它拿出来,称为winner。
问题:这就是你说的为什么每个block都需要大约10min来挖掘,尽管它需要一个月的CPU算力。
回答:是的,平均一个月。但是偶尔运气好,选对nonce,就能更快解决问题。通过改变nonce,你可能只需要不到一个月的时间,这就是10min的由来。
问题:是一个月比较重要还是10min比较重要?因为如果只有一个矿工,预计是平均需要一个月,对吧?
回答:是的,但是如果有很多很多矿工,平均一个block就是10min。
问题:有没有可能出现完全无解的难题?
回答:不,可能需要花费很长的时间,但终究有解。
问题:由于比特币的价值实际上非常不稳定,那我们如何确保矿工的激励制度足以保证未来矿工们会继续计算?我的意思是因为奖励的数量是预先确定的,假设是6.25比特币,但由于某些原因,比特币价值下跌了,然后对于矿工来说,激励措施不够好。
回答:是的,这时候矿工这样做就没有任何价值,然后比特币网络就崩溃了。如果要解决这件事,那可以通过上涨交易费用(即对于矿工而言的次要奖励)。
追问:但交易费用上涨,对于使用区块链的人们来说,又是一种相反的激励。
回答:是的,但如果每个人都在比特币网络上,如果你想交易商品,就必须和比特币网络上某个人交易。所以有各种各样复杂的分析,我不想预测结果会是什么。按照目前的速率,我想在2140年,这是奖励制度用尽的时候,之后将完全基于交易费用激励矿工。
19.10 实际问题(practical issues)
硬分叉是指比特币区块格式或交易格式(这就是广泛流传的“共识”)发生改变时,未升级的节点拒绝验证已经升级的节点生产出的区块,然后大家各自延续自己认为正确的链,所以分成两条链。
软分叉是指比特币交易的数据结构(这就是被广泛流传的“共识”)发生改变时,未升级的节点可以验证已经升级的节点生产出的区块,而且已经升级的节点也可以验证未升级的节点生产出的区块。
比特币硬分叉与软分叉(BTC,BCH,BTG,B2X)_链圈子 (wwsww.cn)
(区块大小导致交易速度问题) : 比特币网路受制于区块大小,目前每个区块1MB的区块大小,处理能力大概是20万笔交易。近年来随着比特币蓬勃发展,交易数量越来越多,因此区块空余空间越来越小,交易速率也受限制。
2015年5月,比特币前核心开发者Gavin Andresen 表示,比特币网路扩容问题迫在眉睫,并提出了透过硬分叉的方式,将比特币块大小上限提高到20mb,时间定为utc 时间2016 年3 月1 日。
不过,到了2016 年,各大阵营提出的扩容方案达不到一致。整个社群对于应该直接进行链上扩容的硬分叉方案,还是采用SegWit 软分叉方案,分成了两大阵营。
- 什么是硬分叉: 硬分叉是指当规则改版,采新旧不同版本的节点因规则不同而导致共用的区块錬的分叉时,旧版本的节点硬性地不接受新版本节点产生的区块,因此采用旧规则的节点而生的分叉继续依旧规而变长,而采用新规则的节点而生的分叉也继续依新规则而变长,采取不同新旧规则的世界两分明,各自筑构各自的分叉(branch/fork)。简单说 就是不相容旧比特币。
- 什么是软分叉 : 软分叉是指当规则改版,采新旧不同版本规则的节点因规则不同而导致共用的区块錬的分叉时,采用旧规则的节点也会软性地接受新规则节点产生的区块,新旧不同版本的节点混在一起筑构区块錬。简单说 就是相容旧比特币。
块计算和传播时间(10 min)
我认为10min是时间的上限,大概是10次传播到网络的时间。所以比特币试图避免一种特权,特权分叉(privilege fork)。避免fork的两个节点几乎同时计算,大致同时扩展一条链。避免这种问题的一种方法,就是给节点留有足够的时间传播block到其他很多节点,让其他大多数节点接受这个block。这就是10min的由来。
区块大小(block size)
当然,区块大小决定了每秒的交易数量,一个block大概是1MB,大约每隔10min生成一个新区块,然后交易数量也被限制成能在单个block中容纳的数量。
改变协议(changes require consensus)
改变需要达成共识。
some are easy
其中一些改变是容易达成共识的,比如解题难度N(前置零的数量)调整,其有一种确定性的算法,每个节点使用相同算法计算
some changes in soft fork
还有一些变化导致了soft fork。比如比特币的核心发布版本作出改变,有一些不兼容的。所以你会有旧客户端(old clients),旧版本的client和新版本client之间会产生一些forks。当然从长远看,人们很可能会选择安装了新软件的新fork。
some changes in hard fork
例如几年前,社区内就block size进行讨论(增大size还是保持原本的size),然后分裂出两fork,实际可能不止2个fork。
当共识算法进入比特币这类去中心化的系统,你会遇到各种各样的实际问题,它可能导致soft fork或者hard fork。因为人们不想在特定的新形式上进行合作。
问题:在硬分叉上,发生了什么?
回答:你有两个不同的区块链,客户端必须选择他们想要跟随哪个分支fork。或者在两个都发布他们的交易,我不太清楚。
追问:假如我有几个比特币,我会在两个分叉都拥有这几个比特币。我可以开始花费它们….
回答:好的,你有那些前缀的比特币,所以两个分叉都有前缀,所以你不能重复花钱…(后续另一个人回答)当比特币有一个硬分叉,其中一个新的分叉被称为比特币现金(Bitcoin cash),所有代币都是在代币的价值内复制的,你没有使自己的价值翻倍。而比特币所减少的价值,其减少的差额正是比特币现金(Bitcoin cash)的价值。所以可以把它想象成股票拆分,你得到了更多的代币,但实际价值保持不变,因为增加了代币的供应。
19.11 小结
分布式共识(distribute consensus with byzantine participants)
具有潜在拜占庭参与者的开放分布式系统中,达成共识。
公开的账单(public ledger)
在公开帐本或公开日志上,允许人们检查每个公钥的余额,并避免重复花费。
工作量证明(proof-of-work, PoW)
确定了允许谁扩展区块链。
问题:能不能多谈一点关于权益证明(proof-of-stake, PoS)?
回答:讲师表示自己不是很懂,可以自己google,哈哈。但基本上网络中的power,与网络中的proof-of-stake成正比。基本的想法即如果你拥有所有比特币的10%,你能决定10%的新区块。你会得到激励,更多的权益。
问题:在PoS下,斗争变得更加具有确定性,对吗?
回答:取决于协议细节。在算法方面,有一个周期性的领导者(periodical leader),还有一个委员会选举(committee election),然后委员会决定下一个区块是什么。然后有一个新的领导者,新的委员会选举,等等。其中许多方面,可能是固定的和随机的,所以攻击者可能赢得游戏。
问题:为了能够挖掘,你必须拥有日志来验证交易,对吧?
回答:是的。矿工复制了整个日志,GB级别。
问题:GB级别的日志会不会太大?
回答:对于一个合理的计算机来说,完全可以接受。
问题:一旦一个币中最新的交易放在足够的区块中,它之前花费的交易可以放弃,进而节省磁盘空间。我认知中的区块链,从来不会丢弃交易,它保存着所有交易的完整日志。为什么实践中要怎么做。
回答:因为为了节省空间。允许矿工节点上的空间压缩。所以,他们(矿工)不必跟踪日志中每一笔交易、每一个比特币。他们必须跟踪最后一个。一种考虑方式是,你可以按照时间计算出所有点所有值的快照,然后你就不需要记住所有过去(的交易记录)了。
追问:那谁会保留完整的历史交易记录呢?
回答:一个是,当你检查交易是否有效时,去扫描整个日志。但人们实际不会这么做。而构建一个数据结构没有太大的影响,有每一个没有花掉的硬币的最后一笔交易。你完全可以下载完整的日志,这些完整日志确实有某些节点维护和保存。而其他人可以选择丢弃古早的历史交易记录,他们可以计算出所有的余额,从一开始就运行所有的交易。
问题:系统中谁维护整个区块,整个交易。
回答:复制到任何地方,每个想得到日志的人。
追问:但如果大多数人都选择截断交易(指放弃历史的交易记录日志),为什么有人会选择一直保持?
回答:(如果你截断了古早的交易记录日志)这让你可以自行决定交易在过去发生在哪里,但它不允许你验证交易。所以,如果你想要能够验证,你就必须保留过去的交易。
Lecture20 Blockstack
Blockstack简介 - 简书 (jianshu.com) <= 推荐阅读,里面最下面的原文链接会更详细一些
Blockstack是一个分散式应用程序的新互联网,配备了一整套开源开发工具来构建和引导分散的应用程序和协议生态系统。用户拥有自己的数据,浏览器就是开始所需的一切,Blockstack是区块链的“Google”。 Blockstack是一款集成了分散式数据、分散式应用程序、分散式用户数据的区块链浏览器应用。 所谓分布式互联网,用户在此之上拥有对其身份的所有权,数据和身份绑定,存储在自己的私有设备,或者云端,从而取消了对第三方机构的依赖。而开发者可以开发分布式的应用本地运行,调用用户的API,在用户许可的情况下访问用户数据,从而不用考虑数据的存储问题。Blockstack通过这种方式将数据主权交还给用户,用户数据由用户保管,未经用户许可,任何第三方无法访问用户数据。由于用户拥有了数据主权,用户可以随心所欲转移,不用再受到平台限制。
Napster是一款可以在网络中下载自己想要的MP3文件的软件。它同时能够让自己的机器也成为一台服务器,为其它用户提供下载。
Kerberos是一种计算机网络授权协议,用来在非安全网络中,对个人通信以安全的手段进行身份认证。这个词又指麻省理工学院为这个协议开发的一套计算机软件。
2016年的论文。Blockstack是一种构建去中心化应用程序(decentralized apps)的方式。与中心化的网站不同,这个网站拥有数据,而去中心化的应用,系统以一种方式设置,用户控制数据而不是网站。
在90s年代末以及2000年早期,就有很多点对点应用程序(p2p)。比如Napster,keybase等等。
Blockstack是一种非货币使用比特币区块链的例子。这个系统关注的是命名,即如何构建一个分布式去中心化的命名系统。常见的命名系统有DNS,kerberos。Blockstack是去中心化的。
与前面的章节不同,Blockstack更算是一个实验性的项目,尚不能认为是某一种问题的唯一解决方案。这是一篇发人深省的论文,但不是针对某一特定技术问题给出明确答案。围绕这篇论文,主要讨论里面涉及的一些设计,思考有何利弊。
20.1 中心化网站(centralized websites)
在讨论去中心化的应用程序之前,先回顾下常见的中心化网站(centralized websites)。网站可能分布在世界各地的多个数据中心,但网站的设计架构是集中式的。这种设计的一个显著特征即,数据和应用捆绑,数据本身只是被应用程序网站所控制。对于大多数中心化网站,用户应用程序数据非常受控制,你无法主动控制这些数据。网站甚至可以非法售卖用户数据来获利,但是你对此无能为力。
是否有一种设计能够打破这种模式,而是遵循去中心化的应用模式。
20.2 去中心化应用(decentralized apps)
假设有U1和U2两个用户,其将自身的数据通过加密传输至google Drive或Amazon S3等云存储。U1和U2可以通过本地的某个app获取云存储上双方的数据并解密。此时服务器只提供存储API,而应用程序在用户机器上运行,数据也是只有用户能解密(即数据的主动权在用户自身)。这是一种构建去中心化架构的应用程序的方式。
20.3 去中心化应用实现难点
有两大类的挑战(challenges):
商业盈利模式(revenue model)
这里不是讨论重点。
技术挑战(techmical challenge)
文件系统API不如SQL灵活强大
目标是希望能够对所有用户数据进行任意查询,这在去中心化应用中更难实现。因为数据可能分散在很多不同的存储服务器上。
类出价场景
去中心化,需要有某些可信的方面,来这和这些bids,然后决定谁是winner,而不会事先透露相关信息。
加密密钥
管理上也比较困难,通常涉及数据的加密,密钥管理等话题。一些用户如果不消息丢失了密钥,那就永远无法得到自己的数据了。
命名
因为Blockstack主要的功能就是命名。
问题:出价有什么挑战?挑战是什么?
回答:你需要你个应用程序能够访问用户的出价,但不应该把信息透露给其他应用程序。比如U1出价后,如果通过应用程序得知U2的出价,那并不公平。所以你需要受信任的一方或任何协议,让这一切发生。如果应用程序模型在你的本地工作站上运行,那你可以任意修改应用程序。
问题:关于去中心化模型的设计,这个应用程序是否需要一个客户端,或者能不能有集中式应用在互联网上。
回答:原则上你可以在互联网上,不一定是在用户本地工作站上运行,可以在任何地方,但是这个应用程序本身受用户控制。用户可以自己决定哪个应用来处理哪些数据(即用户拥有对数据的主动权)。
20.4 blockstack命名(names)
公钥基础设施是一个包括硬件、软件、人员、策略和规程的集合,用来实现基于公钥密码体制的密钥和证书的产生、管理、存储、分发和撤销等功能。
PKI体系是计算机软硬件、权威机构及应用系统的结合。它为实施电子商务、电子政务、办公自动化等提供了基本的安全服务,从而使那些彼此不认识或距离很远的用户能通过信任链安全地交流。
Domain Name System Security Extensions (DNSSEC)DNS安全扩展,是由IETF提供的一系列DNS安全认证的机制(可参考RFC2535)。它提供了一种来源鉴定和数据完整性的扩展,但不去保障可用性、加密性和证实域名不存在。
假设你有一个todo列表想要和其他用户共享,你必须能够命名要共享的用户,所以有一个从名字到用户的映射(name => user)。另外,还存在从名字到数据位置的映射(name => location of data)。如果用户1想要访问用户2的数据,用户1需要有一种命名用户2的todo列表,并且获取它。另外,还有名字到公钥的映射(name => public key),让用户1获取到用户2的数据,需要通过公钥验证签名。
- name -> user
- name -> location of data
- name -> public key
可见,在去中心化系统中,名字(name)起着至关重要的作用。并且,common name给出从name到keys的映射,称为**公钥基础设施(public key infrastructure)**。构建任何公钥基础设施都是相当具有挑战性的。你可能对DNSSec很熟悉,在万维网上有一种特殊的方式,证书具有完整的公钥基础设施,Kerberos是公钥基础设施的一个示例。
Blockstack提供了去中心化的公钥基础设施。
实现去中心化的命名系统有以下3个难点:
命名唯一性(unique name)
每个用户都需要有一个唯一的名字
命名可读性(human readable names)
去中心化(decentrailzed)
该论文的观点是很容易实现其中3个,但是同时实现3个很难。比如:
- 邮箱地址只满足命名唯一性、命名可读性,但是不满足去中心化
- 随机公钥满足命名唯一性、去中心化,但是不满足命名可读性
- 手机内的联系人列表,满足命名可读性、去中心化,但是不满足命名唯一性
而论文的目标就是同时实现3个特性,构造唯一命名、用户可读且去中心化的命名系统。
20.5 区块链和namecoin
Namecoin是比特币的一个分叉,也是比特币第一个alt-coin,从2011年4月开始第一笔交易,到8月份与比特币合并挖矿。它最初的启发来自BitDNS(用区块链来管理域名查询服务的一个项目),旨在将域名管理的权力分散,避免单点失败。
Blockstack底层通过区块链实现命名系统,并且系统是公平的。他们采用namecoins方法。这里为了方便讨论,用比特币的区块链进行讨论。
我们要创建命名系统的方法是,发布同步类型的交易,他们都自称一个name。例如我们可能有特殊的交易,因为比特币中每一笔交易都有一个元数据字段,你可以将任何内容放入到元数据字段中,所以我们这里放入的是一个名字记录。
该方案中基本规则即,第一个使用某个name的用户会win (first name record wins),后续的block中如果出现相同的name会被忽略。区块链是所有发生过的操作的日志,它们是有序的,以发生的顺序达成共识。这里相当于利用区块链构造了一个含有所有有效name的数据库。
命名唯一性
满足,通过区块链保证只有最早一个block的name胜出。
命名可读性
满足,命名由用户自行决定
去中心化
满足,按照比特币的方式去中心化。
然而系统并不完美,还有很多问题需要处理。比如如何知道哪条记录与哪个用户匹配,你如何找到其他名字等,同时这些也是常见的命名系统问题。我们应该一气呵成解决所有命名问题。
问题:Namecoin,它们所做的是将这条记录添加到交易中?
回答:它们运行自己的区块链,独立于比特币。它们还有一系列规则,比如你需要支付多少namecoin来得到特定的名字,还有各种各样其他扩展。
20.6 通过区块链实现去中心化的应用和命名系统
如何通过区块链实现去中心化的应用程序和命名系统。这里有一些很务实的问题/难点:
交易能容难的数据量有限(limits on data size txn)
写入和传播缓慢(slow writes)
如前面所述,写入block和传播,在确定区块链稳定之前,通常需要等待再产生5~6个block,避免fork歧义。而一个block计算大约需要10min,即大约等1hour后才稳定。如果把todo列表的修改放入区块链,结果需要1hour后才能观察到变化,那显然不友好。
低带宽/低吞吐(low bandwidth)
每秒只有几笔交易。显然如果想要尽量高吞吐,那不能将系统中所有操作都放置到区块链中。
帐本(ledger)
不是讨论的重点。如果按照传统比特币风格,启动时需要从头开始逐一检查所有的交易,然后才能建立起完整的命名记录,这需要消耗大量时间。
我们(论文)想做的是,最大限度减少区块链的使用,以获得高性能的写入。
20.7 blockstack系统架构概述
笔记 MIT6.824 Lecture 20: Blockstack_Bokk的博客-CSDN博客_6.824 bitcoin 学习笔记 <= 图片出处
最底层的是区块链,里面有许多交易和blockstack完全无关。而blockstack位于区块链中的特定区块。第二层即从区块链中挑选出和blockstack有关的区块,在OP_RETURN字段中,有一个名字,比如name:”x” + 区域文件的哈希值(the hash of zone file)。blockstack利用比特币特性,保证名字到区域文件的绑定/映射在去中心化下还是唯一的。blockstack解释这些特定的name transactions,查看OP字段,存储到blockstack database中,记录名称x到区域文件hash的映射。
整体而言,第二层建立了从name到zonfile hash值的映射记录数据库。当然,这里会过滤掉重复使用name的block,只保留最早出现的一个block。通过使用hash(zonfile),应用程序可以定位到zonefile。当我们收到一个声称是zonefile的文件时,我们重新计算hash,如果和通过比特币交互获取的hash相同,则可认为这就是与x对应的zonefile(认为没有被篡改或顶替)。
zonfile里存储的是名字到URI的映射。zonefile分为可变(mutable)和不可变的(immutable)。
可变的zonfile具有URI和公钥(public key)。当用户2查找用户x时,校验zonfile的hash值,然后从zonefile里获取x的公钥,验证URI指向的文件的签名,这些校验都通过后,认为用户x获取到了用户x的zonefile。
- mutbale zonfile:包括URI、name、public key、文件hash值。在系统实现中,允许用户更新可变zonfile,而用户很难判断文件是新版本还是旧版本,论文提到可能zonefile里也存有文件版本号。
- immutable zonfile:zonefile本身不可变,一个URI唯一标识某一个版本的zonefile。此时如果要更新zonefile,你就必须在区块链中重新发布或创建一个日志条目,将x映射到一个新的hash zonefile。
所以,如果你使用mutable zonefile记录一个文件,那么更新文件时不必在区块链中发布新的记录。实际上,区块链中唯一需要创建的记录只有x的名字name。当然x可能拥有很多name,它们都位于zonefile中。实际只有name和zonefile的hash值需要记录到区块链,其他的数据都不需要依赖区块链。
问题:我们不会失去数据的不变性保证,这些数据可能会被删除,然后你就不会有数据的哈希值,可能会丢失。
回答:什么意思,说的是zonefile丢失吗?这里zonefile也会被传播到大多数节点,所以不会有这个问题。而URI一般是云存储服务商的文件URI,比如Amazon S3之类的。这里用这些存储服务的原因是它们提供统一的文件访问API。
问题:我们如何找到zonefile,如果只有hash值?
回答:我们实际不关心文件出自哪里。上图layer3称为路由层,基本上你告诉路由层,我在找一个具有以下hash值的文件,然后路由层就会产生那个文件。你可以check是否拿到了正确的文件。通过重新计算hash,看看是不是你想要的文件。
问题:文件存储或zonefile中的操作,仍然受到底层区块链的限制,对吗?或者因为对文件的修改或更改需要新的hash,因此需要在区块链中形成新的日志条目。所以,你仍然需要等待block记录”被接受”。(即为避免fork问题,还需要多等待5~6个block加入)
回答:是的,如果你改变了zonefile,它必须通过txn(交易)。例如更新todo列表,不需要比特币交易,你根本没有更新zonefile。(因为更新的是zonefile里URI指向的文件,但URI本身没有改变,即zonefile没有变化)
问题:但是,我们不是也存储了文件的hash值吗?
回答:有两种情况,可变的存储(mutable storage)和不可变存储(imutable storage)。对于不可变存储,你不更新,你可以在zonefile里存放文件的hash值。但是对于可变存储,将会看到大量的写入,此时不该在存储文件hash值,你应该使用密钥。
问题:如何确认使用可变存储,你获得了正确的数据(因为zonefile里没有存储文件hash值)?
回答:你可以通过公钥验证你得到的文件是否由x产生,至少保证是x写的文件。你可能不知道这个最新版本,所以论文没有详细讨论这些。在基本系统实现,我们通常会存储版本号,至少你可以检测到回滚的发生。实际实现还是比较困难的,讲师表示暂时无头绪。至少这里没法保证/验证获取的文件一定是最新版本。
问题:对于可变存储的修改来自哪里?
回答:即修改zonefile的URI指向的位置的文件,然后再重新对其签名。
问题:在zonefile中,每个名字只有一个URI吗?
回答:讲师表示细节不清楚,需要回顾源码。
20.8 创建名字(name creation)
首先用户需要拥有比特币(user must have some bitcoins),因为需要支付(交易费用)。你必须说服至少一个矿工,将你的交易纳入比特币帐本。所以你创建的每个名字都有2笔交易:一种是预购交易(pre-order transaction),另一种是register。
预购交易(pre-order txn)
预购交易中,你不会把名字列出来,而是只有名字的hash值。所以任何收到预购交易的人,不知道名字是什么,只知道hash(name)。
register交易
这个交易真正注册名字,它包含了实际的名字。我们首先发布zonefile的hash值。
为什么要分两种交易,实际上它们这里采用namecoin,namecoin就是这么做的。为什么呢?因为如果一开始直接发布名字,别人会抢注相同的名字。领跑者问题(front runner problem)准确描述了,假设你直接尝试注册google.com,矿工发现后可以抢注相同的名字。所以先声明名字的hash,确保name已经被注册到区块链中。
在某些方面,这不是它们的发明,而是来自namecoin。
问题:为什么攻击者不可能预先计算google.com的hash值,然后查看区块链,看看有没有人发布了这个hash值。
回答:是的,你说的是有可能的。所以实际实现绝对比课堂上描述的复杂,比如还有混入其他参数,如nonce等。否则你可以直接创建一个字典(彩虹表)。
20.9 去中心化的应用程序协作(collaborative decentralized applications)
这里同样以todo列表数据举例。U1和U2各自维护自己的todo列表,并且事先通过某些方式得知对方的name。
此时U1通过U2的name查询到U2的zonefile,在zonefie的URI指向的位置找到todo列表条目。这里省略了通过blockstack的路由层获取文件的流程,以及后续校验流程。而U2更新URI指向的文件时,U1无感知,但定期访问URI可以获取新的todo列表。
这里有个问题是,去中心化的应用程序如何才能简单的编写去中心化版本。中心化的系统,由系统存储和管理文件版本,用户可以简单地通过系统访问不同版本的文件。
问题:最大的困难是什么?使用文件系统API而不是使用关系型数据库?
回答:你怎么呈现全球关系性数据库,所有这些用户文件在各种不同的存储提供商中。你不能在所有存储提供商之间做select,这太疯狂了。你也不可能把所有用户数据下载到自己的计算机上,存储成本过于昂贵。
追问:linked data database怎么样?
回答:我想这是研究人员想要追求的,但你可以构建一种可伸缩的数据库基础设施,其中用户仍然控制位于不同位置的自己的数据,并提供一种关系型数据类型接口。显然,就blockstack是提供不了这种接口。
问题:这种去中心化的PKI(公钥基础设施)与信任网络PKI相比,有什么好处?
回答:我熟悉的信任网络KPI,典型的有keybase。对于这类公钥基础设施的挑战是,你如何表示用户组(groups of users)。比如在SUNDR论文中看到的,有group name,有组名的公钥。如何创建和管理它们,如果把它们插入其中,如何将这些合并到名字记录链中,Keybase正是为此而战的一个典例。keybase可能是最好的去中心化KPI,至少是最广泛被使用的。
问题:像blockstack这么做,有什么好处吗?或者它更具有可扩展性?
回答:blockstack主要不同的是,具有名字唯一性。而keybase更多关注的是去中心化,但不适用于全球唯一的名称(blockstask可以保证全球唯一名字hash值)。这种情况下,Keybase偶尔发布所有名称的hash,以及区块链中所有名称的完整Merkle树,这样你可以确认keybase不玩那个游戏。总之,blockstack和Keybase最大的区别就是Keybase不保证全球唯一的名字。
问题:用户怎么选择向谁展示他们的数据,或者他们允许谁访问他们的数据。我好像没看出来这个在系统里这么实现的?
回答:我不确定blockstack怎么做的,但是你可以为不同的用户加密相同的数据。如果你只想要与U1或者U2共享数据,你可以使用U1活着U2的公钥进行加密,然后只有U1或U2的密钥可以解密数据。这就为你提供了访问控制表(access control lists)。
问题:所以对于每个你想要分享数据的人,你必须用他们的公钥对数据加密。
回答:是的。当然可以做的更复杂,比如可以拥有一组密钥(group keys)。给一组用户一个密钥,使用不同用户的公钥增加密钥盒,然后他们访问密钥盒,取密钥对数据解密。因此你只需要对数据加密一次,而不是多次。你必须对密钥盒加密多次。
问题:你认为这样的系统能够和集中式模式竞争吗?比如在性能或可伸缩性方面。
回答:我不知道答案。我只知道这个系统,在最简单规模下也不是那么容易扩展的。在某些方面,你可以认为去中心化的体系结构,是按用户划分的,每个应用程序都在用户的一台计算机上运行。所以,你不需要数据中心的缓存,所以我不知道问题答案是什么。但是人们已经通过实践证明集中式的设计往往具有更大的可扩展性。
问题:我觉得只是为了获得一个独一无二的名字,使用这个系统还需要付费,有些浪费
回答:实际上激励矿工费用可能没有你想象中那么昂贵。毕竟现实中DNS注册域名也不是免费的,需要相当多的钱。
问题:替换底层的区块链有无可能?
回答:实际上blockstack的设计也不是很依赖底层的区块链,它们可以很容易地切换到另一个区块链。它们最先使用的namecoin,后来才切换到比特币。我认为论文的观点是,我们可以切换底层区块链为我们想要的。
问题:图中blockstack数据库中的名字历史记录(name history)存储了什么?
回答:存储了zonefile的不同版本。对应区块链中x对同一个zonefile的修改记录。
问题:为什么后来又将底层区块链从namecoin切换到比特币区块链,出于什么考量?
回答:我想论文中一开始在namecoin上构建,这是一种用于命名的特殊用户的帐本。后来发现了namecoin的安全问题,其中一个问题是矿工并不多,它观察到有一些矿工池有50%以上的工作容量,因此这些矿工池可以做任何想做的事情到帐本上。
问题:zonefile存储系统的URI,我想应该不是单纯的S3?
回答:这个由blockstack实现决定,其文件系统有用于不同存储提供商的后端,不管是S3还是google的文件系统,所有有一些命名方案保证blockstack文件系统可以解释并检索处正确文件。
问题:有一件事一致困扰着我,读这些区块链类型的论文时,比如一百年后会发生什么,当帐本的到数万亿级别的数据。我们是不是没有避免的方案。接下去会发生什么。
回答:很难推测一百年后会发生什么。但是我想可能可以设置一个检查点(checkpoint)。能想象出很多摆脱困境的方案,一个是你可以在状态设置一个检查点,建立在帐本上,并将检查点的hash值包括到帐本中,之后你可以广泛复制检查点,然后从检查点开始运行,截去开头的部分。
追问:这样做的一方必须得到信任还是?
回答:设置检查点应该需要产生一些fork。这不是什么大问题,通常比特币的汇率,因为交易数量,每秒钟你可以做的很少。另外,比特币论文上提到过,有许多优化,你不必记住每一枚coin的每一笔交易,但你必须记住每一枚coin的最后一笔交易。通过这么做,你可以只记住block headers,而不是记住完整的block。